
Der ultimative Leitfaden zum Scrapen des Webs: Techniken, Tools und Best Practices
Veröffentlicht: 2024-01-11Einführung in Web Scraping
Die Grundlagen des Web Scraping verstehen
Beim Web Scraping handelt es sich im Kern um das Extrahieren von Daten von Websites. Diese Technik ermöglicht die automatisierte Sammlung von Informationen von verschiedenen Webseiten und macht sie zu einem leistungsstarken Werkzeug für Datenanalyse, Marktforschung und Inhaltsaggregation.

Quelle: https://www.upwork.com/resources/web-scraping-basics
Um mit Web Scraping zu beginnen, muss man die grundlegenden Komponenten des Webs verstehen: HTML, CSS und JavaScript. HTML (HyperText Markup Language) bildet die Struktur von Webseiten, CSS (Cascading Style Sheets) wird für die Gestaltung verwendet und JavaScript sorgt häufig für Interaktivität. Beim Web-Scraping wird der HTML-Code analysiert, um die benötigten Daten zu extrahieren.
Es gibt verschiedene Methoden zum Web-Scraping, die vom manuellen Kopieren und Einfügen bis hin zu automatisierten Techniken mit verschiedenen Programmiersprachen wie Python oder Tools wie Scrapy und BeautifulSoup reichen. Die Wahl der Methode hängt von der Komplexität der Aufgabe und der technischen Expertise des Anwenders ab.
Die Bedeutung von Web Scraping in der heutigen datengesteuerten Welt
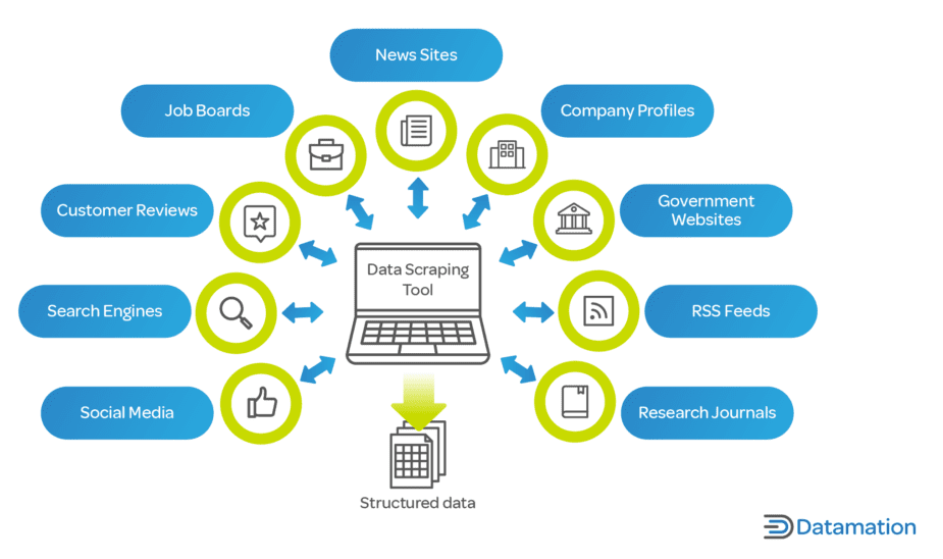
Im heutigen digitalen Zeitalter sind Daten ein entscheidender Vermögenswert für Unternehmen und Forscher. Web Scraping ist von entscheidender Bedeutung, da es die schnelle Erfassung und Analyse großer Datenmengen aus dem Internet ermöglicht, einem wichtigen Faktor bei Entscheidungsprozessen in allen Branchen.
Für Unternehmen kann Web Scraping Einblicke in Markttrends, Wettbewerbsanalysen, Kundenpräferenzen und mehr liefern. Es ist von entscheidender Bedeutung in Branchen wie dem E-Commerce, wo es entscheidend ist, den Überblick über Produktpreise, Beschreibungen und Verfügbarkeit zu behalten.
Im Bereich Forschung und Wissenschaft erleichtert Web Scraping die groß angelegte Datenerfassung für Studien in Bereichen wie Sozialwissenschaften, Informatik und Statistik. Diese Daten, deren manuelle Erfassung Monate dauern kann, können mit Web Scraping in einem Bruchteil der Zeit erfasst werden.
