
Le guide ultime pour gratter le Web : techniques, outils et meilleures pratiques
Publié: 2024-01-11Introduction au Web Scraping
Comprendre les bases du Web Scraping
Le Web scraping, à la base, est le processus d’extraction de données à partir de sites Web. Cette technique permet la collecte automatisée d'informations à partir de diverses pages Web, ce qui en fait un outil puissant pour l'analyse des données, les études de marché et l'agrégation de contenu.

Source : https://www.upwork.com/resources/web-scraping-basics
Pour commencer avec le web scraping, il faut comprendre les composants de base du web : HTML, CSS et JavaScript. HTML (HyperText Markup Language) forme la structure des pages Web, CSS (Cascading Style Sheets) est utilisé pour le style et JavaScript ajoute souvent de l'interactivité. Le Web scraping consiste à analyser le code HTML pour extraire les données dont vous avez besoin.
Il existe plusieurs méthodes pour effectuer du web scraping, allant du copier-coller manuel aux techniques automatisées utilisant divers langages de programmation comme Python ou des outils comme Scrapy et BeautifulSoup. Le choix de la méthode dépend de la complexité de la tâche et de l'expertise technique de l'utilisateur.
L'importance du Web Scraping dans le monde actuel axé sur les données
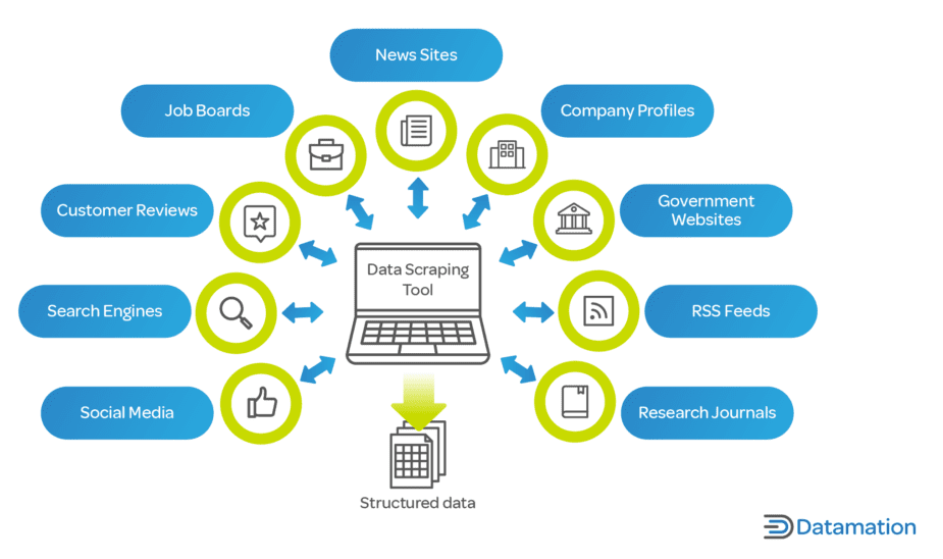
À l’ère numérique d’aujourd’hui, les données constituent un atout essentiel pour les entreprises et les chercheurs. Le web scraping est vital car il permet la collecte et l’analyse rapides de grandes quantités de données provenant d’Internet, un facteur clé dans les processus décisionnels dans tous les secteurs.
Pour les entreprises, le web scraping peut fournir des informations sur les tendances du marché, l'analyse des concurrents, les préférences des clients, etc. Cela joue un rôle déterminant dans des secteurs comme le commerce électronique, où le suivi des prix, des descriptions et de la disponibilité des produits est crucial.
Dans le domaine de la recherche et du monde universitaire, le web scraping facilite la collecte de données à grande échelle pour des études dans des domaines tels que les sciences sociales, l'informatique et les statistiques. Ces données, dont la collecte manuelle peut prendre des mois, peuvent être collectées en une fraction du temps grâce au web scraping.
