
Kompletny przewodnik po skrobaniu sieci: techniki, narzędzia i najlepsze praktyki
Opublikowany: 2024-01-11Wprowadzenie do skrobania sieci
Zrozumienie podstaw skrobania sieci
Skrobanie sieci to w swej istocie proces wydobywania danych ze stron internetowych. Technika ta pozwala na automatyczne zbieranie informacji z różnych stron internetowych, co czyni ją potężnym narzędziem do analizy danych, badań rynku i agregacji treści.

Źródło: https://www.upwork.com/resources/web-scraping-basics
Aby rozpocząć pracę z web scrapingiem, należy zrozumieć podstawowe komponenty sieci: HTML, CSS i JavaScript. HTML (HyperText Markup Language) tworzy strukturę stron internetowych, CSS (Kaskadowe arkusze stylów) służy do stylizacji, a JavaScript często dodaje interaktywność. Skrobanie sieci polega na analizowaniu kodu HTML w celu wyodrębnienia potrzebnych danych.
Istnieje kilka metod skrobania stron internetowych, począwszy od ręcznego wklejania kopii po techniki automatyczne wykorzystujące różne języki programowania, takie jak Python, lub narzędzia takie jak Scrapy i BeautifulSoup. Wybór metody zależy od złożoności zadania i wiedzy technicznej użytkownika.
Znaczenie skrobania sieci w dzisiejszym świecie opartym na danych
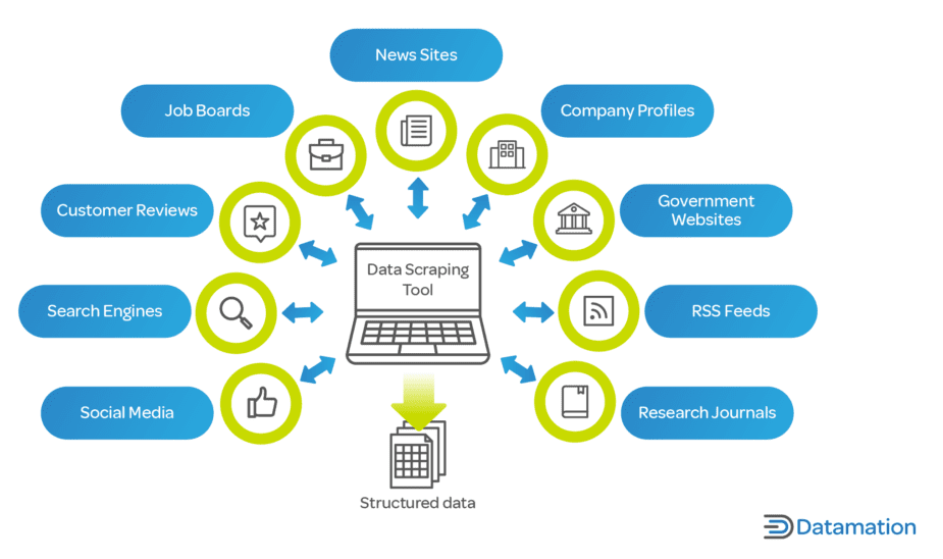
W dzisiejszej epoce cyfrowej dane są kluczowym zasobem przedsiębiorstw i badaczy. Web scraping jest niezbędny, ponieważ umożliwia szybkie gromadzenie i analizę ogromnych ilości danych z Internetu, co jest kluczowym czynnikiem w procesach decyzyjnych w różnych branżach.
W przypadku firm przeglądanie stron internetowych może zapewnić wgląd w trendy rynkowe, analizę konkurencji, preferencje klientów i nie tylko. Odgrywa kluczową rolę w sektorach takich jak handel elektroniczny, gdzie śledzenie cen produktów, opisów i dostępności ma kluczowe znaczenie.
W dziedzinie badań i środowiska akademickiego skrobanie sieci ułatwia gromadzenie danych na dużą skalę do badań w takich dziedzinach, jak nauki społeczne, informatyka i statystyka. Dane te, których ręczne gromadzenie może zająć miesiące, można zebrać w ułamku czasu za pomocą skrobania sieci.
