
웹 스크랩을 위한 궁극적인 가이드: 기술, 도구 및 모범 사례
게시 됨: 2024-01-11웹 스크래핑 소개
웹 스크래핑의 기본 이해
웹 스크래핑의 핵심은 웹사이트에서 데이터를 추출하는 프로세스입니다. 이 기술을 사용하면 다양한 웹 페이지에서 자동으로 정보를 수집할 수 있으므로 데이터 분석, 시장 조사 및 콘텐츠 집계를 위한 강력한 도구가 됩니다.

출처: https://www.upwork.com/resources/web-scraping-basics
웹 스크래핑을 시작하려면 웹의 기본 구성 요소인 HTML, CSS 및 JavaScript를 이해해야 합니다. HTML(HyperText Markup Language)은 웹 페이지의 구조를 형성하고, CSS(Cascading Style Sheets)는 스타일 지정에 사용되며, JavaScript는 종종 상호작용성을 추가합니다. 웹 스크래핑에는 HTML을 구문 분석하여 필요한 데이터를 추출하는 작업이 포함됩니다.
수동 복사-붙여넣기부터 Python과 같은 다양한 프로그래밍 언어나 Scrapy 및 BeautifulSoup와 같은 도구를 사용하는 자동화된 기술에 이르기까지 웹 스크래핑을 수행하는 방법에는 여러 가지가 있습니다. 방법 선택은 작업의 복잡성과 사용자의 기술 전문성에 따라 달라집니다.
오늘날의 데이터 중심 세계에서 웹 스크래핑의 중요성
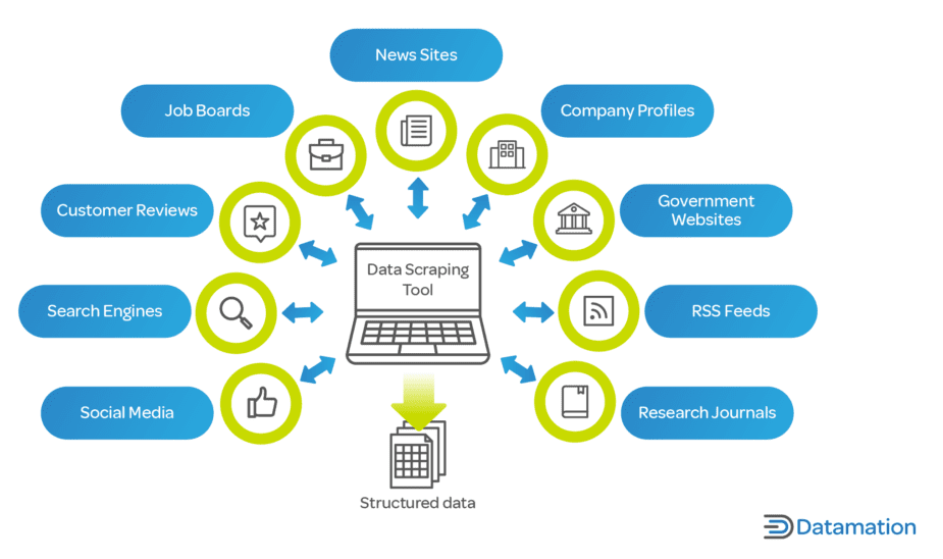
오늘날의 디지털 시대에 데이터는 기업과 연구자들에게 중요한 자산입니다. 웹 스크래핑은 산업 전반의 의사 결정 프로세스의 핵심 동인인 인터넷에서 방대한 양의 데이터를 신속하게 수집하고 분석할 수 있기 때문에 매우 중요합니다.
기업의 경우 웹 스크래핑은 시장 동향, 경쟁사 분석, 고객 선호도 등에 대한 통찰력을 제공할 수 있습니다. 이는 제품 가격, 설명 및 가용성을 추적하는 것이 중요한 전자 상거래와 같은 분야에서 중요한 역할을 합니다.
연구 및 학계 영역에서 웹 스크래핑은 사회 과학, 컴퓨터 과학, 통계 등의 분야 연구를 위한 대규모 데이터 수집을 용이하게 합니다. 수동으로 수집하는 데 몇 달이 걸릴 수 있는 이 데이터는 웹 스크래핑을 사용하면 훨씬 짧은 시간에 수집할 수 있습니다.
