
La guida definitiva per raschiare il Web: tecniche, strumenti e migliori pratiche
Pubblicato: 2024-01-11Introduzione al Web Scraping
Comprendere le basi del Web Scraping
Il web scraping, in sostanza, è il processo di estrazione dei dati dai siti web. Questa tecnica consente la raccolta automatizzata di informazioni da varie pagine Web, rendendola un potente strumento per l'analisi dei dati, le ricerche di mercato e l'aggregazione dei contenuti.

Fonte: https://www.upwork.com/resources/web-scraping-basics
Per iniziare con il web scraping, è necessario comprendere i componenti di base del web: HTML, CSS e JavaScript. HTML (HyperText Markup Language) costituisce la struttura delle pagine web, CSS (Cascading Style Sheets) viene utilizzato per lo stile e JavaScript spesso aggiunge interattività. Il web scraping prevede l'analisi dell'HTML per estrarre i dati necessari.
Esistono diversi metodi per eseguire il web scraping, dal copia-incolla manuale alle tecniche automatizzate che utilizzano vari linguaggi di programmazione come Python o strumenti come Scrapy e BeautifulSoup. La scelta del metodo dipende dalla complessità del compito e dalle competenze tecniche dell'utente.
L'importanza del Web Scraping nel mondo odierno basato sui dati
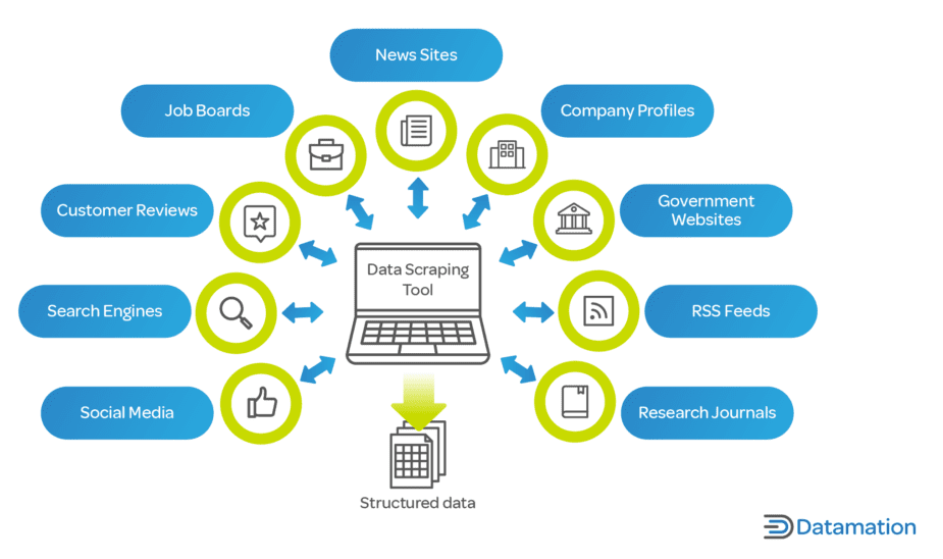
Nell'era digitale di oggi, i dati sono una risorsa fondamentale per aziende e ricercatori. Il web scraping è vitale perché consente la rapida raccolta e analisi di grandi quantità di dati da Internet, un fattore chiave nei processi decisionali in tutti i settori.
Per le aziende, il web scraping può fornire approfondimenti sulle tendenze del mercato, sull'analisi della concorrenza, sulle preferenze dei clienti e altro ancora. È fondamentale in settori come l'e-commerce, dove tenere traccia dei prezzi, delle descrizioni e della disponibilità dei prodotti è fondamentale.
Nel campo della ricerca e del mondo accademico, il web scraping facilita la raccolta di dati su larga scala per studi in campi come le scienze sociali, l'informatica e la statistica. Questi dati, che potrebbero richiedere mesi per essere raccolti manualmente, possono essere raccolti in una frazione del tempo con il web scraping.