Co więcej, web scraping nie ogranicza się tylko do dużych korporacji i instytucji akademickich. Niezależni programiści, małe firmy i hobbyści również wykorzystują skrobanie sieci do różnych projektów, począwszy od tworzenia aplikacji gromadzących artykuły z wiadomościami po prowadzenie osobistych projektów badawczych. Web scraping to nieocenione narzędzie we współczesnym świecie opartym na danych, oferujące możliwość przekształcenia ogromnego morza danych internetowych w przydatne spostrzeżenia.
Konfigurowanie środowiska skrobania sieci Web
Wybór odpowiednich narzędzi i języków do skrobania sieci
Źródło: https://fastercapital.com/startup-topic/web-scraping.html
Jeśli chodzi o scrapowanie stron internetowych, wybór odpowiednich narzędzi i języków programowania ma kluczowe znaczenie dla wydajności i łatwości użytkowania. Python stał się liderem w tej dziedzinie dzięki swojej prostocie i szerokiej gamie bibliotek zaprojektowanych specjalnie do skrobania stron internetowych, takich jak BeautifulSoup i Scrapy.
- Python : Znany ze swojej czytelności i prostoty, Python jest idealny zarówno dla początkujących, jak i ekspertów. Biblioteki takie jak BeautifulSoup upraszczają proces analizowania dokumentów HTML i XML, ułatwiając wyodrębnianie danych.
- Scrapy : ta platforma współpracy o otwartym kodzie źródłowym służy do wydobywania potrzebnych danych ze stron internetowych. To nie tylko biblioteka, ale kompletne rozwiązanie i platforma do skrobania stron internetowych.
- Inne języki : chociaż Python jest popularny, inne języki, takie jak Ruby, PHP i JavaScript (Node.js) również oferują możliwości przeglądania stron internetowych. Wybór może zależeć od Twoich istniejących umiejętności programowania lub konkretnych wymagań projektu.
Oprócz języków programowania możesz także rozważyć skorzystanie ze specjalistycznego oprogramowania do skrobania stron internetowych lub usług w chmurze, zwłaszcza jeśli nie lubisz kodować. Narzędzia takie jak Octoparse lub Dexi.io oferują bardziej wizualne podejście do skrobania, umożliwiając użytkownikom wskazywanie i klikanie danych, które chcą wyodrębnić.
Konfigurowanie pierwszego projektu skrobania sieci: przewodnik krok po kroku
- Zainstaluj Python i biblioteki : Rozpocznij od zainstalowania Pythona i pip, instalatora pakietu Pythona. Następnie zainstaluj biblioteki do skrobania stron internetowych, takie jak BeautifulSoup i żądania, uruchamiając żądania pip install Beautifulsoup4.
- Zidentyfikuj docelową witrynę internetową : wybierz witrynę, z której chcesz zeskrobać dane internetowe. Zapoznaj się z plikiem robots.txt witryny, aby poznać zasady skrobania.
- Sprawdź stronę internetową : użyj narzędzi programistycznych przeglądarki, aby sprawdzić strukturę HTML strony. Zidentyfikuj elementy HTML zawierające dane, które chcesz zeskrobać z sieci.
- Napisz skrypt skrobania : Napisz skrypt w języku Python, aby zażądać zawartości strony internetowej i przeanalizować kod HTML. Użyj BeautifulSoup lub innej biblioteki analizującej, aby wyodrębnić potrzebne dane.
- Uruchom swój skrypt i wyodrębnij dane : Wykonaj swój skrypt i zbierz dane. Pamiętaj, aby obsłużyć wyjątki i błędy z wdziękiem.
- Przechowuj zeskrobane dane : Zdecyduj, w jaki sposób będziesz przechowywać zeskrobane dane internetowe. Typowe opcje obejmują pliki CSV, JSON lub system baz danych, taki jak SQLite lub MongoDB.
- Praktyki skrobania oparte na szacunku : Wprowadź opóźnienia w skrypcie skrobania, aby uniknąć przeciążenia serwera i przestrzegaj zasad prywatności danych i wytycznych prawnych obowiązujących w witrynie.

Źródło: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Ten przewodnik stanowi podstawę Twojego pierwszego projektu skrobania sieciowego, zapewniając przegląd narzędzi i kroków związanych z konfiguracją podstawowego, ale skutecznego środowiska skrobania.
