
數據規範化:將原始數字轉化為收入
已發表: 2022-05-13數據是所有業務決策的核心。 它每時每刻都圍繞著我們。 不幸的是,您直接從數據源獲得的信息通常是非結構化的、碎片化的和誤導性的。
您可能正坐在一堆枯燥無味的數據上,這些數據可以幫助您吸引潛在客戶、提高投資回報率並增加收入。
數據規範化會將您的原始數據轉化為推動價值的可行見解。
什麼是數據規範化?
用一些大詞來說,數據規範化是組織數據以使其適合特定範圍或標準形式的過程。 它可以幫助分析師獲得新的見解,最大限度地減少數據冗餘,消除重複數據,並使數據易於消化以進行進一步分析。
但是,這樣的措辭可能會很複雜和令人困惑,所以讓我們將其歸結為一個簡單且具有說明性的示例。
想像一下,你是一個收割蘋果的園丁。 今年,您已經從 20 棵樹上收穫了 500 個蘋果。 然而,你的鄰居吹噓自己收集了1000 個蘋果,並稱你為糟糕的園丁。
如果您將您的 500 個蘋果與您鄰居的 1,000 個蘋果進行比較,您可能看起來不是一個非常熟練的園丁。 但是你的鄰居從來沒有告訴你,他種了一百棵蘋果樹來達到這樣的產量。
如果你對數據進行標準化,就會發現你的鄰居處於不愉快的境地。 從 20 棵樹上摘下 500 個蘋果,你每棵樹收穫 25 個蘋果,而你的鄰居每棵樹只能收穫 10 個蘋果。 那麼,現在誰是一個糟糕的園丁?
大量非標準化數據會使分析變得混亂,因此您無法只見樹木不見森林。
這是另一個使用槍支控制數據的示例。 它向我們展示了在沒有數據規範化的情況下成為認知偏差的受害者是多麼容易。

如果沒有規範化的見解,幾乎不可能建立全面的圖景並就研究主題做出明智的決定。
關鍵要點:
- 數據規範化是對數據集中的數據進行重組的過程。
- 這個過程簡化了進一步的分析和數據操作。
- 數據規範化可確保您全面了解所研究的主題。
好的,但是什麼時候需要標準化數據呢?
由於異構數據(數據類型和格式的高度可變性的數據),用戶會遇到不同的問題。 當您需要規範化數據時,還有其他用例。 讓我們從營銷分析師的角度來考慮這個問題。
首先是命名約定的統一。 例如,在從數十個營銷渠道收集數據時,分析師經常會遇到不同名稱的相同指標。 因此,分析師在映射數據時面臨困難。
例如,這裡是一位 Reddit 用戶如何解釋他們對不同數據的問題。
另一個挑戰是將不同的數據(例如貨幣或時區)整合到單一的事實來源中。 當您的廣告支出分為美元、歐元、英鎊和其他幾種貨幣時,您根本無法構建一個有洞察力的儀表板。
以下是另一位營銷人員在 Reddit 上描述此問題的方式。
那麼,什麼時候是規範化數據的合適時間呢?
- 當數據集中的匹配指標具有不同的命名約定時。
- 當您需要匹配異構數據時,例如貨幣、時區、日期格式等。
- 當您注意到您的某些數據是多餘的,您需要將其刪除。
經常混淆的術語:數據規範化與標準化
在數據轉換中,標準化和規範化是兩個經常混淆的不同術語。
歸一化重新調整數據集的值,使它們落入 [0,1] 的範圍內。 當您需要所有參數都在正範圍內時,此過程很有用。
標準化將您的數據調整為平均值為 0 和標準差為 1 。 它不必落入特定範圍,並且受異常值的影響要小得多。
這些信息足以讓營銷分析師停止混淆條款。 但是,如果您想更深入地研究這個主題,您可以在這裡找到這兩個概念之間的所有差異。
如何規範化數據並將您的見解整合在一起
從本質上講,數據規範化要求您為數據集中的所有記錄創建標準數據格式。 您的算法應該以統一格式存儲所有數據,而不考慮輸入。
以下是數據規範化的一些示例:
- 福爾摩斯先生應該以福爾摩斯先生的身份存儲。
- Fifth Avenue Sf應存儲為5th Ave, San Francisco。
- CTO應存儲為首席技術官。
使您的數據規範化與數據庫規範化密切相關。 讓我們簡要概述一下它是什麼。
數據庫規範化:提純洞察的先決條件
數據庫規範化是在關係數據庫中組織表和數據行的過程。
該過程包括創建和管理表之間的關係。 在規範化數據庫時,分析師和數據工程師依賴有助於保護數據並使其更靈活地進行進一步分析的規則。
