
Panduan Utama untuk Mengikis Web: Teknik, Alat, dan Praktik Terbaik
Diterbitkan: 2024-01-11Pengantar Pengikisan Web
Memahami Dasar-Dasar Web Scraping
Web scraping, pada intinya, adalah proses mengekstraksi data dari situs web. Teknik ini memungkinkan pengumpulan informasi secara otomatis dari berbagai halaman web, menjadikannya alat yang ampuh untuk analisis data, riset pasar, dan agregasi konten.

Sumber: https://www.upwork.com/resources/web-scraping-basics
Untuk memulai dengan web scraping, kita perlu memahami komponen dasar web: HTML, CSS, dan JavaScript. HTML (HyperText Markup Language) membentuk struktur halaman web, CSS (Cascading Style Sheets) digunakan untuk penataan gaya, dan JavaScript sering kali menambahkan interaktivitas. Pengikisan web melibatkan penguraian HTML untuk mengekstrak data yang Anda perlukan.
Ada beberapa metode untuk melakukan web scraping, mulai dari copy-paste manual hingga teknik otomatis menggunakan berbagai bahasa pemrograman seperti Python atau tools seperti Scrapy dan BeautifulSoup. Pilihan metode bergantung pada kompleksitas tugas dan keahlian teknis pengguna.
Pentingnya Web Scraping di Dunia Berbasis Data Saat Ini
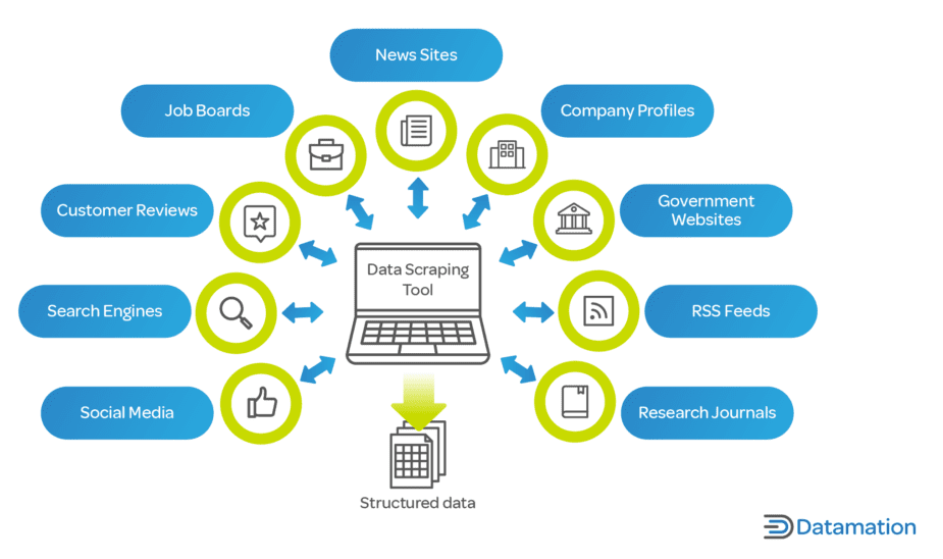
Di era digital saat ini, data merupakan aset penting bagi dunia usaha dan peneliti. Pengikisan web sangat penting karena memungkinkan pengumpulan dan analisis data dalam jumlah besar dari internet dengan cepat, yang merupakan pendorong utama dalam proses pengambilan keputusan di berbagai industri.
Untuk bisnis, web scraping dapat memberikan wawasan tentang tren pasar, analisis pesaing, preferensi pelanggan, dan banyak lagi. Hal ini penting dalam sektor-sektor seperti e-commerce, di mana pencatatan harga, deskripsi, dan ketersediaan produk sangatlah penting.
Di bidang penelitian dan akademisi, web scraping memfasilitasi pengumpulan data berskala besar untuk penelitian di berbagai bidang seperti ilmu sosial, ilmu komputer, dan statistik. Data ini, yang mungkin membutuhkan waktu berbulan-bulan untuk dikumpulkan secara manual, dapat dikumpulkan dalam waktu singkat dengan web scraping.
