
Web をスクレイピングするための究極のガイド: テクニック、ツール、ベスト プラクティス
公開: 2024-01-11Webスクレイピングの概要
Webスクレイピングの基本を理解する
Web スクレイピングの核心は、Web サイトからデータを抽出するプロセスです。 この技術により、さまざまな Web ページからの情報の自動収集が可能になり、データ分析、市場調査、コンテンツ集約のための強力なツールになります。

出典: https://www.upwork.com/resources/web-scraping-basics
Web スクレイピングを始めるには、Web の基本コンポーネントである HTML、CSS、JavaScript を理解する必要があります。 HTML (HyperText Markup Language) は Web ページの構造を形成し、CSS (Cascading Style Sheets) はスタイル設定に使用され、JavaScript は多くの場合対話性を追加します。 Web スクレイピングには、HTML を解析して必要なデータを抽出することが含まれます。
Web スクレイピングを実行するには、手動のコピー&ペーストから、Python などのさまざまなプログラミング言語や Scrapy や BeautifulSoup などのツールを使用した自動化手法まで、いくつかの方法があります。 どの方法を選択するかは、タスクの複雑さとユーザーの技術的専門知識によって異なります。
今日のデータ主導の世界における Web スクレイピングの重要性
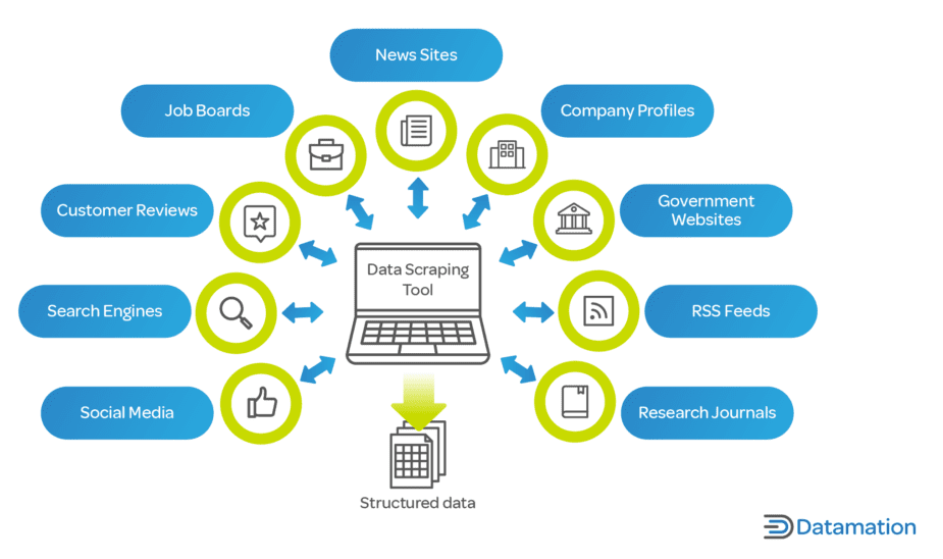
今日のデジタル時代において、データは企業や研究者にとって重要な資産です。 Web スクレイピングは、業界全体の意思決定プロセスにおける重要な推進力である、インターネットからの膨大な量のデータの迅速な収集と分析を可能にするため、非常に重要です。
企業にとって、Web スクレイピングは市場の傾向、競合他社の分析、顧客の好みなどに関する洞察を提供します。 これは、製品の価格、説明、入手可能性を追跡することが重要である電子商取引などの分野で役立ちます。
研究や学術の分野では、Web スクレイピングにより、社会科学、コンピューター サイエンス、統計などの分野の研究のための大規模なデータ収集が容易になります。 このデータは手動で収集するには数か月かかる場合がありますが、Web スクレイピングを使用するとほんの少しの時間で収集できます。
さらに、Web スクレイピングは大企業や学術機関だけに限定されません。 独立系開発者、中小企業、愛好家も、ニュース記事を集約するアプリの開発から個人的な調査プロジェクトの実施に至るまで、さまざまなプロジェクトに Web スクレイピングを利用しています。 Web スクレイピングは、現代のデータ主導の世界では非常に貴重なツールであり、膨大な Web データの海を実用的な洞察に変える力を提供します。
Webスクレイピング環境のセットアップ
Web スクレイピングに適切なツールと言語を選択する
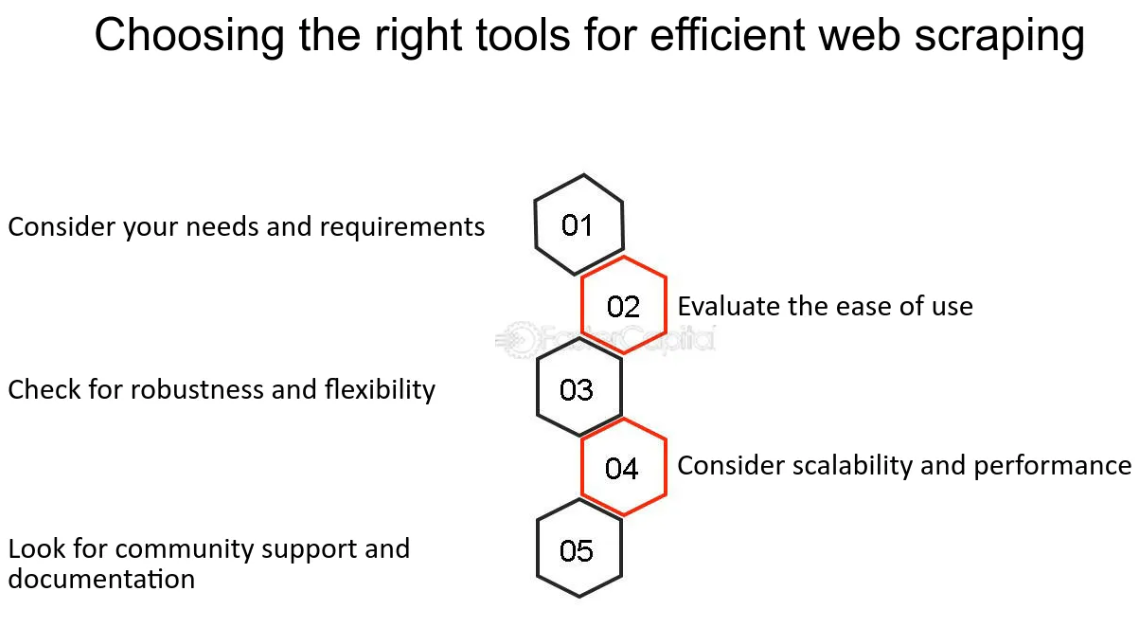
出典: https://fastercapital.com/startup-topic/web-scraping.html
Web スクレイピングに関しては、効率性と使いやすさを実現するために、適切なツールとプログラミング言語を選択することが重要です。 Python は、そのシンプルさと、BeautifulSoup や Scrapy など、Web スクレイピング用に特別に設計された膨大なライブラリのおかげで、この分野のフロントランナーとして浮上しました。
- Python : Python は読みやすさとシンプルさで知られており、初心者にも専門家にも同様に理想的です。 BeautifulSoup のようなライブラリは、HTML および XML ドキュメントの解析プロセスを簡素化し、データの抽出を容易にします。
