
O guia definitivo para raspar a web: técnicas, ferramentas e práticas recomendadas
Publicados: 2024-01-11Introdução à raspagem da Web
Compreendendo os princípios básicos do Web Scraping
Web scraping, em sua essência, é o processo de extração de dados de sites. Essa técnica permite a coleta automatizada de informações de diversas páginas da web, tornando-se uma ferramenta poderosa para análise de dados, pesquisa de mercado e agregação de conteúdo.

Fonte: https://www.upwork.com/resources/web-scraping-basics
Para começar com web scraping, é necessário entender os componentes básicos da web: HTML, CSS e JavaScript. HTML (HyperText Markup Language) forma a estrutura das páginas da web, CSS (Cascading Style Sheets) é usado para estilização e JavaScript geralmente adiciona interatividade. Web scraping envolve a análise do HTML para extrair os dados necessários.
Existem vários métodos para realizar web scraping, desde copiar e colar manualmente até técnicas automatizadas usando várias linguagens de programação como Python ou ferramentas como Scrapy e BeautifulSoup. A escolha do método depende da complexidade da tarefa e do conhecimento técnico do usuário.
A importância do Web Scraping no mundo atual movido por dados
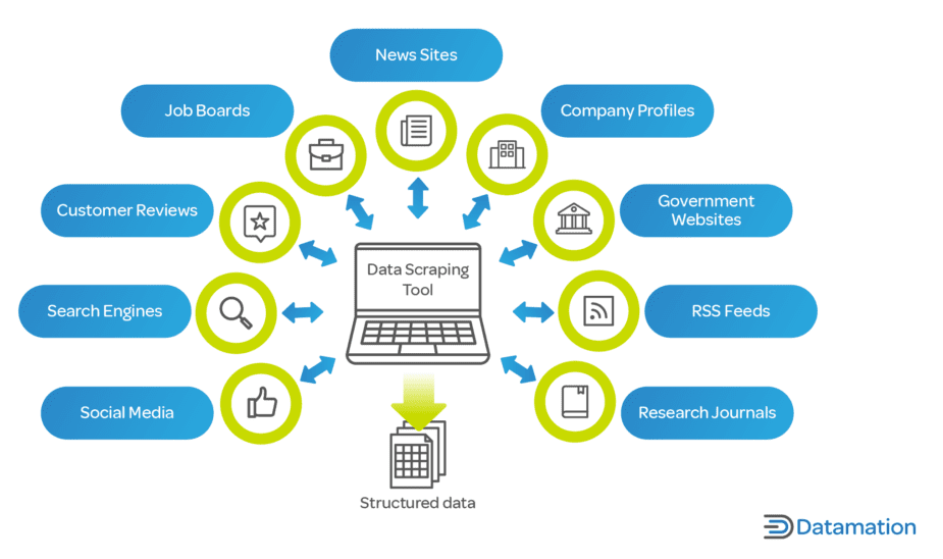
Na era digital de hoje, os dados são um ativo crítico para empresas e investigadores. O web scraping é vital porque permite a rápida coleta e análise de grandes quantidades de dados da Internet, um fator-chave nos processos de tomada de decisão em todos os setores.
Para as empresas, o web scraping pode fornecer insights sobre tendências de mercado, análises de concorrentes, preferências dos clientes e muito mais. É fundamental em setores como o comércio eletrônico, onde é crucial acompanhar os preços, as descrições e a disponibilidade dos produtos.
No âmbito da pesquisa e da academia, o web scraping facilita a coleta de dados em grande escala para estudos em áreas como ciências sociais, ciência da computação e estatística. Esses dados, que podem levar meses para serem coletados manualmente, podem ser coletados em uma fração do tempo com web scraping.