Selain itu, web scraping tidak terbatas hanya pada perusahaan besar atau institusi akademis. Pengembang independen, usaha kecil, dan penghobi juga memanfaatkan web scraping untuk berbagai proyek, mulai dari mengembangkan aplikasi yang mengumpulkan artikel berita hingga melakukan proyek penelitian pribadi. Pengikisan web adalah alat yang sangat berharga di dunia kontemporer yang berbasis data, menawarkan kemampuan untuk mengubah lautan data web yang luas menjadi wawasan yang dapat ditindaklanjuti.
Menyiapkan Lingkungan Scraping Web Anda
Memilih Alat dan Bahasa yang Tepat untuk Web Scraping
Sumber: https://fastercapital.com/startup-topic/web-scraping.html
Dalam hal web scraping, memilih alat dan bahasa pemrograman yang tepat sangat penting untuk efisiensi dan kemudahan penggunaan. Python telah muncul sebagai yang terdepan dalam bidang ini, berkat kesederhanaannya dan beragam perpustakaan yang dirancang khusus untuk web scraping, seperti BeautifulSoup dan Scrapy.
- Python : Dikenal karena keterbacaan dan kesederhanaannya, Python sangat ideal untuk pemula dan ahli. Perpustakaan seperti BeautifulSoup menyederhanakan proses penguraian dokumen HTML dan XML, sehingga lebih mudah mengekstrak data.
- Scrapy : Kerangka kerja sumber terbuka dan kolaboratif ini digunakan untuk mengekstraksi data yang Anda perlukan dari situs web. Ini bukan hanya perpustakaan tetapi solusi dan kerangka web scraping yang lengkap.
- Bahasa Lain : Meskipun Python populer, bahasa lain seperti Ruby, PHP, dan JavaScript (Node.js) juga menawarkan kemampuan web scraping. Pilihannya mungkin bergantung pada keahlian pemrograman Anda saat ini atau persyaratan proyek tertentu.
Selain bahasa pemrograman, Anda juga dapat mempertimbangkan untuk menggunakan perangkat lunak web scraping khusus atau layanan cloud, terutama jika Anda tidak tertarik pada coding. Alat seperti Octoparse atau Dexi.io menawarkan pendekatan yang lebih visual untuk pengikisan, memungkinkan pengguna mengarahkan dan mengeklik data yang ingin mereka ekstrak.
Menyiapkan Proyek Scraping Web Pertama Anda: Panduan Langkah demi Langkah
- Instal Python dan Perpustakaan : Mulailah dengan menginstal Python dan pip, penginstal paket Python. Selanjutnya, instal pustaka web scraping seperti BeautifulSoup dan permintaan dengan menjalankan permintaan pip install beautifulsoup4.
- Identifikasi Situs Web Target : Pilih situs web yang ingin Anda kikis data webnya. Pastikan untuk meninjau file robots.txt situs untuk memahami aturan pengikisan.
- Periksa Halaman Web : Gunakan alat pengembang browser Anda untuk memeriksa struktur HTML halaman. Identifikasi elemen HTML yang berisi data yang ingin Anda kikis webnya.
- Write the Scraping Script : Tulis skrip Python untuk meminta konten halaman web dan parsing HTML. Gunakan BeautifulSoup atau pustaka parsing lainnya untuk mengekstrak data yang Anda perlukan.
- Jalankan Skrip Anda dan Ekstrak Data : Jalankan skrip Anda dan kumpulkan datanya. Pastikan untuk menangani pengecualian dan kesalahan dengan baik.
- Simpan Data yang Digores : Putuskan bagaimana Anda akan menyimpan data web yang tergores. Opsi umum mencakup file CSV, JSON, atau sistem database seperti SQLite atau MongoDB.
- Praktik Pengikisan yang Hormat : Terapkan penundaan dalam skrip pengikisan Anda untuk menghindari membebani server, dan hormati privasi data dan pedoman hukum situs web.