게다가 웹스크래핑은 대기업이나 학술기관에만 국한되지 않습니다. 독립 개발자, 중소기업, 취미생활자도 뉴스 기사를 집계하는 앱 개발부터 개인 연구 프로젝트 수행에 이르기까지 다양한 프로젝트에 웹 스크래핑을 활용합니다. 웹 스크래핑은 현대 데이터 중심 세계에서 귀중한 도구로, 방대한 웹 데이터를 실행 가능한 통찰력으로 전환할 수 있는 힘을 제공합니다.
웹 스크래핑 환경 설정
웹 스크래핑에 적합한 도구 및 언어 선택
출처: https://fastercapital.com/startup-topic/web-scraping.html
웹 스크래핑의 경우 효율성과 사용 편의성을 위해 올바른 도구와 프로그래밍 언어를 선택하는 것이 중요합니다. Python은 단순성과 BeautifulSoup 및 Scrapy와 같이 웹 스크래핑을 위해 특별히 설계된 다양한 라이브러리 덕분에 이 분야의 선두 주자로 부상했습니다.
- Python : 가독성과 단순성으로 잘 알려진 Python은 초보자와 전문가 모두에게 이상적입니다. BeautifulSoup과 같은 라이브러리는 HTML 및 XML 문서 구문 분석 프로세스를 단순화하여 데이터 추출을 더 쉽게 만듭니다.
- Scrapy : 이 오픈 소스 협업 프레임워크는 웹사이트에서 필요한 데이터를 추출하는 데 사용됩니다. 이는 단순한 라이브러리가 아니라 완전한 웹 스크래핑 솔루션 및 프레임워크입니다.
- 기타 언어 : Python이 인기가 있지만 Ruby, PHP, JavaScript(Node.js)와 같은 다른 언어도 웹 스크래핑 기능을 제공합니다. 선택은 기존 프로그래밍 기술이나 특정 프로젝트 요구 사항에 따라 달라질 수 있습니다.
프로그래밍 언어 외에도 특히 코딩에 관심이 없는 경우 전문적인 웹 스크래핑 소프트웨어 또는 클라우드 서비스 사용을 고려할 수도 있습니다. Octoparse 또는 Dexi.io와 같은 도구는 스크래핑에 대한 보다 시각적인 접근 방식을 제공하므로 사용자는 추출하려는 데이터를 가리키고 클릭할 수 있습니다.
첫 번째 웹 스크래핑 프로젝트 설정: 단계별 가이드
- Python 및 라이브러리 설치 : Python과 Python의 패키지 설치 프로그램인 pip를 설치하여 시작합니다. 다음으로 pip install beautifulsoup4 요청을 실행하여 BeautifulSoup 및 요청과 같은 웹 스크래핑 라이브러리를 설치합니다.
- 대상 웹사이트 식별 : 웹 데이터를 스크랩하려는 웹사이트를 선택합니다. 스크래핑 규칙을 이해하려면 사이트의 robots.txt 파일을 검토하세요.
- 웹 페이지 검사 : 브라우저의 개발자 도구를 사용하여 페이지의 HTML 구조를 검사합니다. 웹에서 스크랩하려는 데이터가 포함된 HTML 요소를 식별하세요.
- 스크래핑 스크립트 작성 : 웹페이지 콘텐츠를 요청하고 HTML을 구문 분석하는 Python 스크립트를 작성합니다. BeautifulSoup 또는 다른 구문 분석 라이브러리를 사용하여 필요한 데이터를 추출하세요.
- 스크립트 실행 및 데이터 추출 : 스크립트를 실행하고 데이터를 수집합니다. 예외와 오류를 적절하게 처리해야 합니다.
- 스크랩한 데이터 저장 : 스크랩한 웹 데이터를 어떻게 저장할지 결정하세요. 일반적인 옵션에는 CSV 파일, JSON 또는 SQLite나 MongoDB와 같은 데이터베이스 시스템이 포함됩니다.
- 존중하는 스크래핑 관행 : 서버에 부담을 주지 않도록 스크래핑 스크립트에 지연을 구현하고 웹 사이트의 데이터 개인 정보 보호 및 법적 지침을 존중하십시오.