Além disso, o web scraping não se limita apenas a grandes corporações ou instituições acadêmicas. Desenvolvedores independentes, pequenas empresas e hobbyistas também utilizam web scraping para vários projetos, desde o desenvolvimento de aplicativos que agregam artigos de notícias até a realização de projetos de pesquisa pessoal. Web scraping é uma ferramenta inestimável no mundo contemporâneo orientado por dados, oferecendo o poder de transformar o vasto mar de dados da web em insights acionáveis.
Configurando seu ambiente de web scraping
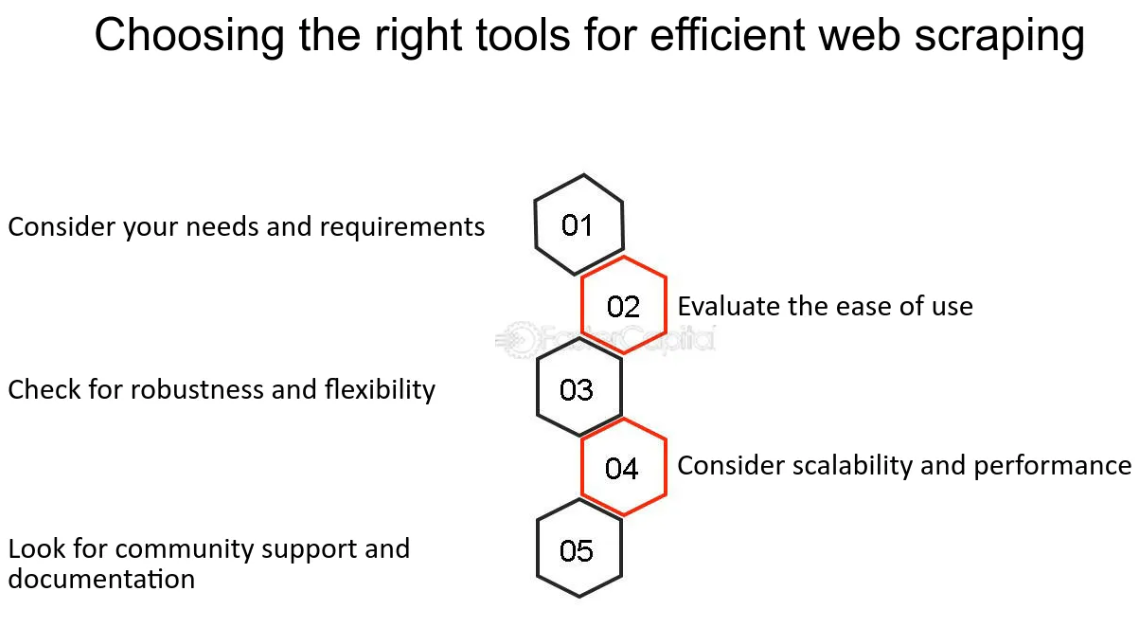
Escolhendo as ferramentas e idiomas certos para web scraping
Fonte: https://fastercapital.com/startup-topic/web-scraping.html
Quando se trata de web scraping, selecionar as ferramentas e linguagens de programação certas é crucial para eficiência e facilidade de uso. Python emergiu como pioneiro neste espaço, graças à sua simplicidade e à vasta gama de bibliotecas projetadas especificamente para web scraping, como BeautifulSoup e Scrapy.
- Python : Conhecido por sua legibilidade e simplicidade, Python é ideal tanto para iniciantes quanto para especialistas. Bibliotecas como BeautifulSoup simplificam o processo de análise de documentos HTML e XML, facilitando a extração de dados.
- Scrapy : esta estrutura colaborativa e de código aberto é usada para extrair os dados necessários de sites. Não é apenas uma biblioteca, mas uma solução e estrutura completa de web scraping.
- Outras linguagens : embora Python seja popular, outras linguagens como Ruby, PHP e JavaScript (Node.js) também oferecem recursos de web scraping. A escolha pode depender de suas habilidades de programação existentes ou de requisitos específicos do projeto.