De plus, le web scraping ne se limite pas aux grandes entreprises ou aux établissements universitaires. Les développeurs indépendants, les petites entreprises et les amateurs utilisent également le web scraping pour divers projets, allant du développement d'applications regroupant des articles de presse à la réalisation de projets de recherche personnels. Le Web scraping est un outil inestimable dans le monde contemporain axé sur les données, offrant le pouvoir de transformer la vaste mer de données Web en informations exploitables.
Configuration de votre environnement de Web Scraping
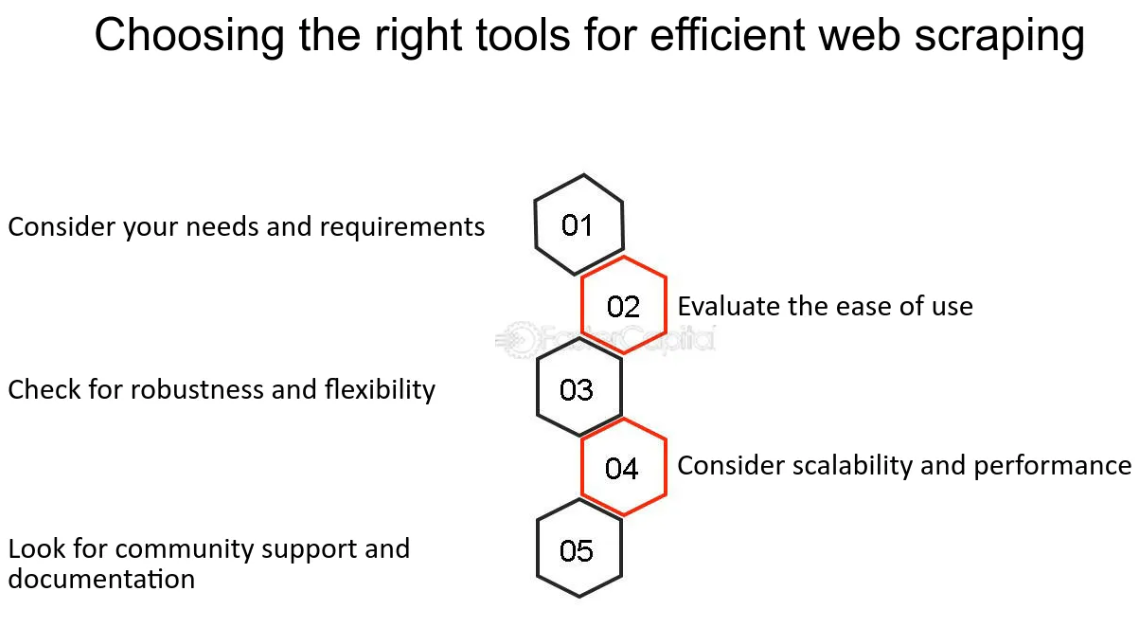
Choisir les bons outils et langages pour le Web Scraping
Source : https://fastercapital.com/startup-topic/web-scraping.html
Lorsqu'il s'agit de web scraping, la sélection des bons outils et langages de programmation est cruciale pour l'efficacité et la facilité d'utilisation. Python est devenu un leader dans ce domaine, grâce à sa simplicité et à la vaste gamme de bibliothèques spécialement conçues pour le web scraping, comme BeautifulSoup et Scrapy.
- Python : Connu pour sa lisibilité et sa simplicité, Python est idéal aussi bien pour les débutants que pour les experts. Des bibliothèques comme BeautifulSoup simplifient le processus d'analyse des documents HTML et XML, facilitant ainsi l'extraction des données.
- Scrapy : Ce framework open source et collaboratif est utilisé pour extraire les données dont vous avez besoin à partir de sites Web. Il ne s'agit pas simplement d'une bibliothèque, mais d'une solution et d'un framework complets de web scraping.
- Autres langages : bien que Python soit populaire, d'autres langages comme Ruby, PHP et JavaScript (Node.js) offrent également des fonctionnalités de web scraping. Le choix peut dépendre de vos compétences en programmation existantes ou des exigences spécifiques du projet.
Outre les langages de programmation, vous pouvez également envisager d'utiliser un logiciel de web scraping spécialisé ou des services cloud, surtout si vous n'aimez pas le codage. Des outils comme Octoparse ou Dexi.io offrent une approche plus visuelle du scraping, permettant aux utilisateurs de pointer et de cliquer sur les données qu'ils souhaitent extraire.
