
La guía definitiva para scrapear la Web: técnicas, herramientas y mejores prácticas
Publicado: 2024-01-11Introducción al web scraping
Comprender los conceptos básicos del web scraping
El web scraping, en esencia, es el proceso de extraer datos de sitios web. Esta técnica permite la recopilación automatizada de información de varias páginas web, lo que la convierte en una poderosa herramienta para el análisis de datos, la investigación de mercado y la agregación de contenido.

Fuente: https://www.upwork.com/resources/web-scraping-basics
Para comenzar con el web scraping, es necesario comprender los componentes básicos de la web: HTML, CSS y JavaScript. HTML (lenguaje de marcado de hipertexto) forma la estructura de las páginas web, CSS (hojas de estilo en cascada) se utiliza para diseñar y JavaScript a menudo agrega interactividad. El web scraping implica analizar el HTML para extraer los datos que necesita.
Existen varios métodos para realizar web scraping, que van desde copiar y pegar manualmente hasta técnicas automatizadas que utilizan varios lenguajes de programación como Python o herramientas como Scrapy y BeautifulSoup. La elección del método depende de la complejidad de la tarea y de la experiencia técnica del usuario.
La importancia del web scraping en el mundo actual basado en datos
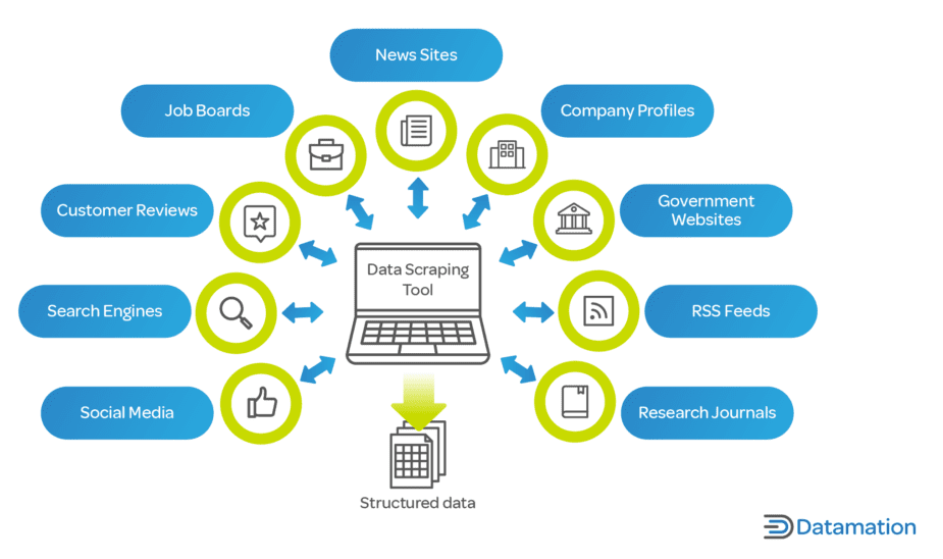
En la era digital actual, los datos son un activo fundamental para las empresas y los investigadores. El web scraping es vital porque permite la rápida recopilación y análisis de grandes cantidades de datos de Internet, un factor clave en los procesos de toma de decisiones en todas las industrias.
Para las empresas, el web scraping puede proporcionar información sobre las tendencias del mercado, análisis de la competencia, preferencias de los clientes y más. Es fundamental en sectores como el comercio electrónico, donde es fundamental realizar un seguimiento de los precios, las descripciones y la disponibilidad de los productos.
En el ámbito de la investigación y el mundo académico, el web scraping facilita la recopilación de datos a gran escala para estudios en campos como las ciencias sociales, la informática y la estadística. Estos datos, que pueden tardar meses en recopilarse manualmente, se pueden recopilar en una fracción del tiempo con el web scraping.