Zaawansowane techniki skrobania sieci
Radzenie sobie z witrynami dynamicznymi i obciążonymi JavaScriptem
Scraping dynamicznych witryn internetowych, zwłaszcza tych w dużym stopniu zależnych od JavaScriptu, wymaga bardziej zaawansowanych technik niż tradycyjne skrobanie oparte na HTML. Witryny te często ładują treść asynchronicznie, co oznacza, że potrzebne dane mogą nie znajdować się w początkowej odpowiedzi HTML.
- Zrozumienie AJAX i interfejsów API : Wiele dynamicznych witryn internetowych ładuje dane przy użyciu żądań AJAX (asynchroniczny JavaScript i XML). Sprawdzanie ruchu sieciowego za pomocą narzędzi programistycznych przeglądarki może ujawnić punkty końcowe interfejsu API, które zwracają dane w ustrukturyzowanym formacie, takim jak JSON, który może być łatwiejszy do zeskrobania z sieci niż analizowanie kodu HTML.
- Selenium i automatyzacja przeglądarki : Narzędzia takie jak Selenium pozwalają zautomatyzować przeglądarkę internetową, umożliwiając pobieranie treści renderowanych w JavaScript. Selenium może symulować rzeczywiste interakcje użytkownika, zapewniając załadowanie całej zawartości dynamicznej.
- Przeglądarki bezgłowe : narzędzia takie jak Puppeteer dla Node.js lub Headless Chrome mogą renderować stronę internetową bez graficznego interfejsu użytkownika, umożliwiając efektywne przeglądanie witryn obciążonych dużą ilością JavaScript.
- Obsługa nieskończonego przewijania i paginacji : w przypadku stron z nieskończonym przewijaniem lub wieloma stronami skrobak musi albo symulować działania użytkownika (takie jak przewijanie), albo obsługiwać parametry adresu URL w celu poruszania się po stronach.
Zaawansowane techniki analizy i czyszczenia danych
Po pomyślnym zeskrobaniu danych kolejnym kluczowym krokiem jest przeanalizowanie i oczyszczenie, aby zapewnić ich użyteczność i znaczenie.
- Wyrażenia regularne (Regex) : Wyrażenia regularne są potężnym narzędziem do wydobywania określonych wzorców z tekstu. Można ich używać do wyodrębniania numerów telefonów, adresów e-mail i innych standardowych formatów danych.
- Transformacja danych : Konwersja zebranych danych internetowych do żądanego formatu lub struktury, na przykład zmiana formatów dat lub łączenie oddzielnych pól danych, jest niezbędna do spójnej analizy.
- Obsługa problemów z Unicode i kodowaniem : Dane internetowe mogą mieć różne kodowania. Zapewnienie prawidłowej obsługi Unicode i innych kodowań jest niezbędne do utrzymania integralności zeskrobanych danych internetowych.
- Biblioteki do czyszczenia danych : wykorzystuj biblioteki takie jak Pandas w Pythonie do czyszczenia i przekształcania danych. Pandas oferuje rozbudowane funkcje do obsługi brakujących wartości, duplikatów i konwersji typów danych.
- Walidacja danych : Wprowadź kontrole w celu sprawdzenia dokładności i spójności zeskrobanych danych internetowych. Ten krok jest kluczowy, aby zidentyfikować wszelkie anomalie lub błędy w procesie zgarniania.
- Względy etyczne i ograniczanie szybkości : Zawsze przeglądaj sieć w sposób odpowiedzialny, nie przeciążając serwera i przestrzegając warunków korzystania z witryny. Wdrażaj ograniczanie szybkości i korzystaj z buforowania, aby zminimalizować żądania serwera.
Opanowując te zaawansowane techniki skrobania sieci, możesz efektywnie obsługiwać dynamiczne strony internetowe i mieć pewność, że zbierane dane są dokładne i czyste, gotowe do analizy lub integracji z aplikacjami.