Além das linguagens de programação, você também pode considerar o uso de software especializado de web scraping ou serviços em nuvem, especialmente se não estiver interessado em codificação. Ferramentas como Octoparse ou Dexi.io oferecem uma abordagem mais visual para raspagem, permitindo que os usuários apontem e cliquem nos dados que desejam extrair.
Configurando seu primeiro projeto de Web Scraping: um guia passo a passo
- Instale Python e bibliotecas : comece instalando Python e pip, o instalador de pacotes do Python. Em seguida, instale bibliotecas de web scraping como BeautifulSoup e solicitações executando pip install beautifulsoup4 requests.
- Identifique o site de destino : escolha um site do qual deseja extrair os dados da web. Certifique-se de revisar o arquivo robots.txt do site para entender as regras de extração.
- Inspecione a página da Web : use as ferramentas de desenvolvedor do seu navegador para inspecionar a estrutura HTML da página. Identifique os elementos HTML que contêm os dados que você deseja extrair da web.
- Escreva o script de raspagem : escreva um script Python para solicitar o conteúdo da página da web e analisar o HTML. Use BeautifulSoup ou outra biblioteca de análise para extrair os dados necessários.
- Execute seu script e extraia dados : execute seu script e colete os dados. Certifique-se de lidar com exceções e erros normalmente.
- Armazene os dados raspados : decida como você armazenará seus dados raspados da web. As opções comuns incluem arquivos CSV, JSON ou um sistema de banco de dados como SQLite ou MongoDB.
- Práticas respeitosas de scraping : implemente atrasos em seu script de scraping para evitar sobrecarregar o servidor e respeite a privacidade dos dados e as diretrizes legais do site.

Fonte: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Este guia estabelece a base para seu primeiro projeto de web scraping, fornecendo uma visão geral das ferramentas e etapas envolvidas na configuração de um ambiente de scraping básico, mas eficaz.
Técnicas avançadas de web scraping
Lidando com sites dinâmicos e com muito JavaScript
A raspagem de sites dinâmicos, especialmente aqueles fortemente dependentes de JavaScript, requer técnicas mais avançadas do que a raspagem tradicional baseada em HTML. Esses sites geralmente carregam conteúdo de forma assíncrona, o que significa que os dados necessários podem não estar presentes na resposta HTML inicial.
- Noções básicas sobre AJAX e APIs : muitos sites dinâmicos carregam dados usando solicitações AJAX (JavaScript assíncrono e XML). A inspeção do tráfego de rede por meio das ferramentas de desenvolvedor do seu navegador pode revelar endpoints de API que retornam dados em um formato estruturado como JSON, que pode ser mais fácil de extrair da web do que analisar HTML.
- Selenium e automação do navegador : ferramentas como o Selenium permitem automatizar um navegador da web, permitindo a extração de conteúdo renderizado em JavaScript. O Selenium pode simular interações reais do usuário, garantindo que todo o conteúdo dinâmico seja carregado.
- Navegadores sem cabeça : ferramentas como Puppeteer para Node.js ou Headless Chrome podem renderizar uma página da web sem uma GUI, permitindo a extração eficiente de sites com muito JavaScript.
- Lidando com rolagem e paginação infinitas : para páginas com rolagem infinita ou múltiplas páginas, seu raspador precisa simular ações do usuário (como rolagem) ou manipular parâmetros de URL para navegar pelas páginas.
Técnicas avançadas de análise e limpeza de dados
Depois de extrair os dados com sucesso, a próxima etapa crucial é analisar e limpar para garantir que sejam utilizáveis e significativos.
- Expressões regulares (Regex) : Expressões regulares são uma ferramenta poderosa para extrair padrões específicos de texto. Eles podem ser usados para extrair números de telefone, endereços de e-mail e outros formatos de dados padronizados.
- Transformação de dados : converter os dados da web em um formato ou estrutura desejada, como alterar formatos de data ou mesclar campos de dados separados, é essencial para uma análise consistente.