所有規則都由數據庫規範化類型或所謂的“規範形式”聲明。
一共有七種範式(前三種是最常用的):
- 第一範式 (1 NF)
- 第二範式 (2 NF)
- 第三範式 (3 NF)
- Boyce Codd 範式 (BCNF)
- 第四範式 (4 NF)
- 第五範式 (5 NF)
- 第六範式 (6 NF)
讓我們瀏覽所有這些範式,了解它們如何幫助規範化您的數據。
第一範式 (1NF)
第一個範式要求數據表滿足以下條件:
- 每個表格單元格都應該有一個值。
- 每條記錄都應該是唯一的。
- 任何列都不應包含隱藏值。
讓我們回顧一個例子。 這裡我們有兩條來自員工表的記錄。

Department_Name 單元格在一個單元格中包含多個參數。 因此,它們違反了 1NF 的第一條規則。
您必須將此表拆分為兩部分以規範化您的表並刪除重複組。 規範化的表將如下所示:

第二和第三範式圍繞主鍵列和非鍵列之間的依賴關係展開。
第二範式 (2NF)
第二範式的主要要求是表的所有屬性都應該依賴於主鍵。 換句話說,輔助列中的所有值都應該依賴於主列。
注意:主鍵是有助於識別數據庫記錄的唯一列值。 它有一些限制和屬性:
- 主鍵值不能為 NULL。
- 每個表的主鍵值應該始終是唯一的。
此外,該表必須已經在 1NF 中,並刪除了所有部分依賴項並放置在單獨的表中。
在這個階段,複合主鍵成為最成問題的問題。
注意:複合主鍵是由兩個或多個數據列組成的主鍵。
讓我們想像一下,您有一個表格來記錄您的員工所學的課程。 不同的員工可以參加同一課程。 這就是為什麼您需要一個複合鍵來識別唯一記錄。 Date 列將是您的複合鍵的附加參數。 看一下這個例子:
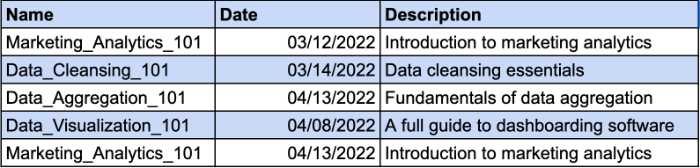
但是,描述列在功能上依賴於名稱列。 如果您更改課程名稱,您還應該更改描述。 因此,您需要為課程描述創建一個單獨的表,以符合 2NF 要求。

這就是您可以為課程描述提供一個單獨的鍵並避免使用複合鍵的方式。
第三範式 (3NF)
第三種範式要求表中的所有非鍵列都直接依賴於主鍵。 換句話說,如果您刪除任何非鍵列,其餘列仍應為每條記錄提供唯一標識符。
以下是 3NF 的主要要求:
- 所有表格均符合 2NF 要求。
- 非主鍵列應該只依賴於主鍵列。
- 表沒有傳遞函數依賴。
2NF 和 3NF 的主要區別在於,在 3NF 中,沒有傳遞依賴。 當非鍵列依賴於另一個非鍵列時,存在傳遞依賴。
注意:傳遞依賴是同一個表中的值之間的間接關係,它會導致函數依賴。 功能依賴設置屬性之間的特定約束。 在這種關係中,屬性 A 決定屬性 B 的值,而 B 決定 A 的值。
看看下面的例子:

在這裡,員工 ID 確定我們前面示例中的部門 ID,而部門 ID 確定部門名稱。 這是員工 ID 和部門名稱之間存在間接依賴關係的地方。
為了符合 3NF 要求,我們需要將表拆分為多個部分。
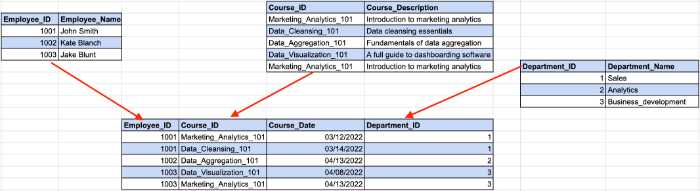
使用這種結構,所有非鍵列僅依賴於主鍵。
即使有 7 種範式,數據庫在符合 3NF 要求後也被認為是規範化的。 我們將對剩餘的範式進行快速概述,以將主題涵蓋到最後。
Boyce-Codd 範式 (BCNF)
它是 3NF 的更強大的版本。 BCNF 表應該符合所有 3NF 規則並且沒有多個重疊的候選鍵。
第四範式 (4NF)
如果數據庫的任何實例包含兩個或多個獨立和多值數據條目,則該數據庫被視為 4NF。
第五範式 (5NF)
如果一個表符合 4NF 要求,它就屬於第五範式,並且它不能被拆分成更小的表而不丟失數據。
第六範式 (6NF)
第六範式旨在將關係變量分解為不可約的分量。 在處理時間變量或其他區間數據時,這可能很重要。
這就是數據庫規範化 101 的全部內容。現在您知道一切是如何工作的,您可以更好地了解數據規範化為您的洞察力帶來的好處。
為什麼規範化數據很重要?
