
Web'i Kazımak İçin Nihai Kılavuz: Teknikler, Araçlar ve En İyi Uygulamalar
Yayınlanan: 2024-01-11Web Scraping'e Giriş
Web Scraping'in Temellerini Anlamak
Web kazıma özünde web sitelerinden veri çıkarma işlemidir. Bu teknik, çeşitli web sayfalarından otomatik olarak bilgi toplanmasına olanak tanır ve bu da onu veri analizi, pazar araştırması ve içerik toplama için güçlü bir araç haline getirir.

Kaynak: https://www.upwork.com/resources/web-scraping-basics
Web kazımaya başlamak için web'in temel bileşenlerini anlamak gerekir: HTML, CSS ve JavaScript. HTML (HyperText Markup Language) web sayfalarının yapısını oluşturur, CSS (Basamaklı Stil Sayfaları) stil oluşturmak için kullanılır ve JavaScript sıklıkla etkileşim ekler. Web kazıma, ihtiyacınız olan verileri çıkarmak için HTML'nin ayrıştırılmasını içerir.
Python gibi çeşitli programlama dillerini veya Scrapy ve BeautifulSoup gibi araçları kullanarak manuel kopyalayıp yapıştırmadan otomatik tekniklere kadar web kazıma gerçekleştirmenin çeşitli yöntemleri vardır. Yöntem seçimi, görevin karmaşıklığına ve kullanıcının teknik uzmanlığına bağlıdır.
Günümüzün Veriye Dayalı Dünyasında Web Scraping'in Önemi
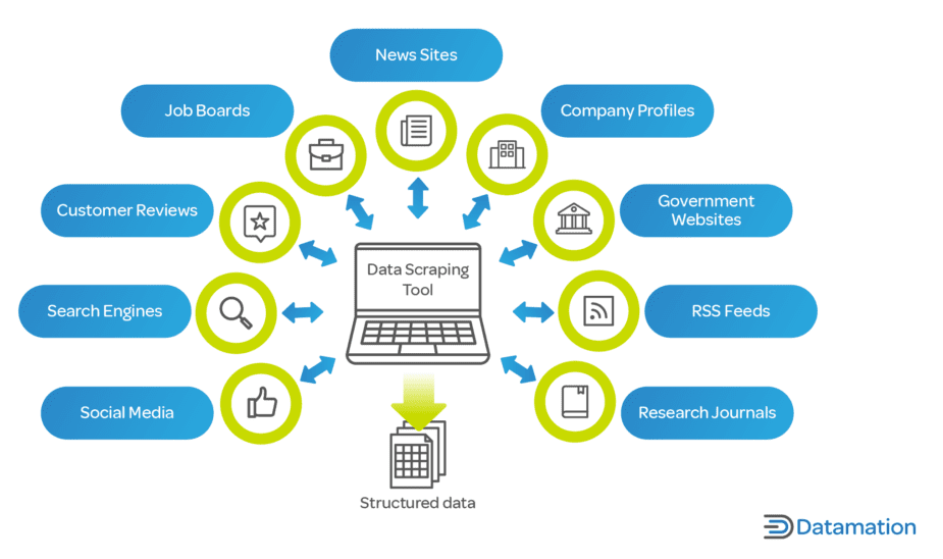
Günümüzün dijital çağında veriler, işletmeler ve araştırmacılar için kritik bir varlıktır. Web kazıma hayati öneme sahiptir çünkü endüstriler arası karar verme süreçlerinde önemli bir etken olan internetten büyük miktarlarda verinin hızlı bir şekilde toplanmasını ve analiz edilmesini sağlar.
İşletmeler için web kazıma, pazar eğilimleri, rakip analizi, müşteri tercihleri ve daha fazlası hakkında bilgi sağlayabilir. Ürün fiyatlarını, açıklamalarını ve bulunabilirliğini takip etmenin çok önemli olduğu e-ticaret gibi sektörlerde faydalıdır.
Araştırma ve akademi alanında web kazıma, sosyal bilimler, bilgisayar bilimi ve istatistik gibi alanlardaki çalışmalar için büyük ölçekli veri toplanmasını kolaylaştırır. Manuel olarak toplanması aylar sürebilecek bu veriler, web scraping ile çok daha kısa sürede toplanabilir.