Inoltre, il web scraping non è limitato solo alle grandi aziende o alle istituzioni accademiche. Anche sviluppatori indipendenti, piccole imprese e hobbisti utilizzano il web scraping per vari progetti, dallo sviluppo di app che aggregano articoli di notizie alla conduzione di progetti di ricerca personali. Il web scraping è uno strumento inestimabile nel mondo contemporaneo basato sui dati, poiché offre il potere di trasformare il vasto mare di dati web in informazioni fruibili.
Configurazione dell'ambiente di web scraping
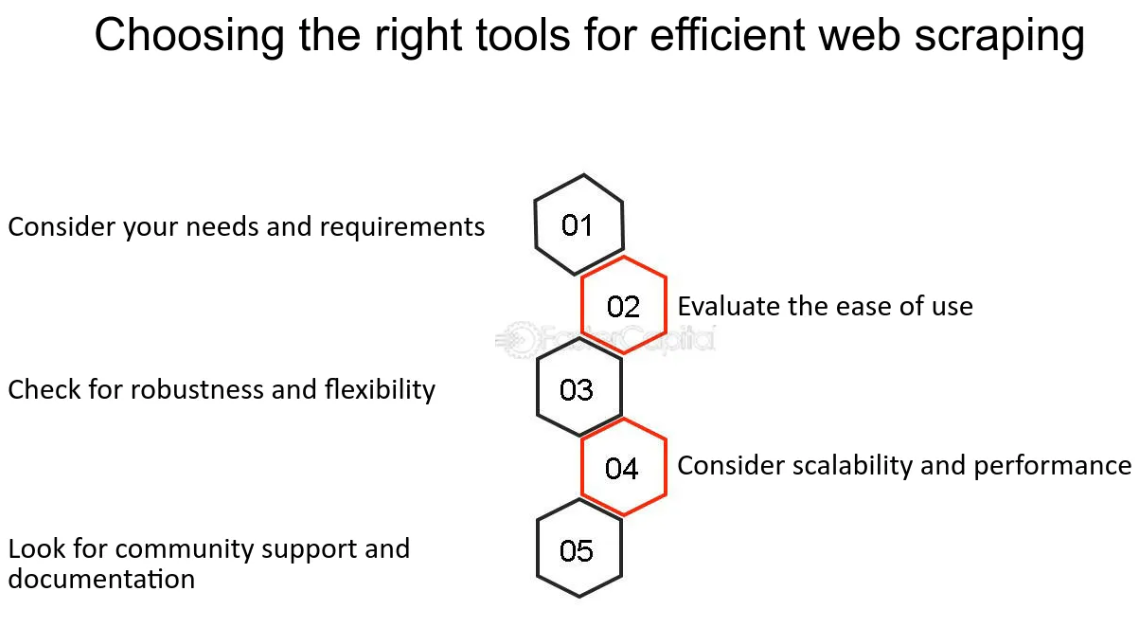
Scegliere gli strumenti e i linguaggi giusti per il Web Scraping
Fonte: https://fastercapital.com/startup-topic/web-scraping.html
Quando si tratta di web scraping, la selezione degli strumenti e dei linguaggi di programmazione giusti è fondamentale per l'efficienza e la facilità d'uso. Python è emerso come un pioniere in questo spazio, grazie alla sua semplicità e alla vasta gamma di librerie appositamente progettate per il web scraping, come BeautifulSoup e Scrapy.
- Python : noto per la sua leggibilità e semplicità, Python è ideale sia per principianti che per esperti. Librerie come BeautifulSoup semplificano il processo di analisi dei documenti HTML e XML, facilitando l'estrazione dei dati.
- Scrapy : questo framework open source e collaborativo viene utilizzato per estrarre i dati necessari dai siti Web. Non è solo una libreria, ma una soluzione e un framework completi per il web scraping.
- Altri linguaggi : sebbene Python sia popolare, anche altri linguaggi come Ruby, PHP e JavaScript (Node.js) offrono funzionalità di web scraping. La scelta può dipendere dalle tue capacità di programmazione esistenti o dai requisiti specifici del progetto.
