
データの正規化:生の数値を収益に変換する
公開: 2022-05-13データはすべてのビジネス上の意思決定の中心です。 それはあらゆる場面で私たちを取り囲んでいます。 残念ながら、データソースから直接取得する情報は、構造化されておらず、断片化されており、誤解を招くことがよくあります。
あなたはおそらく、リードを引き付け、ROIを改善し、収益を増やすのに役立つ可能性のある鈍いデータの山に座っています。
データの正規化により、生の数値が価値を高める実用的な洞察に変わります。
データの正規化とは何ですか?
いくつかの大きな言葉を使用すると、データの正規化は、特定の範囲または標準形式にデータを適合させるような方法でデータを編成するプロセスです。 これは、アナリストが新しい洞察を獲得し、データの冗長性を最小限に抑え、重複を取り除き、データを簡単に消化してさらに分析できるようにするのに役立ちます。
ただし、そのような言い回しは複雑で混乱を招く可能性があるため、簡単で説明的な例に要約してみましょう。
あなたがリンゴを収穫している庭師だと想像してみてください。 今年は、 20本の木から500個のリンゴを収穫することができました。 しかし、あなたの隣人は1,000個のリンゴを集めることを誇りに思っており、あなたをひどい庭師と呼んでいます。
500個のリンゴを隣人の1,000個のリンゴと比較すると、あなたはあまり熟練した庭師ではないように見えるかもしれません。 しかし、あなたの隣人は、彼がそのような収穫を達成するために百本のリンゴの木を植えたとあなたに決して言いませんでした。
データを正規化すると、隣人が不快な状況にあることが明らかになります。 20本の木から500個のリンゴを使用すると、 1本の木あたり25個のリンゴを収穫しますが、隣人は1本の木あたり10個のリンゴしか収穫できません。 それで、今ひどい庭師は誰ですか?
分析は、正規化されていない大量のデータによって混乱する可能性があるため、樹木の森を確認することはできません。
銃規制データを使用した別の例を次に示します。 これは、データの正規化なしで認知バイアスの犠牲になることがいかに簡単であるかを示しています。

正規化された洞察がなければ、包括的な全体像を構築し、調査したトピックについて十分な情報に基づいた意思決定を行うことはほとんど不可能です。
重要なポイント:
- データの正規化は、データセット内のデータを再編成するプロセスです。
- このプロセスにより、さらなる分析とデータ操作が簡素化されます。
- データの正規化により、調査したトピックの包括的なビューを確実に取得できます。
わかりましたが、いつデータを正規化する必要がありますか?
異種データ(データ型と形式のばらつきが大きいデータ)の結果として、ユーザーはさまざまな問題を経験します。 データを正規化する必要がある場合は、他のユースケースがあります。 マーケティングアナリストの観点からこの問題を考えてみましょう。
何よりもまず、命名規則の統一です。 たとえば、数十のマーケティングチャネルからデータを収集しているときに、アナリストは異なる名前で同じ指標に遭遇することがよくあります。 その結果、アナリストはデータをマッピングする際に困難に直面します。
たとえば、あるRedditユーザーが異種データの問題を説明する方法は次のとおりです。
もう1つの課題は、通貨やタイムゾーンなどの異なるデータを信頼できる唯一の情報源に統合することです。 広告費がドル、ユーロ、ポンド、およびその他のいくつかの通貨に分割されている間は、洞察に満ちたダッシュボードを構築することはできません。
別のマーケティング担当者がRedditでこの問題を説明する方法は次のとおりです。
では、データを正規化するのに適切な時期はいつですか?