正如我們已經提到的,數據規範化的主要目標和好處是減少數據庫中的數據冗餘和不一致。 您擁有的重複越少,數據檢索過程中可能發生的錯誤和問題就越少。
但是,在數據分析師的工作流程中幫助數據分析師的好處並不明顯。
數據映射不再是時間差
如果您曾經處理過非規範化數據,您就會知道將數據從多個表映射到一個表的過程非常繁瑣。
它需要連接多個表、處理重複項並清理許多空數據條目。
當然,您可以通過編寫 SQL 查詢或 Python 腳本手動規範化數據。 但是,具有自動數據規範化功能的數據映射工具將加快這一過程。
例如,Oracle 集成雲提供數據映射功能。 在對雲中的數據進行規範化之後,該工具會為源模式構建元數據,並為目標模式中的每個數據對象創建一對一的記錄。
處理營銷洞察力的分析師有他們自己隱藏的寶石。 Improvado 的 MCDM(營銷通用數據模型)是用於營銷和銷售數據規範化的瑞士軍刀。 該工具統一了不同的命名約定,規範了您的見解,並彌合了數據源和目標之間的差距,無需手動操作。
️ 通過我們廣泛的列表找到滿足您需求的正確數據映射工具️
更有效地使用數據存儲
隨著時間的推移,公司收集的數據越來越多,佔用了存儲空間。 無論您使用雲存儲還是本地數據倉庫,您都必須有效地使用它。
例如,存儲在 AWS S3 中的 100 TB 數據每月將花費您2,580 美元。 更重要的是,亞馬遜會為您對數據執行的每次查詢收費。 數十 GB 的冗餘數據不僅會增加您的存儲服務發票,還會導致您為分析無意義的見解付費。
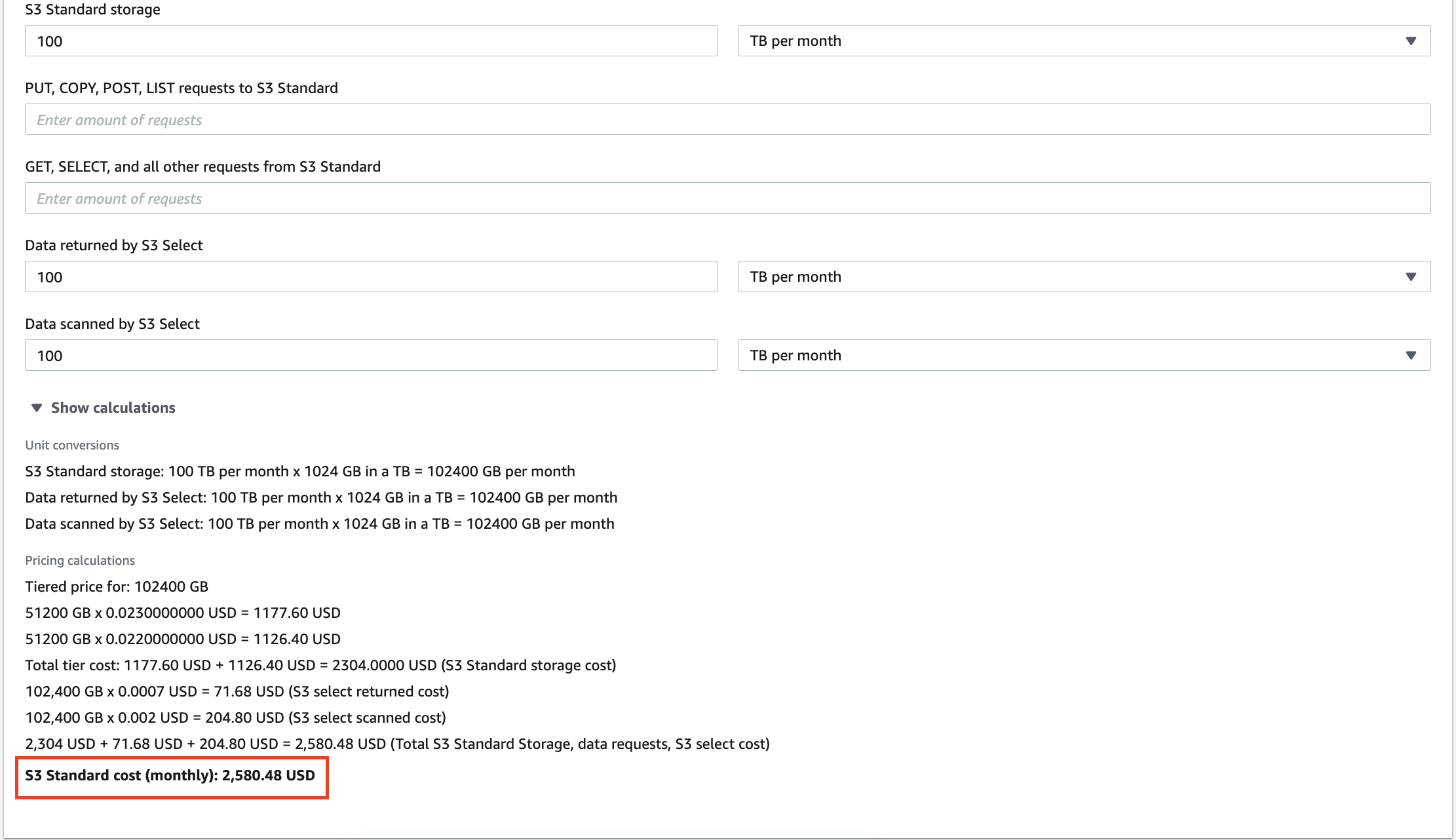
擴展本地數據倉庫也很昂貴,因此清除不必要的信息可以幫助您降低運營成本和 TCO(總擁有成本)。
縮短獲得洞察力的時間
除了降低成本外,分析師還可以提高他們的分析效率。
對 TB 級數據執行查詢需要時間。 在您的系統處理查詢時,您可以隨意喝杯咖啡並與同事討論政治。 但遺憾的是,當您的數據集中存在一些不一致時,查詢輸出毫無意義。