Oltre ai linguaggi di programmazione, potresti anche prendere in considerazione l'utilizzo di software specializzati di web scraping o servizi cloud, soprattutto se non sei appassionato di programmazione. Strumenti come Octoparse o Dexi.io offrono un approccio più visivo allo scraping, consentendo agli utenti di puntare e fare clic sui dati che desiderano estrarre.
Impostazione del tuo primo progetto di web scraping: una guida passo passo
- Installa Python e le librerie : inizia installando Python e pip, il programma di installazione dei pacchetti Python. Successivamente, installa le librerie di web scraping come BeautifulSoup e le richieste eseguendo pip install beautifulsoup4 request.
- Identifica il sito Web di destinazione : scegli un sito Web in cui desideri acquisire i dati Web. Assicurati di rivedere il file robots.txt del sito per comprendere le regole di scraping.
- Ispeziona la pagina Web : utilizza gli strumenti di sviluppo del browser per ispezionare la struttura HTML della pagina. Identifica gli elementi HTML che contengono i dati che desideri recuperare dal web.
- Scrivi lo script di scraping : scrivi uno script Python per richiedere il contenuto della pagina web e analizzare l'HTML. Utilizza BeautifulSoup o un'altra libreria di analisi per estrarre i dati di cui hai bisogno.
- Esegui il tuo script ed estrai i dati : esegui il tuo script e raccogli i dati. Assicurati di gestire le eccezioni e gli errori con garbo.
- Archivia i dati raschiati : decidi come archiviare i dati web raschiati. Le opzioni comuni includono file CSV, JSON o un sistema di database come SQLite o MongoDB.
- Pratiche di scraping rispettose : implementa ritardi nello script di scraping per evitare di sovraccaricare il server e rispettare la privacy dei dati e le linee guida legali del sito web.

Fonte: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Questa guida pone le basi per il tuo primo progetto di web scraping, fornendo una panoramica degli strumenti e dei passaggi necessari per impostare un ambiente di scraping semplice ma efficace.
Tecniche avanzate di web scraping
Gestione di siti Web dinamici e ricchi di JavaScript
Lo scraping di siti Web dinamici, in particolare quelli fortemente dipendenti da JavaScript, richiede tecniche più avanzate rispetto al tradizionale scraping basato su HTML. Questi siti spesso caricano i contenuti in modo asincrono, il che significa che i dati necessari potrebbero non essere presenti nella risposta HTML iniziale.
- Comprensione di AJAX e delle API : molti siti Web dinamici caricano i dati utilizzando richieste AJAX (JavaScript asincrono e XML). L'ispezione del traffico di rete tramite gli strumenti di sviluppo del browser può rivelare endpoint API che restituiscono dati in un formato strutturato come JSON, che può essere più semplice da analizzare sul Web rispetto all'analisi dell'HTML.
- Selenium e automazione del browser : strumenti come Selenium consentono di automatizzare un browser Web, consentendo lo scraping di contenuti renderizzati con JavaScript. Selenium può simulare le interazioni reali dell'utente, garantendo che tutto il contenuto dinamico venga caricato.
- Browser headless : strumenti come Puppeteer per Node.js o Headless Chrome possono eseguire il rendering di una pagina Web senza una GUI, consentendo uno scraping efficiente di siti ricchi di JavaScript.
- Gestione dello scorrimento infinito e dell'impaginazione : per le pagine con scorrimento infinito o più pagine, il tuo raschietto deve simulare le azioni dell'utente (come lo scorrimento) o gestire i parametri URL per navigare tra le pagine.
Tecniche avanzate di analisi e pulizia dei dati
Dopo aver recuperato con successo i dati, il passaggio cruciale successivo è l'analisi e la pulizia per garantire che siano utilizzabili e significativi.
- Espressioni regolari (Regex) : le espressioni regolari sono un potente strumento per estrarre modelli specifici dal testo. Possono essere utilizzati per estrarre numeri di telefono, indirizzi e-mail e altri formati di dati standardizzati.
- Trasformazione dei dati : la conversione dei dati web nel formato o nella struttura desiderati, come la modifica dei formati delle date o l'unione di campi dati separati, è essenziale per un'analisi coerente.
