
Ghidul suprem pentru a răzui pe web: tehnici, instrumente și cele mai bune practici
Publicat: 2024-01-11Introducere în Web Scraping
Înțelegerea elementelor de bază ale Web Scraping
Web scraping, în esență, este procesul de extragere a datelor de pe site-uri web. Această tehnică permite colectarea automată a informațiilor din diverse pagini web, ceea ce o face un instrument puternic pentru analiza datelor, cercetarea pieței și agregarea conținutului.

Sursa: https://www.upwork.com/resources/web-scraping-basics
Pentru a începe cu web scraping, trebuie să înțelegeți componentele de bază ale web: HTML, CSS și JavaScript. HTML (HyperText Markup Language) formează structura paginilor web, CSS (Cascading Style Sheets) este folosit pentru stil, iar JavaScript adaugă adesea interactivitate. Web scraping implică analizarea HTML-ului pentru a extrage datele de care aveți nevoie.
Există mai multe metode de a efectua scraping-ul web, de la copiere-lipire manuală la tehnici automate care utilizează diverse limbaje de programare precum Python sau instrumente precum Scrapy și BeautifulSoup. Alegerea metodei depinde de complexitatea sarcinii și de expertiza tehnică a utilizatorului.
Importanța web scraping în lumea actuală bazată pe date
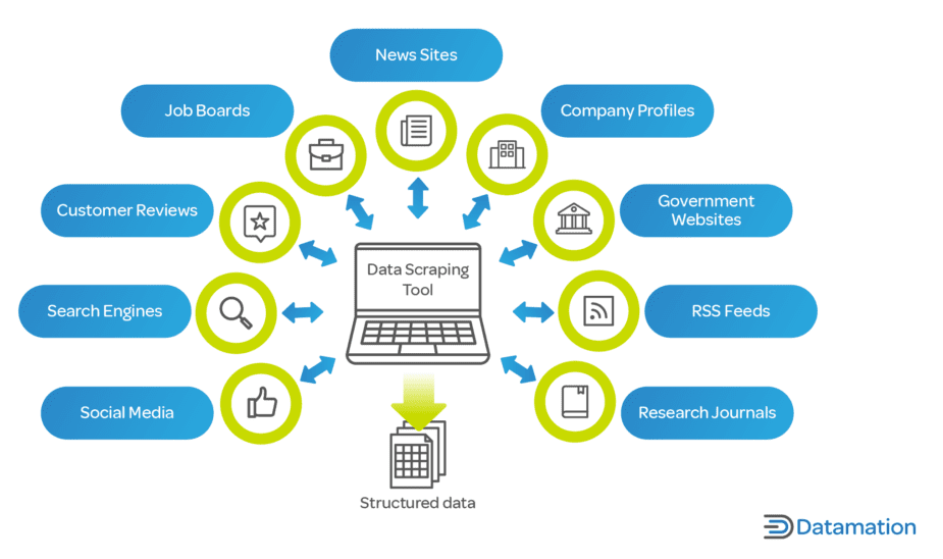
În era digitală de astăzi, datele sunt un activ esențial pentru companii și cercetători. Web scraping este vital pentru că permite colectarea și analiza rapidă a unor cantități mari de date de pe internet, un factor cheie în procesele de luare a deciziilor în toate industriile.
Pentru companii, web scraping poate oferi informații despre tendințele pieței, analiza concurenților, preferințele clienților și multe altele. Este esențial în sectoare precum comerțul electronic, unde este esențială urmărirea prețurilor, descrierilor și disponibilității produselor.
În domeniul cercetării și al mediului academic, web scraping facilitează colectarea de date pe scară largă pentru studii în domenii precum științe sociale, informatică și statistică. Aceste date, care ar putea dura luni de zile pentru a fi colectate manual, pot fi adunate într-o fracțiune de timp cu web scraping.
Mai mult, web scraping nu se limitează doar la mari corporații sau instituții academice. Dezvoltatorii independenți, întreprinderile mici și pasionații folosesc, de asemenea, web scraping pentru diverse proiecte, de la dezvoltarea de aplicații care adună articole de știri până la realizarea de proiecte personale de cercetare. Web scraping este un instrument de neprețuit în lumea contemporană bazată pe date, oferind puterea de a transforma marea mare de date web în perspective acționabile.