Darüber hinaus ist Web Scraping nicht nur auf große Unternehmen oder akademische Einrichtungen beschränkt. Unabhängige Entwickler, kleine Unternehmen und Hobbyisten nutzen Web Scraping auch für verschiedene Projekte, von der Entwicklung von Apps, die Nachrichtenartikel zusammenfassen, bis hin zur Durchführung persönlicher Forschungsprojekte. Web Scraping ist ein unschätzbar wertvolles Werkzeug in der heutigen datengesteuerten Welt und bietet die Möglichkeit, die riesige Menge an Webdaten in umsetzbare Erkenntnisse umzuwandeln.
Einrichten Ihrer Web Scraping-Umgebung
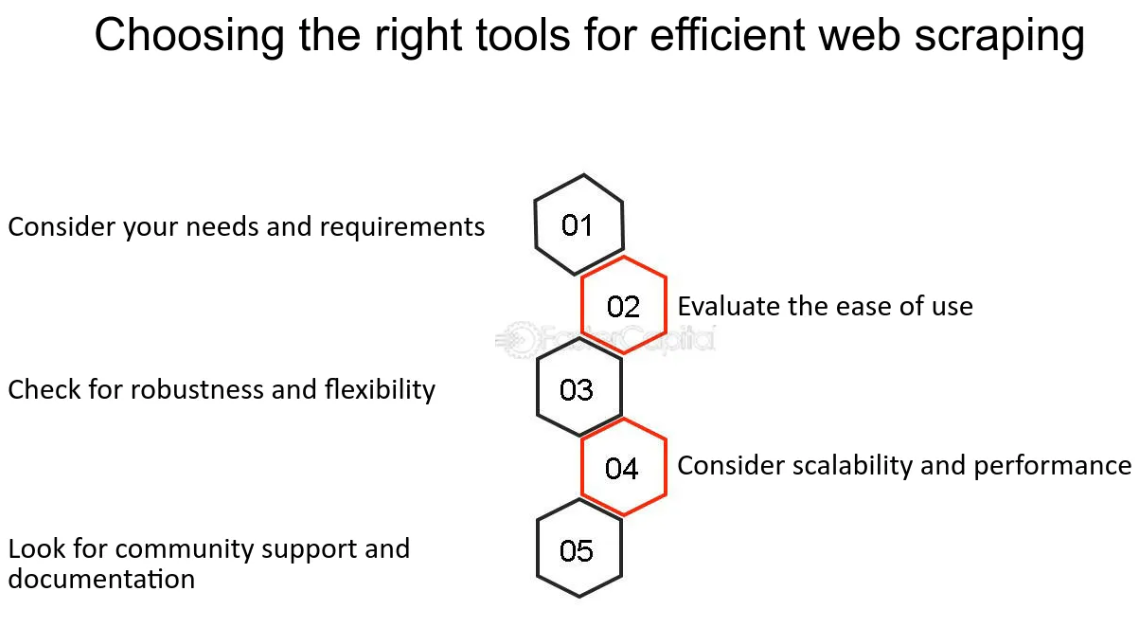
Auswahl der richtigen Tools und Sprachen für Web Scraping
Quelle: https://fastercapital.com/startup-topic/web-scraping.html
Beim Web Scraping ist die Auswahl der richtigen Tools und Programmiersprachen entscheidend für Effizienz und Benutzerfreundlichkeit. Python hat sich in diesem Bereich dank seiner Einfachheit und der großen Auswahl an Bibliotheken, die speziell für Web Scraping entwickelt wurden, wie BeautifulSoup und Scrapy, als Spitzenreiter herausgestellt.
- Python : Python ist für seine Lesbarkeit und Einfachheit bekannt und eignet sich sowohl für Anfänger als auch für Experten. Bibliotheken wie BeautifulSoup vereinfachen das Parsen von HTML- und XML-Dokumenten und erleichtern so das Extrahieren von Daten.
- Scrapy : Dieses Open-Source- und kollaborative Framework wird zum Extrahieren der benötigten Daten von Websites verwendet. Es handelt sich nicht nur um eine Bibliothek, sondern um eine vollständige Web-Scraping-Lösung und ein Framework.