使用規範化的數據,您總是會得到預期的輸出,但不會出現“N/A”、“NaN”、“NULL”等意外。此外,當您只解析相關數據時,系統會更快地執行您的查詢。 誰知道呢,也許下次你會在咖啡機製作卡布奇諾之前得到輸出!
構建您可以信任的儀表板
數據可視化是全面了解您的分析工作的最佳方式。 但是,如果您根據嚴苛的數據構建儀表板,則儀表板將缺乏價值。 如果您提供重複的儀表板,則儀表板將無法反映真實的情況。
這就是為什麼如果您想通過彩色圖表和條形的棱鏡來解釋複雜的概念或性能指標,數據規範化是重中之重。
如何在不同環境中規範化數據
由於數據分析師使用不同的工具,我們將解釋如何在當今市場上最需要的環境中規範化數據。
如何在 Python 中規範化數據
使用 Python 的數據科學家和分析師使用多個庫來操作和整理數據。 以下是其中最受歡迎的:
- 熊貓
- 麻木的
- TensorFlow
我們將回顧這些庫的一些功能,這些功能可能會幫助您加快數據規範化過程。

刪除數據集中的列
原始數據通常包含過多或不必要的類別。 例如,您使用的營銷指標數據集包括展示次數、每次點擊費用、點擊率、廣告支出回報率和轉化次數,但您只需要此表中的轉化次數。
如果除了轉換之外的所有內容對分析都不重要,則需要刪除過多的列。 Pandas 提供了一種使用 drop() 函數從數據集中刪除列的簡單方法。
首先,您必須定義要刪除的列列表。 在我們的例子中,它看起來像這樣:
column_drop_list = ['展示次數,'CPC','CTR','ROAS']
然後,您需要執行該功能:
dataframe_name.drop(column_drop_list,就地=真,軸=1)
在這行代碼中,第一個參數代表我們的列列表的名稱。 將inplace參數設置為 True 意味著 Pandas 將直接將更改應用於您的對象。 第三個參數表示是否從數據框中刪除標籤或列('0' 代表標籤,'1' 代表列)。