- データセット内のメトリックを一致させる場合、命名規則が異なります。
- 通貨、タイムゾーン、日付形式などの異種データを照合する必要がある場合。
- 一部のデータが冗長であることに気付いた場合は、それを削除する必要があります。
よく混同される用語:データの正規化と標準化
データ変換では、標準化と正規化は2つの異なる用語であり、しばしば混同されます。
正規化は、データセットの値を再スケーリングして、[0,1]の範囲に収まるようにします。 このプロセスは、すべてのパラメーターを正のスケールにする必要がある場合に役立ちます。
標準化により、データの平均が0、標準偏差が1になるように調整されます。 特定の範囲に入る必要はなく、外れ値の影響をはるかに受けません。
この情報は、マーケティングアナリストが用語の混乱を避けるのに十分すぎるほどです。 ただし、このトピックをさらに深く掘り下げたい場合は、ここで2つの概念のすべての違いを見つけることができます。
データを正規化し、洞察をまとめる方法
基本的に、データの正規化では、データセット内のすべてのレコードに対して標準のデータ形式を作成する必要があります。 アルゴリズムは、入力に関係なく、すべてのデータを統一された形式で保存する必要があります。
データの正規化の例を次に示します。
- ミスターHOLmESは、ホームズ氏として保管する必要があります。
- Fifth Avenue Sfは、サンフランシスコの5thAveとして保存する必要があります。
- CTOは最高技術責任者として保管する必要があります。
データを正規化することは、データベースの正規化と密接に関連しています。 それが何であるかについて簡単に説明しましょう。
データベースの正規化:洗練された洞察の前提条件
データベースの正規化は、リレーショナルデータベース内でテーブルとデータ行を整理するプロセスです。
このプロセスには、テーブル間の関係の作成と管理が含まれます。 データベースを正規化する一方で、アナリストとデータエンジニアは、データを保護し、さらに分析するための柔軟性を高めるのに役立つルールに依存しています。
すべてのルールは、データベース正規化タイプまたはいわゆる「正規形」によって宣言されます。
合計で7つの正規形があります(最初の3つが最も頻繁に使用されます):
- 第一正規形(1 NF)
- 第2正規形(2 NF)
- 第3正規形(3 NF)
- ボイスコッド正規形(BCNF)
- 第4正規形(4 NF)
- 5番目の通常の形式(5 NF)
- 6番目の通常の形式(6 NF)
これらすべての正規形を調べて、データの正規化にどのように役立つかを学びましょう。
第一正規形(1NF)
最初の正規形では、次の条件を満たすデータテーブルが必要です。
- 各テーブルセルには単一の値が必要です。
- 各レコードは一意である必要があります。
- どの列にも非表示の値を含めることはできません。
例を見てみましょう。 ここに、employeeテーブルからの2つのレコードがあります。

Department_Nameセルには、セルに複数のパラメーターが含まれています。 したがって、それらは1NFの最初の規則に違反します。
テーブルを正規化し、繰り返しグループを削除するには、このテーブルを2つの部分に分割する必要があります。 正規化されたテーブルは次のようになります。

2番目と3番目の正規形は、主キー列と非キー列の間の依存関係を中心に展開します。
第2正規形(2NF)
第2正規形の主な要件は、テーブルのすべての属性が主キーに依存する必要があることです。 つまり、2次列のすべての値は、1次列に依存している必要があります。
注:主キーは、データベースレコードの識別に役立つ一意の列値です。 いくつかの制限と属性があります。
- 主キーの値をNULLにすることはできません。
- 主キーの値は、テーブルごとに常に一意である必要があります。
さらに、テーブルはすでに1NFにあり、すべての部分的な依存関係が削除され、別のテーブルに配置されている必要があります。
この段階で、複合主キーが最も問題となる問題になります。
注:複合主キーは、2つ以上のデータ列で構成される主キーです。
従業員が受講したコースを追跡するテーブルがあると想像してみてください。 異なる従業員が同じコースに登録する場合があります。 そのため、一意のレコードを識別するための複合キーが必要になります。 [日付]列は、複合キーの追加パラメーターになります。 例を見てください:
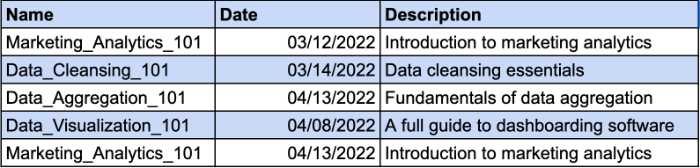
ただし、[説明]列は機能的に[名前]列に依存しています。 コース名を変更する場合は、説明も変更する必要があります。 したがって、2NF要件に準拠するには、コースの説明用に別のテーブルを作成する必要があります。

このようにして、コースの説明に別のキーを付けて、複合キーの使用をやめることができます。
第3正規形(3NF)
3番目の正規形では、テーブル内のすべての非キー列が主キーに直接依存している必要があります。 つまり、キー以外の列のいずれかを削除しても、残りの列は各レコードに一意の識別子を提供する必要があります。
3NFの主な要件は次のとおりです。
- すべてのテーブルは2NF要件に準拠しています。
- 非主キー列は、主キー列のみに依存する必要があります。
- テーブルには推移的な機能依存性はありません。
2NFと3NFの主な違いは、3NFには推移的な依存関係がないことです。 非キー列が別の非キー列に依存している場合、推移的な依存関係が存在します。
注:推移的な依存関係は、同じテーブル内の値間の間接的な関係であり、機能的な依存関係を引き起こします。 関数従属性は、属性間に特定の制約を設定します。 この関係では、属性Aが属性Bの値を決定し、BがAの値を決定します。
以下の例を見てください。

ここで、従業員IDは前の例の部門IDを決定し、部門IDは部門名を決定します。 ここで、従業員IDと部門名の間に間接的な依存関係が発生します。
3NF要件に準拠するには、テーブルを複数の部分に分割する必要があります。
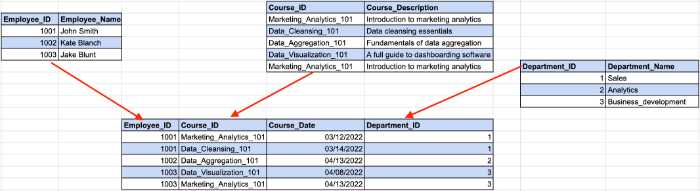
この構造では、すべての非キー列は主キーのみに依存します。
7つの正規形がありますが、データベースは3NF要件に準拠した後に正規化されたと見なされます。 トピックを最後までカバーするために、残りの正規形の概要を簡単に説明します。
ボイスコッド正規形(BCNF)
これは、3NFのより堅牢なバージョンです。 BCNFテーブルは、すべての3NFルールに準拠し、複数の重複する候補キーがないようにする必要があります。
第4正規形(4NF)
インスタンスのいずれかに2つ以上の独立した複数値のデータエントリが含まれている場合、データベースは4NFと見なされます。
5番目の通常の形式(5NF)
テーブルが4NF要件に準拠している場合、テーブルは5番目の通常の形式に分類され、データを失うことなく小さなテーブルに分割することはできません。
6番目の通常の形式(6NF)
6番目の正規形は、関係変数を既約成分に分解することを目的としています。 時間変数または他の間隔データを処理するときに重要になる場合があります。
データベースの正規化101については以上です。すべてがどのように機能するかがわかったので、データの正規化が洞察にもたらすメリットをよりよく理解できます。
データを正規化することが重要なのはなぜですか?