Configuration de votre premier projet Web Scraping : un guide étape par étape
- Installer Python et les bibliothèques : Commencez par installer Python et pip, le programme d'installation du package Python. Ensuite, installez les bibliothèques de scraping Web comme BeautifulSoup et les requêtes en exécutant les requêtes pip install beautifulsoup4.
- Identifiez le site Web cible : choisissez un site Web dont vous souhaitez récupérer les données Web. Assurez-vous de consulter le fichier robots.txt du site pour comprendre les règles de scraping.
- Inspecter la page Web : utilisez les outils de développement de votre navigateur pour inspecter la structure HTML de la page. Identifiez les éléments HTML qui contiennent les données que vous souhaitez extraire du Web.
- Écrivez le script Scraping : écrivez un script Python pour demander le contenu de la page Web et analyser le HTML. Utilisez BeautifulSoup ou une autre bibliothèque d'analyse pour extraire les données dont vous avez besoin.
- Exécutez votre script et extrayez les données : exécutez votre script et collectez les données. Assurez-vous de gérer les exceptions et les erreurs avec élégance.
- Stocker les données récupérées : décidez comment vous allez stocker vos données Web récupérées. Les options courantes incluent les fichiers CSV, JSON ou un système de base de données comme SQLite ou MongoDB.
- Pratiques de scraping respectueuses : mettez en œuvre des retards dans votre script de scraping pour éviter de surcharger le serveur et respectez la confidentialité des données et les directives légales du site Web.

Source : https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Ce guide jette les bases de votre premier projet de scraping Web, en fournissant un aperçu des outils et des étapes impliquées dans la mise en place d'un environnement de scraping basique mais efficace.
Techniques avancées de scraping Web
Gérer des sites Web dynamiques et lourds en JavaScript
Le scraping de sites Web dynamiques, en particulier ceux qui dépendent fortement de JavaScript, nécessite des techniques plus avancées que le scraping traditionnel basé sur HTML. Ces sites chargent souvent le contenu de manière asynchrone, ce qui signifie que les données dont vous avez besoin peuvent ne pas être présentes dans la réponse HTML initiale.
- Comprendre AJAX et les API : De nombreux sites Web dynamiques chargent des données à l'aide de requêtes AJAX (JavaScript asynchrone et XML). L'inspection du trafic réseau via les outils de développement de votre navigateur peut révéler des points de terminaison d'API qui renvoient des données dans un format structuré tel que JSON, ce qui peut être plus facile à gratter le Web qu'à analyser du HTML.
- Selenium et automatisation du navigateur : des outils comme Selenium vous permettent d'automatiser un navigateur Web, permettant ainsi de supprimer le contenu rendu par JavaScript. Selenium peut simuler des interactions utilisateur réelles, garantissant que tout le contenu dynamique est chargé.
- Navigateurs sans tête : des outils tels que Puppeteer pour Node.js ou Headless Chrome peuvent afficher une page Web sans interface graphique, permettant ainsi un scraping efficace des sites lourds en JavaScript.
- Gestion du défilement infini et de la pagination : pour les pages avec défilement infini ou plusieurs pages, votre scraper doit soit simuler les actions de l'utilisateur (comme le défilement), soit gérer les paramètres d'URL pour naviguer dans les pages.
Techniques avancées d’analyse et de nettoyage des données
Après avoir réussi à récupérer les données, la prochaine étape cruciale consiste à les analyser et à les nettoyer pour garantir qu'elles sont utilisables et significatives.
- Expressions régulières (Regex) : Les expressions régulières sont un outil puissant pour extraire des modèles spécifiques du texte. Ils peuvent être utilisés pour extraire des numéros de téléphone, des adresses e-mail et d'autres formats de données standardisés.
- Transformation des données : la conversion des données Web récupérées dans le format ou la structure souhaitée, comme la modification des formats de date ou la fusion de champs de données distincts, est essentielle pour une analyse cohérente.