Sumber: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Panduan ini menetapkan dasar untuk proyek web scraping pertama Anda, memberikan gambaran umum tentang alat dan langkah-langkah yang terlibat dalam menyiapkan lingkungan scraping yang dasar namun efektif.
Teknik Pengikisan Web Tingkat Lanjut
Berurusan dengan Situs Web Dinamis dan Banyak JavaScript
Mengikis situs web dinamis, terutama yang sangat bergantung pada JavaScript, memerlukan teknik yang lebih canggih dibandingkan dengan menggores berbasis HTML tradisional. Situs-situs ini sering kali memuat konten secara asinkron, artinya data yang Anda perlukan mungkin tidak ada dalam respons HTML awal.
- Memahami AJAX dan API : Banyak situs web dinamis memuat data menggunakan permintaan AJAX (Asynchronous JavaScript dan XML). Memeriksa lalu lintas jaringan melalui alat pengembang browser Anda dapat mengungkapkan titik akhir API yang mengembalikan data dalam format terstruktur seperti JSON, yang lebih mudah untuk mengikis web daripada menguraikan HTML.
- Selenium dan Otomatisasi Peramban : Alat seperti Selenium memungkinkan Anda mengotomatisasi peramban web, memungkinkan pengikisan konten yang dirender JavaScript. Selenium dapat mensimulasikan interaksi pengguna nyata, memastikan bahwa semua konten dinamis dimuat.
- Browser Tanpa Kepala : Alat seperti Puppeteer untuk Node.js atau Headless Chrome dapat merender halaman web tanpa GUI, sehingga memungkinkan pengikisan situs yang banyak menggunakan JavaScript secara efisien.
- Menangani Pengguliran Tak Terbatas dan Penomoran Halaman : Untuk halaman dengan pengguliran tak terbatas atau beberapa halaman, scraper Anda perlu menyimulasikan tindakan pengguna (seperti menggulir) atau menangani parameter URL untuk menavigasi halaman.
Teknik Penguraian dan Pembersihan Data Tingkat Lanjut
Setelah berhasil menggores data, langkah penting berikutnya adalah penguraian dan pembersihan untuk memastikan data dapat digunakan dan bermakna.
- Ekspresi Reguler (Regex) : Ekspresi reguler adalah alat yang ampuh untuk mengekstrak pola tertentu dari teks. Mereka dapat digunakan untuk mengekstrak nomor telepon, alamat email, dan format data standar lainnya.
- Transformasi Data : Mengonversi data web ke dalam format atau struktur yang diinginkan, seperti mengubah format tanggal atau menggabungkan bidang data terpisah, sangat penting untuk analisis yang konsisten.
- Menangani Masalah Unicode dan Pengkodean : Data web dapat datang dalam berbagai pengkodean. Memastikan penanganan Unicode dan pengkodean lainnya yang benar sangat penting untuk menjaga integritas data web yang tergores.
- Perpustakaan Pembersihan Data : Memanfaatkan perpustakaan seperti Pandas dengan Python untuk membersihkan dan mengubah data. Pandas menawarkan fungsi ekstensif untuk menangani nilai yang hilang, duplikat, dan konversi tipe data.
- Validasi Data : Menerapkan pemeriksaan untuk memvalidasi keakuratan dan konsistensi data web yang tergores. Langkah ini penting untuk mengidentifikasi anomali atau kesalahan apa pun dalam proses pengikisan.
- Pertimbangan Etis dan Pembatasan Tarif : Selalu mengikis web secara bertanggung jawab dengan tidak membebani server secara berlebihan dan dengan menghormati persyaratan layanan situs web. Terapkan pembatasan kecepatan dan gunakan caching untuk meminimalkan permintaan server.
Dengan menguasai teknik pengikisan web tingkat lanjut ini, Anda dapat menangani situs web dinamis secara efisien dan memastikan data yang Anda kumpulkan akurat dan bersih, siap untuk dianalisis atau diintegrasikan ke dalam aplikasi Anda.