Korzystanie z narzędzi i struktur do skrobania sieci
Przegląd popularnych narzędzi do skrobania sieci i ich funkcji
Narzędzia i struktury do skrobania sieci znacznie upraszczają proces wydobywania danych ze stron internetowych. Oto przegląd kilku popularnych:
- BeautifulSoup : biblioteka Pythona do analizowania dokumentów HTML i XML. Jest znany ze swojej prostoty i łatwości obsługi, szczególnie przydatny w projektach skrobania na małą skalę. BeautifulSoup umożliwia poruszanie się po drzewie analizy i wyszukiwanie elementów według atrybutów, co jest przydatne przy wydobywaniu określonych danych.
- Scrapy : kolejne narzędzie oparte na Pythonie, Scrapy to bardziej kompletna platforma do przeszukiwania i skrobania sieci. Jest wysoce wydajny, skalowalny i nadaje się do większych projektów lub wymagających złożonej ekstrakcji danych. Scrapy zapewnia kompletne rozwiązanie do żądania adresów URL, przetwarzania zwróconych stron i obsługi zeskrobanych danych.
- Selenium : pierwotnie narzędzie do automatyzacji przeglądarek internetowych do celów testowych, Selenium jest również skuteczne do skrobania zawartości dynamicznej. Umożliwia programowe sterowanie przeglądarką internetową, umożliwiając pobieranie treści renderowanych w JavaScript.
- Octoparse : narzędzie do wizualnego skrobania bez kodu, idealne dla osób bez rozległej wiedzy programistycznej. Oferuje interfejs typu „wskaż i kliknij”, umożliwiający wybranie danych, które chcesz zeskrobać z sieci, dzięki czemu proces jest intuicyjny.
- Lalkarz i dramaturg : te biblioteki Node.js służą do automatyzacji przeglądarki, szczególnie przydatne do skrobania witryn zawierających dużo JavaScript. Zapewniają wysoki poziom kontroli nad Chrome lub Chromium i doskonale nadają się do obsługi złożonych scenariuszy skrobania.
Praktyczne przykłady: używanie narzędzi takich jak Scrapy i BeautifulSoup
Przykład z BeautifulSoup :
z bs4 importuj BeautifulSoup
żądania importu
url = „http://example.com”
odpowiedź = żądania.get(url)
zupa = BeautifulSoup(response.text, 'html.parser')
# Wyodrębnianie wszystkich linków na stronie
dla linku w zupie.find_all('a'):
print(link.get('href'))
Ten prosty skrypt wykorzystuje BeautifulSoup do analizy strony internetowej i wydrukowania wszystkich hiperłączy.
Przykład ze Scrapym :
Aby użyć Scrapy, zazwyczaj tworzysz projekt Scrapy za pomocą pająka. Oto podstawowy przykład:
importuj scrapy
klasa PrzykładSpider(scrapy.Spider):
nazwa = „przykład”
dozwolone_domeny = ['example.com']
start_urls = ['http://example.com/']
def parse(samodzielność, odpowiedź):
# Wyodrębnianie zawartości za pomocą selektorów CSS
tytuły = odpowiedź.css('h2::tekst').extract()
plon {'tytuły': tytuły}
Ten pająk Scrapy zeskrobuje tytuły stron internetowych (zawarte w tagach h2) z example.com.
Te przykłady pokazują podstawowe użycie BeautifulSoup do prostych zadań i Scrapy do bardziej ustrukturyzowanych i skalowalnych projektów skrobania. Obydwa narzędzia mają swoje unikalne mocne strony, dzięki czemu nadają się do różnych typów potrzeb związanych ze skrobaniem sieci.
Radzenie sobie z typowymi wyzwaniami związanymi z przeglądaniem sieci
Pokonywanie CAPTCHA i blokad IP
Jednym z głównych wyzwań związanych z web scrapingiem jest radzenie sobie z CAPTCHA i zakazami IP, czyli mechanizmami używanymi przez strony internetowe w celu zapobiegania automatycznemu dostępowi.
Postępowanie z CAPTCHA :
- Usługi rozwiązywania CAPTCHA : korzystaj z usług rozwiązywania problemów CAPTCHA innych firm. Usługi te wykorzystują kombinację sztucznej inteligencji i wkładu ludzkiego do rozwiązywania problemów CAPTCHA za opłatą.