Üstelik web kazıma sadece büyük şirketler veya akademik kurumlarla sınırlı değildir. Bağımsız geliştiriciler, küçük işletmeler ve hobiciler, haber makalelerini bir araya getiren uygulamalar geliştirmekten kişisel araştırma projeleri yürütmeye kadar çeşitli projeler için web kazıma işleminden de yararlanıyor. Web kazıma, çağdaş veri odaklı dünyada, geniş web veri denizini eyleme geçirilebilir içgörülere dönüştürme gücü sunan paha biçilmez bir araçtır.
Web Scraping Ortamınızı Kurma
Web Scraping için Doğru Araçları ve Dilleri Seçmek
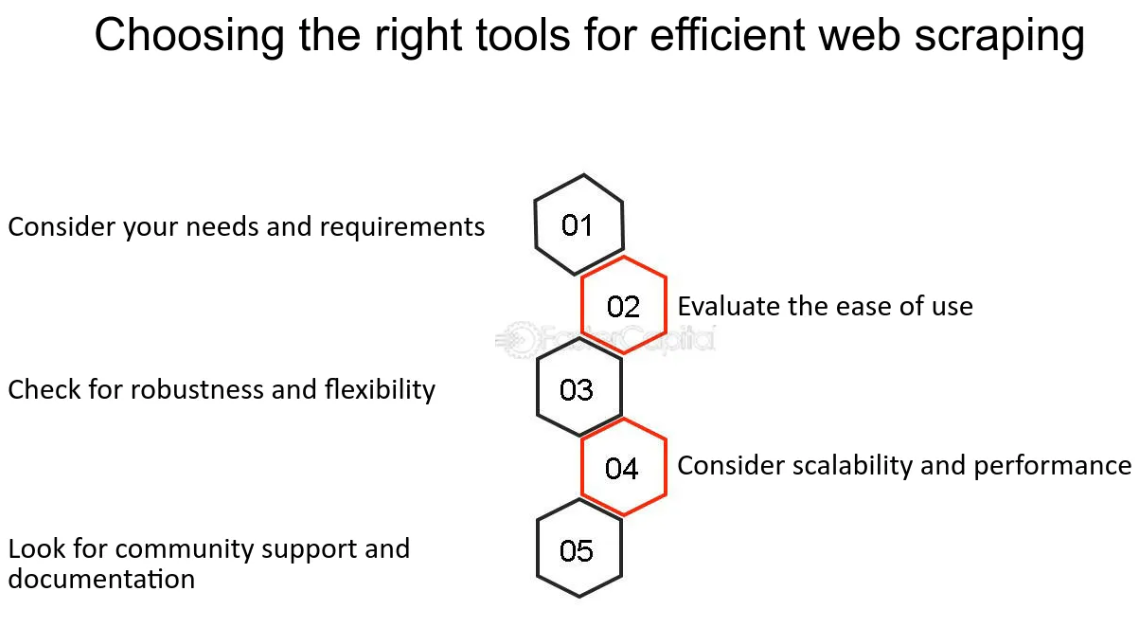
Kaynak: https://fastercapital.com/startup-topic/web-scraping.html
Web kazıma söz konusu olduğunda, doğru araçları ve programlama dillerini seçmek, verimlilik ve kullanım kolaylığı açısından çok önemlidir. Python, sadeliği ve BeautifulSoup ve Scrapy gibi web kazıma için özel olarak tasarlanmış geniş kütüphane yelpazesi sayesinde bu alanda öncü olarak ortaya çıkmıştır.
- Python : Okunabilirliği ve basitliğiyle bilinen Python, hem yeni başlayanlar hem de uzmanlar için idealdir. BeautifulSoup gibi kütüphaneler, HTML ve XML belgelerini ayrıştırma sürecini basitleştirerek veri çıkarmayı kolaylaştırır.
- Scrapy : Bu açık kaynaklı ve işbirlikçi çerçeve, ihtiyacınız olan verileri web sitelerinden çıkarmak için kullanılır. Bu sadece bir kütüphane değil, eksiksiz bir web kazıma çözümü ve çerçevesidir.