- Scrapy : このオープンソースの共同フレームワークは、Web サイトから必要なデータを抽出するために使用されます。 これは単なるライブラリではなく、完全な Web スクレイピング ソリューションおよびフレームワークです。
- 他の言語: Python が人気ですが、Ruby、PHP、JavaScript (Node.js) などの他の言語も Web スクレイピング機能を提供します。 どちらを選択するかは、既存のプログラミング スキルや特定のプロジェクトの要件によって異なります。
特にコーディングに興味がない場合は、プログラミング言語に加えて、専用の Web スクレイピング ソフトウェアやクラウド サービスの使用を検討することもできます。 Octoparse や Dexi.io などのツールは、スクレイピングに対するより視覚的なアプローチを提供し、ユーザーが抽出したいデータをポイント アンド クリックできるようにします。
初めての Web スクレイピング プロジェクトのセットアップ: ステップバイステップ ガイド
- Python とライブラリのインストール: まず、Python と Python のパッケージ インストーラーである pip をインストールします。 次に、pip install beautifulsoup4 リクエストを実行して、BeautifulSoup などの Web スクレイピング ライブラリとリクエストをインストールします。
- ターゲット Web サイトの特定: Web データをスクレイピングする Web サイトを選択します。 サイトの robots.txt ファイルを必ず確認して、スクレイピング ルールを理解してください。
- Web ページを検査する: ブラウザの開発者ツールを使用して、ページの HTML 構造を検査します。 Web からスクレイピングするデータを含む HTML 要素を特定します。
- スクレイピング スクリプトを作成する: Web ページのコンテンツをリクエストし、HTML を解析するための Python スクリプトを作成します。 BeautifulSoup または別の解析ライブラリを使用して、必要なデータを抽出します。
- スクリプトを実行してデータを抽出: スクリプトを実行してデータを収集します。 例外とエラーを適切に処理するようにしてください。
- スクレイピングしたデータを保存する: スクレイピングした Web データを保存する方法を決定します。 一般的なオプションには、CSV ファイル、JSON、または SQLite や MongoDB などのデータベース システムが含まれます。
- 敬意を持ったスクレイピングの実践: サーバーに負荷がかかることを避けるためにスクレイピング スクリプトに遅延を実装し、Web サイトのデータ プライバシーと法的ガイドラインを尊重します。

出典: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
このガイドでは、最初の Web スクレイピング プロジェクトの基礎を確立し、基本的かつ効果的なスクレイピング環境のセットアップに必要なツールと手順の概要を説明します。
高度な Web スクレイピング技術
動的で JavaScript を多用する Web サイトの処理
動的な Web サイト、特に JavaScript に大きく依存する Web サイトのスクレイピングには、従来の HTML ベースのスクレイピングよりも高度な技術が必要です。 これらのサイトはコンテンツを非同期で読み込むことが多いため、必要なデータが最初の HTML 応答に存在しない可能性があります。