- Lidando com problemas de Unicode e codificação : os dados da Web podem vir em várias codificações. Garantir o manuseio correto de Unicode e outras codificações é vital para manter a integridade dos dados da web.
- Bibliotecas de limpeza de dados : utilize bibliotecas como Pandas em Python para limpar e transformar dados. Pandas oferece funções abrangentes para lidar com valores ausentes, duplicatas e conversões de tipo de dados.
- Validação de dados : implemente verificações para validar a precisão e consistência da coleta de dados da web. Esta etapa é crucial para identificar quaisquer anomalias ou erros no processo de raspagem.
- Considerações Éticas e Limitação de Taxa : Sempre raspe a web com responsabilidade, não sobrecarregando o servidor e respeitando os termos de serviço do site. Implemente limitação de taxa e use cache para minimizar solicitações do servidor.
Ao dominar essas técnicas avançadas de web scraping, você pode lidar com sites dinâmicos com eficiência e garantir que os dados coletados sejam precisos e limpos, prontos para análise ou integração em seus aplicativos.

Usando ferramentas e estruturas de web scraping
Uma visão geral das ferramentas populares de web scraping e seus recursos
Ferramentas e estruturas de web scraping simplificam muito o processo de extração de dados de sites. Aqui está uma visão geral de alguns dos mais populares:
- BeautifulSoup : uma biblioteca Python para análise de documentos HTML e XML. É conhecido por sua simplicidade e facilidade de uso, especialmente útil para projetos de raspagem em pequena escala. BeautifulSoup permite navegar na árvore de análise e pesquisar elementos por atributos, o que é útil para extrair dados específicos.
- Scrapy : Outra ferramenta baseada em Python, Scrapy é mais uma estrutura completa de rastreamento e raspagem da web. É altamente eficiente, escalável e adequado para projetos maiores ou que exigem extração de dados complexa. Scrapy fornece uma solução completa para solicitar URLs, processar as páginas retornadas e manipular os dados copiados.
- Selenium : Originalmente uma ferramenta para automatizar navegadores da web para fins de teste, o Selenium também é eficaz para extrair conteúdo dinâmico. Ele permite que você controle programaticamente um navegador da web, permitindo a extração de conteúdo renderizado em JavaScript.
- Octoparse : Uma ferramenta de raspagem visual sem código, ideal para indivíduos sem amplo conhecimento de programação. Ele oferece uma interface de apontar e clicar para selecionar os dados que você deseja extrair da web, tornando o processo intuitivo.
- Puppeteer e Playwright : essas bibliotecas Node.js são usadas para automação de navegador, particularmente úteis para raspar sites com muito JavaScript. Eles fornecem um alto nível de controle sobre o Chrome ou Chromium e são excelentes para lidar com cenários complexos de raspagem.
Exemplos práticos: usando ferramentas como Scrapy e BeautifulSoup
Exemplo com BeautifulSoup :
da importação bs4 BeautifulSoup
solicitações de importação
url = “http://exemplo.com”
resposta = solicitações.get(url)
sopa = BeautifulSoup(response.text, 'html.parser')
# Extraindo todos os links da página
para link em sopa.find_all('a'):
imprimir(link.get('href'))
Este script simples usa BeautifulSoup para analisar uma página da web e imprimir todos os hiperlinks.
Exemplo com Scrapy :
Para usar o Scrapy, você normalmente cria um projeto Scrapy com um spider. Aqui está um exemplo básico:
importar scrapy
classe ExemploSpider(scrapy.Spider):
nome = 'exemplo'
domínios_permitidos = ['exemplo.com']
start_urls = ['http://example.com/']
def analisar(self, resposta):
# Extraindo o conteúdo usando seletores css
títulos = resposta.css('h2::text').extract()
rendimento {'títulos': títulos}
Este Scrapy spider irá extrair os títulos da web (entre tags h2) de example.com.