Además, el web scraping no se limita sólo a grandes corporaciones o instituciones académicas. Los desarrolladores independientes, las pequeñas empresas y los aficionados también utilizan el web scraping para diversos proyectos, desde el desarrollo de aplicaciones que agregan artículos de noticias hasta la realización de proyectos de investigación personales. El web scraping es una herramienta invaluable en el mundo contemporáneo basado en datos, que ofrece el poder de convertir el vasto mar de datos web en información procesable.
Configuración de su entorno de raspado web
Elegir las herramientas y los lenguajes adecuados para el web scraping
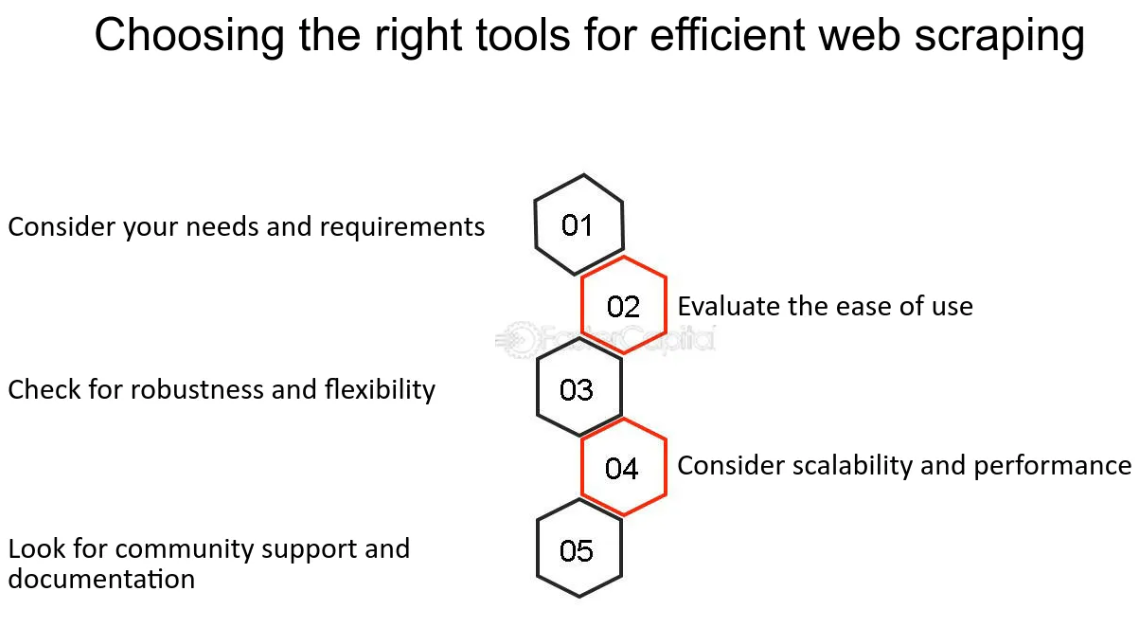
Fuente: https://fastercapital.com/startup-topic/web-scraping.html
Cuando se trata de web scraping, seleccionar las herramientas y los lenguajes de programación adecuados es crucial para lograr eficiencia y facilidad de uso. Python se ha convertido en un pionero en este espacio, gracias a su simplicidad y la amplia gama de bibliotecas diseñadas específicamente para web scraping, como BeautifulSoup y Scrapy.
- Python : conocido por su legibilidad y simplicidad, Python es ideal tanto para principiantes como para expertos. Bibliotecas como BeautifulSoup simplifican el proceso de análisis de documentos HTML y XML, facilitando la extracción de datos.
- Scrapy : este marco colaborativo y de código abierto se utiliza para extraer los datos que necesita de los sitios web. No es solo una biblioteca, sino un marco y una solución de raspado web completo.
- Otros lenguajes : si bien Python es popular, otros lenguajes como Ruby, PHP y JavaScript (Node.js) también ofrecen capacidades de web scraping. La elección puede depender de sus habilidades de programación existentes o de los requisitos específicos del proyecto.