- AJAX と API について: 多くの動的 Web サイトは、AJAX (非同期 JavaScript および XML) リクエストを使用してデータを読み込みます。 ブラウザの開発者ツールを通じてネットワーク トラフィックを検査すると、JSON などの構造化形式でデータを返す API エンドポイントが明らかになります。これは、HTML を解析するよりも Web をスクレイピングする方が簡単です。
- Selenium とブラウザの自動化: Selenium のようなツールを使用すると、Web ブラウザを自動化し、JavaScript でレンダリングされたコンテンツのスクレイピングを可能にします。 Selenium は実際のユーザー インタラクションをシミュレートし、すべての動的コンテンツが確実に読み込まれるようにします。
- ヘッドレス ブラウザ: Puppeteer for Node.js や Headless Chrome などのツールは、GUI なしで Web ページをレンダリングできるため、JavaScript を多用するサイトを効率的にスクレイピングできます。
- 無限スクロールとページネーションの処理: 無限スクロールまたは複数のページがあるページの場合、スクレイパーはユーザーのアクション (スクロールなど) をシミュレートするか、ページ間を移動するための URL パラメーターを処理する必要があります。
高度なデータ解析およびクリーニング技術
データのスクレイピングに成功したら、次の重要なステップは、データが使用可能で意味のあるものであることを確認するために解析とクリーニングを行うことです。
- 正規表現 (Regex) : 正規表現は、テキストから特定のパターンを抽出するための強力なツールです。 これらは、電話番号、電子メール アドレス、その他の標準化されたデータ形式を抽出するために使用できます。
- データ変換: 日付形式の変更や個別のデータ フィールドの結合など、スクレイピングした Web データを目的の形式や構造に変換することは、一貫した分析を行うために不可欠です。
- Unicode とエンコーディングの問題の処理: Web データにはさまざまなエンコーディングが使用されます。 Web データのスクレイピングの整合性を維持するには、Unicode およびその他のエンコーディングを正しく処理することが重要です。
- データ クリーニング ライブラリ: データのクリーニングと変換に Python の Pandas などのライブラリを利用します。 Pandas は、欠損値、重複、データ型変換を処理するための広範な関数を提供します。
- データ検証: Web データのスクレイピングの正確性と一貫性を検証するためのチェックを実装します。 このステップは、スクレイピング プロセスの異常やエラーを特定するために重要です。
- 倫理的考慮事項とレート制限: サーバーに過負荷をかけず、Web サイトの利用規約を尊重し、常に責任を持って Web をスクレイピングしてください。 レート制限を実装し、キャッシュを使用してサーバーリクエストを最小限に抑えます。
これらの高度な Web スクレイピング技術を習得することで、動的な Web サイトを効率的に処理し、収集したデータが正確かつクリーンで、分析やアプリケーションへの統合の準備が整っていることを確認できます。

Webスクレイピングツールとフレームワークの使用
人気のある Web スクレイピング ツールとその機能の概要
Web スクレイピング ツールとフレームワークは、Web サイトからのデータ抽出プロセスを大幅に簡素化します。 ここでは、いくつかの人気のあるものの概要を示します。
- BeautifulSoup : HTML および XML ドキュメントを解析するための Python ライブラリ。 シンプルさと使いやすさで知られており、特に小規模なスクレイピング プロジェクトに役立ちます。 BeautifulSoup を使用すると、解析ツリーをナビゲートし、属性によって要素を検索できます。これは、特定のデータを抽出するのに便利です。