- Diğer Diller : Python popüler olsa da Ruby, PHP ve JavaScript (Node.js) gibi diğer diller de web kazıma yetenekleri sunar. Seçim, mevcut programlama becerilerinize veya özel proje gereksinimlerinize bağlı olabilir.
Programlama dillerinin yanı sıra, özellikle kodlamaya meraklı değilseniz, özel web kazıma yazılımı veya bulut hizmetlerini kullanmayı da düşünebilirsiniz. Octoparse veya Dexi.io gibi araçlar, kazıma işlemine daha görsel bir yaklaşım sunarak kullanıcıların çıkarmak istedikleri verileri işaret etmelerine ve tıklamalarına olanak tanır.
İlk Web Scraping Projenizi Kurma: Adım Adım Kılavuz
- Python ve Kütüphaneleri Kurun : Python'u ve Python'un paket yükleyicisi olan pip'i yükleyerek başlayın. Daha sonra, BeautifulSoup gibi web kazıma kitaplıklarını ve pip install güzelsoup4 isteklerini çalıştırarak istekleri yükleyin.
- Hedef Web Sitesini Belirleyin : Web verilerini kazımak istediğiniz bir web sitesi seçin. Kazıma kurallarını anlamak için sitenin robots.txt dosyasını incelediğinizden emin olun.
- Web Sayfasını İnceleyin : Sayfanın HTML yapısını incelemek için tarayıcınızın geliştirici araçlarını kullanın. Web'i kazımak istediğiniz verileri içeren HTML öğelerini tanımlayın.
- Kazıma Komut Dosyasını Yaz : Web sayfası içeriğini istemek ve HTML'yi ayrıştırmak için bir Python komut dosyası yazın. İhtiyacınız olan verileri çıkarmak için BeautifulSoup'u veya başka bir ayrıştırma kitaplığını kullanın.
- Komut Dosyanızı Çalıştırın ve Verileri Çıkarın : Komut dosyanızı yürütün ve verileri toplayın. İstisnaları ve hataları incelikle ele aldığınızdan emin olun.
- Kazınmış Verileri Saklayın : Kazınmış web verilerinizi nasıl saklayacağınıza karar verin. Yaygın seçenekler arasında CSV dosyaları, JSON veya SQLite veya MongoDB gibi bir veritabanı sistemi bulunur.
- Saygılı Kazıma Uygulamaları : Sunucunun aşırı yüklenmesini önlemek için kazıma komut dosyanızda gecikmeler uygulayın ve web sitesinin veri gizliliğine ve yasal yönergelerine saygı gösterin.

Kaynak: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Bu kılavuz, temel ancak etkili bir kazıma ortamı oluşturmayla ilgili araçlara ve adımlara genel bir bakış sunarak ilk web kazıma projenizin temelini oluşturur.
Gelişmiş Web Kazıma Teknikleri
Dinamik ve JavaScript Yoğun Web Siteleriyle Başa Çıkmak
Dinamik web sitelerini, özellikle de büyük ölçüde JavaScript'e bağımlı olanları kazımak, geleneksel HTML tabanlı kazımaya göre daha gelişmiş teknikler gerektirir. Bu siteler genellikle içeriği eşzamansız olarak yükler; bu, ihtiyacınız olan verilerin ilk HTML yanıtında bulunmayabileceği anlamına gelir.
- AJAX ve API'leri Anlamak : Birçok dinamik web sitesi, verileri AJAX (Eşzamansız JavaScript ve XML) isteklerini kullanarak yükler. Ağ trafiğini tarayıcınızın geliştirici araçları aracılığıyla incelemek, verileri JSON gibi yapılandırılmış bir biçimde döndüren API uç noktalarını ortaya çıkarabilir; bu, web'i kazımak için HTML'yi ayrıştırmaktan daha kolay olabilir.
- Selenyum ve Tarayıcı Otomasyonu : Selenyum gibi araçlar, bir web tarayıcısını otomatikleştirmenize olanak tanıyarak, JavaScript ile oluşturulan içeriğin kazınmasını sağlar. Selenium, tüm dinamik içeriğin yüklenmesini sağlayarak gerçek kullanıcı etkileşimlerini simüle edebilir.