출처: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
이 가이드는 기본적이지만 효과적인 스크래핑 환경 설정과 관련된 도구 및 단계에 대한 개요를 제공하여 첫 번째 웹 스크래핑 프로젝트의 기초를 설정합니다.
고급 웹 스크래핑 기술
동적 및 JavaScript 중심 웹사이트 다루기
동적 웹사이트, 특히 JavaScript에 크게 의존하는 웹사이트를 스크래핑하려면 기존 HTML 기반 스크래핑보다 더 고급 기술이 필요합니다. 이러한 사이트는 콘텐츠를 비동기식으로 로드하는 경우가 많습니다. 즉, 필요한 데이터가 초기 HTML 응답에 없을 수도 있습니다.
- AJAX 및 API 이해 : 많은 동적 웹사이트는 AJAX(Asynchronous JavaScript and XML) 요청을 사용하여 데이터를 로드합니다. 브라우저의 개발자 도구를 통해 네트워크 트래픽을 검사하면 HTML을 구문 분석하는 것보다 웹을 스크랩하는 것이 더 쉬울 수 있는 JSON과 같은 구조화된 형식으로 데이터를 반환하는 API 엔드포인트를 확인할 수 있습니다.
- Selenium 및 브라우저 자동화 : Selenium과 같은 도구를 사용하면 웹 브라우저를 자동화하여 JavaScript로 렌더링된 콘텐츠를 스크랩할 수 있습니다. Selenium은 실제 사용자 상호 작용을 시뮬레이션하여 모든 동적 콘텐츠가 로드되도록 할 수 있습니다.
- 헤드리스 브라우저 : Node.js용 Puppeteer 또는 헤드리스 Chrome과 같은 도구는 GUI 없이 웹페이지를 렌더링할 수 있으므로 JavaScript가 많은 사이트를 효율적으로 스크래핑할 수 있습니다.
- 무한 스크롤 및 페이지 매김 처리 : 무한 스크롤 또는 여러 페이지가 있는 페이지의 경우 스크래퍼는 사용자 작업(예: 스크롤)을 시뮬레이션하거나 URL 매개변수를 처리하여 페이지를 탐색해야 합니다.
고급 데이터 구문 분석 및 정리 기술
데이터를 성공적으로 스크랩한 후 다음으로 중요한 단계는 구문 분석 및 정리하여 데이터가 사용 가능하고 의미가 있는지 확인하는 것입니다.
- 정규식(Regex) : 정규식은 텍스트에서 특정 패턴을 추출하는 강력한 도구입니다. 전화번호, 이메일 주소 및 기타 표준화된 데이터 형식을 추출하는 데 사용할 수 있습니다.
- 데이터 변환 : 날짜 형식을 변경하거나 별도의 데이터 필드를 병합하는 등 웹 데이터를 원하는 형식이나 구조로 변환하는 것은 일관된 분석을 위해 필수적입니다.
- 유니코드 및 인코딩 문제 처리 : 웹 데이터는 다양한 인코딩으로 제공될 수 있습니다. 웹 데이터 스크랩의 무결성을 유지하려면 유니코드 및 기타 인코딩을 올바르게 처리하는 것이 중요합니다.
- 데이터 정리 라이브러리 : 데이터 정리 및 변환을 위해 Python의 Pandas와 같은 라이브러리를 활용합니다. Pandas는 누락된 값, 중복 및 데이터 유형 변환을 처리하기 위한 광범위한 기능을 제공합니다.
- 데이터 검증 : 웹 데이터 스크랩의 정확성과 일관성을 검증하는 검사를 구현합니다. 이 단계는 스크래핑 프로세스의 이상이나 오류를 식별하는 데 중요합니다.
- 윤리적 고려 사항 및 속도 제한 : 항상 서버에 과부하를 주지 않고 웹 사이트의 서비스 약관을 존중하여 책임감 있게 웹을 스크레이핑하십시오. 속도 제한을 구현하고 캐싱을 사용하여 서버 요청을 최소화합니다.
이러한 고급 웹 스크래핑 기술을 익히면 동적 웹사이트를 효율적으로 처리하고 수집한 데이터가 정확하고 깨끗하며 분석 또는 애플리케이션에 통합될 준비가 되었는지 확인할 수 있습니다.

