
Normalisasi Data: Mengubah Angka Mentah Menjadi Pendapatan
Diterbitkan: 2022-05-13Data adalah jantung dari semua keputusan bisnis. Itu mengelilingi kita di setiap kesempatan. Sayangnya, informasi yang Anda dapatkan langsung dari sumber data seringkali tidak terstruktur, terfragmentasi, dan menyesatkan.
Anda mungkin duduk di tumpukan data membosankan yang dapat membantu Anda menarik prospek, meningkatkan ROI, dan meningkatkan pendapatan.
Normalisasi data akan mengubah angka mentah Anda menjadi wawasan yang dapat ditindaklanjuti yang mendorong nilai.
Apa itu normalisasi data?
Untuk menggunakan beberapa kata besar, normalisasi data adalah proses pengorganisasian data sedemikian rupa agar sesuai dengan rentang tertentu atau bentuk standar. Ini membantu analis memperoleh wawasan baru, meminimalkan redundansi data, menghilangkan duplikat, dan membuat data mudah dicerna untuk analisis lebih lanjut.
Namun, kata-kata seperti itu mungkin rumit dan membingungkan, jadi mari kita bahas menjadi contoh sederhana dan ilustratif.
Bayangkan Anda seorang tukang kebun yang memanen apel. Tahun ini, Anda telah berhasil memanen 500 apel dari 20 pohon . Namun, tetangga Anda membanggakan mengumpulkan 1.000 apel dan menyebut Anda seorang tukang kebun yang buruk.
Jika Anda membandingkan 500 apel Anda dengan 1.000 apel tetangga Anda, sepertinya Anda bukan tukang kebun yang sangat terampil. Tetapi tetangga Anda tidak pernah memberi tahu Anda bahwa dia menanam seratus pohon apel untuk mendapatkan hasil seperti itu.
Jika Anda menormalkan data, terungkap bahwa tetangga Anda berada dalam situasi yang tidak menyenangkan. Dengan 500 apel dari 20 pohon, Anda memanen 25 apel per pohon , sedangkan tetangga Anda hanya mendapat 10 apel per pohon. Jadi, siapa tukang kebun yang buruk sekarang?
Analisisnya bisa dikaburkan oleh banyak data yang tidak dinormalisasi, jadi Anda tidak bisa melihat hutan untuk pepohonan.
Berikut contoh lain menggunakan data kontrol senjata. Ini menunjukkan kepada kita betapa mudahnya menjadi korban bias kognitif tanpa normalisasi data.

Tanpa wawasan yang dinormalisasi, hampir tidak mungkin untuk membangun gambaran yang komprehensif dan membuat keputusan berdasarkan informasi tentang topik yang diteliti.
Takeaways utama:
- Normalisasi data adalah proses reorganisasi data dalam kumpulan data.
- Proses ini menyederhanakan analisis lebih lanjut dan operasi data.
- Normalisasi data memastikan Anda mendapatkan pandangan komprehensif tentang topik yang diteliti.
Oke, tapi kapan Anda perlu menormalkan data?
Pengguna mengalami masalah yang berbeda sebagai akibat dari data yang heterogen (data dengan variabilitas tipe dan format data yang tinggi). Ada kasus penggunaan lain ketika Anda perlu menormalkan data. Mari kita pertimbangkan masalah ini dari perspektif analis pemasaran.
Pertama dan terpenting adalah penyatuan konvensi penamaan. Misalnya, saat mengumpulkan data dari puluhan saluran pemasaran, analis sering kali menemukan metrik yang sama dengan nama yang berbeda. Akibatnya, analis menghadapi kesulitan saat memetakan data.
Misalnya, inilah cara seorang pengguna Reddit menjelaskan masalah mereka dengan data yang berbeda.
Tantangan lain adalah mengkonsolidasikan data yang berbeda, seperti mata uang atau zona waktu, menjadi satu sumber kebenaran. Anda tidak dapat membuat dasbor yang berwawasan luas sementara pembelanjaan iklan Anda dibagi menjadi dolar, euro, pound, dan beberapa mata uang lainnya.
Begini cara pemasar lain menjelaskan masalah ini di Reddit.
Jadi, kapan waktu yang tepat untuk menormalkan data Anda?
- Saat mencocokkan metrik dalam kumpulan data Anda memiliki konvensi penamaan yang berbeda.
- Saat Anda perlu mencocokkan data heterogen, seperti mata uang, zona waktu, format tanggal, dll.
- Ketika Anda melihat beberapa data Anda berlebihan, dan Anda harus menghilangkannya.
Istilah yang sering membingungkan: normalisasi data vs. standardisasi
Dalam transformasi data, standardisasi dan normalisasi adalah dua istilah berbeda yang sering membingungkan.
Normalisasi mengubah skala nilai kumpulan data untuk membuatnya jatuh ke dalam kisaran [0,1] . Proses ini berguna ketika Anda membutuhkan semua parameter dalam skala positif.
Standardisasi menyesuaikan data Anda agar memiliki rata-rata 0 dan standar deviasi 1 . Itu tidak harus jatuh ke dalam kisaran tertentu dan jauh lebih sedikit terpengaruh oleh outlier.
Informasi ini lebih dari cukup bagi analis pemasaran untuk berhenti membingungkan istilah-istilah tersebut. Namun, jika Anda ingin mendalami topik ini, Anda dapat menemukan semua perbedaan antara kedua konsep tersebut di sini.
Cara menormalkan data dan mengumpulkan wawasan Anda
Pada intinya, normalisasi data mengharuskan Anda membuat format data standar untuk semua catatan dalam kumpulan data Anda. Algoritme Anda harus menyimpan semua data dalam format terpadu tanpa memperhatikan input.