- Başsız Tarayıcılar : Puppeteer for Node.js veya Headless Chrome gibi araçlar, GUI olmadan bir web sayfasını görüntüleyebilir ve JavaScript ağırlıklı sitelerin verimli bir şekilde ayıklanmasına olanak tanır.
- Sonsuz Kaydırma ve Sayfalandırmayı Yönetme : Sonsuz kaydırmalı veya birden fazla sayfalı sayfalar için, kazıyıcınızın sayfalar arasında gezinmek için kullanıcı eylemlerini (kaydırma gibi) simüle etmesi veya URL parametrelerini işlemesi gerekir.
Gelişmiş Veri Ayrıştırma ve Temizleme Teknikleri
Verileri başarılı bir şekilde kazıdıktan sonra, bir sonraki önemli adım, verilerin kullanılabilir ve anlamlı olduğundan emin olmak için ayrıştırma ve temizlemedir.
- Normal İfadeler (Regex) : Düzenli ifadeler, metinden belirli kalıpları çıkarmak için güçlü bir araçtır. Telefon numaralarını, e-posta adreslerini ve diğer standartlaştırılmış veri formatlarını çıkarmak için kullanılabilirler.
- Veri Dönüşümü : Tarih formatlarını değiştirmek veya ayrı veri alanlarını birleştirmek gibi web verilerini istenen formata veya yapıya dönüştürmek, tutarlı analiz için çok önemlidir.
- Unicode ve Kodlama Sorunlarını Ele Alma : Web verileri çeşitli kodlamalarda olabilir. Unicode ve diğer kodlamaların doğru şekilde işlenmesini sağlamak, web verilerinin kazınmasının bütünlüğünü korumak için hayati öneme sahiptir.
- Veri Temizleme Kitaplıkları : Verileri temizlemek ve dönüştürmek için Python'daki Pandas gibi kitaplıkları kullanın. Pandas, eksik değerleri, kopyaları ve veri türü dönüşümlerini yönetmek için kapsamlı işlevler sunar.
- Veri Doğrulaması : Web verilerinin kazınmasının doğruluğunu ve tutarlılığını doğrulamak için kontroller uygulayın. Bu adım, kazıma işlemindeki herhangi bir anormalliği veya hatayı tanımlamak için çok önemlidir.
- Etik Hususlar ve Hız Sınırlaması : Sunucuyu aşırı yüklemeyerek ve web sitesinin hizmet şartlarına saygı göstererek web'i her zaman sorumlu bir şekilde kazıyın. Hız sınırlamayı uygulayın ve sunucu isteklerini en aza indirmek için önbelleğe almayı kullanın.
Bu gelişmiş web kazıma tekniklerine hakim olarak, dinamik web sitelerini verimli bir şekilde yönetebilir ve topladığınız verilerin doğru ve temiz olduğundan, analize veya uygulamalarınıza entegrasyona hazır olduğundan emin olabilirsiniz.

Web Kazıma Araçlarını ve Çerçevelerini Kullanma
Popüler Web Kazıma Araçlarına ve Özelliklerine Genel Bakış
Web kazıma araçları ve çerçeveleri, web sitelerinden veri çıkarma sürecini büyük ölçüde basitleştirir. İşte bazı popüler olanlara genel bir bakış:
- BeautifulSoup : HTML ve XML belgelerini ayrıştırmaya yönelik bir Python kütüphanesi. Sadeliği ve kullanım kolaylığı ile bilinir, özellikle küçük ölçekli kazıma projeleri için kullanışlıdır. BeautifulSoup, ayrıştırma ağacında gezinmenize ve öğeleri niteliklere göre aramanıza olanak tanır; bu, belirli verileri çıkarmak için kullanışlıdır.
- Scrapy : Başka bir Python tabanlı araç olan Scrapy, daha çok eksiksiz bir web tarama ve kazıma çerçevesidir. Oldukça verimlidir, ölçeklenebilirdir ve daha büyük projeler veya karmaşık veri çıkarma gerektiren projeler için uygundur. Scrapy, URL istemek, döndürülen sayfaları işlemek ve alınan verileri işlemek için tam teşekküllü bir çözüm sunar.