웹 스크래핑 도구 및 프레임워크 사용
널리 사용되는 웹 스크래핑 도구 및 해당 기능 개요
웹 스크래핑 도구와 프레임워크는 웹사이트에서 데이터를 추출하는 과정을 크게 단순화합니다. 다음은 몇 가지 인기 있는 항목에 대한 개요입니다.
- BeautifulSoup : HTML 및 XML 문서를 구문 분석하기 위한 Python 라이브러리입니다. 단순성과 사용 용이성으로 잘 알려져 있으며 특히 소규모 스크래핑 프로젝트에 유용합니다. BeautifulSoup을 사용하면 구문 분석 트리를 탐색하고 속성별로 요소를 검색할 수 있어 특정 데이터를 추출하는 데 편리합니다.
- Scrapy : 또 다른 Python 기반 도구인 Scrapy는 완전한 웹 크롤링 및 스크래핑 프레임워크에 가깝습니다. 매우 효율적이고 확장 가능하며 대규모 프로젝트나 복잡한 데이터 추출이 필요한 프로젝트에 적합합니다. Scrapy는 URL 요청, 반환된 페이지 처리, 스크랩된 데이터 처리를 위한 완전한 솔루션을 제공합니다.
- Selenium : 원래 테스트 목적으로 웹 브라우저를 자동화하는 도구였던 Selenium은 동적 콘텐츠를 스크랩하는 데에도 효과적입니다. 이를 통해 웹 브라우저를 프로그래밍 방식으로 제어하여 JavaScript로 렌더링된 콘텐츠를 스크랩할 수 있습니다.
- Octoparse : 광범위한 프로그래밍 지식이 없는 개인에게 이상적인 노코드 시각적 스크래핑 도구입니다. 웹에서 스크랩하려는 데이터를 선택할 수 있는 포인트 앤 클릭 인터페이스를 제공하여 프로세스를 직관적으로 만듭니다.
- Puppeteer 및 Playwright : 이 Node.js 라이브러리는 브라우저 자동화에 사용되며 특히 JavaScript가 많은 웹 사이트를 스크랩하는 데 유용합니다. Chrome 또는 Chromium에 대한 높은 수준의 제어 기능을 제공하며 복잡한 스크래핑 시나리오를 처리하는 데 탁월합니다.
실습 예제: Scrapy 및 BeautifulSoup와 같은 도구 사용
BeautifulSoup의 예 :
bs4에서 가져오기 BeautifulSoup
수입요청
URL = “http://example.com”
응답 = 요청.get(url)
수프 = BeautifulSoup(response.text, 'html.parser')
# 페이지의 모든 링크 추출
Soup.find_all('a')의 링크:
인쇄(link.get('href'))
이 간단한 스크립트는 BeautifulSoup을 사용하여 웹페이지를 구문 분석하고 모든 하이퍼링크를 인쇄합니다.
Scrapy의 예 :
Scrapy를 사용하려면 일반적으로 스파이더를 사용하여 Scrapy 프로젝트를 만듭니다. 기본적인 예는 다음과 같습니다.
수입 스크랩
클래스 예제Spider(scrapy.Spider):
이름 = '예제'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def 구문 분석(자기, 응답):
# CSS 선택기를 사용하여 콘텐츠 추출
제목 = response.css('h2::text').extract()
{'제목': 제목}을 산출합니다
이 Scrapy 스파이더는 example.com에서 웹 제목(h2 태그로 묶음)을 긁어냅니다.
이 예제에서는 간단한 작업을 위한 BeautifulSoup의 기본 사용법과 보다 구조화되고 확장 가능한 스크래핑 프로젝트를 위한 Scrapy의 기본 사용법을 보여줍니다. 두 도구 모두 고유한 장점을 갖고 있어 다양한 유형의 웹 스크래핑 요구 사항에 적합합니다.
일반적인 웹 스크래핑 문제 처리
CAPTCHA 및 IP 금지 극복
웹 스크래핑의 주요 과제 중 하나는 웹사이트에서 자동 액세스를 방지하기 위해 사용하는 메커니즘인 CAPTCHA 및 IP 금지를 처리하는 것입니다.