Berikut adalah beberapa contoh normalisasi data:
- Tuan HOLmES harus disimpan sebagai Tuan Holmes.
- Fifth Avenue Sf harus disimpan sebagai 5th Ave, San Francisco.
- CTO harus disimpan sebagai Chief Technical Officer.
Membuat data Anda dinormalisasi berjalan seiring dengan normalisasi basis data. Mari kita mendapatkan gambaran singkat tentang apa itu.
Normalisasi basis data: prasyarat untuk wawasan murni
Normalisasi database adalah proses mengatur tabel dan baris data di dalam database relasional.
Prosesnya termasuk membuat dan mengelola hubungan antar tabel. Saat menormalkan database, analis dan insinyur data mengandalkan aturan yang membantu melindungi data dan membuatnya lebih fleksibel untuk analisis lebih lanjut.
Semua aturan dideklarasikan oleh tipe normalisasi database atau biasa disebut “Bentuk Normal”.
Ada tujuh Bentuk Normal secara total (tiga yang pertama adalah yang paling sering digunakan):
- Bentuk Normal Pertama (1 NF)
- Bentuk Normal Kedua (2 NF)
- Bentuk Normal Ketiga (3 NF)
- Bentuk Normal Boyce Codd (BCNF)
- Bentuk Normal Keempat (4 NF)
- Bentuk Normal Kelima (5 NF)
- Bentuk Normal Keenam (6 NF)
Mari kita lihat semua Bentuk Normal ini untuk mempelajari bagaimana mereka membantu menormalkan data Anda.
Bentuk Normal Pertama (1NF)
Bentuk Normal pertama membutuhkan tabel data untuk memenuhi kondisi berikut:
- Setiap sel tabel harus memiliki satu nilai.
- Setiap catatan harus unik.
- Tak satu pun dari kolom harus berisi nilai tersembunyi.
Mari kita tinjau sebuah contoh. Di sini kami memiliki dua catatan dari tabel karyawan.

Sel Department_Name berisi lebih dari satu parameter dalam sel. Dengan demikian, mereka melanggar aturan pertama 1NF.
Anda harus membagi tabel ini menjadi dua bagian untuk menormalkan tabel Anda dan menghapus grup yang berulang. Tabel yang dinormalisasi akan terlihat seperti ini:

Bentuk Normal Kedua dan Ketiga berkisar pada ketergantungan antara kolom kunci utama dan kolom bukan kunci.
Bentuk Normal Kedua (2NF)
Persyaratan utama dari Bentuk Normal Kedua adalah bahwa semua atribut tabel harus bergantung pada kunci utama. Dengan kata lain, semua nilai di kolom sekunder harus memiliki ketergantungan pada kolom utama.
Catatan: Kunci utama adalah nilai kolom unik yang membantu mengidentifikasi catatan database. Ini memiliki beberapa batasan dan atribut:
- Nilai kunci utama tidak boleh NULL.
- Nilai kunci utama harus selalu unik untuk setiap tabel.
Selain itu, tabel harus sudah dalam 1NF dengan semua dependensi parsial dihapus dan ditempatkan di tabel terpisah.
Pada tahap ini, kunci primer komposit menjadi masalah yang paling bermasalah.
Catatan: Kunci utama komposit adalah kunci utama yang dibuat dari dua atau lebih kolom data.
Bayangkan Anda memiliki tabel yang mencatat kursus yang telah diambil karyawan Anda. Karyawan yang berbeda dapat mendaftar di kursus yang sama. Itu sebabnya Anda memerlukan kunci komposit untuk mengidentifikasi catatan unik. Kolom Tanggal akan menjadi parameter tambahan untuk kunci komposit Anda. Lihatlah contohnya:
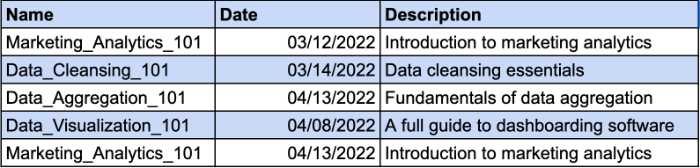
Namun, kolom Deskripsi secara fungsional bergantung pada kolom Nama. Jika Anda mengubah nama kursus, Anda juga harus mengubah deskripsinya. Jadi, Anda harus membuat tabel terpisah untuk deskripsi kursus agar sesuai dengan persyaratan 2NF.

Begitulah cara Anda dapat memberikan deskripsi kursus sebuah kunci terpisah dan menghindari penggunaan kunci komposit.
Bentuk Normal Ketiga (3NF)
Bentuk Normal ketiga membutuhkan semua kolom non-kunci di tabel Anda untuk bergantung pada kunci utama secara langsung. Dengan kata lain, jika Anda menghapus salah satu kolom non-kunci, kolom yang tersisa masih harus memberikan pengidentifikasi unik untuk setiap catatan.
Berikut adalah persyaratan utama dari 3NF:
- Semua tabel memenuhi persyaratan 2NF.
- Kolom kunci non-utama hanya boleh bergantung pada kolom kunci utama.
- Tabel tidak memiliki ketergantungan fungsional transitif.
Perbedaan utama antara 2NF dan 3NF adalah bahwa dalam 3NF, tidak ada ketergantungan transitif. Ketergantungan transitif terjadi ketika kolom non-kunci bergantung pada kolom non-kunci lainnya.