- Gestione dei problemi Unicode e di codifica : i dati Web possono essere disponibili in varie codifiche. Garantire la corretta gestione di Unicode e altre codifiche è fondamentale per mantenere l'integrità dei dati web di scraping.
- Librerie di pulizia dei dati : utilizza librerie come Pandas in Python per pulire e trasformare i dati. Pandas offre ampie funzioni per la gestione di valori mancanti, duplicati e conversioni di tipi di dati.
- Convalida dei dati : implementa controlli per convalidare l'accuratezza e la coerenza dei dati web raccolti. Questo passaggio è fondamentale per identificare eventuali anomalie o errori nel processo di scraping.
- Considerazioni etiche e limitazione della velocità : naviga sempre in modo responsabile, non sovraccaricando il server e rispettando i termini di servizio del sito web. Implementare la limitazione della velocità e utilizzare la memorizzazione nella cache per ridurre al minimo le richieste del server.
Padroneggiando queste tecniche avanzate di web scraping, puoi gestire in modo efficiente siti Web dinamici e garantire che i dati raccolti siano accurati e puliti, pronti per l'analisi o l'integrazione nelle tue applicazioni.

Utilizzo di strumenti e framework di web scraping
Una panoramica dei più diffusi strumenti di web scraping e delle loro caratteristiche
Gli strumenti e i framework di web scraping semplificano notevolmente il processo di estrazione dei dati dai siti web. Ecco una panoramica di alcuni popolari:
- BeautifulSoup : una libreria Python per l'analisi di documenti HTML e XML. È noto per la sua semplicità e facilità d'uso, particolarmente utile per progetti di raschiatura su piccola scala. BeautifulSoup ti consente di navigare nell'albero di analisi e cercare elementi in base agli attributi, il che è utile per estrarre dati specifici.
- Scrapy : un altro strumento basato su Python, Scrapy è più un framework completo di scansione e scraping del web. È altamente efficiente, scalabile e adatto a progetti più grandi o a quelli che richiedono un'estrazione di dati complessa. Scrapy fornisce una soluzione completa per la richiesta di URL, l'elaborazione delle pagine restituite e la gestione dei dati raschiati.
- Selenium : originariamente uno strumento per automatizzare i browser Web a scopo di test, Selenium è efficace anche per lo scraping di contenuti dinamici. Ti consente di controllare a livello di codice un browser web, abilitando lo scraping di contenuti renderizzati con JavaScript.
- Octoparse : uno strumento di scraping visivo senza codice, ideale per persone senza una conoscenza approfondita della programmazione. Offre un'interfaccia punta e clicca per selezionare i dati che desideri raschiare il web, rendendo il processo intuitivo.
- Burattinaio e drammaturgo : queste librerie Node.js vengono utilizzate per l'automazione del browser, particolarmente utili per lo scraping di siti Web ricchi di JavaScript. Forniscono un elevato livello di controllo su Chrome o Chromium e sono eccellenti per gestire scenari di scraping complessi.
Esempi pratici: utilizzo di strumenti come Scrapy e BeautifulSoup
Esempio con BeautifulSoup :
da bs4 importa BeautifulSoup
richieste di importazione
URL = "http://esempio.com"
risposta = richieste.get(url)
zuppa = BeautifulSoup(risposta.testo, 'html.parser')
# Estrazione di tutti i collegamenti sulla pagina
per il collegamento in soup.find_all('a'):
print(link.get('href'))
Questo semplice script utilizza BeautifulSoup per analizzare una pagina Web e stampare tutti i collegamenti ipertestuali.
Esempio con Scrapy :
Per utilizzare Scrapy, in genere crei un progetto Scrapy con uno spider. Ecco un esempio di base:
importare raschiante
class EsempioSpider(scrapy.Spider):
nome = 'esempio'
domini_permessi = ['esempio.com']
start_urls = ['http://esempio.com/']
def analizzare(sé, risposta):
# Estrazione del contenuto utilizzando i selettori CSS
titoli = risposta.css('h2::testo').extract()
rendimento {'titoli': titoli}
Questo spider Scrapy raschierà i titoli web (racchiusi nei tag h2) da example.com.