- Scrapy : もう 1 つの Python ベースのツールである Scrapy は、完全な Web クローリングおよびスクレイピング フレームワークです。 非常に効率的で拡張性があり、大規模なプロジェクトや複雑なデータ抽出が必要なプロジェクトに適しています。 Scrapy は、URL のリクエスト、返されたページの処理、スクレイピングされたデータの処理のための本格的なソリューションを提供します。
- Selenium : 元々はテスト目的で Web ブラウザを自動化するツールでしたが、Selenium は動的コンテンツのスクレイピングにも効果的です。 これにより、Web ブラウザをプログラムで制御し、JavaScript でレンダリングされたコンテンツのスクレイピングが可能になります。
- Octoparse : コード不要のビジュアル スクレイピング ツールで、プログラミングの広範な知識を持たない人に最適です。 Web からスクレイピングするデータを選択するためのポイント アンド クリック インターフェイスが提供され、プロセスが直感的になります。
- Puppeteer および Playwright : これらの Node.js ライブラリはブラウザーの自動化に使用され、特に JavaScript を多用する Web サイトのスクレイピングに役立ちます。 これらは Chrome または Chromium に対する高度な制御を提供し、複雑なスクレイピング シナリオの処理に優れています。
実践例: Scrapy や BeautifulSoup などのツールの使用
BeautifulSoup の例:
bs4 インポートから BeautifulSoup
インポートリクエスト
URL = “http://example.com”
応答 = リクエスト.get(url)
スープ = BeautifulSoup(response.text, 'html.parser')
# ページ上のすべてのリンクを抽出します
Soup.find_all('a') のリンク:
print(link.get('href'))
この単純なスクリプトは、BeautifulSoup を使用して Web ページを解析し、すべてのハイパーリンクを出力します。
Scrapy の例:
Scrapy を使用するには、通常、スパイダーを使用して Scrapy プロジェクトを作成します。 基本的な例を次に示します。
輸入スクレイピー
クラス ExampleSpider(scrapy.Spider):
名前 = '例'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(self, 応答):
# CSS セレクターを使用してコンテンツを抽出する
タイトル = 応答.css('h2::text').extract()
収量 {'タイトル': タイトル}
この Scrapy スパイダーは、example.com から Web タイトル (h2 タグで囲まれた) をスクレイピングします。
これらの例は、単純なタスク用の BeautifulSoup と、より構造化されたスケーラブルなスクレイピング プロジェクト用の Scrapy の基本的な使用法を示しています。 どちらのツールにも独自の強みがあり、さまざまな種類の Web スクレイピングのニーズに適しています。
一般的な Web スクレイピングの課題への対処
CAPTCHA と IP 禁止を克服する
Web スクレイピングにおける主な課題の 1 つは、自動アクセスを防ぐために Web サイトが使用するメカニズムである CAPTCHA と IP 禁止に対処することです。
CAPTCHA の処理:
- CAPTCHA 解決サービス: サードパーティの CAPTCHA 解決サービスを利用します。 これらのサービスは、AI と人間の入力を組み合わせて有料で CAPTCHA を解決します。
- CAPTCHA のトリガーを避ける: CAPTCHA を回避するために、ユーザー エージェントをローテーションする、Web サイトの robots.txt を尊重する、人間と同じような間隔でリクエストを行うなどの戦略を実装します。
- 光学式文字認識 (OCR) : 単純な CAPTCHA の場合、テキストのデコードに OCR ツールが効果的な場合があります。
IP 禁止の回避と処理:
- IP ローテーション: IP アドレスのプールを使用し、ブロックされないようにそれらをローテーションします。 これはプロキシ サービスを通じて実現できます。
- 敬意を持ったスクレイピング: Web サイトのスクレイピング ポリシーを遵守し、ゆっくりとした安定したリクエスト レートを維持し、ピーク時のスクレイピングを避けます。
- 再試行メカニズム: 一時的な IP 禁止やネットワークの問題を処理するために、指数関数的バックオフ戦略を備えた再試行メカニズムを実装します。
効率的なデータストレージと管理戦略
Web スクレイピングを通じて収集されたデータを効果的に処理するには、適切なデータの保存と管理が不可欠です。
適切なストレージ ソリューションの選択:
- データベース: 構造化データの場合、MySQL や PostgreSQL などのリレーショナル データベースが最適です。 より柔軟なスキーマや非構造化データの場合は、MongoDB などの NoSQL データベースを使用できます。
- ファイルベースのストレージ: 単純なプロジェクトや少量のデータは、CSV、JSON、XML などのファイル形式で保存できます。
データの正規化とスキーマ設計:
- データベース スキーマがスクレイピングしているデータを効果的に表現していることを確認してください。 データを正規化して冗長性を減らし、整合性を向上させます。
データのクリーニングと変換:
- スクレイピングしたデータを保存する前に、クリーンアップして変換します。 これには、重複の削除、エラーの修正、データの目的の形式への変換が含まれます。
スケーラビリティとパフォーマンス:
- 大規模なスクレイピングを扱う場合は、スケーラビリティを考慮してください。 データベースのインデックス作成、最適化されたクエリ、およびキャッシュ メカニズムを使用してパフォーマンスを向上させます。
バックアップとリカバリ:
- ハードウェア障害やその他の問題による損失を防ぐために、データを定期的にバックアップしてください。 回復計画を立ててください。
データのプライバシーとセキュリティ:
- データプライバシー法と倫理的考慮事項に注意してください。 データの保管と送信を保護して機密情報を保護します。
これらの一般的な課題に効果的に対処することで、Web スクレイピング プロジェクトを成功させるだけでなく、法的および倫理的な境界を尊重し、収集したデータを効率的に保存および管理することができます。
効率的な Web スクレイピングのためのベスト プラクティスとヒント

出典: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Web スクレイピングを効率的に実行すると、最小限のリソース消費で高品質のデータを生成できます。 ここでは、Web スクレイピング作業の効率と効果を高めるためのベスト プラクティスとヒントをいくつか紹介します。
速度と効率を高めるためにスクレイピング コードを最適化する
- 効率的なセレクターの使用: 具体的かつ直接的な効率的なセレクターを使用します。 過度に広範または複雑な XPath または CSS セレクターは、解析プロセスが遅くなる可能性があるため避けてください。