- Andere Sprachen : Während Python beliebt ist, bieten auch andere Sprachen wie Ruby, PHP und JavaScript (Node.js) Web-Scraping-Funktionen. Die Wahl kann von Ihren vorhandenen Programmierkenntnissen oder spezifischen Projektanforderungen abhängen.
Neben Programmiersprachen könnten Sie auch die Verwendung spezieller Web-Scraping-Software oder Cloud-Dienste in Betracht ziehen, insbesondere wenn Sie sich nicht für das Programmieren interessieren. Tools wie Octoparse oder Dexi.io bieten einen visuelleren Ansatz für das Scraping und ermöglichen es Benutzern, auf die Daten zu zeigen und zu klicken, die sie extrahieren möchten.
Einrichten Ihres ersten Web Scraping-Projekts: Eine Schritt-für-Schritt-Anleitung
- Python und Bibliotheken installieren : Beginnen Sie mit der Installation von Python und pip, dem Paketinstallationsprogramm von Python. Als nächstes installieren Sie Web-Scraping-Bibliotheken wie BeautifulSoup und Requests, indem Sie pip install beautifulsoup4 request ausführen.
- Identifizieren Sie die Zielwebsite : Wählen Sie eine Website aus, von der Sie die Webdaten extrahieren möchten. Sehen Sie sich unbedingt die robots.txt-Datei der Website an, um die Scraping-Regeln zu verstehen.
- Überprüfen Sie die Webseite : Verwenden Sie die Entwicklertools Ihres Browsers, um die HTML-Struktur der Seite zu überprüfen. Identifizieren Sie die HTML-Elemente, die die Daten enthalten, die Sie im Web durchsuchen möchten.
- Schreiben Sie das Scraping-Skript : Schreiben Sie ein Python-Skript, um den Inhalt der Webseite anzufordern und den HTML-Code zu analysieren. Verwenden Sie BeautifulSoup oder eine andere Parsing-Bibliothek, um die benötigten Daten zu extrahieren.
- Führen Sie Ihr Skript aus und extrahieren Sie Daten : Führen Sie Ihr Skript aus und sammeln Sie die Daten. Stellen Sie sicher, dass Ausnahmen und Fehler ordnungsgemäß behandelt werden.
- Speichern Sie die Scraped-Daten : Entscheiden Sie, wie Sie Ihre Scrape-Web-Daten speichern möchten. Zu den gängigen Optionen gehören CSV-Dateien, JSON oder ein Datenbanksystem wie SQLite oder MongoDB.
- Respektvolle Scraping-Praktiken : Implementieren Sie Verzögerungen in Ihrem Scraping-Skript, um eine Überlastung des Servers zu vermeiden und den Datenschutz und die gesetzlichen Richtlinien der Website zu respektieren.

Quelle: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Dieser Leitfaden legt die Grundlage für Ihr erstes Web-Scraping-Projekt und bietet einen Überblick über die Tools und Schritte, die zum Einrichten einer einfachen, aber effektiven Scraping-Umgebung erforderlich sind.
Fortgeschrittene Web-Scraping-Techniken
Umgang mit dynamischen und JavaScript-lastigen Websites
Das Scraping dynamischer Websites, insbesondere solcher, die stark auf JavaScript angewiesen sind, erfordert fortgeschrittenere Techniken als herkömmliches HTML-basiertes Scraping. Diese Websites laden Inhalte oft asynchron, was bedeutet, dass die benötigten Daten möglicherweise nicht in der ersten HTML-Antwort vorhanden sind.
- AJAX und APIs verstehen : Viele dynamische Websites laden Daten mithilfe von AJAX-Anfragen (Asynchronous JavaScript and XML). Wenn Sie den Netzwerkverkehr mit den Entwicklertools Ihres Browsers untersuchen, können API-Endpunkte aufgedeckt werden, die Daten in einem strukturierten Format wie JSON zurückgeben, das einfacher im Web zu durchsuchen ist als das Parsen von HTML.