Además de los lenguajes de programación, también podrías considerar el uso de software especializado de web scraping o servicios en la nube, especialmente si no te gusta la codificación. Herramientas como Octoparse o Dexi.io ofrecen un enfoque más visual para el scraping, permitiendo a los usuarios señalar y hacer clic en los datos que desean extraer.
Configuración de su primer proyecto de Web Scraping: una guía paso a paso
- Instale Python y las bibliotecas : comience instalando Python y pip, el instalador de paquetes de Python. A continuación, instale bibliotecas de raspado web como BeautifulSoup y solicitudes ejecutando solicitudes pip install beautifulsoup4.
- Identifique el sitio web de destino : elija el sitio web del que desea extraer los datos web. Asegúrese de revisar el archivo robots.txt del sitio para comprender las reglas de raspado.
- Inspeccionar la página web : utilice las herramientas de desarrollo de su navegador para inspeccionar la estructura HTML de la página. Identifique los elementos HTML que contienen los datos que desea extraer de la web.
- Escriba el script de raspado : escriba un script de Python para solicitar el contenido de la página web y analizar el HTML. Utilice BeautifulSoup u otra biblioteca de análisis para extraer los datos que necesita.
- Ejecute su secuencia de comandos y extraiga datos : ejecute su secuencia de comandos y recopile los datos. Asegúrese de manejar las excepciones y los errores con elegancia.
- Almacene los datos extraídos : decida cómo almacenará los datos extraídos de la web. Las opciones comunes incluyen archivos CSV, JSON o un sistema de base de datos como SQLite o MongoDB.
- Prácticas de scraping respetuosas : implemente retrasos en su script de scraping para evitar saturar el servidor y respete la privacidad de los datos y las pautas legales del sitio web.

Fuente: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Esta guía sienta las bases para su primer proyecto de web scraping y proporciona una descripción general de las herramientas y los pasos necesarios para configurar un entorno de scraping básico pero eficaz.
Técnicas avanzadas de raspado web
Manejo de sitios web dinámicos y con mucho JavaScript
El scraping de sitios web dinámicos, particularmente aquellos que dependen en gran medida de JavaScript, requiere técnicas más avanzadas que el scraping tradicional basado en HTML. Estos sitios suelen cargar contenido de forma asincrónica, lo que significa que es posible que los datos que necesita no estén presentes en la respuesta HTML inicial.
- Comprensión de AJAX y API : muchos sitios web dinámicos cargan datos mediante solicitudes AJAX (JavaScript asíncrono y XML). La inspección del tráfico de red a través de las herramientas de desarrollo de su navegador puede revelar puntos finales de API que devuelven datos en un formato estructurado como JSON, que puede ser más fácil de rastrear en la web que analizar HTML.
- Selenium y automatización del navegador : herramientas como Selenium le permiten automatizar un navegador web, permitiendo la extracción de contenido renderizado en JavaScript. Selenium puede simular interacciones reales del usuario, garantizando que se cargue todo el contenido dinámico.
- Navegadores sin cabeza : herramientas como Puppeteer para Node.js o Headless Chrome pueden representar una página web sin una GUI, lo que permite eliminar de manera eficiente sitios con mucho JavaScript.
- Manejo de desplazamiento y paginación infinitos : para páginas con desplazamiento infinito o páginas múltiples, su raspador debe simular acciones del usuario (como desplazamiento) o manejar parámetros de URL para navegar por las páginas.
Técnicas avanzadas de análisis y limpieza de datos
Después de extraer los datos con éxito, el siguiente paso crucial es analizarlos y limpiarlos para garantizar que sean utilizables y significativos.
- Expresiones regulares (Regex) : las expresiones regulares son una herramienta poderosa para extraer patrones específicos del texto. Se pueden utilizar para extraer números de teléfono, direcciones de correo electrónico y otros formatos de datos estandarizados.
- Transformación de datos : convertir datos web extraídos a un formato o estructura deseado, como cambiar formatos de fecha o fusionar campos de datos separados, es esencial para un análisis consistente.