Catatan: Ketergantungan transitif adalah hubungan tidak langsung antara nilai dalam tabel yang sama yang menyebabkan ketergantungan fungsional. Sebuah ketergantungan fungsional menetapkan batasan tertentu antara atribut. Dalam hubungan ini, atribut A menentukan nilai atribut B, sedangkan B menentukan nilai A.
Perhatikan contoh di bawah ini:

Di sini, ID karyawan menentukan ID departemen dari contoh kita sebelumnya, sedangkan ID departemen menentukan nama departemen. Di sinilah ketergantungan tidak langsung antara ID karyawan dan nama departemen terjadi.
Untuk memenuhi persyaratan 3NF, kita perlu membagi tabel menjadi beberapa bagian.
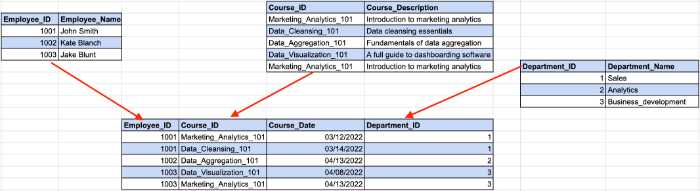
Dengan struktur ini, semua kolom bukan kunci hanya bergantung pada kunci utama.
Meskipun ada tujuh Bentuk Normal, database dianggap dinormalisasi setelah memenuhi persyaratan 3NF. Kami akan melakukan ikhtisar singkat tentang Bentuk Normal yang tersisa untuk membahas topik sampai akhir.
Bentuk Normal Boyce-Codd (BCNF)
Ini adalah versi yang lebih kuat dari 3NF. Tabel BCNF harus mematuhi semua aturan 3NF dan tidak memiliki beberapa kunci kandidat yang tumpang tindih.
Bentuk Normal Keempat (4NF)
Basis data dianggap sebagai 4NF jika salah satu instancenya berisi dua atau lebih entri data yang independen dan multinilai.
Bentuk Normal Kelima (5NF)
Sebuah tabel masuk ke dalam Bentuk Normal kelima jika memenuhi persyaratan 4NF, dan tidak dapat dipecah menjadi tabel yang lebih kecil tanpa kehilangan data.
Bentuk Normal Keenam (6NF)
Bentuk Normal keenam dimaksudkan untuk menguraikan variabel-variabel relasi menjadi komponen-komponen yang tidak dapat direduksi. Ini mungkin penting ketika berhadapan dengan variabel temporal atau data interval lainnya.
Itu saja untuk normalisasi database 101. Sekarang setelah Anda mengetahui cara kerja semuanya, Anda dapat lebih memahami manfaat normalisasi data bagi wawasan Anda.
Mengapa penting untuk menormalkan data?
Seperti yang telah kami sebutkan, tujuan dan manfaat utama normalisasi data adalah untuk mengurangi redundansi data dan inkonsistensi dalam database. Semakin sedikit duplikasi yang Anda miliki, semakin sedikit kesalahan dan masalah yang dapat terjadi selama pengambilan data.
Namun, ada manfaat yang kurang jelas yang membantu analis data dalam alur kerja mereka.
Pemetaan data bukan lagi waktu yang menyebalkan
Jika Anda pernah harus berurusan dengan data yang tidak dinormalisasi, Anda tahu bahwa proses pemetaan data dari beberapa tabel menjadi satu cukup membosankan.
Ini membutuhkan penggabungan beberapa tabel, menangani duplikat, dan membersihkan banyak entri data kosong.
Tentu saja, Anda dapat menormalkan data secara manual dengan menulis kueri SQL atau skrip Python. Namun, alat pemetaan data dengan kemampuan normalisasi data otomatis akan mempercepat prosesnya.
Misalnya, Oracle Integration Cloud menawarkan fungsionalitas pemetaan data. Setelah menormalkan data di cloud, alat tersebut kemudian membangun metadata untuk skema sumber dan membuat catatan satu-ke-satu untuk setiap objek data dalam skema target.
Analis yang bekerja dengan wawasan pemasaran memiliki permata tersembunyi mereka sendiri. MCDM (Marketing Common Data Model) dari Improvado adalah pisau tentara Swiss untuk normalisasi data pemasaran dan penjualan. Alat ini menyatukan konvensi penamaan yang berbeda, menormalkan wawasan Anda, dan menjembatani kesenjangan antara sumber data dan tujuan Anda tanpa memerlukan tindakan manual.
️ Temukan alat pemetaan data yang tepat untuk kebutuhan Anda dengan daftar lengkap kami ️
Gunakan penyimpanan data dengan lebih efisien
Setiap hari, perusahaan mengumpulkan semakin banyak data yang menghabiskan ruang penyimpanan. Baik Anda menggunakan penyimpanan cloud atau gudang data lokal, Anda harus menggunakannya secara efektif.
Misalnya, 100 TB data yang disimpan di AWS S3 akan dikenakan biaya $2.580 per bulan. Terlebih lagi, Amazon akan menagih Anda untuk setiap kueri yang Anda lakukan pada data Anda. Puluhan gigabyte data yang berlebihan tidak hanya akan meningkatkan tagihan Anda untuk layanan penyimpanan, tetapi juga menyebabkan Anda membayar untuk analisis wawasan yang tidak berarti.