- Selenium : Başlangıçta web tarayıcılarını test amacıyla otomatikleştirmeye yönelik bir araç olan Selenium, dinamik içeriğin kazınması için de etkilidir. JavaScript ile oluşturulan içeriğin kazınmasını sağlayarak bir web tarayıcısını programlı olarak kontrol etmenize olanak tanır.
- Octoparse : Kapsamlı programlama bilgisi olmayan kişiler için ideal, kodsuz, görsel kazıma aracı. Web'i kazımak istediğiniz verileri seçmek için işaretle ve tıkla arayüzü sunarak süreci sezgisel hale getirir.
- Kuklacı ve Oyun Yazarı : Bu Node.js kitaplıkları tarayıcı otomasyonu için kullanılır, özellikle JavaScript ağırlıklı web sitelerini ayıklamak için kullanışlıdır. Chrome veya Chromium üzerinde yüksek düzeyde kontrol sağlarlar ve karmaşık kazıma senaryolarının üstesinden gelmek için mükemmeldirler.
Uygulamalı Örnekler: Scrapy ve BeautifulSoup gibi Araçları Kullanmak
BeautifulSoup ile örnek :
bs4'ten BeautifulSoup'u içe aktar
içe aktarma istekleri
url = “http://example.com”
yanıt = request.get(url)
çorba = BeautifulSoup(response.text, 'html.parser')
# Sayfadaki tüm bağlantıların çıkarılması
Sopa.find_all('a') dosyasındaki bağlantı için:
print(link.get('href'))
Bu basit komut dosyası, bir web sayfasını ayrıştırmak ve tüm köprüleri yazdırmak için BeautifulSoup'u kullanır.
Scrapy ile örnek :
Scrapy'yi kullanmak için genellikle örümcek içeren bir Scrapy projesi oluşturursunuz. İşte temel bir örnek:
ithalat hurdası
sınıf ÖrnekSpider(scrapy.Spider):
isim = 'örnek'
izin verilen_alanlar = ['örnek.com']
start_urls = ['http://example.com/']
def ayrıştırma(kendisi, yanıt):
# CSS seçicileri kullanarak içeriğin çıkarılması
başlıklar = yanıt.css('h2::text').extract()
verim {'başlıklar': başlıklar}
Bu Scrapy örümceği, example.com'daki web başlıklarını (h2 etiketleriyle çevrelenmiş) sıyıracaktır.
Bu örnekler, basit görevler için BeautifulSoup'un ve daha yapılandırılmış ve ölçeklenebilir kazıma projeleri için Scrapy'nin temel kullanımını göstermektedir. Her iki aracın da kendine özgü güçlü yönleri vardır ve bu da onları farklı türdeki web kazıma ihtiyaçlarına uygun hale getirir.
Yaygın Web Scraping Zorluklarının Üstesinden Gelme
CAPTCHA'ların ve IP Yasaklamalarının Aşılması
Web kazımadaki en büyük zorluklardan biri, web sitelerinin otomatik erişimi önlemek için kullandığı mekanizmalar olan CAPTCHA'lar ve IP yasaklarıyla uğraşmaktır.
CAPTCHA'larla ilgilenmek :
- CAPTCHA Çözme Hizmetleri : Üçüncü taraf CAPTCHA çözme hizmetlerinden yararlanın. Bu hizmetler, CAPTCHA'ları bir ücret karşılığında çözmek için yapay zeka ve insan girdisinin bir kombinasyonunu kullanır.
- CAPTCHA'ları Tetiklemekten Kaçının : Kullanıcı aracılarını dönüşümlü kullanmak, web sitesinin robots.txt dosyasına saygı duymak ve CAPTCHA'lardan kaçınmak için insan benzeri aralıklarla isteklerde bulunmak gibi stratejiler uygulayın.
- Optik Karakter Tanıma (OCR) : Daha basit CAPTCHA'lar için OCR araçları bazen metnin kodunu çözmede etkili olabilir.