- Gestion des problèmes d'Unicode et d'encodage : les données Web peuvent être présentées sous différents encodages. Assurer une gestion correcte de l'Unicode et d'autres encodages est essentiel pour maintenir l'intégrité des données Web récupérées.
- Bibliothèques de nettoyage de données : utilisez des bibliothèques comme Pandas en Python pour nettoyer et transformer les données. Pandas offre des fonctions étendues pour gérer les valeurs manquantes, les doublons et les conversions de types de données.
- Validation des données : mettre en œuvre des contrôles pour valider l'exactitude et la cohérence des données récupérées sur le Web. Cette étape est cruciale pour identifier d’éventuelles anomalies ou erreurs dans le processus de scraping.
- Considérations éthiques et limitation du débit : grattez toujours le Web de manière responsable en ne surchargeant pas le serveur et en respectant les conditions d'utilisation du site Web. Implémentez une limitation de débit et utilisez la mise en cache pour minimiser les requêtes du serveur.
En maîtrisant ces techniques avancées de web scraping, vous pouvez gérer efficacement les sites Web dynamiques et garantir que les données que vous collectez sont précises et propres, prêtes à être analysées ou intégrées dans vos applications.

Utilisation des outils et des frameworks de Web Scraping
Un aperçu des outils de Web Scraping populaires et de leurs fonctionnalités
Les outils et frameworks de web scraping simplifient considérablement le processus d’extraction de données à partir de sites Web. Voici un aperçu de quelques-uns des plus populaires :
- BeautifulSoup : Une bibliothèque Python pour analyser les documents HTML et XML. Il est connu pour sa simplicité et sa facilité d'utilisation, particulièrement utile pour les projets de scraping à petite échelle. BeautifulSoup vous permet de naviguer dans l'arborescence d'analyse et de rechercher des éléments par attributs, ce qui est pratique pour extraire des données spécifiques.
- Scrapy : Un autre outil basé sur Python, Scrapy est davantage un framework complet d'exploration et de scraping Web. Il est très efficace, évolutif et adapté aux projets plus importants ou à ceux nécessitant une extraction de données complexe. Scrapy fournit une solution à part entière pour demander des URL, traiter les pages renvoyées et gérer les données récupérées.
- Selenium : À l'origine un outil permettant d'automatiser les navigateurs Web à des fins de tests, Selenium est également efficace pour scraper du contenu dynamique. Il vous permet de contrôler par programme un navigateur Web, permettant ainsi de supprimer le contenu rendu par JavaScript.
- Octoparse : Un outil de scraping visuel sans code, idéal pour les personnes sans connaissances approfondies en programmation. Il offre une interface pointer-cliquer pour sélectionner les données que vous souhaitez récupérer sur le Web, rendant le processus intuitif.
- Marionnettiste et dramaturge : ces bibliothèques Node.js sont utilisées pour l'automatisation du navigateur, particulièrement utiles pour scraper des sites Web contenant beaucoup de JavaScript. Ils offrent un haut niveau de contrôle sur Chrome ou Chromium et sont excellents pour gérer des scénarios de scraping complexes.
Exemples pratiques : utilisation d'outils comme Scrapy et BeautifulSoup
Exemple avec BeautifulSoup :
à partir de bs4 importer BeautifulSoup
demandes d'importation
url = « http://exemple.com »
réponse = requêtes.get (url)
soupe = BeautifulSoup(response.text, 'html.parser')
# Extraire tous les liens de la page
pour le lien dans soup.find_all('a'):
print(lien.get('href'))
Ce script simple utilise BeautifulSoup pour analyser une page Web et imprimer tous les hyperliens.
Exemple avec Scrapy :
Pour utiliser Scrapy, vous créez généralement un projet Scrapy avec une araignée. Voici un exemple de base :
importer de la tremblante
classe ExempleSpider(scrapy.Spider):
nom = 'exemple'
Domaines_autorisés = ['exemple.com']
start_urls = ['http://exemple.com/']
def analyser (soi, réponse):
# Extraire le contenu à l'aide de sélecteurs CSS
titres = réponse.css('h2::text').extract()
rendement {'titres': titres}
Cette araignée Scrapy récupérera les titres Web (enfermés dans des balises h2) de example.com.