- Manejo de problemas de codificación y Unicode : los datos web pueden venir en varias codificaciones. Garantizar el manejo correcto de Unicode y otras codificaciones es vital para mantener la integridad de los datos de la web.
- Bibliotecas de limpieza de datos : utilice bibliotecas como Pandas en Python para limpiar y transformar datos. Pandas ofrece amplias funciones para manejar valores faltantes, duplicados y conversiones de tipos de datos.
- Validación de datos : implemente controles para validar la precisión y coherencia de los datos extraídos de la web. Este paso es crucial para identificar cualquier anomalía o error en el proceso de raspado.
- Consideraciones éticas y limitación de tarifas : navegue siempre por la web de manera responsable, no sobrecargando el servidor y respetando los términos de servicio del sitio web. Implemente limitación de velocidad y utilice el almacenamiento en caché para minimizar las solicitudes del servidor.
Al dominar estas técnicas avanzadas de web scraping, podrá manejar de manera eficiente sitios web dinámicos y garantizar que los datos que recopile sean precisos y limpios, listos para su análisis o integración en sus aplicaciones.

Uso de herramientas y marcos de web scraping
Una descripción general de las herramientas populares de web scraping y sus características
Las herramientas y marcos de web scraping simplifican enormemente el proceso de extracción de datos de sitios web. Aquí hay una descripción general de algunos populares:
- BeautifulSoup : una biblioteca de Python para analizar documentos HTML y XML. Es conocido por su simplicidad y facilidad de uso, especialmente útil para proyectos de scraping a pequeña escala. BeautifulSoup le permite navegar por el árbol de análisis y buscar elementos por atributos, lo cual resulta útil para extraer datos específicos.
- Scrapy : Otra herramienta basada en Python, Scrapy es más bien un marco completo de rastreo y raspado web. Es muy eficiente, escalable y adecuado para proyectos más grandes o aquellos que requieren extracción de datos compleja. Scrapy proporciona una solución completa para solicitar URL, procesar las páginas devueltas y manejar los datos extraídos.
- Selenium : originalmente una herramienta para automatizar navegadores web con fines de prueba, Selenium también es eficaz para extraer contenido dinámico. Le permite controlar mediante programación un navegador web, lo que permite extraer contenido renderizado en JavaScript.
- Octoparse : una herramienta de raspado visual sin código, ideal para personas sin amplios conocimientos de programación. Ofrece una interfaz de apuntar y hacer clic para seleccionar los datos que desea extraer de la web, lo que hace que el proceso sea intuitivo.
- Titiritero y dramaturgo : estas bibliotecas de Node.js se utilizan para la automatización del navegador y son particularmente útiles para eliminar sitios web con mucho JavaScript. Proporcionan un alto nivel de control sobre Chrome o Chromium y son excelentes para manejar escenarios complejos de scraping.
Ejemplos prácticos: uso de herramientas como Scrapy y BeautifulSoup
Ejemplo con BeautifulSoup :
desde bs4 importar BeautifulSoup
solicitudes de importación
URL = “http://ejemplo.com”
respuesta = solicitudes.get(url)
sopa = BeautifulSoup(respuesta.texto, 'html.parser')
# Extrayendo todos los enlaces de la página.
para el enlace en sopa.find_all('a'):
imprimir(enlace.get('href'))
Este sencillo script utiliza BeautifulSoup para analizar una página web e imprimir todos los hipervínculos.
Ejemplo con Scrapy :
Para usar Scrapy, normalmente creas un proyecto Scrapy con una araña. Aquí hay un ejemplo básico:
importar scrapy
clase EjemploSpider(scrapy.Spider):
nombre = 'ejemplo'
dominios_permitidos = ['ejemplo.com']
start_urls = ['http://ejemplo.com/']
def analizar(yo, respuesta):
# Extrayendo el contenido usando selectores CSS
títulos = respuesta.css('h2::texto').extract()
rendimiento {'títulos': títulos}
Esta araña Scrapy extraerá los títulos web (incluidos en etiquetas h2) de example.com.