- Selenium und Browser-Automatisierung : Mit Tools wie Selenium können Sie einen Webbrowser automatisieren und so das Scraping von JavaScript-gerenderten Inhalten ermöglichen. Selenium kann echte Benutzerinteraktionen simulieren und so sicherstellen, dass alle dynamischen Inhalte geladen werden.
- Headless-Browser : Tools wie Puppeteer für Node.js oder Headless Chrome können eine Webseite ohne GUI rendern und ermöglichen so ein effizientes Scraping von JavaScript-lastigen Websites.
- Umgang mit unendlichem Scrollen und Paginierung : Bei Seiten mit unendlichem Scrollen oder mehreren Seiten muss Ihr Scraper entweder Benutzeraktionen (wie Scrollen) simulieren oder URL-Parameter verarbeiten, um durch die Seiten zu navigieren.
Erweiterte Techniken zur Datenanalyse und -bereinigung
Nach dem erfolgreichen Scrapen der Daten besteht der nächste entscheidende Schritt im Parsen und Bereinigen, um sicherzustellen, dass sie nutzbar und aussagekräftig sind.
- Reguläre Ausdrücke (Regex) : Reguläre Ausdrücke sind ein leistungsstarkes Werkzeug zum Extrahieren bestimmter Muster aus Text. Mit ihnen lassen sich Telefonnummern, E-Mail-Adressen und andere standardisierte Datenformate extrahieren.
- Datentransformation : Das Konvertieren von Scrape-the-Web-Daten in ein gewünschtes Format oder eine gewünschte Struktur, z. B. das Ändern von Datumsformaten oder das Zusammenführen separater Datenfelder, ist für eine konsistente Analyse unerlässlich.
- Umgang mit Unicode- und Codierungsproblemen : Webdaten können in verschiedenen Codierungen vorliegen. Die Sicherstellung der korrekten Handhabung von Unicode und anderen Kodierungen ist von entscheidender Bedeutung, um die Integrität der Scrape-the-Web-Daten aufrechtzuerhalten.
- Datenbereinigungsbibliotheken : Nutzen Sie Bibliotheken wie Pandas in Python zum Bereinigen und Transformieren von Daten. Pandas bietet umfangreiche Funktionen zum Umgang mit fehlenden Werten, Duplikaten und Datentypkonvertierungen.
- Datenvalidierung : Implementieren Sie Prüfungen, um die Genauigkeit und Konsistenz der Scrape-the-Web-Daten zu validieren. Dieser Schritt ist entscheidend, um etwaige Anomalien oder Fehler im Schabeprozess zu erkennen.
- Ethische Überlegungen und Ratenbegrenzung : Gehen Sie beim Surfen im Internet immer verantwortungsbewusst vor, indem Sie den Server nicht überlasten und die Nutzungsbedingungen der Website respektieren. Implementieren Sie eine Ratenbegrenzung und nutzen Sie Caching, um Serveranfragen zu minimieren.
Durch die Beherrschung dieser fortschrittlichen Web-Scraping-Techniken können Sie dynamische Websites effizient verwalten und sicherstellen, dass die von Ihnen gesammelten Daten korrekt und sauber sind und für die Analyse oder Integration in Ihre Anwendungen bereit sind.

Verwendung von Web-Scraping-Tools und Frameworks
Ein Überblick über beliebte Web-Scraping-Tools und ihre Funktionen
Web-Scraping-Tools und Frameworks vereinfachen den Prozess der Datenextraktion von Websites erheblich. Hier ist eine Übersicht über einige beliebte:
- BeautifulSoup : Eine Python-Bibliothek zum Parsen von HTML- und XML-Dokumenten. Es ist für seine Einfachheit und Benutzerfreundlichkeit bekannt und eignet sich besonders für kleine Scraping-Projekte. Mit BeautifulSoup können Sie im Parse-Baum navigieren und anhand von Attributen nach Elementen suchen, was zum Extrahieren spezifischer Daten praktisch ist.
- Scrapy : Ein weiteres Python-basiertes Tool. Scrapy ist eher ein vollständiges Web-Crawling- und Scraping-Framework. Es ist hocheffizient, skalierbar und eignet sich für größere Projekte oder solche, die eine komplexe Datenextraktion erfordern. Scrapy bietet eine umfassende Lösung zum Anfordern von URLs, zum Verarbeiten der zurückgegebenen Seiten und zum Umgang mit den gescrapten Daten.