Questi esempi dimostrano l'utilizzo di base di BeautifulSoup per attività semplici e Scrapy per progetti di scraping più strutturati e scalabili. Entrambi gli strumenti hanno i loro punti di forza unici, che li rendono adatti a diversi tipi di esigenze di web scraping.
Gestire le sfide comuni del web scraping
Superare i CAPTCHA e i divieti IP
Una delle maggiori sfide nel web scraping è la gestione dei CAPTCHA e dei divieti IP, che sono meccanismi utilizzati dai siti Web per impedire l'accesso automatizzato.
Gestire i CAPTCHA :
- Servizi di risoluzione CAPTCHA : utilizza servizi di risoluzione CAPTCHA di terze parti. Questi servizi utilizzano una combinazione di intelligenza artificiale e input umano per risolvere CAPTCHA a pagamento.
- Evita l'attivazione di CAPTCHA : implementa strategie come la rotazione degli user agent, il rispetto del file robots.txt del sito Web e l'invio di richieste a intervalli simili a quelli umani per evitare i CAPTCHA.
- Riconoscimento ottico dei caratteri (OCR) : per CAPTCHA più semplici, gli strumenti OCR a volte possono essere efficaci nel decodificare il testo.
Evitare e gestire i divieti IP :
- Rotazione IP : utilizza un pool di indirizzi IP e ruotali per evitare di essere bloccati. Ciò può essere ottenuto tramite servizi proxy.
- Scraping rispettoso : rispetta le politiche di scraping del sito web, mantieni un tasso di richieste lento e costante ed evita lo scraping durante le ore di punta.
- Meccanismi di nuovo tentativo : implementa meccanismi di nuovo tentativo con strategie di backoff esponenziale per gestire divieti IP temporanei o problemi di rete.
Strategie efficienti di archiviazione e gestione dei dati
La corretta archiviazione e gestione dei dati sono fondamentali per la gestione efficace dei dati raccolti tramite il web scraping.
Scegliere la giusta soluzione di archiviazione :
- Database : per i dati strutturati, i database relazionali come MySQL o PostgreSQL sono l'ideale. Per schemi più flessibili o dati non strutturati, è possibile utilizzare database NoSQL come MongoDB.
- Archiviazione basata su file : progetti semplici o piccole quantità di dati possono essere archiviati in formati di file come CSV, JSON o XML.
Normalizzazione dei dati e progettazione dello schema :
- Assicurati che lo schema del tuo database rappresenti efficacemente i dati che stai raccogliendo. Normalizza i dati per ridurre la ridondanza e migliorare l'integrità.
Pulizia e trasformazione dei dati :
- Pulisci e trasforma i dati raschiati prima di archiviarli. Ciò include la rimozione dei duplicati, la correzione degli errori e la conversione dei dati nel formato desiderato.
Scalabilità e prestazioni :
- Considera la scalabilità se hai a che fare con scraping su larga scala. Utilizza l'indicizzazione del database, le query ottimizzate e i meccanismi di memorizzazione nella cache per migliorare le prestazioni.
Backup e ripristino :
- Eseguire regolarmente il backup dei dati per evitare perdite dovute a guasti hardware o altri problemi. Avere un piano di recupero in atto.
Privacy e sicurezza dei dati :
- Prestare attenzione alle leggi sulla privacy dei dati e alle considerazioni etiche. Proteggi l'archiviazione e la trasmissione dei dati per proteggere le informazioni sensibili.
Affrontando in modo efficace queste sfide comuni, puoi garantire che i tuoi progetti di web scraping non solo abbiano successo ma rispettino anche i confini legali ed etici e che i dati raccolti siano archiviati e gestiti in modo efficiente.
Migliori pratiche e suggerimenti per un web scraping efficiente

Fonte: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Il web scraping, se eseguito in modo efficiente, può produrre dati di alta qualità con un dispendio minimo di risorse. Ecco alcune migliori pratiche e suggerimenti per migliorare l'efficienza e l'efficacia dei tuoi sforzi di web scraping.