- Unikaj wywoływania CAPTCHA : wdrażaj strategie takie jak rotacja agentów użytkownika, przestrzeganie pliku robots.txt witryny i wysyłanie żądań w odstępach czasu zbliżonych do ludzkich, aby uniknąć CAPTCHA.
- Optyczne rozpoznawanie znaków (OCR) : w przypadku prostszych znaków CAPTCHA narzędzia OCR mogą czasami skutecznie dekodować tekst.
Unikanie i obsługa blokad IP :
- Rotacja adresów IP : użyj puli adresów IP i zmieniaj je, aby uniknąć blokowania. Można to osiągnąć za pośrednictwem usług proxy.
- Skrobanie z szacunkiem : przestrzegaj zasad skrobania obowiązujących w witrynie, utrzymuj powolny i stały współczynnik żądań oraz unikaj skrobania w godzinach szczytu.
- Mechanizmy ponawiania : wdrażaj mechanizmy ponawiania z wykładniczymi strategiami wycofywania, aby poradzić sobie z tymczasowymi zakazami IP lub problemami z siecią.
Efektywne strategie przechowywania i zarządzania danymi
Właściwe przechowywanie danych i zarządzanie nimi mają kluczowe znaczenie dla skutecznego przetwarzania danych zebranych w ramach web scrapingu.
Wybór odpowiedniego rozwiązania do przechowywania :
- Bazy danych : w przypadku danych strukturalnych idealne są relacyjne bazy danych, takie jak MySQL lub PostgreSQL. W przypadku bardziej elastycznych schematów lub danych nieustrukturyzowanych można zastosować bazy danych NoSQL, takie jak MongoDB.
- Przechowywanie oparte na plikach : proste projekty lub niewielkie ilości danych można przechowywać w formatach plików takich jak CSV, JSON lub XML.
Normalizacja danych i projektowanie schematów :
- Upewnij się, że schemat bazy danych skutecznie reprezentuje dane, które pobierasz. Normalizuj dane, aby zmniejszyć nadmiarowość i poprawić integralność.
Czyszczenie i transformacja danych :
- Oczyść i przekształć zeskrobane dane przed ich zapisaniem. Obejmuje to usuwanie duplikatów, poprawianie błędów i konwertowanie danych do żądanego formatu.
Skalowalność i wydajność :
- Jeśli masz do czynienia ze skrobaniem na dużą skalę, rozważ skalowalność. Użyj indeksowania baz danych, zoptymalizowanych zapytań i mechanizmów buforowania, aby zwiększyć wydajność.
Kopii zapasowych i odzyskiwania :
- Regularnie twórz kopie zapasowe danych, aby zapobiec ich utracie z powodu awarii sprzętu lub innych problemów. Przygotuj plan naprawczy.
Prywatność i bezpieczeństwo danych :
- Należy mieć na uwadze przepisy dotyczące ochrony danych i względy etyczne. Zabezpiecz przechowywanie i transmisję danych, aby chronić poufne informacje.
Skutecznie stawiając czoła tym powszechnym wyzwaniom, możesz mieć pewność, że Twoje projekty web scrapingu nie tylko odniosą sukces, ale także będą szanować granice prawne i etyczne, a także że gromadzone dane będą skutecznie przechowywane i zarządzane.
Najlepsze praktyki i wskazówki dotyczące wydajnego przeglądania sieci

Źródło: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Efektywne przeglądanie sieci może zapewnić wysoką jakość danych przy minimalnych nakładach zasobów. Oto kilka najlepszych praktyk i wskazówek, które pomogą zwiększyć efektywność i efektywność działań związanych z wyszukiwaniem stron internetowych.
Optymalizacja kodu skrobania pod kątem szybkości i wydajności
- Efektywne użycie selektora : Używaj wydajnych selektorów, które są specyficzne i bezpośrednie. Unikaj zbyt szerokich lub skomplikowanych selektorów XPath lub CSS, ponieważ mogą one spowolnić proces analizy.
- Równoczesne żądania : Implementuj równoczesne żądania, ale w rozsądnych granicach, aby uniknąć przeciążenia serwera. Narzędzia takie jak Scrapy pozwalają na łatwą konfigurację jednoczesnych żądań.
- Buforowanie : wdrożenie mechanizmów buforowania w celu przechowywania i ponownego wykorzystania wcześniej pobranych danych, co może znacznie zmniejszyć potrzebę wykonywania zbędnych żądań.