すでに述べたように、データの正規化の主な目標と利点は、データベースのデータの冗長性と不整合を減らすことです。 重複が少ないほど、データ取得中に発生する可能性のあるエラーや問題が少なくなります。
ただし、ワークフローでデータアナリストを支援する明らかな利点はあまりありません。
データマッピングはもはや時間の無駄ではありません
正規化されていないデータを処理する必要があった場合、複数のテーブルから1つのテーブルにデータをマッピングするプロセスはかなり面倒です。
複数のテーブルを結合し、重複を処理し、多くの空のデータエントリをクリーンアップする必要があります。
もちろん、SQLクエリまたはPythonスクリプトを記述して、データを手動で正規化することもできます。 ただし、自動データ正規化機能を備えたデータマッピングツールを使用すると、プロセスが高速化されます。
たとえば、OracleIntegrationCloudはデータマッピング機能を提供します。 クラウド内のデータを正規化した後、ツールはソーススキーマのメタデータを構築し、ターゲットスキーマ内のすべてのデータオブジェクトに対して1対1のレコードを作成します。
マーケティングの洞察を扱うアナリストには、独自の隠された宝石があります。 ImprovadoのMCDM(Marketing Common Data Model)は、マーケティングおよび販売データの正規化のためのスイスアーミーナイフです。 このツールは、異なる命名規則を統合し、洞察を正規化し、手動のアクションを必要とせずにデータソースと宛先の間のギャップを埋めます。
️豊富なリストを使用して、ニーズに合った適切なデータマッピングツールを見つけてください️
データストレージをより効率的に使用する
日を追うごとに、企業はストレージスペースを占有するデータをますます収集しています。 クラウドストレージを使用する場合でも、オンプレミスのデータウェアハウスを使用する場合でも、効果的に使用する必要があります。
たとえば、AWSS3に保存された100TBのデータは、月額$2,580の費用がかかります。 さらに、Amazonは、データに対して実行するすべてのクエリに対して料金を請求します。 数十ギガバイトの冗長データは、ストレージサービスの請求書を増やすだけでなく、意味のない洞察の分析にお金を払わせることになります。
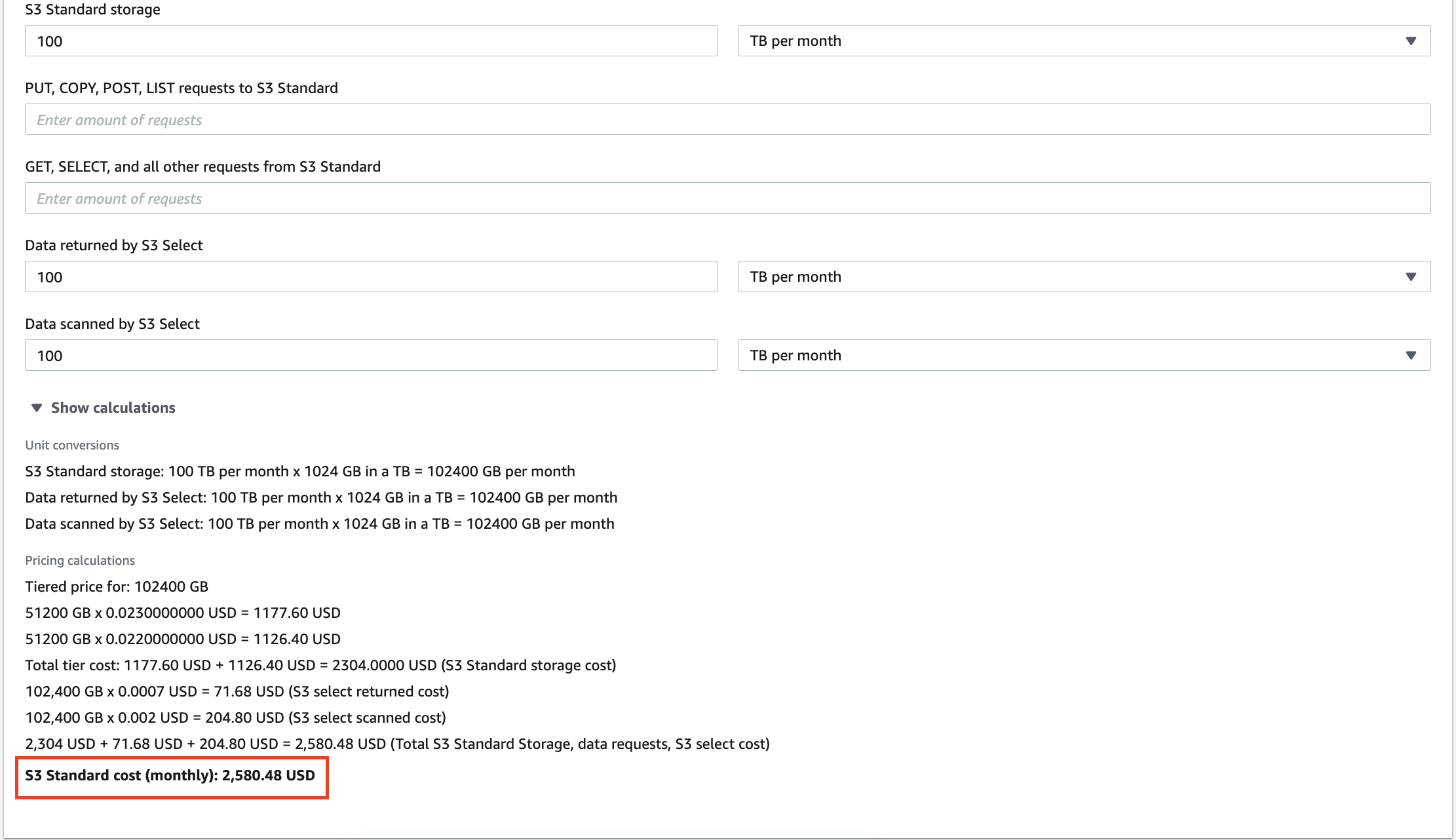
オンプレミスのデータウェアハウスのスケーリングにもコストがかかるため、不要な情報を消去することで、運用コストとTCO(総所有コスト)を削減できます。
洞察までの時間を短縮する