Ces exemples démontrent l'utilisation de base de BeautifulSoup pour des tâches simples et de Scrapy pour des projets de scraping plus structurés et évolutifs. Les deux outils ont leurs atouts uniques, ce qui les rend adaptés à différents types de besoins de web scraping.
Gérer les défis courants du Web Scraping
Surmonter les CAPTCHA et les interdictions IP
L’un des défis majeurs du web scraping est la gestion des CAPTCHA et des interdictions IP, qui sont des mécanismes utilisés par les sites Web pour empêcher l’accès automatisé.
Gérer les CAPTCHA :
- Services de résolution de CAPTCHA : utilisez des services de résolution de CAPTCHA tiers. Ces services utilisent une combinaison d’IA et de contribution humaine pour résoudre les CAPTCHA moyennant des frais.
- Évitez de déclencher des CAPTCHA : mettez en œuvre des stratégies telles que la rotation des agents utilisateurs, le respect du fichier robots.txt du site Web et l'envoi de requêtes à un intervalle proche d'un humain pour éviter les CAPTCHA.
- Reconnaissance optique de caractères (OCR) : Pour les CAPTCHA plus simples, les outils OCR peuvent parfois être efficaces pour décoder le texte.
Éviter et gérer les interdictions IP :
- Rotation IP : utilisez un pool d’adresses IP et faites-les pivoter pour éviter d’être bloqué. Ceci peut être réalisé via des services proxy.
- Scraping respectueux : adhérez aux politiques de scraping du site Web, maintenez un taux de requêtes lent et constant et évitez le scraping pendant les heures de pointe.
- Mécanismes de nouvelle tentative : implémentez des mécanismes de nouvelle tentative avec des stratégies d'attente exponentielles pour gérer les interdictions IP temporaires ou les problèmes de réseau.
Stratégies efficaces de stockage et de gestion des données
Un stockage et une gestion appropriés des données sont cruciaux pour le traitement efficace des données collectées via le web scraping.
Choisir la bonne solution de stockage :
- Bases de données : Pour les données structurées, les bases de données relationnelles comme MySQL ou PostgreSQL sont idéales. Pour des schémas plus flexibles ou des données non structurées, des bases de données NoSQL comme MongoDB peuvent être utilisées.
- Stockage basé sur des fichiers : des projets simples ou de petites quantités de données peuvent être stockés dans des formats de fichiers tels que CSV, JSON ou XML.
Normalisation des données et conception de schémas :
- Assurez-vous que le schéma de votre base de données représente efficacement les données que vous récupérez. Normalisez les données pour réduire la redondance et améliorer l’intégrité.
Nettoyage et transformation des données :
- Nettoyez et transformez les données récupérées avant de les stocker. Cela inclut la suppression des doublons, la correction des erreurs et la conversion des données au format souhaité.
Évolutivité et performances :
- Pensez à l’évolutivité si vous avez affaire à un scraping à grande échelle. Utilisez l'indexation de base de données, les requêtes optimisées et les mécanismes de mise en cache pour améliorer les performances.
Sauvegarde et récupération :
- Sauvegardez régulièrement vos données pour éviter toute perte due à des pannes matérielles ou à d'autres problèmes. Ayez un plan de rétablissement en place.
Confidentialité et sécurité des données :
- Soyez conscient des lois sur la confidentialité des données et des considérations éthiques. Sécurisez le stockage et la transmission de vos données pour protéger les informations sensibles.
En relevant efficacement ces défis courants, vous pouvez garantir que vos projets de web scraping sont non seulement réussis, mais également respectueux des limites juridiques et éthiques, et que les données que vous collectez sont stockées et gérées efficacement.
Meilleures pratiques et conseils pour un scraping Web efficace

Source : https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Le web scraping, lorsqu'il est effectué efficacement, peut produire des données de haute qualité avec une dépense de ressources minimale. Voici quelques bonnes pratiques et conseils pour améliorer l’efficience et l’efficacité de vos efforts de web scraping.