- 同時リクエスト: サーバーの過負荷を避けるために、合理的な制限内で同時リクエストを実装します。 Scrapy のようなツールを使用すると、同時リクエストを簡単に構成できます。
- キャッシュ: 以前に取得したデータを保存して再利用するためのキャッシュ メカニズムを実装します。これにより、冗長なリクエストを行う必要性が大幅に軽減されます。
- 遅延読み込み処理: 遅延読み込みを使用するページの場合は、スクロール アクションをシミュレートすることによって、スクレイパーが必要なすべての要素の読み込みをトリガーするようにします。
- データ抽出効率: 必要なデータのみを抽出します。 スクレイピングの目的に必要でない場合は、画像やスタイルなどの不要なコンテンツをダウンロードしないでください。
- セッション管理: セッションと Cookie を賢く使用して、必要に応じて状態を維持します。これは、ログインが必要なサイトに特に役立ちます。
スクレイピング コードのメンテナンス: 更新とスケーラビリティ
- 定期的なコードレビュー: Web サイトの構造やコンテンツの変更に適応するために、スクレイピング コードを定期的にレビューして更新します。
- モジュール設計: コードをモジュール形式で構造化することで、Web サイトの一部が変更された場合でも、スクレイパーの特定のモジュールを更新するだけで済みます。
- エラー処理: 堅牢なエラー処理とログを実装して、問題を迅速に特定して修正します。 これには、HTTP エラー、接続タイムアウト、データ解析エラーの処理が含まれます。
- スケーラビリティに関する考慮事項: スクレイピング ソリューションをスケーラブルになるように設計します。 データのニーズが増大するにつれて、システムが大幅な再作業なしで増加した負荷とデータ量を処理できることを確認してください。
- 自動テスト: 自動テストを実装して、スクレイパーの進行中の機能をチェックします。 定期的なテストにより、ターゲット Web サイトの変更によって引き起こされる障害を警告できます。
- ドキュメント: コードを十分にドキュメント化してください。 特にコードベースがチーム間で共有されたり、将来のメンテナンスのために引き渡されたりする場合、メンテナンスには明確な文書が重要です。
- 敬意を持ったスクレイピング: 常に倫理的なスクレイピング ガイドラインに従ってください。 データのニーズとターゲット Web サイトのサーバーへの影響の間のバランスを維持します。
これらの慣行に従うことで、Web スクレイピング プロセスをより効率的かつ効果的にするだけでなく、プロセスが持続可能であり、時間の経過による変化にも適応できるようになります。
要約すれば
この包括的なガイドでは、Web スクレイピングのさまざまな側面を検討し、その技術、ツール、ベスト プラクティスについての洞察を提供しています。 Web スクレイピングの基本的な理解と今日のデータ主導の世界におけるその重要性から、動的で JavaScript を多用する Web サイトを処理するための高度なテクニックまで、Web データを効果的に収集して活用するための知識を身につけるための重要な側面を取り上げました。
あなたのビジネスやプロジェクトに Web スクレイピングの力を活用する準備はできていますか? PromptCloud は、この旅をガイドするためにここにいます。 当社の専門知識とカスタマイズされたソリューションにより、Web スクレイピングの複雑な環境をナビゲートし、データ抽出の取り組みから最大の価値を確実に引き出すことができます。 今すぐ PromptCloud に連絡して、企業の Web データの可能性を最大限に引き出してください。
当社のサービスを活用して、データ収集と分析へのアプローチを変革します。 このデータ主導の旅に一緒に乗り出しましょう – 今すぐ PromptCloud に連絡してください!