Estos ejemplos demuestran el uso básico de BeautifulSoup para tareas simples y Scrapy para proyectos de scraping más estructurados y escalables. Ambas herramientas tienen sus puntos fuertes únicos, lo que las hace adecuadas para diferentes tipos de necesidades de web scraping.
Manejo de desafíos comunes de raspado web
Superar los CAPTCHA y las prohibiciones de propiedad intelectual
Uno de los principales desafíos del web scraping es lidiar con los CAPTCHA y las prohibiciones de IP, que son mecanismos que utilizan los sitios web para evitar el acceso automatizado.
Manejo de CAPTCHA :
- Servicios de resolución de CAPTCHA : utilice servicios de resolución de CAPTCHA de terceros. Estos servicios utilizan una combinación de inteligencia artificial y aportación humana para resolver CAPTCHA por una tarifa.
- Evite activar CAPTCHA : implemente estrategias como rotar agentes de usuario, respetar el archivo robots.txt del sitio web y realizar solicitudes en un intervalo similar al de los humanos para evitar CAPTCHA.
- Reconocimiento óptico de caracteres (OCR) : para CAPTCHA más simples, las herramientas de OCR a veces pueden ser efectivas para decodificar el texto.
Cómo evitar y manejar las prohibiciones de propiedad intelectual :
- Rotación de IP : utilice un grupo de direcciones IP y rótelas para evitar ser bloqueado. Esto se puede lograr a través de servicios proxy.
- Scraping respetuoso : respete las políticas de scraping del sitio web, mantenga una tasa de solicitudes lenta y constante y evite el scraping durante las horas pico.
- Mecanismos de reintento : implemente mecanismos de reintento con estrategias de retroceso exponencial para manejar prohibiciones temporales de IP o problemas de red.
Estrategias eficientes de gestión y almacenamiento de datos
El almacenamiento y la gestión adecuados de los datos son cruciales para el manejo eficaz de los datos recopilados mediante el web scraping.
Elegir la solución de almacenamiento adecuada :
- Bases de datos : para datos estructurados, las bases de datos relacionales como MySQL o PostgreSQL son ideales. Para esquemas más flexibles o datos no estructurados, se pueden utilizar bases de datos NoSQL como MongoDB.
- Almacenamiento basado en archivos : se pueden almacenar proyectos simples o pequeñas cantidades de datos en formatos de archivo como CSV, JSON o XML.
Normalización de datos y diseño de esquemas :
- Asegúrese de que el esquema de su base de datos represente efectivamente los datos que está extrayendo. Normalice los datos para reducir la redundancia y mejorar la integridad.
Limpieza y transformación de datos :
- Limpie y transforme los datos extraídos antes de almacenarlos. Esto incluye eliminar duplicados, corregir errores y convertir datos al formato deseado.
Escalabilidad y rendimiento :
- Considere la escalabilidad si se trata de scraping a gran escala. Utilice indexación de bases de datos, consultas optimizadas y mecanismos de almacenamiento en caché para mejorar el rendimiento.
Copia de seguridad y recuperación :
- Haga una copia de seguridad de sus datos periódicamente para evitar pérdidas debido a fallas de hardware u otros problemas. Tenga implementado un plan de recuperación.
Privacidad y seguridad de datos :
- Tenga en cuenta las leyes de privacidad de datos y las consideraciones éticas. Asegure su almacenamiento y transmisión de datos para proteger la información confidencial.
Al abordar eficazmente estos desafíos comunes, puede garantizar que sus proyectos de web scraping no solo sean exitosos sino que también respeten los límites legales y éticos, y que los datos que recopile se almacenen y administren de manera eficiente.
Mejores prácticas y consejos para un web scraping eficiente

Fuente: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
El web scraping, cuando se realiza de manera eficiente, puede generar datos de alta calidad con un gasto mínimo de recursos. A continuación se presentan algunas prácticas recomendadas y consejos para mejorar la eficiencia y eficacia de sus esfuerzos de web scraping.