コスト削減とは別に、アナリストは分析の生産性を高めることもできます。
テラバイトのデータに対するクエリの実行には時間がかかります。 システムがクエリを処理している間、コーヒーを飲みながら同僚と政治について話し合うことができます。 しかし、データセットにいくつかの不整合があったためにクエリ出力が無意味である場合は残念です。
正規化されたデータを使用すると、常に期待どおりの出力が得られますが、「N / A」、「NaN」、「NULL」などの驚きはありません。さらに、関連データのみを解析すると、システムはクエリをより高速に実行します。 誰が知っている、多分次回あなたはあなたのコーヒーマシンがあなたのカプチーノを作る前に出力を得るでしょう!
信頼できるダッシュボードを作成する
データの視覚化は、分析作業の全体像を構築するための最良の方法です。 ただし、ダッシュボードを過酷なデータに基づいて構築した場合、ダッシュボードには価値がありません。 ダッシュボードを複製してフィードすると、ダッシュボードは実際の状況を反映しません。

そのため、カラフルなチャートやバーのプリズムを通して複雑な概念やパフォーマンス指標を説明したい場合は、データの正規化が最優先事項です。
さまざまな環境でデータを正規化する方法
データアナリストはさまざまなツールを使用するため、今日の市場で最も需要の高い環境でデータを正規化する方法について説明します。
Pythonでデータを正規化する方法
Pythonを使用するデータサイエンティストとアナリストは、いくつかのライブラリを使用してデータを操作し、整理します。 それらの中で最も人気のあるものは次のとおりです。
- パンダ
- ゴツゴツ
- TensorFlow
データの正規化プロセスを高速化するのに役立つ可能性のあるこれらのライブラリの機能のいくつかを確認します。
データセットの列を削除する
生データには、多くの場合、過剰または不要なカテゴリが含まれています。 たとえば、インプレッション、CPC、CTR、ROAS、コンバージョンを含むマーケティング指標のデータセットを使用していますが、必要なのはこのテーブルからのコンバージョンのみです。
変換以外のすべてが分析にとって重要でない場合は、余分な列を削除する必要があります。 Pandasは、drop()関数を使用してデータセットから列を削除する簡単な方法を提供します。
まず、削除する列のリストを定義する必要があります。 この場合、次のようになります。
column_drop_list = ['Impressions、' CPC'、' CTR'、' ROAS']
次に、関数を実行する必要があります。