Ottimizzazione del codice di scraping per velocità ed efficienza
- Utilizzo efficiente dei selettori : utilizzare selettori efficienti, specifici e diretti. Evita selettori XPath o CSS eccessivamente ampi o complessi, poiché possono rallentare il processo di analisi.
- Richieste simultanee : implementa richieste simultanee ma entro limiti ragionevoli per evitare di sovraccaricare il server. Strumenti come Scrapy consentono una facile configurazione di richieste simultanee.
- Caching : implementare meccanismi di caching per archiviare e riutilizzare i dati recuperati in precedenza, il che può ridurre significativamente la necessità di effettuare richieste ridondanti.
- Gestione del caricamento lento : per le pagine che utilizzano il caricamento lento, assicurati che il tuo scraper attivi il caricamento di tutti gli elementi necessari, possibilmente simulando azioni di scorrimento.
- Efficienza di estrazione dei dati : estrae solo i dati necessari. Evita di scaricare contenuti non necessari come immagini o stili se non necessari per i tuoi obiettivi di scraping.
- Gestione delle sessioni : utilizza sessioni e cookie con saggezza per mantenere lo stato dove necessario, il che può essere particolarmente utile per i siti che richiedono l'accesso.
Mantenere il codice di scraping: aggiornamenti e scalabilità
- Revisioni regolari del codice : rivedi e aggiorna regolarmente il tuo codice di scraping per adattarlo a eventuali modifiche nella struttura o nel contenuto del sito web.
- Design modulare : struttura il tuo codice in modo modulare, in modo che se cambia una parte del sito web, devi solo aggiornare un modulo specifico del tuo scraper.
- Gestione degli errori : implementa una gestione e una registrazione efficaci degli errori per identificare e risolvere rapidamente i problemi. Ciò include la gestione degli errori HTTP, dei timeout di connessione e degli errori di analisi dei dati.
- Considerazioni sulla scalabilità : progetta la tua soluzione di scraping in modo che sia scalabile. Man mano che le tue esigenze di dati crescono, assicurati che il tuo sistema possa gestire carichi e volumi di dati maggiori senza rielaborazioni significative.
- Test automatizzati : implementa test automatizzati per verificare la funzionalità continua del tuo raschietto. Test regolari possono avvisarti di errori causati da modifiche nel sito Web di destinazione.
- Documentazione : mantieni il tuo codice ben documentato. Una documentazione chiara è fondamentale per la manutenzione, soprattutto se la base di codice è condivisa da un team o consegnata per manutenzione futura.
- Raschiatura rispettosa : seguire sempre le linee guida etiche sulla raschiatura. Mantieni un equilibrio tra le tue esigenze di dati e l'impatto sui server del sito web di destinazione.
Aderendo a queste pratiche, non solo rendi i tuoi processi di web scraping più efficienti ed efficaci, ma assicuri anche che siano sostenibili e adattabili ai cambiamenti nel tempo.
In sintesi
In questa guida completa, abbiamo esplorato i vari aspetti del web scraping, offrendo approfondimenti sulle sue tecniche, strumenti e migliori pratiche. Dalla comprensione di base del web scraping e della sua importanza nel mondo odierno basato sui dati, alle tecniche avanzate per gestire siti Web dinamici e ricchi di JavaScript, abbiamo trattato gli aspetti essenziali per fornirti le conoscenze per raccogliere e utilizzare in modo efficace i dati web.
Sei pronto a sfruttare la potenza del web scraping per la tua azienda o progetto? PromptCloud è qui per guidarti in questo viaggio. Con la nostra esperienza e soluzioni su misura, possiamo aiutarti a navigare nel complesso panorama del web scraping, assicurandoti di ottenere il massimo valore dai tuoi sforzi di estrazione dei dati. Contatta PromptCloud oggi stesso e sfrutta tutto il potenziale dei dati Web per la tua azienda!
Sfrutta i nostri servizi per trasformare il tuo approccio alla raccolta e all'analisi dei dati. Intraprendiamo insieme questo viaggio basato sui dati: contatta PromptCloud adesso!