Esses exemplos demonstram o uso básico do BeautifulSoup para tarefas simples e do Scrapy para projetos de scraping mais estruturados e escalonáveis. Ambas as ferramentas têm pontos fortes únicos, tornando-as adequadas para diferentes tipos de necessidades de web scraping.
Lidando com desafios comuns de web scraping
Superando CAPTCHAs e proibições de IP
Um dos principais desafios do web scraping é lidar com CAPTCHAs e proibições de IP, que são mecanismos que os sites usam para impedir o acesso automatizado.
Lidando com CAPTCHAs :
- Serviços de resolução de CAPTCHA : Utilize serviços de resolução de CAPTCHA de terceiros. Esses serviços usam uma combinação de IA e contribuição humana para resolver CAPTCHAs mediante o pagamento de uma taxa.
- Evite o acionamento de CAPTCHAs : implemente estratégias como rotação de agentes de usuário, respeitando o robots.txt do site e fazendo solicitações em intervalos semelhantes aos humanos para evitar CAPTCHAs.
- Reconhecimento óptico de caracteres (OCR) : Para CAPTCHAs mais simples, as ferramentas de OCR às vezes podem ser eficazes na decodificação do texto.
Evitando e lidando com proibições de IP :
- Rotação de IP : Use um conjunto de endereços IP e gire-os para evitar ser bloqueado. Isto pode ser conseguido através de serviços de proxy.
- Scraping respeitoso : siga as políticas de scraping do site, mantenha uma taxa de solicitação lenta e constante e evite scraping durante os horários de pico.
- Mecanismos de nova tentativa : implemente mecanismos de nova tentativa com estratégias de espera exponencial para lidar com proibições temporárias de IP ou problemas de rede.
Estratégias eficientes de armazenamento e gerenciamento de dados
O armazenamento e o gerenciamento adequados de dados são cruciais para o tratamento eficaz dos dados coletados por meio de web scraping.
Escolhendo a solução de armazenamento certa :
- Bancos de dados : para dados estruturados, bancos de dados relacionais como MySQL ou PostgreSQL são ideais. Para esquemas mais flexíveis ou dados não estruturados, bancos de dados NoSQL como MongoDB podem ser usados.
- Armazenamento baseado em arquivo : projetos simples ou pequenas quantidades de dados podem ser armazenados em formatos de arquivo como CSV, JSON ou XML.
Normalização de dados e design de esquema :
- Certifique-se de que o esquema do seu banco de dados represente efetivamente os dados que você está coletando. Normalize os dados para reduzir a redundância e melhorar a integridade.
Limpeza e transformação de dados :
- Limpe e transforme os dados extraídos antes de armazená-los. Isso inclui a remoção de duplicatas, a correção de erros e a conversão de dados para o formato desejado.
Escalabilidade e desempenho :
- Considere a escalabilidade se estiver lidando com raspagem em grande escala. Use indexação de banco de dados, consultas otimizadas e mecanismos de cache para melhorar o desempenho.
Restaurar e recuperar :
- Faça backup regularmente dos seus dados para evitar perdas devido a falhas de hardware ou outros problemas. Tenha um plano de recuperação em vigor.
Privacidade e segurança de dados :
- Esteja atento às leis de privacidade de dados e às considerações éticas. Proteja o armazenamento e a transmissão de dados para proteger informações confidenciais.
Ao abordar com eficácia esses desafios comuns, você pode garantir que seus projetos de web scraping não sejam apenas bem-sucedidos, mas também respeitem os limites legais e éticos, e que os dados coletados sejam armazenados e gerenciados de forma eficiente.
Melhores práticas e dicas para web scraping eficiente

Fonte: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
A raspagem da Web, quando feita de forma eficiente, pode produzir dados de alta qualidade com gasto mínimo de recursos. Aqui estão algumas práticas recomendadas e dicas para aumentar a eficiência e eficácia de seus esforços de web scraping.