dataframe_name.drop(column_drop_list、inplace = True、axis = 1)
このコード行では、最初のパラメーターは列のリストの名前を表します。 インプレースパラメータをTrueに設定すると、Pandasは変更をオブジェクトに直接適用します。 3番目のパラメーターは、データフレームからラベルまたは列を削除するかどうかを示します(「0」はラベルを表し、「1」は列を表します)。
データセットを再度確認すると、冗長な列がすべて正常に削除されていることがわかります。
データフィールドのクリーンアップ
もう1つのステップは、データフィールドを整理することです。 データの一貫性を高め、データを標準化された形式にするのに役立ちます。
ここでの主な問題は、マーケティングプラットフォームのAPIが100%正確なデータを転送することを確信できないことです。 それでも、文字の置き忘れや誤解を招くデータに遭遇する可能性があります。
1つのマーケティングキャンペーンで表示できるインプレッション数は1つだけです。 そのため、貴重な数字を他の文字から分離する必要があります。
正規表現(regex)は、データセット内のすべての数字を識別するのに役立ちます。 この正規表現ジェネレーターは、ニーズに合った正規表現を作成し、すぐにテストするのに役立ちます。
次に、str.extract()関数を使用して、データセットから必要なデータを列として抽出できます。
true_impressions = dataframe_name.str.extract(your_regex)、expand = False)
最後に、列を数値バージョンに変換する必要がある場合があります。 データフレームのすべての列にはオブジェクトタイプがあるため、数値に変換すると、以降の計算が簡単になります。 これは、pd.to_numeric()関数を使用して行うことができます。
データフレームの列の名前を変更する
データソースは、アナリストが理解できない名前の列を転送することがよくあります。 たとえば、CTRは何らかの理由でC_T_R_finalと呼ばれる場合があります。
異なるソースからのデータをマージして全体として分析すると、別の問題が明らかになります。 最初のデータソースはインプレッションをインプと呼びますが、別のデータソースはそれをビューと呼びます。 これにより、すべてのデータソースにわたって全体像を計算して構築することが困難になります。
そのため、すべてを構造化するには、列の名前を変更する必要があります。
まず、列の将来の名前を使用して辞書を作成します。 命名規則が異なるGoogle広告とFacebook広告からのインプレッションがあると仮定します。 この場合、辞書は次のようになります。