Menggunakan Alat dan Kerangka Pengikisan Web
Ikhtisar Alat Scraping Web Populer dan Fiturnya
Alat dan kerangka kerja pengikisan web sangat menyederhanakan proses ekstraksi data dari situs web. Berikut ikhtisar beberapa yang populer:
- BeautifulSoup : Pustaka Python untuk mem-parsing dokumen HTML dan XML. Ini dikenal karena kesederhanaan dan kemudahan penggunaannya, terutama berguna untuk proyek pengikisan skala kecil. BeautifulSoup memungkinkan Anda menavigasi pohon parse dan mencari elemen berdasarkan atribut, yang berguna untuk mengekstrak data tertentu.
- Scrapy : Alat berbasis Python lainnya, Scrapy lebih merupakan kerangka kerja perayapan dan pengikisan web yang lengkap. Ini sangat efisien, terukur, dan cocok untuk proyek yang lebih besar atau proyek yang memerlukan ekstraksi data yang kompleks. Scrapy memberikan solusi lengkap untuk meminta URL, memproses halaman yang dikembalikan, dan menangani data yang tergores.
- Selenium : Awalnya alat untuk mengotomatiskan browser web untuk tujuan pengujian, Selenium juga efektif untuk menggores konten dinamis. Ini memungkinkan Anda mengontrol browser web secara terprogram, memungkinkan pengikisan konten yang dirender JavaScript.
- Octoparse : Alat pengikis visual tanpa kode, ideal untuk individu tanpa pengetahuan pemrograman yang luas. Ia menawarkan antarmuka tunjuk-dan-klik untuk memilih data yang ingin Anda hapus dari web, menjadikan prosesnya intuitif.
- Dalang dan Penulis Drama : Pustaka Node.js ini digunakan untuk otomatisasi browser, khususnya berguna untuk menyalin situs web yang banyak menggunakan JavaScript. Mereka memberikan kontrol tingkat tinggi terhadap Chrome atau Chromium dan sangat baik untuk menangani skenario pengikisan yang rumit.
Contoh Praktis: Menggunakan Alat seperti Scrapy dan BeautifulSoup
Contoh dengan BeautifulSoup :
dari bs4 impor BeautifulSoup
permintaan impor
url = “http://contoh.com”
respon = permintaan.dapatkan(url)
sup = BeautifulSoup(response.teks, 'html.parser')
# Mengekstrak semua tautan di halaman
untuk tautan di sup.find_all('a'):
mencetak(link.mendapatkan('href'))
Skrip sederhana ini menggunakan BeautifulSoup untuk mengurai halaman web dan mencetak semua hyperlink.
Contoh dengan Scrapy :
Untuk menggunakan Scrapy, Anda biasanya membuat proyek Scrapy dengan laba-laba. Berikut ini contoh dasarnya:
impor kasar
kelas ContohSpider(scrapy.Spider):
nama = 'contoh'
diperbolehkan_domain = ['example.com']
start_urls = ['http://example.com/']
def parse(diri sendiri, respons):
# Mengekstrak konten menggunakan penyeleksi css
judul = respon.css('h2::teks').extract()
hasil {'judul': judul}
Laba-laba Scrapy ini akan mengikis judul web (terlampir dalam tag h2) dari example.com.
Contoh-contoh ini menunjukkan penggunaan dasar BeautifulSoup untuk tugas-tugas sederhana dan Scrapy untuk proyek scraping yang lebih terstruktur dan terukur. Kedua alat tersebut memiliki kekuatan uniknya masing-masing, sehingga cocok untuk berbagai jenis kebutuhan web scraping.
Menangani Tantangan Pengikisan Web yang Umum
Mengatasi CAPTCHA dan Larangan IP
Salah satu tantangan utama dalam web scraping adalah menangani CAPTCHA dan larangan IP, yang merupakan mekanisme yang digunakan situs web untuk mencegah akses otomatis.
Berurusan dengan CAPTCHA :
- Layanan Penyelesaian CAPTCHA : Memanfaatkan layanan penyelesaian CAPTCHA pihak ketiga. Layanan ini menggunakan kombinasi AI dan masukan manusia untuk menyelesaikan CAPTCHA dengan biaya tertentu.