Optimización de su código scraping para mayor velocidad y eficiencia
- Uso eficiente del selector : utilice selectores eficientes que sean específicos y directos. Evite selectores XPath o CSS demasiado amplios o complejos, ya que pueden ralentizar el proceso de análisis.
- Solicitudes concurrentes : implemente solicitudes concurrentes pero dentro de límites razonables para evitar sobrecargar el servidor. Herramientas como Scrapy permiten una fácil configuración de solicitudes simultáneas.
- Almacenamiento en caché : implemente mecanismos de almacenamiento en caché para almacenar y reutilizar datos obtenidos previamente, lo que puede reducir significativamente la necesidad de realizar solicitudes redundantes.
- Manejo de carga diferida : para las páginas que utilizan carga diferida, asegúrese de que su raspador active la carga de todos los elementos necesarios, posiblemente simulando acciones de desplazamiento.
- Eficiencia de extracción de datos : extraiga solo los datos necesarios. Evite descargar contenido innecesario, como imágenes o estilos, si no es necesario para sus objetivos de scraping.
- Gestión de sesiones : utilice sesiones y cookies de forma inteligente para mantener el estado donde sea necesario, lo que puede resultar especialmente útil para sitios que requieren inicio de sesión.
Mantenimiento de su código scraping: actualizaciones y escalabilidad
- Revisiones periódicas de código : revise y actualice periódicamente su código de raspado para adaptarse a cualquier cambio en la estructura o el contenido del sitio web.
- Diseño modular : estructura tu código de forma modular, de modo que si una parte del sitio web cambia, solo necesitas actualizar un módulo específico de tu scraper.
- Manejo de errores : implemente un manejo y registro de errores sólidos para identificar y solucionar problemas rápidamente. Esto incluye el manejo de errores HTTP, tiempos de espera de conexión y errores de análisis de datos.
- Consideraciones de escalabilidad : diseñe su solución de scraping para que sea escalable. A medida que aumentan sus necesidades de datos, asegúrese de que su sistema pueda manejar mayores cargas y volúmenes de datos sin necesidad de realizar modificaciones importantes.
- Pruebas automatizadas : implemente pruebas automatizadas para verificar la funcionalidad continua de su raspador. Las pruebas periódicas pueden alertarle sobre fallas causadas por cambios en el sitio web de destino.
- Documentación : mantenga su código bien documentado. La documentación clara es crucial para el mantenimiento, especialmente si el código base se comparte entre un equipo o se entrega para mantenimiento futuro.
- Scraping respetuoso : Siga siempre las pautas éticas de scraping. Mantenga un equilibrio entre sus necesidades de datos y el impacto en los servidores del sitio web de destino.
Al seguir estas prácticas, no solo hará que sus procesos de web scraping sean más eficientes y efectivos, sino que también garantizará que sean sostenibles y adaptables a los cambios a lo largo del tiempo.