再次檢查數據集後,您會看到所有冗餘列都已成功刪除。
清理數據字段
另一個步驟是整理數據字段。 它有助於提高數據一致性並將數據轉換為標準化格式。
這裡的主要問題是您不能確定營銷平台的 API 會傳輸 100% 準確的數據。 您仍然可能會遇到錯位的字符或誤導性數據。
一個營銷活動只能有一個印像數。 這就是為什麼我們需要將有價值的數字與其他字符分開。
正則表達式 (regex) 可以幫助您識別數據集中的所有數字。 此正則表達式生成器將幫助您根據需要創建正則表達式並立即對其進行測試。
然後,借助 str.extract() 函數,我們可以從數據集中提取所需的數據作為列。
true_impressions = dataframe_name.str.extract(your_regex) , expand = False)
最後,您可能需要將列轉換為數字版本。 由於數據框中的所有列都具有對像類型,將其轉換為數值將簡化進一步的計算。 您可以在 pd.to_numeric() 函數的幫助下做到這一點。
重命名數據框中的列
數據源經常傳輸名稱分析師無法理解的列。 例如,由於某種原因,CTR 可能被稱為 C_T_R_final。
當您合併來自不同來源的數據並對其進行整體分析時,就會發現另一個問題。 雖然第一個數據源將印象稱為 imps,但另一個數據源將其稱為視圖。 這使得計算和構建跨所有數據源的整體圖變得困難。
這就是為什麼您需要重命名列以使所有內容結構化。
首先,使用列的未來名稱創建一個字典。 假設我們從具有不同命名約定的 Google Ads 和 Facebook Ads 中獲得印象。 在這種情況下,我們的字典將如下所示:
new_clmn_names = {'Imps' : 'Google Ads 展示次數',
“觀看次數”:“Facebook 廣告展示次數”}