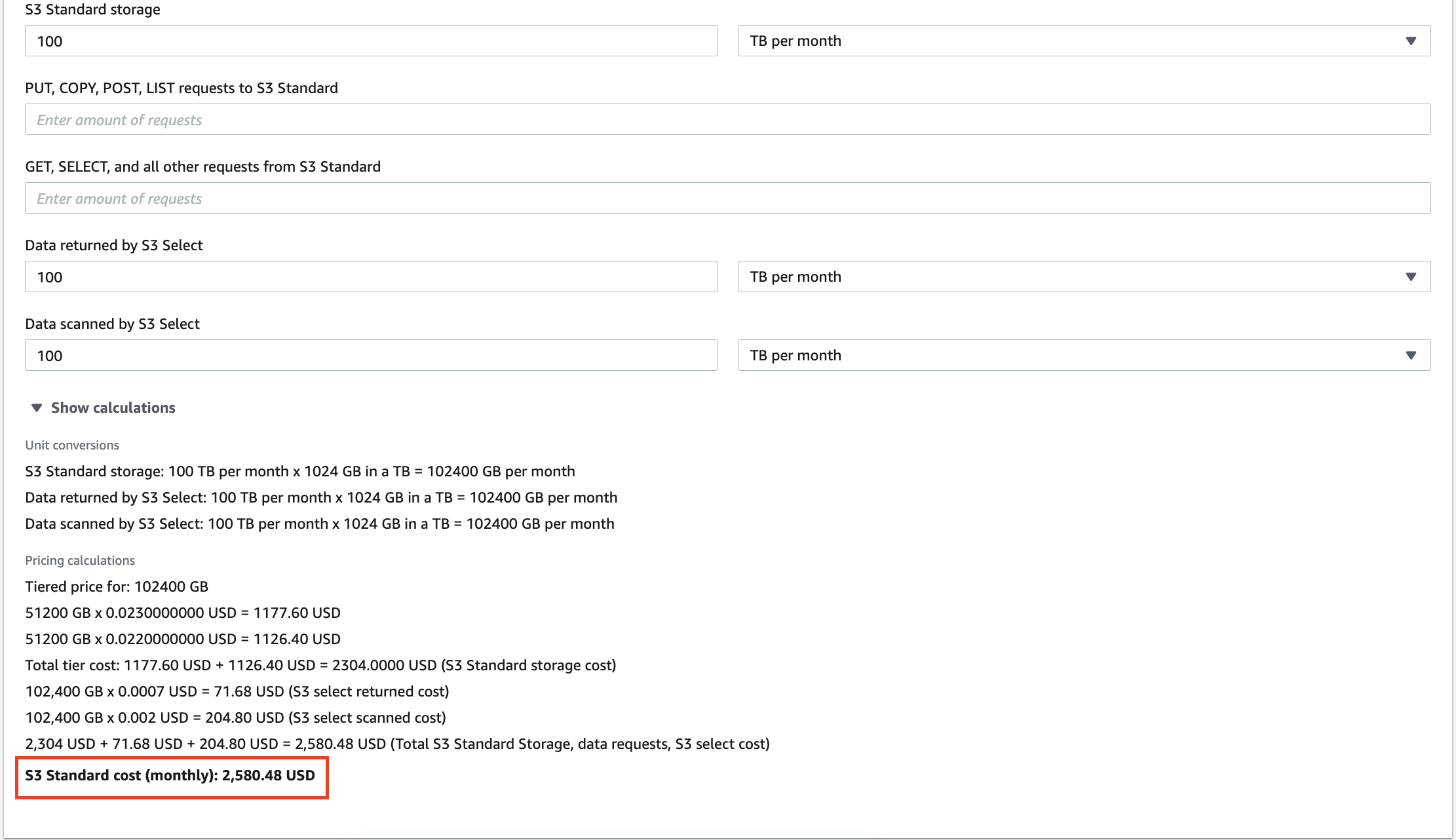
Menskalakan gudang data lokal juga mahal, jadi menghapus informasi yang tidak perlu dapat membantu Anda mengurangi biaya operasional dan TCO (Total Cost of Ownership).

Kurangi waktu Anda untuk mendapatkan wawasan
Selain pengurangan biaya, analis juga dapat meningkatkan produktivitas analisis mereka.
Menjalankan kueri pada terabyte data membutuhkan waktu. Saat sistem Anda memproses kueri, Anda dapat menikmati secangkir kopi dan mendiskusikan politik dengan kolega Anda. Tetapi sangat disayangkan ketika output kueri tidak ada gunanya karena Anda memiliki beberapa inkonsistensi dalam kumpulan data Anda.
Dengan data yang dinormalisasi, Anda selalu mendapatkan keluaran yang diharapkan, tetapi tanpa kejutan seperti "N/A", "NaN", "NULL", dll. Selain itu, sistem menjalankan kueri Anda lebih cepat saat Anda hanya menguraikan data yang relevan. Siapa tahu, mungkin lain kali Anda akan mendapatkan hasilnya sebelum mesin kopi Anda membuat cappuccino Anda!
Bangun dasbor yang dapat Anda percayai
Visualisasi data adalah cara terbaik untuk membangun gambaran komprehensif tentang upaya analisis Anda. Namun, dasbor tidak memiliki nilai jika Anda membuatnya berdasarkan data kasar. Dasbor tidak akan mencerminkan keadaan sebenarnya jika Anda memberinya duplikat.
Itulah mengapa normalisasi data menjadi prioritas utama jika Anda ingin menjelaskan konsep kompleks atau indikator kinerja melalui prisma bagan dan batang warna-warni.
Cara menormalkan data di lingkungan yang berbeda
Karena analis data bekerja dengan alat yang berbeda, kami akan menjelaskan cara menormalkan data di lingkungan yang paling banyak diminati di pasar saat ini.