IP Yasaklarından Kaçınmak ve bunlarla Başa Çıkmak :
- IP Rotasyonu : Bir IP adresi havuzu kullanın ve engellenmeyi önlemek için bunları döndürün. Bu, proxy hizmetleri aracılığıyla sağlanabilir.
- Saygılı Kazıma : Web sitesinin kazıma politikalarına uyun, yavaş ve istikrarlı bir istek oranı sağlayın ve yoğun saatlerde kazıma yapmaktan kaçının.
- Yeniden Deneme Mekanizmaları : Geçici IP yasaklarını veya ağ sorunlarını ele almak için üstel geri çekilme stratejileriyle yeniden deneme mekanizmalarını uygulayın.
Verimli Veri Depolama ve Yönetim Stratejileri
Web kazıma yoluyla toplanan verilerin etkili bir şekilde işlenmesi için uygun veri depolama ve yönetimi çok önemlidir.
Doğru Depolama Çözümünü Seçmek :
- Veritabanları : Yapılandırılmış veriler için MySQL veya PostgreSQL gibi ilişkisel veritabanları idealdir. Daha esnek şemalar veya yapılandırılmamış veriler için MongoDB gibi NoSQL veritabanları kullanılabilir.
- Dosya Tabanlı Depolama : Basit projeler veya küçük miktarlardaki veriler CSV, JSON veya XML gibi dosya formatlarında saklanabilir.
Veri Normalleştirme ve Şema Tasarımı :
- Veritabanı şemanızın, kazıdığınız verileri etkili bir şekilde temsil ettiğinden emin olun. Artıklığı azaltmak ve bütünlüğü artırmak için verileri normalleştirin.
Veri Temizleme ve Dönüştürme :
- Kazınan verileri saklamadan önce temizleyin ve dönüştürün. Buna kopyaların kaldırılması, hataların düzeltilmesi ve verilerin istenen formata dönüştürülmesi de dahildir.
Ölçeklenebilirlik ve Performans :
- Büyük ölçekli kazımayla uğraşıyorsanız ölçeklenebilirliği düşünün. Performansı artırmak için veritabanı indekslemeyi, optimize edilmiş sorguları ve önbelleğe alma mekanizmalarını kullanın.
Yedekleme ve kurtarma :
- Donanım arızaları veya diğer sorunlardan kaynaklanan kayıpları önlemek için verilerinizi düzenli olarak yedekleyin. Bir kurtarma planınız olsun.
Veri Gizliliği ve Güvenliği :
- Veri gizliliği yasalarına ve etik hususlara dikkat edin. Hassas bilgileri korumak için veri depolamanızı ve iletiminizi güvence altına alın.
Bu ortak zorlukları etkili bir şekilde ele alarak, web kazıma projelerinizin yalnızca başarılı olmakla kalmayıp aynı zamanda yasal ve etik sınırlara saygılı olmasını ve topladığınız verilerin verimli bir şekilde saklanmasını ve yönetilmesini sağlayabilirsiniz.
Verimli Web Scraping için En İyi Uygulamalar ve İpuçları

Kaynak: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Web kazıma, verimli bir şekilde yapıldığında, minimum kaynak harcamasıyla yüksek kaliteli veriler sağlayabilir. Web kazıma çabalarınızın verimliliğini ve etkinliğini artıracak bazı en iyi uygulamaları ve ipuçlarını burada bulabilirsiniz.
Hız ve Verimlilik için Kazıma Kodunuzu Optimize Etme
- Verimli Seçici Kullanımı : Spesifik ve doğrudan etkili seçiciler kullanın. Ayrıştırma sürecini yavaşlatabilecekleri için aşırı geniş veya karmaşık XPath veya CSS seçicilerinden kaçının.
- Eşzamanlı İstekler : Eşzamanlı istekleri uygulayın ancak sunucunun aşırı yüklenmesini önlemek için makul sınırlar dahilinde. Scrapy gibi araçlar eşzamanlı isteklerin kolay yapılandırılmasına olanak tanır.
- Önbelleğe Alma : Daha önce getirilen verileri depolamak ve yeniden kullanmak için önbelleğe alma mekanizmaları uygulayın; bu, gereksiz istek yapma ihtiyacını önemli ölçüde azaltabilir.