- Selenium : Ursprünglich ein Tool zur Automatisierung von Webbrowsern zu Testzwecken, eignet sich Selenium auch zum Scraping dynamischer Inhalte. Es ermöglicht Ihnen die programmgesteuerte Steuerung eines Webbrowsers und ermöglicht so das Scraping von JavaScript-gerenderten Inhalten.
- Octoparse : Ein visuelles Scraping-Tool ohne Code, ideal für Personen ohne umfassende Programmierkenntnisse. Es bietet eine Point-and-Click-Oberfläche zur Auswahl der Daten, die Sie im Internet durchsuchen möchten, und macht den Vorgang dadurch intuitiv.
- Puppenspieler und Dramatiker : Diese Node.js-Bibliotheken werden für die Browserautomatisierung verwendet und sind besonders nützlich für das Scraping von JavaScript-lastigen Websites. Sie bieten ein hohes Maß an Kontrolle über Chrome oder Chromium und eignen sich hervorragend für die Bewältigung komplexer Scraping-Szenarien.
Praktische Beispiele: Verwendung von Tools wie Scrapy und BeautifulSoup
Beispiel mit BeautifulSoup :
aus bs4 Import BeautifulSoup
Importanfragen
URL = „http://example.com“
Antwort = Anfragen.get(URL)
Suppe = BeautifulSoup(response.text, 'html.parser')
# Extrahieren aller Links auf der Seite
für Link in Suppe.find_all('a'):
print(link.get('href'))
Dieses einfache Skript verwendet BeautifulSoup, um eine Webseite zu analysieren und alle Hyperlinks auszudrucken.
Beispiel mit Scrapy :
Um Scrapy zu verwenden, erstellen Sie normalerweise ein Scrapy-Projekt mit einem Spider. Hier ist ein einfaches Beispiel:
Scrapy importieren
Klasse BeispielSpider(scrapy.Spider):
name = 'Beispiel'
erlaubte_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(selbst, Antwort):
# Extrahieren des Inhalts mithilfe von CSS-Selektoren
titles = Response.css('h2::text').extract()
yield {'titles': titles}
Diese Scrapy-Spinne kratzt die Webtitel (in h2-Tags eingeschlossen) von example.com.
Diese Beispiele veranschaulichen die grundlegende Verwendung von BeautifulSoup für einfache Aufgaben und Scrapy für strukturiertere und skalierbarere Scraping-Projekte. Beide Tools haben ihre einzigartigen Stärken, wodurch sie für verschiedene Arten von Web-Scraping-Anforderungen geeignet sind.
Bewältigung häufiger Web-Scraping-Herausforderungen
Überwindung von CAPTCHAs und IP-Verboten
Eine der größten Herausforderungen beim Web Scraping ist der Umgang mit CAPTCHAs und IP-Verboten, also Mechanismen, mit denen Websites automatisierte Zugriffe verhindern.
Umgang mit CAPTCHAs :
- CAPTCHA-Lösungsdienste : Nutzen Sie CAPTCHA-Lösungsdienste von Drittanbietern. Diese Dienste nutzen eine Kombination aus KI und menschlichem Input, um gegen eine Gebühr CAPTCHAs zu lösen.
- Vermeiden Sie das Auslösen von CAPTCHAs : Implementieren Sie Strategien wie rotierende Benutzeragenten, respektieren Sie die robots.txt-Datei der Website und stellen Sie Anfragen in menschenähnlichen Abständen, um CAPTCHAs zu vermeiden.
- Optische Zeichenerkennung (OCR) : Bei einfacheren CAPTCHAs können OCR-Tools manchmal effektiv bei der Dekodierung des Textes sein.
Vermeidung und Umgang mit IP-Verboten :
- IP-Rotation : Verwenden Sie einen Pool von IP-Adressen und rotieren Sie diese, um eine Blockierung zu vermeiden. Dies kann durch Proxy-Dienste erreicht werden.