然後,您應該在數據框中使用 rename() 函數:
dataframe_name.rename(列=new_clmn_names,就地=真)
現在,您的列將在字典中分配名稱。
Pandas 有更多不同的功能可以幫助您規範化數據。 我們建議閱讀官方文檔以更好地掌握其他功能。
如何規範化 Excel 中的數據
Excel 或 Google 表格因其易用性和廣泛的功能而成為許多分析師喜愛的強大工具。 毫無疑問,諸如 R 或 Python 之類的編程語言可以提供更多功能,但電子表格在分析數據方面做得很好。
但是,您的表可能包含異構數據,並且 Excel 提供了一個工具集來規範化見解。
修剪多餘的空格
手動識別大表中的過多空間是浪費時間。 幸運的是,Excel 和 Google Sheets 具有 TRIM 功能,允許分析師僅使用一個功能刪除數據集中的多餘空格。 看看下面的例子。

如您所見,條目數據在單詞之間有很大的空白。 使用 TRIM 功能,數據被放入正確的格式。

刪除數據集中的空數據行
在分析過程中,空單元格可能會升級為真正的噩夢。 這就是為什麼你應該總是事先與他們打交道。 這是如何做到這一點的。
- 選擇所有單元格,然後單擊工具欄中的“數據”選項卡。

- 單擊排序範圍菜單中的“按列排序範圍(Z 到 A)”按鈕。
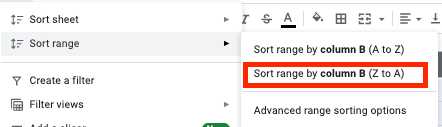
- 現在您的表格底部有所有空行,因此您可以簡單地選擇並刪除它們。
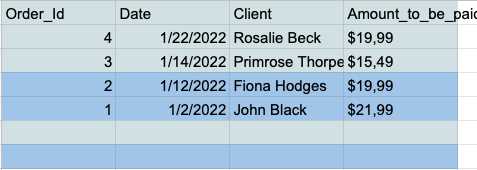
刪除重複項
重複數據條目是使用 Excel 或 Google 表格工作的分析師的常見問題。 這就是為什麼這些工具具有以快速簡便的方式刪除重複項的專用功能。
Google 表格具有 UNIQUE 功能,可讓您在表格中僅保留唯一數據。
假設您有一個包含多個重複項的 Name 和 Age 列的簡單表。