Cara menormalkan data dengan Python
Ilmuwan dan analis data yang bekerja dengan Python menggunakan beberapa perpustakaan untuk memanipulasi data dan merapikannya. Berikut adalah yang paling populer di antara mereka:
- panda
- numpy
- TensorFlow
Kami akan meninjau beberapa fungsi pustaka ini yang mungkin membantu Anda mempercepat proses normalisasi data Anda.
Menjatuhkan kolom di kumpulan data Anda
Data mentah sering mengandung kategori yang berlebihan atau tidak perlu. Misalnya, Anda bekerja dengan kumpulan data metrik pemasaran yang mencakup tayangan, BPK, RKT, ROAS, dan konversi, tetapi Anda hanya memerlukan konversi dari tabel ini.
Jika segala sesuatu selain konversi tidak penting untuk analisis, Anda perlu menghapus kolom yang berlebihan. Pandas menawarkan cara mudah untuk menghapus kolom dari kumpulan data dengan fungsi drop().
Pertama, Anda harus menentukan daftar kolom yang ingin Anda jatuhkan. Dalam kasus kami, itu akan terlihat seperti ini:
column_drop_list = ['Tayangan, 'BPK', 'RKT', 'ROAS']
Kemudian, Anda perlu menjalankan fungsi:
dataframe_name.drop(column_drop_list, inplace=True, axis=1)
Dalam baris kode ini, parameter pertama adalah nama dari daftar kolom kami. Menyetel parameter inplace ke True berarti Pandas akan menerapkan perubahan langsung ke objek Anda. Parameter ketiga menunjukkan apakah akan melepaskan label atau kolom dari bingkai data ('0' berarti label, '1' berarti kolom).
Setelah memeriksa kumpulan data lagi, Anda akan melihat bahwa semua kolom yang berlebihan telah berhasil dihapus.
Membersihkan bidang data
Langkah lainnya adalah merapikan bidang data. Ini membantu meningkatkan konsistensi data dan memasukkan data ke dalam format standar.
Masalah utama di sini adalah Anda tidak yakin bahwa API dari platform pemasaran akan mentransfer data yang 100% akurat. Anda masih dapat menemukan karakter yang salah tempat atau data yang menyesatkan.
Satu kampanye pemasaran hanya dapat memiliki satu jumlah tayangan. Itu sebabnya kita perlu memisahkan angka berharga dari karakter lain.
Ekspresi reguler (regex) dapat membantu Anda mengidentifikasi semua digit di dalam kumpulan data Anda. Generator regex ini akan membantu Anda membuat ekspresi reguler untuk kebutuhan Anda dan langsung mengujinya.
Kemudian, dengan bantuan fungsi str.extract(), kita dapat mengekstrak data yang diperlukan dari kumpulan data sebagai kolom.
true_impressions = dataframe_name.str.extract(your_regex) , expand = False)
Terakhir, Anda mungkin perlu mengonversi kolom ke versi numerik. Karena semua kolom dalam bingkai data memiliki tipe objek, mengubahnya menjadi nilai numerik akan menyederhanakan perhitungan lebih lanjut. Anda dapat melakukan ini dengan bantuan fungsi pd.to_numeric() .
Mengganti nama kolom dalam bingkai data
Sumber data sering kali mentransfer kolom dengan nama yang tidak dapat dipahami oleh analis. Misalnya, RKT mungkin disebut C_T_R_final karena alasan tertentu.
Masalah lain terungkap saat Anda menggabungkan data dari sumber yang berbeda dan menganalisisnya secara keseluruhan. Sementara sumber data pertama mengacu pada tayangan sebagai tayangan, sumber lain menyebutnya tampilan. Hal ini membuat sulit untuk menghitung dan membangun gambaran holistik di semua sumber data.
Itu sebabnya Anda perlu mengganti nama kolom Anda agar semuanya terstruktur.
Pertama, buat kamus dengan nama masa depan kolom Anda. Mari kita asumsikan bahwa kita memiliki tayangan dari Google Ads dan Facebook Ads dengan konvensi penamaan yang berbeda. Dalam hal ini, kamus kami akan terlihat seperti berikut:
new_clmn_names = {'Tayangan' : 'Tayangan Iklan Google',
'Tampilan': 'Tayangan Iklan Facebook'}
Kemudian, Anda harus menggunakan fungsi rename() pada bingkai data Anda:
dataframe_name.rename(columns=new_clmn_names, inplace=True)
Sekarang, kolom Anda akan memiliki nama yang ditetapkan dalam kamus.
Pandas memiliki lebih banyak fungsi berbeda yang dapat membantu Anda menormalkan data. Kami merekomendasikan membaca dokumentasi resmi untuk mendapatkan pemahaman yang lebih baik tentang fungsi lainnya.
Cara menormalkan data di Excel
Excel atau Google Sheets adalah alat canggih yang disukai oleh banyak analis karena kemudahan penggunaan dan kemampuannya yang luas. Tidak diragukan lagi bahwa bahasa pemrograman, seperti R atau Python, memiliki lebih banyak fitur untuk ditawarkan, tetapi spreadsheet melakukan pekerjaan yang baik dalam menganalisis data.
Namun, tabel Anda mungkin berisi data yang heterogen, dan Excel menyediakan seperangkat alat untuk menormalkan wawasan.
Memangkas ruang ekstra
Mengidentifikasi ruang yang berlebihan dalam tabel besar adalah buang-buang waktu jika dilakukan secara manual. Untungnya, Excel dan Google Sheets memiliki fungsi TRIM yang memungkinkan analis menghapus spasi ekstra dalam kumpulan data hanya dengan satu fungsi. Lihatlah contoh di bawah ini.