new_clmn_names = {'Imps':'Google Ads Impressions'、
'ビュー':'Facebook広告の表示回数'}
次に、データフレームでrename()関数を使用する必要があります。
dataframe_name.rename(columns = new_clmn_names、inplace = True)
これで、列に辞書で名前が割り当てられます。
Pandasには、データの正規化に役立つさまざまな機能があります。 他の機能をよりよく理解するために、公式ドキュメントを読むことをお勧めします。
Excelでデータを正規化する方法
ExcelまたはGoogleスプレッドシートは、その使いやすさと幅広い機能により、多くのアナリストに愛されている強力なツールです。 RやPythonなどのプログラミング言語には、提供できる機能がもっとあることは間違いありませんが、スプレッドシートはデータを分析するのに非常に役立ちます。
ただし、テーブルには異種データが含まれている可能性があり、Excelには洞察を正規化するためのツールセットが用意されています。
余分なスペースのトリミング
大きなテーブルで余分なスペースを特定することは、手動で行うと時間の無駄です。 幸い、ExcelとGoogleスプレッドシートには、アナリストが1つの関数だけでデータセット内の余分なスペースを削除できるTRIM関数があります。 以下の例を見てください。

ご覧のとおり、エントリデータには単語間に大きな空白があります。 TRIM機能を使用すると、データは正しい形式になります。

データセット内の空のデータ行を削除する
空のセルは、分析中に真の悪夢にエスカレートする可能性があります。 そのため、常に事前に対処する必要があります。 その方法は次のとおりです。
- すべてのセルを選択し、ツールバーの[データ]タブをクリックします。

- 範囲の並べ替えメニューの[列で範囲を並べ替える(ZからA)]ボタンをクリックします。
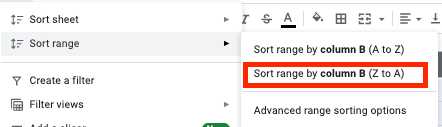
- これで、テーブルの下部にすべての空の行があるので、それらを選択して削除するだけです。
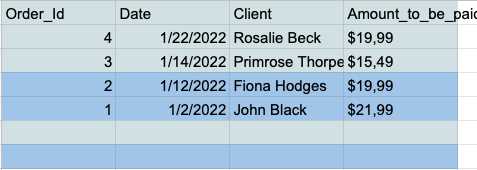
重複を削除する
重複するデータエントリは、ExcelまたはGoogleスプレッドシートで作業するアナリストにとって一般的な問題です。 そのため、これらのツールには、重複をすばやく簡単に削除するための専用機能があります。
Googleスプレッドシートには、テーブルに一意のデータのみを保持できるUNIQUE関数があります。