Optimiser votre code de scraping pour plus de rapidité et d'efficacité
- Utilisation efficace des sélecteurs : utilisez des sélecteurs efficaces, spécifiques et directs. Évitez les sélecteurs XPath ou CSS trop larges ou complexes, car ils peuvent ralentir le processus d'analyse.
- Requêtes simultanées : Implémentez des requêtes simultanées mais dans des limites raisonnables pour éviter de surcharger le serveur. Des outils comme Scrapy permettent une configuration facile des requêtes simultanées.
- Mise en cache : implémentez des mécanismes de mise en cache pour stocker et réutiliser les données précédemment récupérées, ce qui peut réduire considérablement le besoin de faire des requêtes redondantes.
- Gestion du chargement paresseux : pour les pages qui utilisent le chargement paresseux, assurez-vous que votre scraper déclenche le chargement de tous les éléments nécessaires, éventuellement en simulant des actions de défilement.
- Efficacité de l'extraction des données : extrayez uniquement les données nécessaires. Évitez de télécharger du contenu inutile comme des images ou du style s'il n'est pas nécessaire pour vos objectifs de scraping.
- Gestion des sessions : utilisez judicieusement les sessions et les cookies pour maintenir l'état si nécessaire, ce qui peut être particulièrement utile pour les sites qui nécessitent une connexion.
Maintenir votre code de scraping : mises à jour et évolutivité
- Examens réguliers du code : examinez et mettez à jour régulièrement votre code de scraping pour vous adapter à tout changement dans la structure ou le contenu du site Web.
- Conception modulaire : Structurez votre code de manière modulaire, de sorte que si une partie du site change, vous n'avez qu'à mettre à jour un module spécifique de votre scraper.
- Gestion des erreurs : implémentez une gestion et une journalisation des erreurs robustes pour identifier et résoudre rapidement les problèmes. Cela inclut la gestion des erreurs HTTP, des délais d'expiration de connexion et des erreurs d'analyse des données.
- Considérations d'évolutivité : concevez votre solution de scraping pour qu'elle soit évolutive. À mesure que vos besoins en données augmentent, assurez-vous que votre système peut gérer des charges et des volumes de données accrus sans retouches majeures.
- Tests automatisés : mettez en œuvre des tests automatisés pour vérifier la fonctionnalité continue de votre scraper. Des tests réguliers peuvent vous alerter des échecs provoqués par des modifications du site Web cible.
- Documentation : Gardez votre code bien documenté. Une documentation claire est cruciale pour la maintenance, surtout si la base de code est partagée au sein d'une équipe ou remise pour une maintenance future.
- Grattage respectueux : suivez toujours les directives éthiques en matière de grattage. Maintenez un équilibre entre vos besoins en données et l'impact sur les serveurs du site Web cible.
En adhérant à ces pratiques, vous rendez non seulement vos processus de web scraping plus efficients et efficaces, mais vous garantissez également qu'ils sont durables et adaptables aux changements au fil du temps.
En résumé
Dans ce guide complet, nous avons exploré les différentes facettes du web scraping, offrant un aperçu de ses techniques, outils et meilleures pratiques. De la compréhension de base du web scraping et de son importance dans le monde actuel axé sur les données, aux techniques avancées de gestion des sites Web dynamiques et utilisant beaucoup de JavaScript, nous avons couvert les aspects essentiels pour vous doter des connaissances nécessaires pour récolter et utiliser efficacement les données Web.
Êtes-vous prêt à exploiter la puissance du web scraping pour votre entreprise ou votre projet ? PromptCloud est là pour vous guider dans ce voyage. Grâce à notre expertise et à nos solutions sur mesure, nous pouvons vous aider à naviguer dans le paysage complexe du web scraping, en vous assurant d'extraire une valeur maximale de vos efforts d'extraction de données. Contactez PromptCloud dès aujourd'hui et libérez tout le potentiel des données Web pour votre entreprise !
Tirez parti de nos services pour transformer votre approche de la collecte et de l’analyse des données. Embarquons ensemble dans ce voyage basé sur les données – contactez PromptCloud dès maintenant !