CAPTCHA 처리 :
- CAPTCHA 해결 서비스 : 타사 CAPTCHA 해결 서비스를 활용합니다. 이러한 서비스는 AI와 인간 입력의 조합을 사용하여 유료로 CAPTCHA를 해결합니다.
- CAPTCHA 트리거 방지 : 사용자 에이전트 교체, 웹 사이트의 robots.txt 존중, CAPTCHA를 방지하기 위해 사람과 같은 간격으로 요청하는 등의 전략을 구현합니다.
- 광학 문자 인식(OCR) : 간단한 CAPTCHA의 경우 OCR 도구가 텍스트를 디코딩하는 데 효과적일 수 있습니다.
IP 금지 방지 및 처리 :
- IP 순환 : IP 주소 풀을 사용하고 차단되지 않도록 순환합니다. 이는 프록시 서비스를 통해 달성할 수 있습니다.
- 정중한 스크래핑 : 웹사이트의 스크래핑 정책을 준수하고, 느리고 꾸준한 요청 속도를 유지하고, 사용량이 많은 시간대에는 스크래핑을 피합니다.
- 재시도 메커니즘 : 일시적인 IP 금지 또는 네트워크 문제를 처리하기 위해 지수 백오프 전략을 사용하여 재시도 메커니즘을 구현합니다.
효율적인 데이터 저장 및 관리 전략
웹 스크래핑을 통해 수집된 데이터를 효과적으로 처리하려면 적절한 데이터 저장 및 관리가 중요합니다.
적합한 스토리지 솔루션 선택 :
- 데이터베이스 : 구조화된 데이터의 경우 MySQL 또는 PostgreSQL과 같은 관계형 데이터베이스가 이상적입니다. 보다 유연한 스키마 또는 구조화되지 않은 데이터의 경우 MongoDB와 같은 NoSQL 데이터베이스를 사용할 수 있습니다.
- 파일 기반 저장 : 간단한 프로젝트나 소량의 데이터를 CSV, JSON, XML과 같은 파일 형식으로 저장할 수 있습니다.
데이터 정규화 및 스키마 설계 :
- 데이터베이스 스키마가 스크랩 중인 데이터를 효과적으로 나타내는지 확인하세요. 데이터를 정규화하여 중복성을 줄이고 무결성을 향상합니다.
데이터 정리 및 변환 :
- 스크랩한 데이터를 저장하기 전에 정리하고 변환하세요. 여기에는 중복 제거, 오류 수정, 데이터를 원하는 형식으로 변환 등이 포함됩니다.
확장성 및 성능 :
- 대규모 스크래핑을 처리하는 경우 확장성을 고려하십시오. 데이터베이스 인덱싱, 최적화된 쿼리 및 캐싱 메커니즘을 사용하여 성능을 향상합니다.
백업 및 복구 :
- 하드웨어 오류나 기타 문제로 인한 손실을 방지하려면 데이터를 정기적으로 백업하세요. 회복 계획을 마련하십시오.
데이터 개인정보 보호 및 보안 :
- 데이터 개인 정보 보호법과 윤리적 고려 사항을 염두에 두십시오. 민감한 정보를 보호하기 위해 데이터 저장 및 전송을 보호하세요.
이러한 일반적인 문제를 효과적으로 해결함으로써 웹 스크래핑 프로젝트가 성공할 뿐만 아니라 법적 및 윤리적 경계를 존중하고 수집한 데이터가 효율적으로 저장 및 관리되도록 할 수 있습니다.
효율적인 웹 스크래핑을 위한 모범 사례 및 팁

출처: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
웹 스크래핑을 효율적으로 수행하면 최소한의 리소스 비용으로 고품질 데이터를 얻을 수 있습니다. 다음은 웹 스크래핑 노력의 효율성과 효과를 향상시키기 위한 몇 가지 모범 사례와 팁입니다.
속도와 효율성을 위해 스크래핑 코드 최적화
- 효율적인 선택기 사용법 : 구체적이고 직접적인 효율적인 선택기를 사용합니다. 지나치게 광범위하거나 복잡한 XPath 또는 CSS 선택기는 구문 분석 프로세스 속도를 늦출 수 있으므로 피하세요.