複数の重複を含むName列とAge列を持つこの単純なテーブルがあるとします。

データセットをUNIQUE関数にフィードすることにより、重複するエントリのないクリーンなテーブルを取得できます。

テキストケースの正規化
テキストファイルからデータをインポートした後、名前やタイトルに一貫性のないテキスト大文字小文字が含まれていることがよくあります。 次の機能を使用して、ExcelまたはGoogleスプレッドシートでデータを簡単に修正できます。
- LOWER()-すべてのテキストを小文字に変換します。
- UPPER()-すべてのテキストを大文字に変換します。
- PROPER()-すべてのテキストを適切な大文字と小文字に変換します。

特定のユースケースに応じて、ExcelまたはGoogleスプレッドシートのデータを正規化する方法はたくさんあります。 これらのガイドは、Excelデータの正規化についてより多くの光を当てています。
- Excelのデータクレンジング技術
- MicrosoftのExcelデータ正規化のヒント
自動データ正規化ツール
プログラミング言語は、データを正規化するための幅広いツールセットを提供します。 ただし、手動のデータ正規化には制限があります。
まず、アナリストには、必要なライブラリに関する強力なエンジニアリング知識と実践的な経験が必要です。 データサイエンティストとエンジニアは非常に望ましい才能であり、彼らの給料はしばしば天文学的なものです。
さらに、コーディングには時間がかかり、間違いを犯しがちです。 したがって、分析されたデータセットのフォローアップレビューは必須です。 最終的に、分析プロセスには意図したよりもはるかに長い時間がかかる可能性があります。
自動化されたツールは、アナリストの時間を節約し、より正確な結果を提供します。 データを正規化ツールに合理化し、数日ではなく数分で純粋な洞察を得ることができます。
Improvadoの例を考えてみましょう。 Improvadoは、マーケティングアナリストと営業担当者が異なるデータを調整し、洞察を1か所に保存するのに役立つ収益ETLプラットフォームです。
このプラットフォームは300以上のソースからデータを収集し、アナリストがゼロの労力でそれらを正規化するのに役立ちます。 今日のマーケティングおよび販売ツール市場は細分化されており、プラットフォームが異なれば、同様の指標に異なる命名規則が使用されます。
ImprovadoのMarketingCommonData Model(MCDM)は、一般的なデータソースの自動化されたクロスチャネルマッピング、重複排除、およびUNIONを提供する統合データモデルです。 さらに、有料メディアソースをつなぎ合わせて標準化し、分析可能な洞察をデータウェアハウスに自動的に転送します。