Seperti yang Anda lihat, data entri memiliki spasi putih besar di antara kata-kata. Dengan fungsi TRIM, data dimasukkan ke dalam format yang tepat.

Menghapus baris data kosong di kumpulan data
Sel kosong dapat meningkat menjadi mimpi buruk selama analisis. Itu sebabnya Anda harus selalu berurusan dengan mereka sebelumnya. Berikut cara melakukannya.
- Pilih semua sel dan klik tab "Data" di bilah alat.

- Klik tombol "Urutkan rentang menurut kolom (Z ke A)" di menu rentang urutkan.
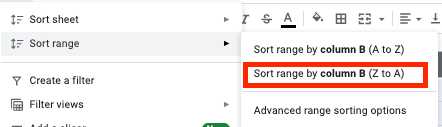
- Sekarang Anda memiliki semua baris kosong di bagian bawah tabel Anda, jadi Anda cukup memilih dan menghapusnya.
Menghapus duplikat
Entri data duplikat adalah masalah umum bagi analis yang bekerja di Excel atau Google Spreadsheet. Itu sebabnya alat ini memiliki fitur khusus untuk menghapus duplikat dengan cara yang cepat dan mudah.
Google Spreadsheet memiliki fungsi UNIK yang memungkinkan Anda menyimpan hanya data unik di tabel Anda.
Misalkan Anda memiliki tabel sederhana ini dengan kolom Nama dan Usia yang berisi banyak duplikat.

Anda bisa mendapatkan tabel yang bersih tanpa entri duplikat dengan memasukkan kumpulan data Anda ke fungsi UNIK.

Normalisasi kasus teks
Setelah mengimpor data dari file teks, Anda akan sering menemukan kasus teks yang tidak konsisten dalam nama atau judul. Anda dapat dengan mudah memperbaiki data Anda di Excel atau Google Spreadsheet dengan menggunakan fitur berikut:
- LOWER() - Mengubah semua teks menjadi huruf kecil.
- UPPER() - Mengubah semua teks menjadi huruf besar.
- PROPER() - Mengonversi semua teks menjadi huruf besar/kecil.

Bergantung pada kasus penggunaan khusus Anda, ada banyak cara untuk menormalkan data Excel atau Google Spreadsheet. Panduan ini menjelaskan lebih lanjut tentang normalisasi data Excel:
- Teknik pembersihan data Excel
- Kiat normalisasi data Microsoft Excel
Alat normalisasi data otomatis
Bahasa pemrograman menawarkan perangkat yang luas untuk menormalkan data Anda. Namun, normalisasi data manual memiliki keterbatasan.
Pertama-tama, analis membutuhkan pengetahuan teknik yang kuat dan pengalaman langsung dengan perpustakaan yang diperlukan. Ilmuwan dan insinyur data adalah bakat yang sangat diinginkan, dan gaji mereka seringkali sangat besar.
Selain itu, pengkodean membutuhkan waktu, dan sering kali rentan terhadap kesalahan. Jadi, tinjauan tindak lanjut dari kumpulan data yang dianalisis harus dimiliki. Akhirnya, proses analisis mungkin memakan waktu lebih lama dari yang dimaksudkan.
Alat otomatis menghemat waktu analis dan menawarkan hasil yang lebih tepat. Anda dapat menyederhanakan data Anda ke alat normalisasi dan mendapatkan wawasan murni dalam hitungan menit, bukan hari.
Mari kita perhatikan contoh Improvado. Improvado adalah platform ETL pendapatan yang membantu analis pemasaran dan staf penjualan menyelaraskan data mereka yang berbeda dan menyimpan wawasan di satu tempat.
Platform mengumpulkan data dari 300+ sumber dan membantu analis untuk menormalkannya tanpa usaha. Pasar alat pemasaran dan penjualan saat ini terfragmentasi, dan platform yang berbeda menggunakan konvensi penamaan yang berbeda untuk metrik yang serupa.
Marketing Common Data Model (MCDM) Improvado adalah model data terpadu yang menyediakan pemetaan lintas saluran otomatis, deduping, dan penyatuan sumber data populer. Selain itu, ini menyatukan dan menstandardisasi sumber media berbayar bersama-sama, secara otomatis mentransfer wawasan siap analisis ke gudang data Anda.