通過將數據集提供給 UNIQUE 函數,您可以獲得一個沒有任何重複條目的干淨表。

文本大小寫規範化
從文本文件導入數據後,您經常會發現名稱或標題中的文本大小寫不一致。 您可以使用以下功能輕鬆修復 Excel 或 Google 表格中的數據:
- LOWER() - 將所有文本轉換為小寫。
- UPPER() - 將所有文本轉換為大寫。
- PROPER() - 將所有文本轉換為正確的大小寫。

根據您的特定用例,有多種方法可以標準化 Excel 或 Google 表格數據。 這些指南更詳細地說明了 Excel 數據規範化:
- Excel 數據清洗技術
- 微軟的 Excel 數據規範化技巧
自動化數據標準化工具
編程語言提供了廣泛的工具集來規範您的數據。 但是,手動數據標準化有其局限性。
首先,分析師需要強大的工程知識和所需庫的實踐經驗。 數據科學家和工程師是非常受歡迎的人才,他們的薪水通常是天文數字。
此外,編碼需要時間,而且往往容易出錯。 因此,必須對分析的數據集進行後續審查。 最終,分析過程可能會花費比預期更多的時間。
自動化工具可以節省分析師的時間並提供更精確的結果。 您可以將數據簡化為規範化工具,並在幾分鐘而不是幾天內獲得純化的見解。
讓我們考慮即興表演的例子。 Improvado 是一個收入 ETL 平台,可幫助營銷分析師和銷售人員在一個地方調整他們不同的數據和存儲洞察力。
該平台從 300 多個來源收集數據,並幫助分析師以零努力對其進行標準化。 今天的營銷和銷售工具市場是分散的,不同的平台對相似的指標使用不同的命名約定。
Improvado 的營銷通用數據模型 (MCDM) 是一個統一的數據模型,可提供流行數據源的自動跨渠道映射、重複數據刪除和 UNIONing。 此外,它將付費媒體源拼接和標準化,自動將分析就緒的見解傳輸到您的數據倉庫。
例如,Improvado 可以自動將 Google Ads 和 Bing 數據合併到一個表中。