- Hindari Memicu CAPTCHA : Terapkan strategi seperti merotasi agen pengguna, menghormati robots.txt situs web, dan membuat permintaan pada interval yang mirip dengan manusia untuk menghindari CAPTCHA.
- Pengenalan Karakter Optik (OCR) : Untuk CAPTCHA yang lebih sederhana, alat OCR terkadang efektif dalam memecahkan kode teks.
Menghindari dan Menangani Larangan IP :
- Rotasi IP : Gunakan kumpulan alamat IP dan putar alamat tersebut agar tidak diblokir. Hal ini dapat dicapai melalui layanan proxy.
- Pengikisan dengan Hormat : Patuhi kebijakan pengikisan situs web, pertahankan tingkat permintaan yang lambat dan stabil, dan hindari pengikisan selama jam sibuk.
- Mekanisme Coba Ulang : Menerapkan mekanisme coba ulang dengan strategi backoff eksponensial untuk menangani larangan IP sementara atau masalah jaringan.
Strategi Penyimpanan dan Manajemen Data yang Efisien
Penyimpanan dan pengelolaan data yang tepat sangat penting untuk penanganan data yang dikumpulkan melalui web scraping secara efektif.
Memilih Solusi Penyimpanan yang Tepat :
- Basis Data : Untuk data terstruktur, basis data relasional seperti MySQL atau PostgreSQL adalah pilihan yang ideal. Untuk skema yang lebih fleksibel atau data tidak terstruktur, database NoSQL seperti MongoDB dapat digunakan.
- Penyimpanan Berbasis File : Proyek sederhana atau data dalam jumlah kecil dapat disimpan dalam format file seperti CSV, JSON, atau XML.
Normalisasi Data dan Desain Skema :
- Pastikan skema database Anda secara efektif mewakili data yang Anda ambil. Normalisasi data untuk mengurangi redundansi dan meningkatkan integritas.
Pembersihan dan Transformasi Data :
- Bersihkan dan ubah data yang tergores sebelum menyimpannya. Ini termasuk menghapus duplikat, memperbaiki kesalahan, dan mengonversi data ke format yang diinginkan.
Skalabilitas dan Kinerja :
- Pertimbangkan skalabilitas jika Anda berurusan dengan scraping skala besar. Gunakan pengindeksan database, kueri yang dioptimalkan, dan mekanisme cache untuk meningkatkan kinerja.
Cadangan dan pemulihan :
- Cadangkan data Anda secara teratur untuk mencegah kehilangan karena kegagalan perangkat keras atau masalah lainnya. Miliki rencana pemulihan.
Privasi dan Keamanan Data :
- Perhatikan undang-undang privasi data dan pertimbangan etis. Amankan penyimpanan dan transmisi data Anda untuk melindungi informasi sensitif.
Dengan mengatasi tantangan umum ini secara efektif, Anda dapat memastikan bahwa proyek web scraping Anda tidak hanya berhasil tetapi juga menghormati batasan hukum dan etika, dan bahwa data yang Anda kumpulkan disimpan dan dikelola secara efisien.
Praktik Terbaik dan Tip untuk Pengikisan Web yang Efisien

Sumber: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Pengikisan web, bila dilakukan secara efisien, dapat menghasilkan data berkualitas tinggi dengan pengeluaran sumber daya minimal. Berikut adalah beberapa praktik terbaik dan tips untuk meningkatkan efisiensi dan efektivitas upaya web scraping Anda.
Mengoptimalkan Kode Scraping Anda untuk Kecepatan dan Efisiensi
- Penggunaan Pemilih Efisien : Gunakan penyeleksi efisien yang spesifik dan langsung. Hindari pemilih XPath atau CSS yang terlalu luas atau rumit, karena dapat memperlambat proses penguraian.
- Permintaan Serentak : Menerapkan permintaan serentak tetapi dalam batas wajar untuk menghindari kelebihan beban pada server. Alat seperti Scrapy memungkinkan konfigurasi permintaan bersamaan dengan mudah.