En resumen
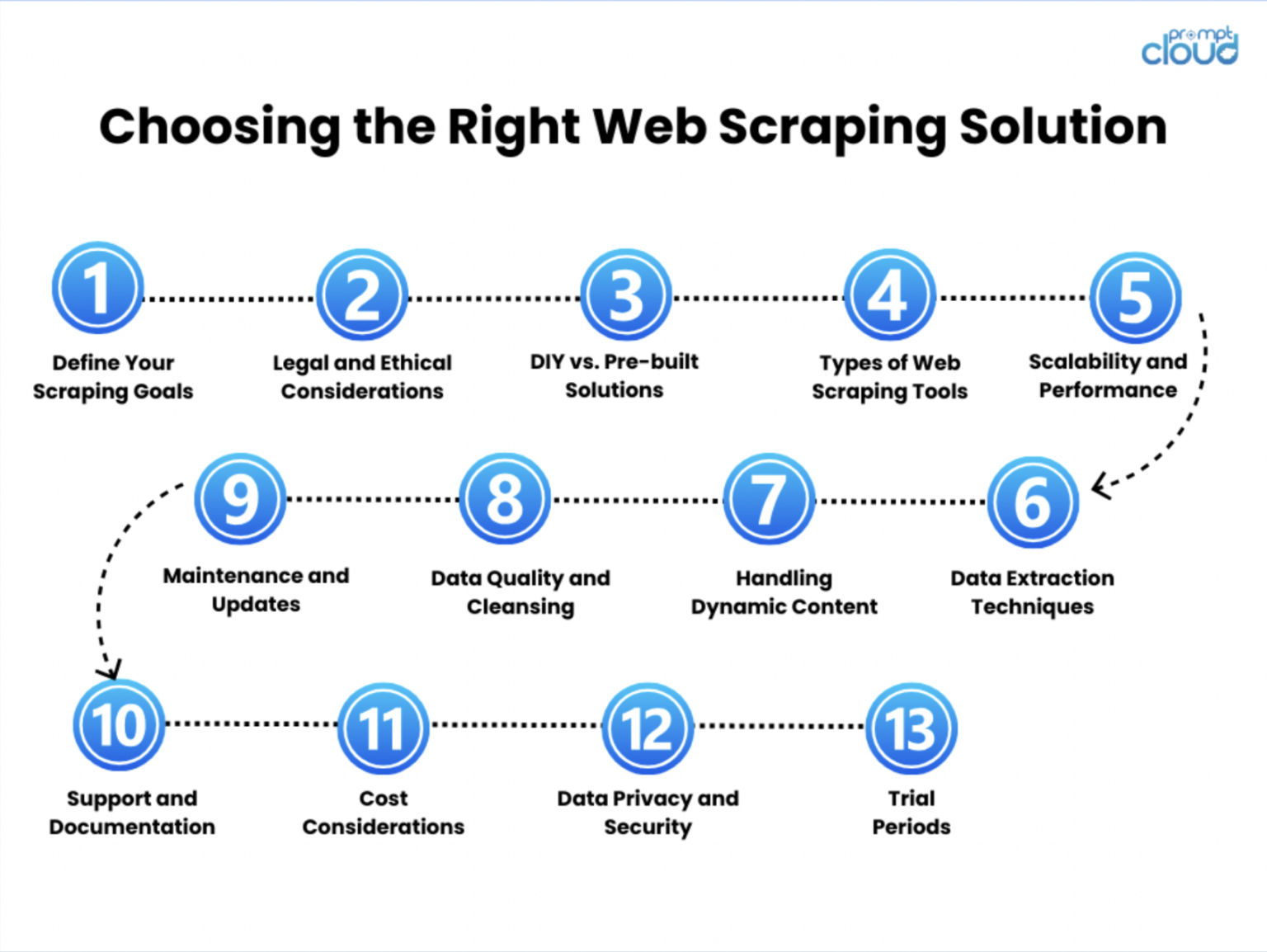
En esta guía completa, hemos explorado las diversas facetas del web scraping y ofrecemos información sobre sus técnicas, herramientas y mejores prácticas. Desde la comprensión básica del web scraping y su importancia en el mundo actual basado en datos, hasta técnicas avanzadas para tratar con sitios web dinámicos y con mucho JavaScript, hemos cubierto aspectos esenciales para equiparlo con el conocimiento para recolectar y utilizar datos web de manera efectiva.
¿Estás listo para aprovechar el poder del web scraping para tu negocio o proyecto? PromptCloud está aquí para guiarlo en este viaje. Con nuestra experiencia y soluciones personalizadas, podemos ayudarlo a navegar por el complejo panorama del web scraping, asegurándole que extraiga el máximo valor de sus esfuerzos de extracción de datos. ¡Póngase en contacto con PromptCloud hoy y libere todo el potencial de los datos web para su empresa!
Aproveche nuestros servicios para transformar su enfoque en la recopilación y el análisis de datos. Embarquémonos juntos en este viaje basado en datos: ¡comuníquese con PromptCloud ahora!