- Tembel Yükleme İşleme : Tembel yükleme kullanan sayfalar için, kazıyıcınızın muhtemelen kaydırma eylemlerini simüle ederek gerekli tüm öğelerin yüklenmesini tetiklediğinden emin olun.
- Veri Çıkarma Verimliliği : Yalnızca gerekli verileri çıkarın. Kazıma hedefleriniz için gerekmiyorsa, resim veya stil gibi gereksiz içerikleri indirmekten kaçının.
- Oturum Yönetimi : Gerektiğinde durumu korumak için oturumları ve çerezleri akıllıca kullanın; bu, özellikle oturum açmayı gerektiren siteler için yararlı olabilir.
Kazıma Kodunuzu Korumak: Güncellemeler ve Ölçeklenebilirlik
- Düzenli Kod İncelemeleri : Web sitesi yapısındaki veya içeriğindeki değişikliklere uyum sağlamak için kazıma kodunuzu düzenli olarak inceleyin ve güncelleyin.
- Modüler Tasarım : Kodunuzu modüler bir şekilde yapılandırın; böylece web sitesinin bir kısmı değişirse, kazıyıcınızın yalnızca belirli bir modülünü güncellemeniz gerekir.
- Hata İşleme : Sorunları hızlı bir şekilde tanımlamak ve düzeltmek için güçlü hata işleme ve günlük kaydı uygulayın. Buna HTTP hatalarının, bağlantı zaman aşımlarının ve veri ayrıştırma hatalarının yönetimi de dahildir.
- Ölçeklenebilirlik Konuları : Kazıma çözümünüzü ölçeklenebilir olacak şekilde tasarlayın. Verilerinizin büyümesi gerektikçe, sisteminizin artan yükleri ve veri hacimlerini ciddi bir yeniden işleme gerek kalmadan karşılayabileceğinden emin olun.
- Otomatik Test : Kazıyıcınızın devam eden işlevselliğini kontrol etmek için otomatik testler uygulayın. Düzenli testler, hedef web sitesindeki değişikliklerin neden olduğu hatalar konusunda sizi uyarabilir.
- Belgeleme : Kodunuzu iyi belgelenmiş halde tutun. Özellikle kod tabanı bir ekip arasında paylaşılıyorsa veya gelecekteki bakım için devrediliyorsa, bakım için açık dokümantasyon çok önemlidir.
- Saygılı Kazıma : Daima etik kazıma kurallarına uyun. Veri ihtiyaçlarınız ile hedef web sitesinin sunucuları üzerindeki etki arasında bir denge kurun.
Bu uygulamalara bağlı kalarak web kazıma süreçlerinizi daha verimli ve etkili hale getirmekle kalmaz, aynı zamanda sürdürülebilir olmalarını ve zaman içindeki değişikliklere uyarlanabilir olmalarını da sağlarsınız.
Özetle
Bu kapsamlı kılavuzda, web kazımanın çeşitli yönlerini araştırdık; teknikleri, araçları ve en iyi uygulamaları hakkında bilgiler sunduk. Web kazımanın temel anlayışından ve günümüzün veri odaklı dünyasındaki öneminden, dinamik ve JavaScript ağırlıklı web siteleriyle başa çıkmak için ileri tekniklere kadar, web verilerini etkili bir şekilde toplamak ve kullanmak için sizi bilgiyle donatacak temel hususları ele aldık.
İşletmeniz veya projeniz için web kazımanın gücünden yararlanmaya hazır mısınız? PromptCloud bu yolculukta size rehberlik etmek için burada. Uzmanlığımız ve özel çözümlerimiz sayesinde, web kazımanın karmaşık ortamında gezinmenize yardımcı olabilir, veri çıkarma çabalarınızdan maksimum değer elde etmenizi sağlayabiliriz. PromptCloud ile bugün iletişime geçin ve kuruluşunuz için web verilerinin tüm potansiyelini ortaya çıkarın!
Veri toplama ve analiz yaklaşımınızı dönüştürmek için hizmetlerimizden yararlanın. Gelin bu veri odaklı yolculuğa birlikte çıkalım; hemen PromptCloud'a ulaşın!