- Caching : Menerapkan mekanisme caching untuk menyimpan dan menggunakan kembali data yang diambil sebelumnya, yang secara signifikan dapat mengurangi kebutuhan untuk membuat permintaan yang berlebihan.
- Penanganan Pemuatan Lambat : Untuk halaman yang menggunakan pemuatan lambat, pastikan scraper Anda memicu pemuatan semua elemen yang diperlukan, mungkin dengan menyimulasikan tindakan gulir.
- Efisiensi Ekstraksi Data : Ekstrak hanya data yang diperlukan. Hindari mengunduh konten yang tidak perlu seperti gambar atau gaya jika tidak diperlukan untuk tujuan pengikisan Anda.
- Manajemen Sesi : Gunakan sesi dan cookie dengan bijak untuk mempertahankan status bila diperlukan, yang dapat berguna khususnya untuk situs yang memerlukan login.
Mempertahankan Kode Scraping Anda: Pembaruan dan Skalabilitas
- Tinjauan Kode Reguler : Tinjau dan perbarui kode scraping Anda secara berkala untuk beradaptasi dengan perubahan apa pun dalam struktur atau konten situs web.
- Desain Modular : Susun kode Anda secara modular, sehingga jika satu bagian situs web berubah, Anda hanya perlu memperbarui modul spesifik dari scraper Anda.
- Penanganan Kesalahan : Menerapkan penanganan kesalahan dan pencatatan log yang kuat untuk mengidentifikasi dan memperbaiki masalah dengan cepat. Ini termasuk penanganan kesalahan HTTP, waktu tunggu koneksi habis, dan kesalahan penguraian data.
- Pertimbangan Skalabilitas : Rancang solusi scraping Anda agar dapat diskalakan. Seiring bertambahnya kebutuhan data Anda, pastikan sistem Anda dapat menangani peningkatan beban dan volume data tanpa pengerjaan ulang yang signifikan.
- Pengujian Otomatis : Terapkan pengujian otomatis untuk memeriksa fungsionalitas scraper Anda yang sedang berlangsung. Tes rutin dapat memperingatkan Anda tentang kegagalan yang disebabkan oleh perubahan pada situs web target.
- Dokumentasi : Simpan kode Anda terdokumentasi dengan baik. Dokumentasi yang jelas sangat penting untuk pemeliharaan, terutama jika basis kode dibagikan di antara tim atau diserahkan untuk pemeliharaan di masa mendatang.
- Scraping dengan Hormat : Selalu ikuti pedoman etika scraping. Pertahankan keseimbangan antara kebutuhan data Anda dan dampaknya pada server situs web target.
Dengan mengikuti praktik ini, Anda tidak hanya membuat proses pengikisan web Anda lebih efisien dan efektif, tetapi juga memastikan proses tersebut berkelanjutan dan dapat beradaptasi terhadap perubahan dari waktu ke waktu.
Kesimpulan
Dalam panduan komprehensif ini, kami telah menjelajahi berbagai aspek web scraping, menawarkan wawasan tentang teknik, alat, dan praktik terbaiknya. Dari pemahaman dasar tentang web scraping dan pentingnya web scraping di dunia berbasis data saat ini, hingga teknik lanjutan untuk menangani situs web dinamis dan banyak JavaScript, kami telah membahas aspek-aspek penting untuk membekali Anda dengan pengetahuan untuk mengumpulkan dan memanfaatkan data web secara efektif.
Apakah Anda siap memanfaatkan kekuatan web scraping untuk bisnis atau proyek Anda? PromptCloud hadir untuk memandu Anda dalam perjalanan ini. Dengan keahlian dan solusi khusus kami, kami dapat membantu Anda menavigasi lanskap web scraping yang kompleks, memastikan Anda mendapatkan nilai maksimal dari upaya ekstraksi data Anda. Hubungi PromptCloud hari ini dan buka potensi penuh data web untuk perusahaan Anda!
Manfaatkan layanan kami untuk mengubah pendekatan Anda terhadap pengumpulan dan analisis data. Mari kita mulai perjalanan berbasis data ini bersama-sama – hubungi PromptCloud sekarang!