- Obsługa leniwego ładowania : w przypadku stron korzystających z leniwego ładowania upewnij się, że skrobak uruchamia ładowanie wszystkich niezbędnych elementów, prawdopodobnie poprzez symulowanie czynności przewijania.
- Wydajność ekstrakcji danych : wyodrębnij tylko niezbędne dane. Unikaj pobierania niepotrzebnej zawartości, takiej jak obrazy lub stylizacje, jeśli nie jest to potrzebne do celów skrobania.
- Zarządzanie sesjami : mądrze korzystaj z sesji i plików cookie, aby utrzymać stan tam, gdzie jest to konieczne, co może być szczególnie przydatne w przypadku witryn wymagających logowania.
Utrzymanie kodu skrobania: aktualizacje i skalowalność
- Regularne przeglądy kodu : regularnie przeglądaj i aktualizuj swój kod skrobania, aby dostosować się do wszelkich zmian w strukturze lub treści witryny.
- Projekt modułowy : Zbuduj swój kod w sposób modułowy, więc jeśli jedna część witryny ulegnie zmianie, wystarczy zaktualizować tylko określony moduł skrobaka.
- Obsługa błędów : zaimplementuj solidną obsługę błędów i rejestrowanie, aby szybko identyfikować i naprawiać problemy. Obejmuje to obsługę błędów HTTP, przekroczeń limitu czasu połączenia i błędów analizy danych.
- Kwestie dotyczące skalowalności : Zaprojektuj swoje rozwiązanie do skrobania tak, aby było skalowalne. W miarę wzrostu potrzeb w zakresie danych upewnij się, że system będzie w stanie obsłużyć zwiększone obciążenia i wolumeny danych bez konieczności wykonywania znaczących przeróbek.
- Testowanie automatyczne : wdrażaj automatyczne testy, aby sprawdzić ciągłą funkcjonalność skrobaka. Regularne testy mogą ostrzegać Cię o awariach spowodowanych zmianami w docelowej witrynie.
- Dokumentacja : zadbaj o dobrą dokumentację swojego kodu. Przejrzysta dokumentacja jest kluczowa dla konserwacji, szczególnie jeśli baza kodu jest współdzielona pomiędzy zespołem lub przekazywana do przyszłej konserwacji.
- Skrobanie z szacunkiem : Zawsze postępuj zgodnie z etycznymi wytycznymi dotyczącymi skrobania. Zachowaj równowagę między potrzebami dotyczącymi danych a wpływem na serwery docelowej witryny internetowej.
Przestrzegając tych praktyk, nie tylko sprawisz, że procesy skrobania stron internetowych będą bardziej wydajne i skuteczne, ale także zapewnisz ich trwałość i możliwość dostosowania do zmian w czasie.
W podsumowaniu
W tym obszernym przewodniku zbadaliśmy różne aspekty web scrapingu, oferując wgląd w jego techniki, narzędzia i najlepsze praktyki. Od podstawowego zrozumienia web scrapingu i jego znaczenia w dzisiejszym świecie opartym na danych, po zaawansowane techniki radzenia sobie z dynamicznymi stronami internetowymi z dużą ilością JavaScript, omówiliśmy istotne aspekty, aby wyposażyć Cię w wiedzę niezbędną do skutecznego gromadzenia i wykorzystywania danych internetowych.
Czy jesteś gotowy wykorzystać moc skrobania sieci w swojej firmie lub projekcie? PromptCloud jest tutaj, aby poprowadzić Cię w tej podróży. Dzięki naszej wiedzy specjalistycznej i dostosowanym rozwiązaniom możemy pomóc Ci poruszać się po złożonym środowisku web scrapingu, zapewniając, że wydobędziesz maksymalną wartość z wysiłków związanych z ekstrakcją danych. Skontaktuj się z PromptCloud już dziś i odblokuj pełny potencjał danych internetowych dla swojego przedsiębiorstwa!
Skorzystaj z naszych usług, aby zmienić swoje podejście do gromadzenia i analizy danych. Wyruszmy razem w tę podróż opartą na danych – skontaktuj się z PromptCloud już teraz!