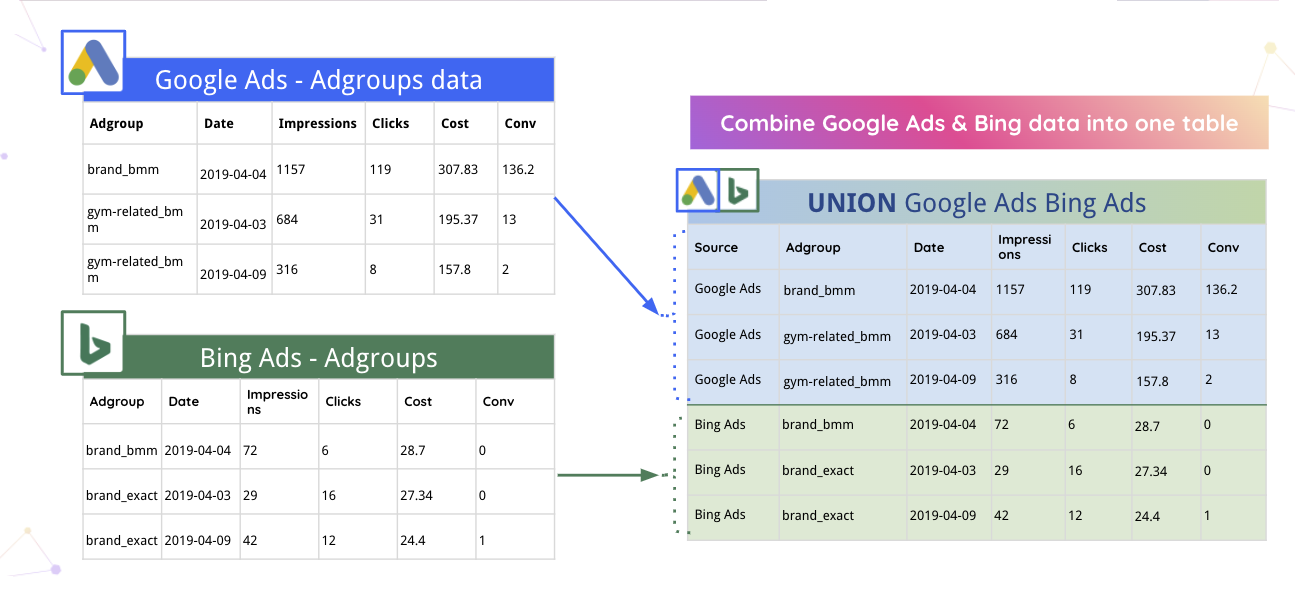
Misalnya, Improvado dapat secara otomatis menggabungkan data Google Ads dan Bing ke dalam satu tabel.
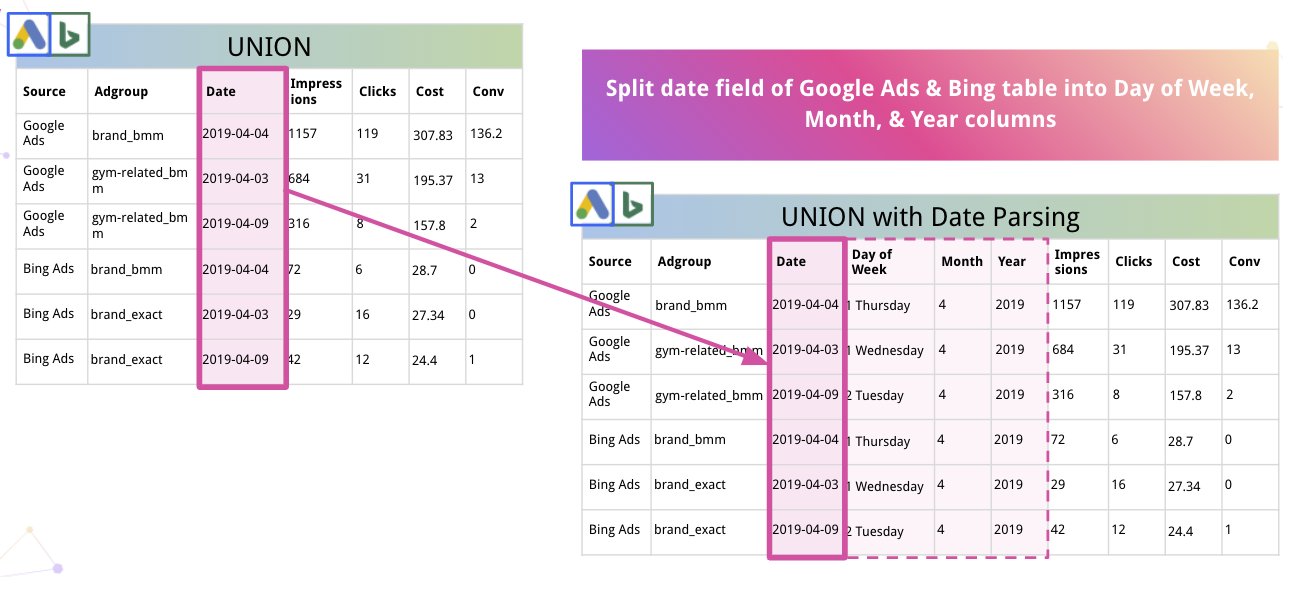
Selanjutnya, platform dapat secara otomatis mengurai data dan mengonversinya ke format yang sesuai. Misalnya, inilah cara Improvado membagi Tanggal menjadi kolom Hari dalam Minggu, Bulan, dan Tahun.
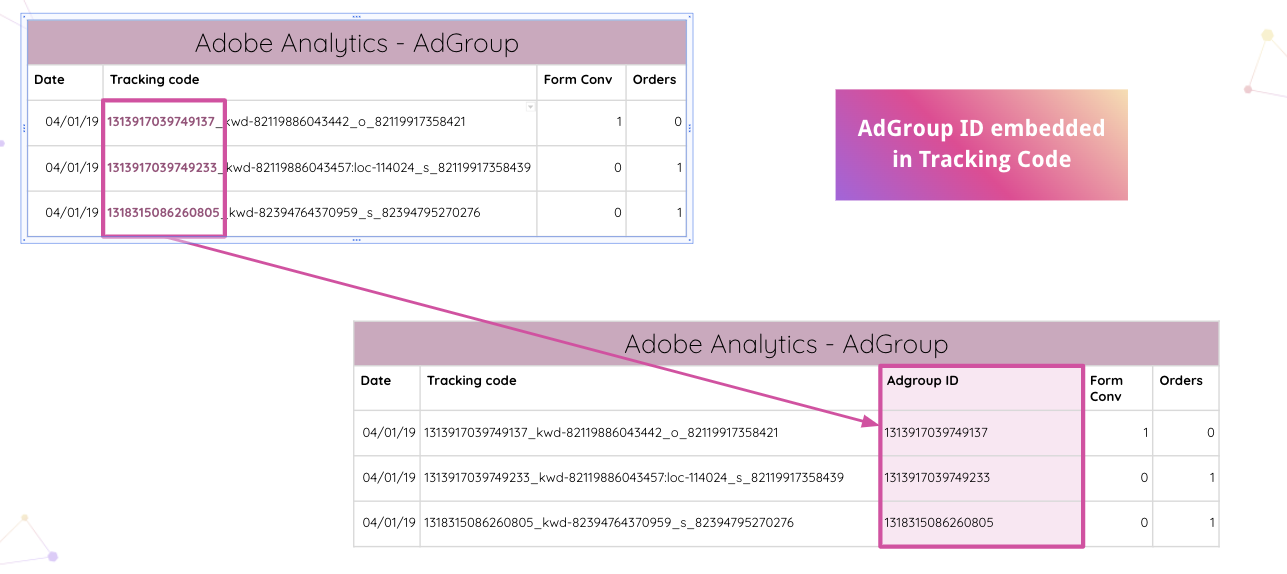
Improvado bahkan melangkah lebih jauh, memungkinkan analis untuk secara otomatis mengurai kode pelacakan Adobe Analytics di situs web Anda. Anda dapat mengekstrak ID AdGroup yang disematkan dari kode pelacakan tanpa manipulasi manual.