- 동시 요청 : 서버 과부하를 방지하기 위해 합리적인 한도 내에서 동시 요청을 구현합니다. Scrapy와 같은 도구를 사용하면 동시 요청을 쉽게 구성할 수 있습니다.
- 캐싱 : 이전에 가져온 데이터를 저장하고 재사용하는 캐싱 메커니즘을 구현하여 중복 요청의 필요성을 크게 줄일 수 있습니다.
- 지연 로딩 처리 : 지연 로딩을 사용하는 페이지의 경우 스크레이퍼가 스크롤 작업을 시뮬레이션하여 필요한 모든 요소의 로딩을 트리거하는지 확인하세요.
- 데이터 추출 효율성 : 필요한 데이터만 추출합니다. 스크래핑 목표에 필요하지 않은 경우 이미지나 스타일과 같은 불필요한 콘텐츠를 다운로드하지 마세요.
- 세션 관리 : 세션과 쿠키를 현명하게 사용하여 필요한 경우 상태를 유지합니다. 이는 로그인이 필요한 사이트에 특히 유용할 수 있습니다.
스크래핑 코드 유지 관리: 업데이트 및 확장성
- 정기 코드 검토 : 웹 사이트 구조나 콘텐츠의 변경 사항에 맞게 스크래핑 코드를 정기적으로 검토하고 업데이트합니다.
- 모듈형 디자인 : 웹사이트의 한 부분이 변경되면 스크레이퍼의 특정 모듈만 업데이트하면 되도록 코드를 모듈식으로 구성합니다.
- 오류 처리 : 강력한 오류 처리 및 로깅을 구현하여 문제를 신속하게 식별하고 해결합니다. 여기에는 HTTP 오류, 연결 시간 초과 및 데이터 구문 분석 오류 처리가 포함됩니다.
- 확장성 고려 사항 : 확장 가능하도록 스크래핑 솔루션을 설계합니다. 데이터 요구 사항이 증가함에 따라 시스템이 상당한 재작업 없이 증가된 로드와 데이터 볼륨을 처리할 수 있는지 확인하십시오.
- 자동화된 테스트 : 스크레이퍼의 지속적인 기능을 확인하기 위해 자동화된 테스트를 구현합니다. 정기적인 테스트를 통해 대상 웹사이트의 변경으로 인한 오류를 경고할 수 있습니다.
- 문서화 : 코드를 잘 문서화하세요. 명확한 문서화는 유지 관리에 매우 중요하며, 특히 코드베이스가 팀 간에 공유되거나 향후 유지 관리를 위해 넘겨지는 경우 더욱 그렇습니다.
- 존중하는 스크래핑 : 항상 윤리적인 스크래핑 지침을 따르십시오. 데이터 요구 사항과 대상 웹 사이트 서버에 미치는 영향 간의 균형을 유지하십시오.
이러한 관행을 준수함으로써 웹 스크래핑 프로세스를 보다 효율적이고 효과적으로 만들 수 있을 뿐만 아니라 지속 가능하고 시간이 지남에 따른 변화에 적응할 수 있도록 보장합니다.