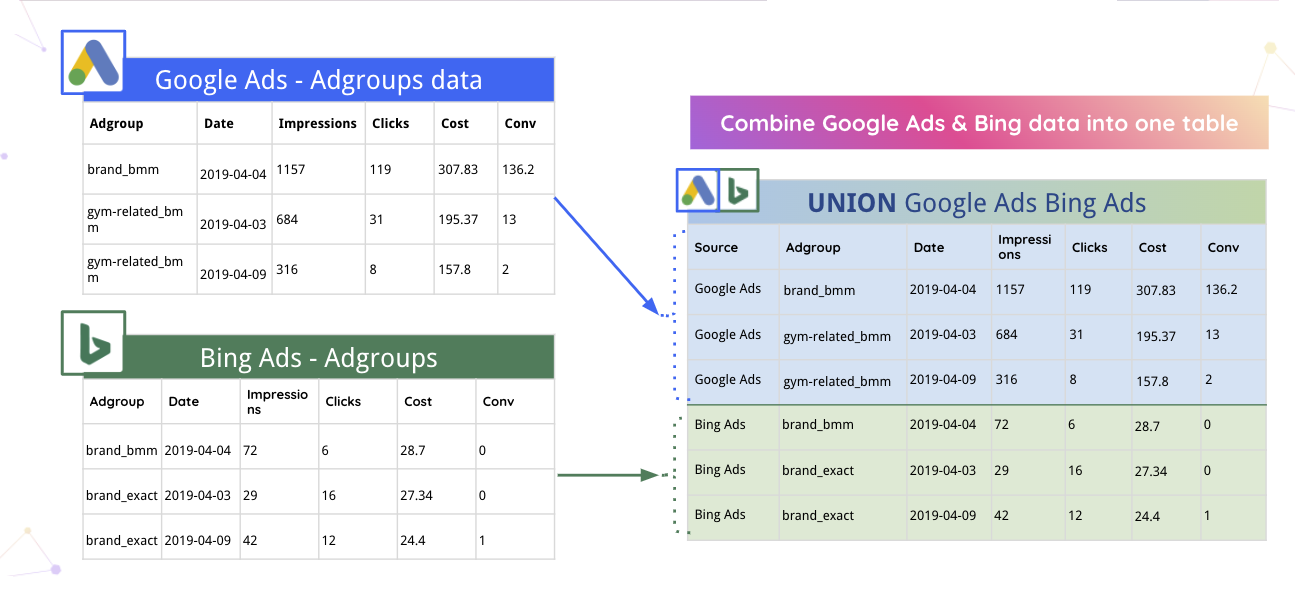
たとえば、ImprovadoはGoogle広告とBingのデータを1つのテーブルに自動的にマージできます。
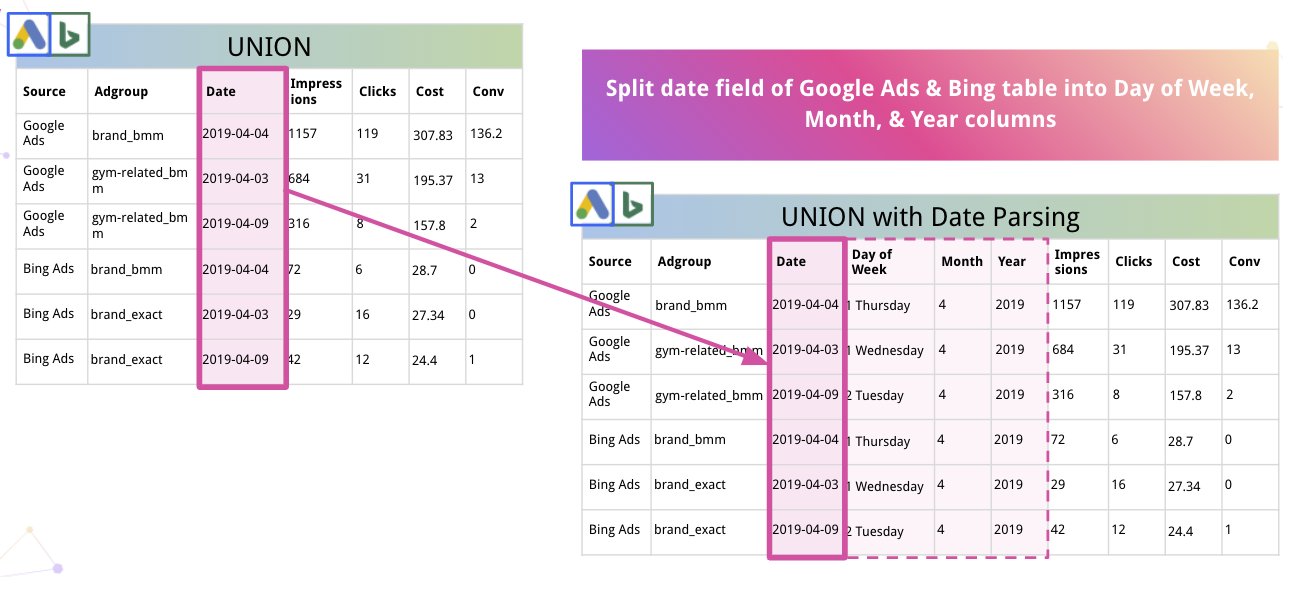
さらに、プラットフォームはデータを自動的に解析し、適切な形式に変換できます。 たとえば、Improvadoが日付を曜日、月、年の列に分割する方法は次のとおりです。
Improvadoはさらに進んで、アナリストがWebサイト上のAdobeAnalyticsトラッキングコードを自動的に解析できるようにします。 手動操作なしで、トラッキングコードから埋め込みAdGroupIDを抽出できます。
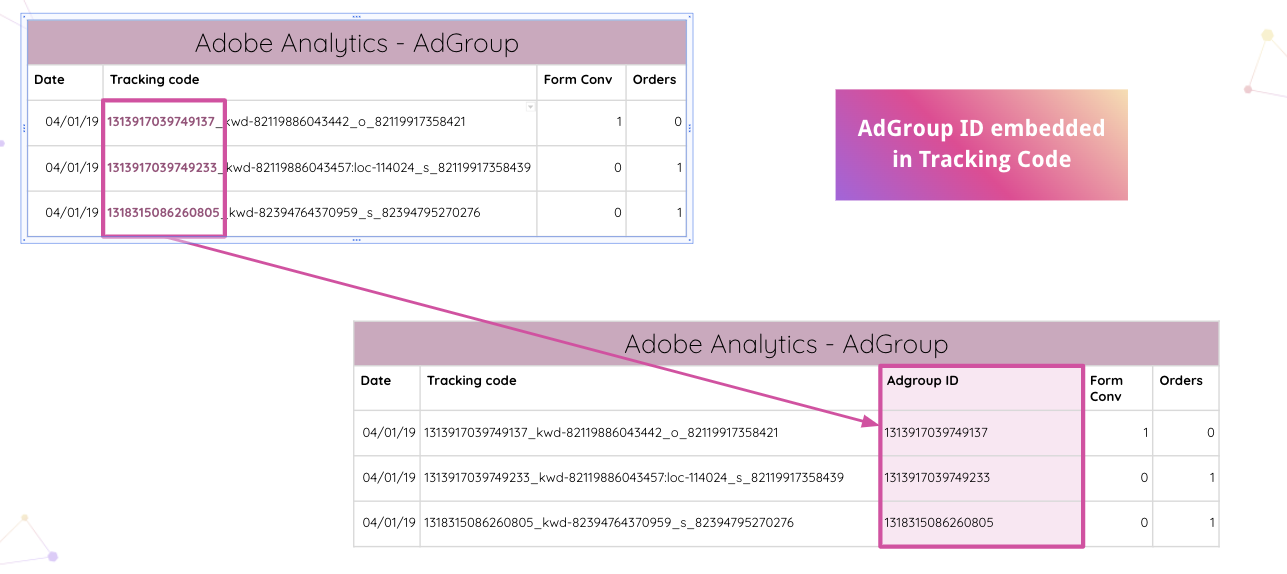
次に、アナリストは内部スプレッドシートを分類と組み合わせて、ネットワークIDに基づいてそれらを照合できます。
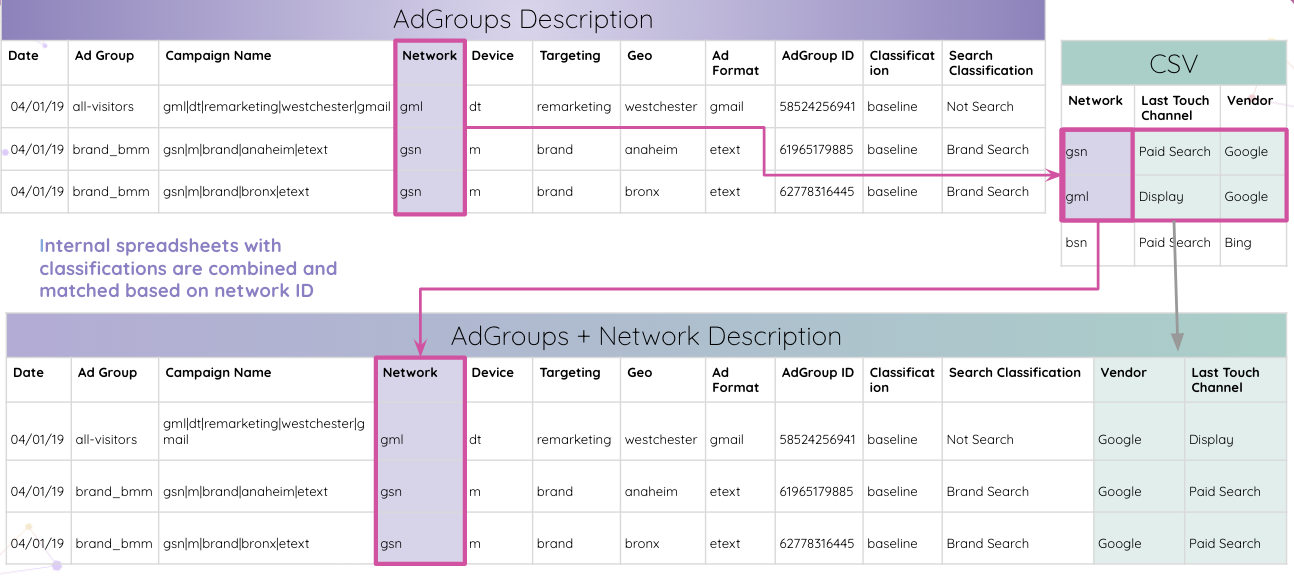
最終的に、アナリストはAdGroup IDと一致するすべてのテーブルを取得し、最終結果テーブルに結合します。

これは、Improvadoがデータを正規化し、さらなる調査のために消化可能な方法で洞察を提供できる多くのユースケースの1つにすぎません。
すべての洞察を1か所にまとめることで、プラットフォームはそれらを任意の視覚化ツールに合理化できます。 精製され構造化されたデータにより、包括的なクロスチャネルダッシュボードの構築がはるかに簡単になります。 たとえば、Improvadoの洞察に基づいたDataStudioダッシュボードは次のとおりです。
Improvadoを使用してマーケティングおよび販売データを正規化する
データの正規化には時間がかかりますが、明確な洞察は常に努力する価値があります。 分析に直接飛び込み、洞察までの時間を大幅に短縮できるのであれば、なぜデータの正規化に時間を浪費するのでしょうか。
Improvadoは、収益データのWebを解きほぐし、手動のデータ操作に費やす時間を削減し、洞察の最高の粒度を保証します。 このETLシステムを使用すると、信頼できるデータを分析し、マーケティング費用の有効性を示すリアルタイムのダッシュボードを構築できます。 詳細については、電話を予約してください。
収益ETLプラットフォームが、マーケティング目標を超え、アナリストの時間を節約するのにどのように役立つかを学びます。