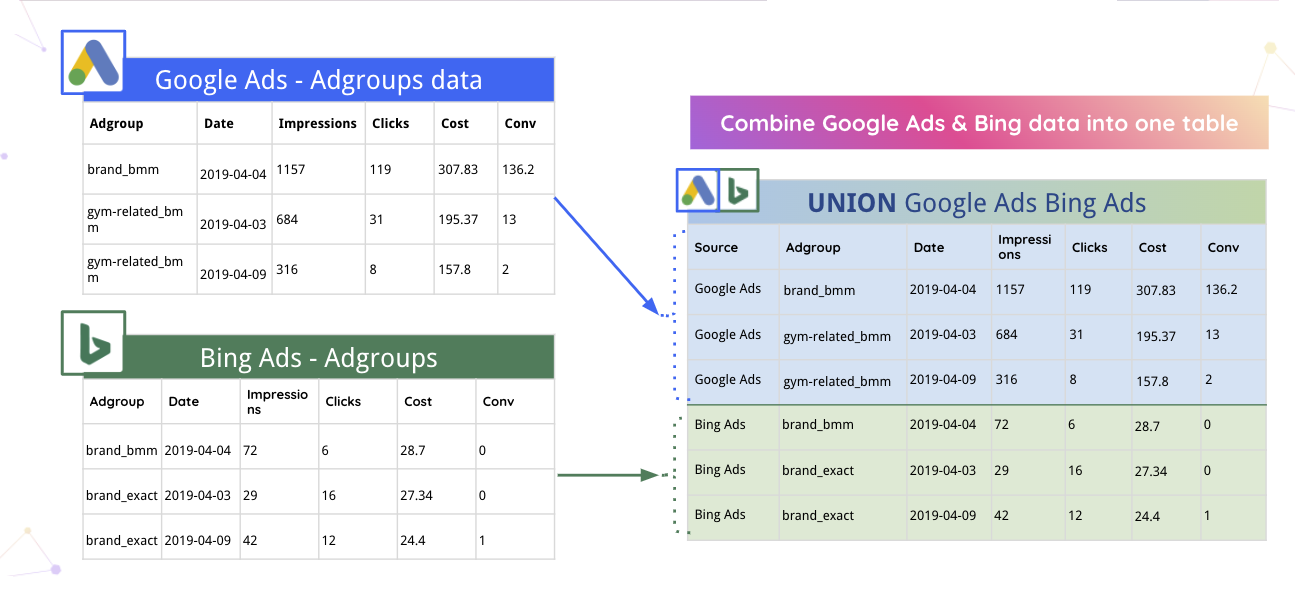
此外,平台可以自動解析數據並將其轉換為合適的格式。 例如,以下是 Improvado 如何將 Date 拆分為 Day of Week、Month 和 Year 列。
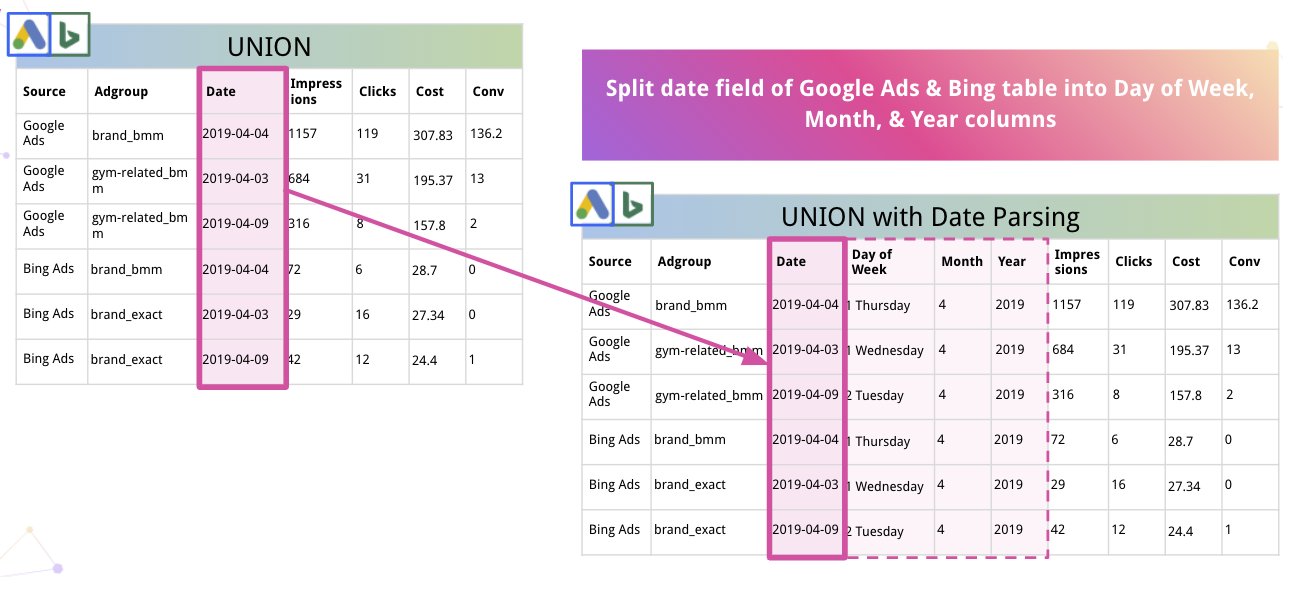
Improvado 更進一步,允許分析師自動解析您網站上的 Adobe Analytics 跟踪代碼。 您可以從跟踪代碼中提取嵌入的 AdGroup ID,而無需手動操作。
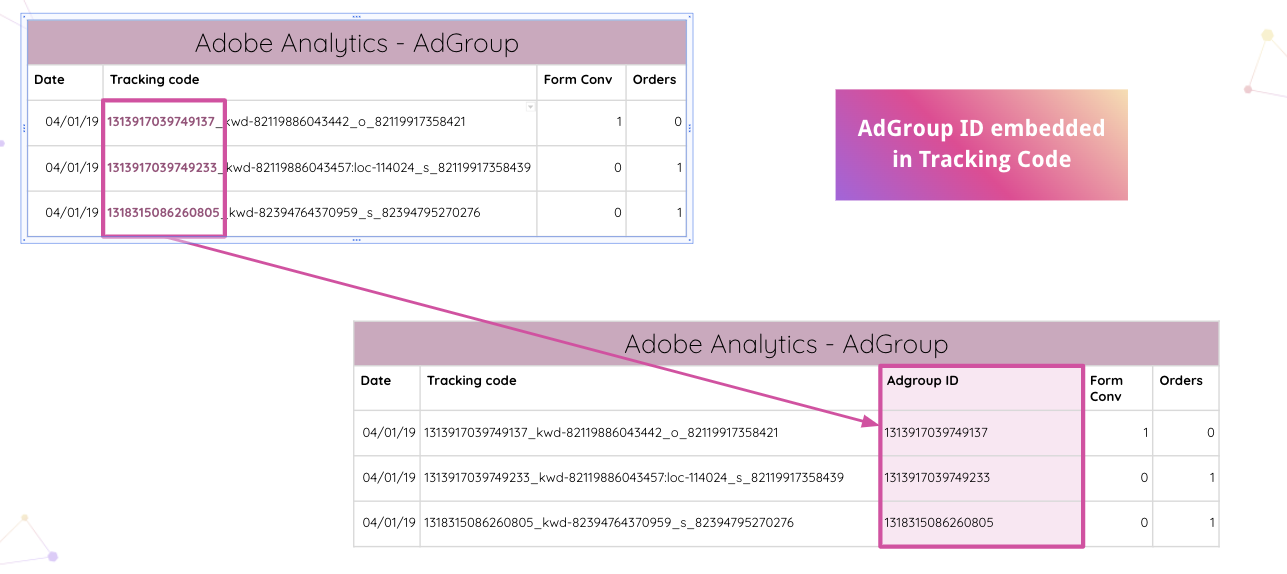
然後,分析師可以將內部電子表格與分類相結合,並根據網絡 ID 進行匹配。
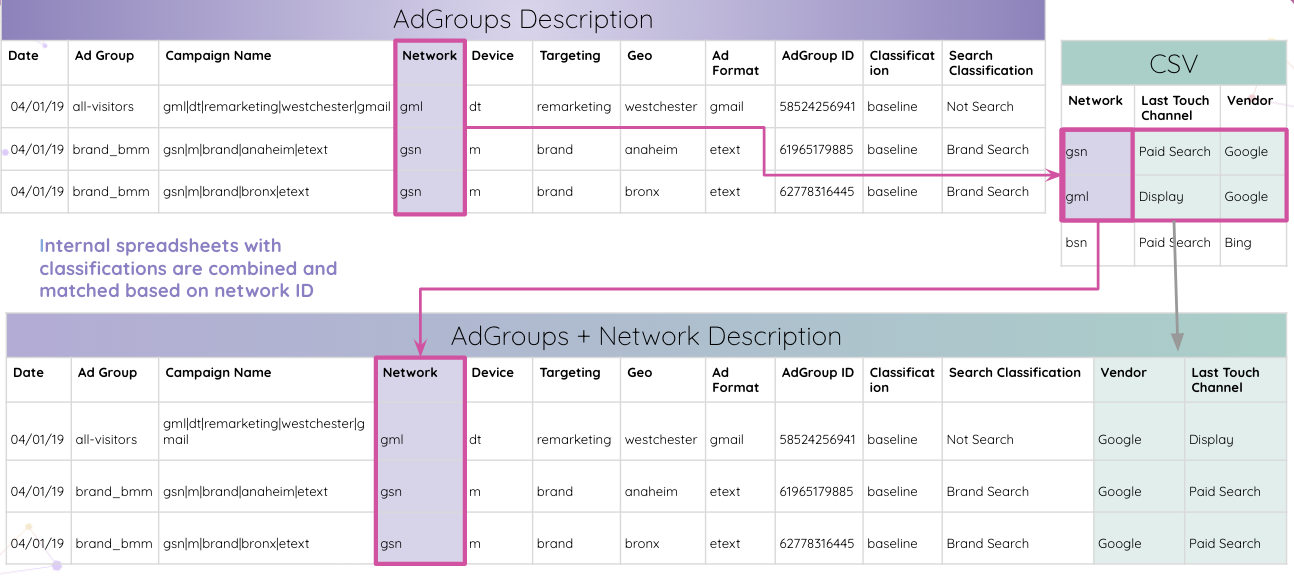
最終,分析師獲得了與 AdGroup ID 匹配的所有表格,並將其合併到最終結果表格中。

這只是 Improvado 可以規範化數據並以易於理解的方式提供見解以供進一步研究的眾多用例之一。
將所有見解集中在一個地方,該平台可以將它們簡化為您選擇的任何可視化工具。 純化和結構化的數據使構建全面的跨渠道儀表板變得更加容易。 例如,這是一個基於 Improvado 見解的 Data Studio 儀表板:
使用 Improvado 規範營銷和銷售數據
數據規範化需要時間,但清晰的洞察力總是值得付出努力的。 如果您可以直接深入分析並大大縮短洞察時間,為什麼還要浪費時間在數據規範化上?
Improvado 解開您的收入數據網絡,減少手動數據操作所花費的時間,並確保最高粒度的洞察力。 使用此 ETL 系統,您可以分析可信數據並構建實時儀表板,以展示您的營銷資金的有效性。 安排通話以了解更多信息。
了解收入 ETL 平台如何幫助您超越營銷目標並節省分析師的時間。