- Respektvolles Scraping : Halten Sie sich an die Scraping-Richtlinien der Website, sorgen Sie für eine langsame und konstante Anfragerate und vermeiden Sie Scraping während der Hauptverkehrszeiten.
- Wiederholungsmechanismen : Implementieren Sie Wiederholungsmechanismen mit exponentiellen Backoff-Strategien, um vorübergehende IP-Sperren oder Netzwerkprobleme zu bewältigen.
Effiziente Strategien zur Datenspeicherung und -verwaltung
Die ordnungsgemäße Datenspeicherung und -verwaltung ist für den effektiven Umgang mit den durch Web Scraping gesammelten Daten von entscheidender Bedeutung.
Auswahl der richtigen Speicherlösung :
- Datenbanken : Für strukturierte Daten sind relationale Datenbanken wie MySQL oder PostgreSQL ideal. Für flexiblere Schemata oder unstrukturierte Daten können NoSQL-Datenbanken wie MongoDB verwendet werden.
- Dateibasierte Speicherung : Einfache Projekte oder kleine Datenmengen können in Dateiformaten wie CSV, JSON oder XML gespeichert werden.
Datennormalisierung und Schemadesign :
- Stellen Sie sicher, dass Ihr Datenbankschema die Daten, die Sie auswerten, effektiv darstellt. Normalisieren Sie Daten, um Redundanz zu reduzieren und die Integrität zu verbessern.
Datenbereinigung und -transformation :
- Bereinigen und transformieren Sie die Scraped-Daten, bevor Sie sie speichern. Dazu gehört das Entfernen von Duplikaten, das Korrigieren von Fehlern und das Konvertieren von Daten in das gewünschte Format.
Skalierbarkeit und Leistung :
- Berücksichtigen Sie die Skalierbarkeit, wenn Sie mit groß angelegtem Scraping zu tun haben. Nutzen Sie Datenbankindizierung, optimierte Abfragen und Caching-Mechanismen, um die Leistung zu steigern.
Sicherung und Wiederherstellung :
- Sichern Sie Ihre Daten regelmäßig, um Verluste aufgrund von Hardwarefehlern oder anderen Problemen zu vermeiden. Halten Sie einen Wiederherstellungsplan bereit.
Datenschutz und Sicherheit :
- Beachten Sie Datenschutzgesetze und ethische Erwägungen. Sichern Sie Ihre Datenspeicherung und -übertragung, um sensible Informationen zu schützen.
Indem Sie diese allgemeinen Herausforderungen effektiv angehen, können Sie sicherstellen, dass Ihre Web-Scraping-Projekte nicht nur erfolgreich sind, sondern auch rechtliche und ethische Grenzen respektieren und dass die von Ihnen gesammelten Daten effizient gespeichert und verwaltet werden.
Best Practices und Tipps für effizientes Web Scraping

Quelle: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Web Scraping kann bei effizienter Durchführung qualitativ hochwertige Daten mit minimalem Ressourcenaufwand liefern. Hier finden Sie einige Best Practices und Tipps zur Steigerung der Effizienz und Effektivität Ihrer Web-Scraping-Bemühungen.
Optimieren Sie Ihren Scraping-Code für Geschwindigkeit und Effizienz
- Effiziente Selektornutzung : Verwenden Sie effiziente Selektoren, die spezifisch und direkt sind. Vermeiden Sie zu breite oder komplexe XPath- oder CSS-Selektoren, da diese den Parsing-Prozess verlangsamen können.
- Gleichzeitige Anforderungen : Implementieren Sie gleichzeitige Anforderungen, jedoch innerhalb angemessener Grenzen, um eine Überlastung des Servers zu vermeiden. Tools wie Scrapy ermöglichen die einfache Konfiguration gleichzeitiger Anfragen.
- Caching : Implementieren Sie Caching-Mechanismen zum Speichern und Wiederverwenden zuvor abgerufener Daten, wodurch die Notwendigkeit redundanter Anforderungen erheblich reduziert werden kann.
- Lazy Loading-Handhabung : Stellen Sie bei Seiten, die Lazy Loading verwenden, sicher, dass Ihr Scraper das Laden aller erforderlichen Elemente auslöst, möglicherweise durch Simulieren von Scroll-Aktionen.