Otimizando Seu Código de Scraping para Velocidade e Eficiência
- Uso eficiente do seletor : Use seletores eficientes, específicos e diretos. Evite seletores XPath ou CSS excessivamente amplos ou complexos, pois eles podem retardar o processo de análise.
- Solicitações simultâneas : implemente solicitações simultâneas, mas dentro de limites razoáveis para evitar sobrecarregar o servidor. Ferramentas como o Scrapy permitem fácil configuração de solicitações simultâneas.
- Cache : Implemente mecanismos de cache para armazenar e reutilizar dados obtidos anteriormente, o que pode reduzir significativamente a necessidade de fazer solicitações redundantes.
- Tratamento de carregamento lento : para páginas que usam carregamento lento, certifique-se de que seu raspador acione o carregamento de todos os elementos necessários, possivelmente simulando ações de rolagem.
- Eficiência de extração de dados : Extraia apenas os dados necessários. Evite baixar conteúdo desnecessário, como imagens ou estilos, se não for necessário para seus objetivos de scraping.
- Gerenciamento de sessão : use sessões e cookies com sabedoria para manter o estado quando necessário, o que pode ser particularmente útil para sites que exigem login.
Mantendo seu código de scraping: atualizações e escalabilidade
- Revisões regulares de código : revise e atualize regularmente seu código de scraping para se adaptar a quaisquer alterações na estrutura ou conteúdo do site.
- Design Modular : Estruture seu código de forma modular, de forma que caso uma parte do site mude, você só precise atualizar um módulo específico do seu scraper.
- Tratamento de erros : implemente tratamento robusto de erros e registro para identificar e corrigir problemas rapidamente. Isso inclui o tratamento de erros HTTP, tempos limite de conexão e erros de análise de dados.
- Considerações sobre escalabilidade : projete sua solução de raspagem para ser escalonável. À medida que suas necessidades de dados aumentam, garanta que seu sistema possa lidar com cargas e volumes de dados maiores sem retrabalho significativo.
- Teste automatizado : implemente testes automatizados para verificar a funcionalidade contínua do seu raspador. Testes regulares podem alertá-lo sobre falhas causadas por alterações no site de destino.
- Documentação : Mantenha seu código bem documentado. Uma documentação clara é crucial para a manutenção, especialmente se a base de código for compartilhada entre uma equipe ou entregue para manutenção futura.
- Raspagem Respeitosa : Sempre siga as diretrizes éticas de raspagem. Mantenha um equilíbrio entre suas necessidades de dados e o impacto nos servidores do site de destino.
Ao aderir a essas práticas, você não apenas torna seus processos de web scraping mais eficientes e eficazes, mas também garante que sejam sustentáveis e adaptáveis às mudanças ao longo do tempo.
Resumindo
Neste guia abrangente, exploramos as várias facetas do web scraping, oferecendo insights sobre suas técnicas, ferramentas e práticas recomendadas. Desde a compreensão básica de web scraping e sua importância no mundo atual, orientado por dados, até técnicas avançadas para lidar com sites dinâmicos e com muito JavaScript, cobrimos aspectos essenciais para equipá-lo com o conhecimento para coletar e utilizar dados da web de maneira eficaz.
Você está pronto para aproveitar o poder do web scraping para o seu negócio ou projeto? PromptCloud está aqui para guiá-lo nesta jornada. Com nossa experiência e soluções personalizadas, podemos ajudá-lo a navegar no cenário complexo de web scraping, garantindo que você extraia o máximo valor de seus esforços de extração de dados. Contate a PromptCloud hoje e libere todo o potencial dos dados da web para sua empresa!
Aproveite nossos serviços para transformar sua abordagem de coleta e análise de dados. Vamos embarcar juntos nesta jornada baseada em dados – entre em contato com o PromptCloud agora!