요약하자면
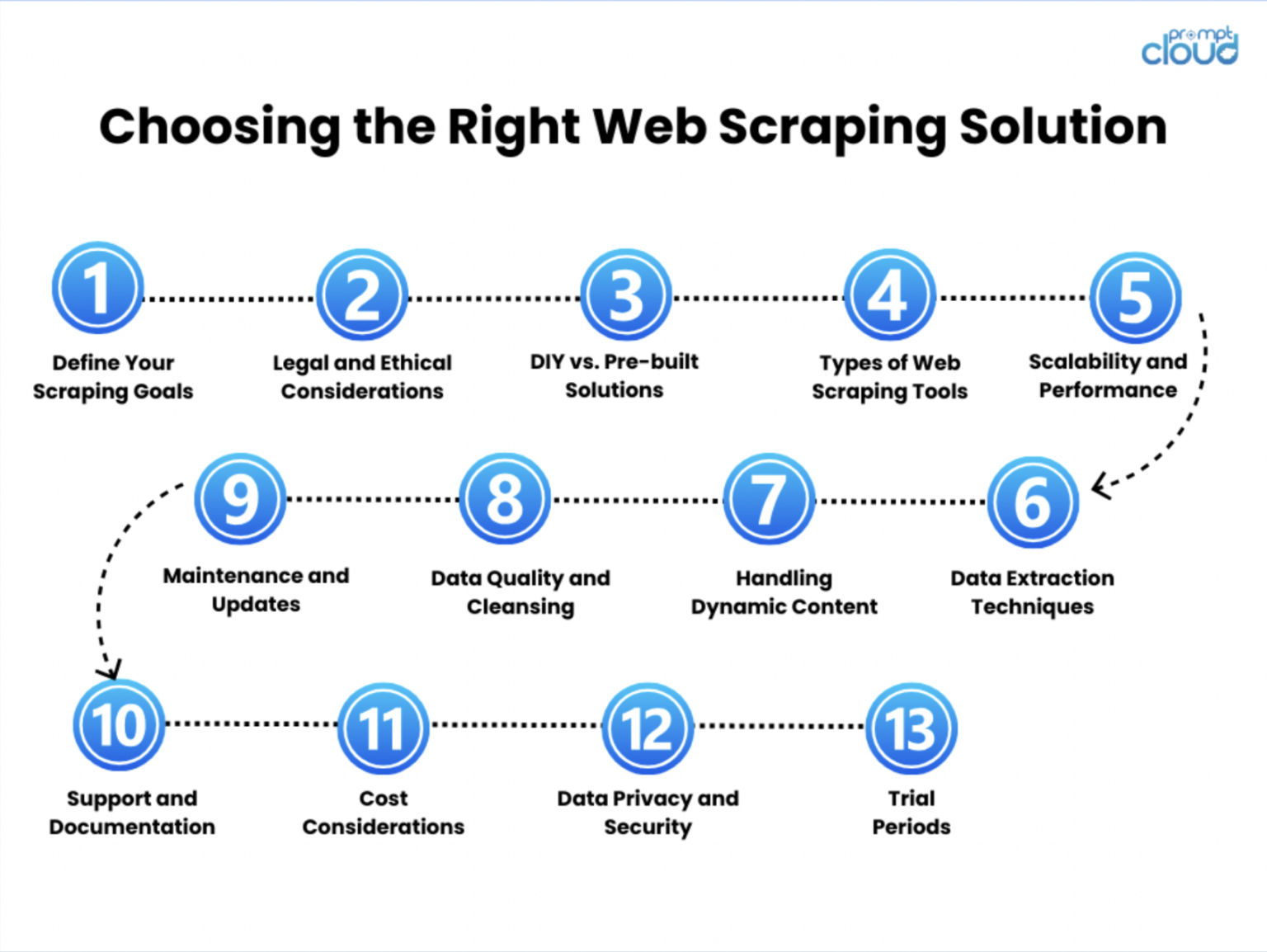
이 포괄적인 가이드에서 우리는 웹 스크래핑의 다양한 측면을 탐색하여 기술, 도구 및 모범 사례에 대한 통찰력을 제공했습니다. 오늘날의 데이터 중심 세계에서 웹 스크래핑과 그 중요성에 대한 기본적인 이해부터 동적이며 JavaScript가 많은 웹 사이트를 처리하기 위한 고급 기술에 이르기까지 웹 데이터를 효과적으로 수집하고 활용하기 위한 지식을 갖추는 데 필요한 필수 측면을 다뤘습니다.
귀하의 비즈니스나 프로젝트에 웹 스크래핑의 힘을 활용할 준비가 되셨습니까? PromptCloud가 이 여정을 안내해 드립니다. 당사의 전문 지식과 맞춤형 솔루션을 통해 웹 스크래핑의 복잡한 환경을 탐색하여 데이터 추출 노력에서 최대 가치를 추출할 수 있도록 도와드립니다. 지금 PromptCloud에 문의하여 기업을 위한 웹 데이터의 잠재력을 최대한 활용하십시오!
당사의 서비스를 활용하여 데이터 수집 및 분석에 대한 접근 방식을 혁신하십시오. 이 데이터 기반 여정을 함께 시작합시다. 지금 PromptCloud에 문의하세요!