- Effizienz der Datenextraktion : Extrahieren Sie nur die erforderlichen Daten. Vermeiden Sie das Herunterladen unnötiger Inhalte wie Bilder oder Stile, wenn diese nicht für Ihre Scraping-Ziele benötigt werden.
- Sitzungsverwaltung : Setzen Sie Sitzungen und Cookies sinnvoll ein, um den Status bei Bedarf aufrechtzuerhalten, was besonders nützlich für Websites sein kann, die eine Anmeldung erfordern.
Pflege Ihres Scraping-Codes: Updates und Skalierbarkeit
- Regelmäßige Codeüberprüfungen : Überprüfen und aktualisieren Sie Ihren Scraping-Code regelmäßig, um ihn an alle Änderungen in der Struktur oder dem Inhalt der Website anzupassen.
- Modulares Design : Strukturieren Sie Ihren Code modular, sodass Sie bei Änderungen an einem Teil der Website nur ein bestimmtes Modul Ihres Scrapers aktualisieren müssen.
- Fehlerbehandlung : Implementieren Sie eine robuste Fehlerbehandlung und -protokollierung, um Probleme schnell zu identifizieren und zu beheben. Dazu gehört die Behandlung von HTTP-Fehlern, Verbindungszeitüberschreitungen und Datenanalysefehlern.
- Überlegungen zur Skalierbarkeit : Gestalten Sie Ihre Scraping-Lösung so, dass sie skalierbar ist. Wenn Ihr Datenbedarf wächst, stellen Sie sicher, dass Ihr System höhere Lasten und Datenmengen ohne größere Nacharbeiten bewältigen kann.
- Automatisierte Tests : Implementieren Sie automatisierte Tests, um die laufende Funktionalität Ihres Scrapers zu überprüfen. Regelmäßige Tests können Sie auf Fehler aufmerksam machen, die durch Änderungen auf der Zielwebsite verursacht werden.
- Dokumentation : Halten Sie Ihren Code gut dokumentiert. Eine klare Dokumentation ist für die Wartung von entscheidender Bedeutung, insbesondere wenn die Codebasis von einem Team gemeinsam genutzt oder für zukünftige Wartungsarbeiten übergeben wird.
- Respektvolles Schaben : Befolgen Sie immer die ethischen Richtlinien zum Schaben. Halten Sie ein Gleichgewicht zwischen Ihren Datenanforderungen und den Auswirkungen auf die Server der Zielwebsite.
Durch die Einhaltung dieser Praktiken machen Sie Ihre Web-Scraping-Prozesse nicht nur effizienter und effektiver, sondern stellen auch sicher, dass sie nachhaltig und an Veränderungen im Laufe der Zeit anpassbar sind.
In Summe
In diesem umfassenden Leitfaden haben wir die verschiedenen Facetten des Web Scraping untersucht und Einblicke in seine Techniken, Tools und Best Practices gegeben. Vom grundlegenden Verständnis des Web Scraping und seiner Bedeutung in der heutigen datengesteuerten Welt bis hin zu fortgeschrittenen Techniken für den Umgang mit dynamischen und JavaScript-lastigen Websites haben wir wesentliche Aspekte behandelt, um Ihnen das Wissen zu vermitteln, um Webdaten effektiv zu sammeln und zu nutzen.
Sind Sie bereit, die Leistungsfähigkeit von Web Scraping für Ihr Unternehmen oder Projekt zu nutzen? PromptCloud ist hier, um Sie auf dieser Reise zu begleiten. Mit unserem Fachwissen und maßgeschneiderten Lösungen können wir Ihnen helfen, sich in der komplexen Landschaft des Web Scraping zurechtzufinden und sicherzustellen, dass Sie den größtmöglichen Nutzen aus Ihren Datenextraktionsbemühungen ziehen. Kontaktieren Sie PromptCloud noch heute und erschließen Sie das volle Potenzial von Webdaten für Ihr Unternehmen!
Nutzen Sie unsere Dienstleistungen, um Ihren Ansatz zur Datenerfassung und -analyse zu verändern. Begeben wir uns gemeinsam auf diese datengesteuerte Reise – wenden Sie sich jetzt an PromptCloud!