Kemudian, analis dapat menggabungkan spreadsheet internal dengan klasifikasi dan mencocokkannya berdasarkan ID jaringan.
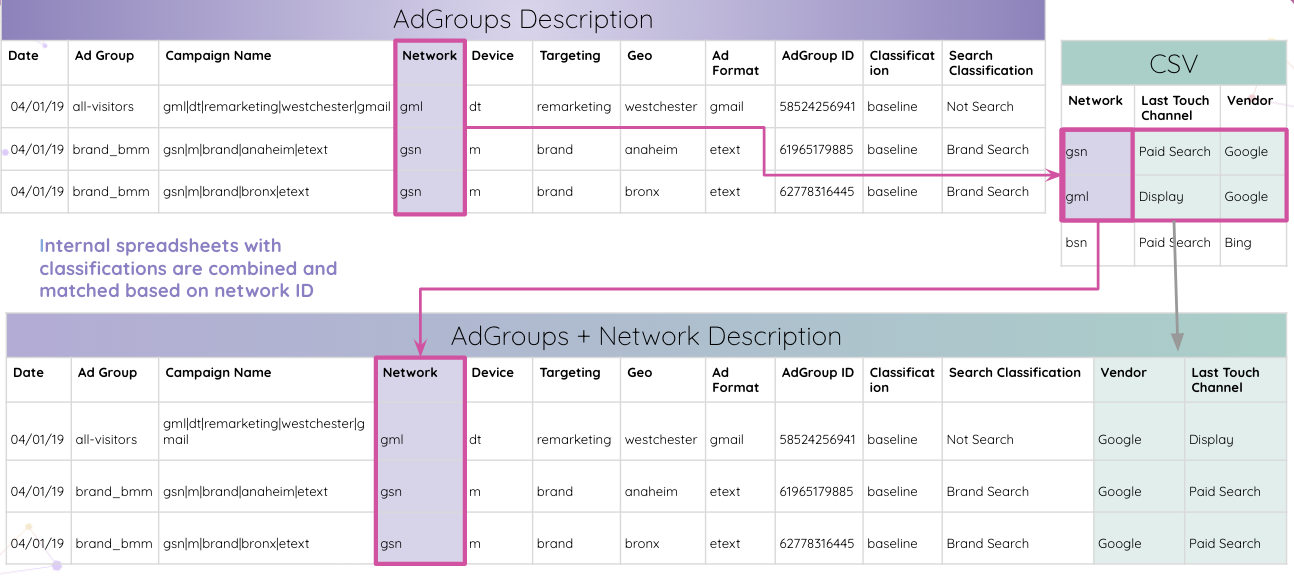
Akhirnya, analis mendapatkan semua tabel yang cocok dengan ID AdGroup dan digabungkan ke dalam tabel hasil akhir.

Itu hanyalah salah satu dari banyak kasus penggunaan di mana Improvado dapat menormalkan data dan memberikan wawasan dengan cara yang mudah dicerna untuk penelitian lebih lanjut.
Dengan semua wawasan di satu tempat, platform dapat merampingkannya ke alat visualisasi apa pun pilihan Anda. Data yang dimurnikan dan terstruktur membuat pembuatan dasbor lintas saluran yang komprehensif menjadi lebih mudah. Misalnya, berikut adalah dasbor Data Studio berdasarkan wawasan Improvado:
Normalisasikan data pemasaran dan penjualan dengan Improvado
Normalisasi data membutuhkan waktu, tetapi wawasan yang jelas selalu sepadan dengan usaha. Mengapa membuang waktu Anda untuk normalisasi data jika Anda dapat langsung terjun ke analisis dan secara dramatis memangkas waktu Anda untuk memahami?
Improvado menguraikan data pendapatan web Anda, mengurangi waktu yang dihabiskan untuk manipulasi data manual, dan memastikan perincian wawasan tertinggi. Dengan sistem ETL ini, Anda dapat menganalisis data yang dapat dipercaya dan membangun dasbor waktu nyata yang menunjukkan efektivitas uang pemasaran Anda. Jadwalkan panggilan untuk mempelajari lebih lanjut.
Pelajari bagaimana platform ETL pendapatan dapat membantu Anda melampaui sasaran pemasaran dan menghemat waktu waktu analis Anda.