Configurarea mediului Web Scraping
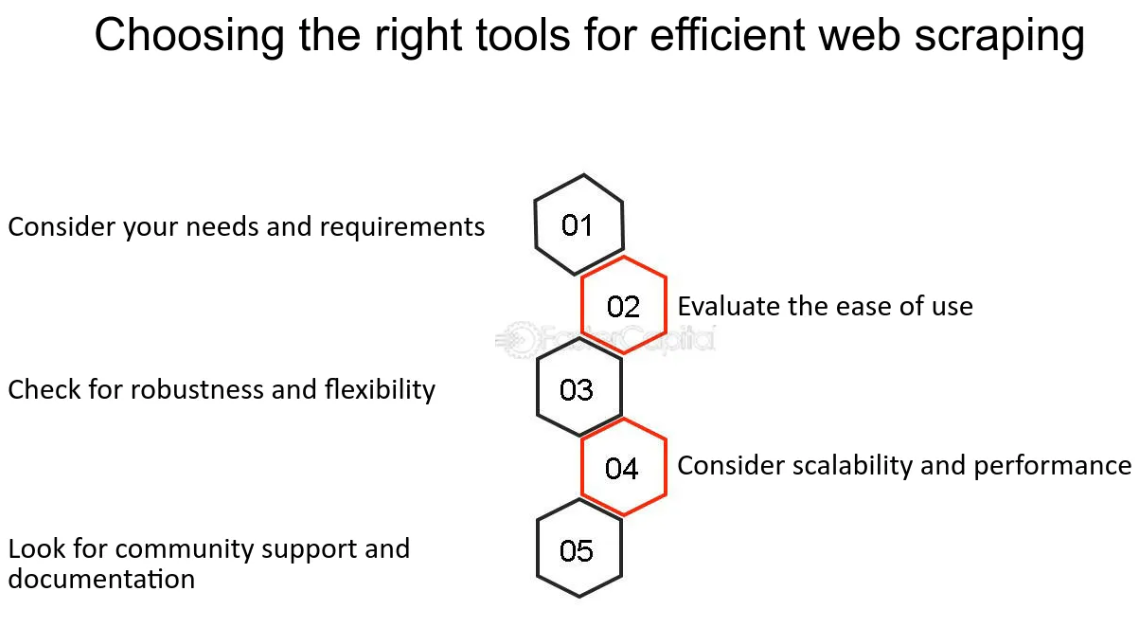
Alegerea instrumentelor și limbilor potrivite pentru Web Scraping
Sursa: https://fastercapital.com/startup-topic/web-scraping.html
Când vine vorba de web scraping, selectarea instrumentelor și limbajelor de programare potrivite este crucială pentru eficiență și ușurință în utilizare. Python a apărut ca lider în acest spațiu, datorită simplității sale și gamei vaste de biblioteci concepute special pentru web scraping, cum ar fi BeautifulSoup și Scrapy.
- Python : Cunoscut pentru lizibilitatea și simplitatea sa, Python este ideal atât pentru începători, cât și pentru experți. Bibliotecile precum BeautifulSoup simplifică procesul de analiză a documentelor HTML și XML, facilitând extragerea datelor.
- Scrapy : Acest cadru open-source și colaborativ este folosit pentru extragerea datelor de care aveți nevoie de pe site-uri web. Nu este doar o bibliotecă, ci o soluție și un cadru complet de web scraping.
- Alte limbi : În timp ce Python este popular, alte limbi precum Ruby, PHP și JavaScript (Node.js) oferă, de asemenea, capabilități de scraping web. Alegerea poate depinde de abilitățile de programare existente sau de cerințele specifice ale proiectului.
Pe lângă limbajele de programare, ați putea lua în considerare și utilizarea unui software specializat de web scraping sau a serviciilor cloud, mai ales dacă nu sunteți pasionat de codare. Instrumente precum Octoparse sau Dexi.io oferă o abordare mai vizuală a scrapingului, permițând utilizatorilor să indice și să facă clic către datele pe care doresc să le extragă.
Configurarea primului dvs. proiect Web Scraping: un ghid pas cu pas
- Instalați Python și biblioteci : Începeți prin a instala Python și pip, programul de instalare a pachetelor Python. Apoi, instalați biblioteci web scraping precum BeautifulSoup și solicitări rulând cererile pip install beautifulsoup4.
- Identificați site-ul țintă : alegeți un site web pe care doriți să răzuiți datele web. Asigurați-vă că examinați fișierul robots.txt al site-ului pentru a înțelege regulile de scraping.
- Inspectați pagina web : utilizați instrumentele de dezvoltare ale browserului pentru a inspecta structura HTML a paginii. Identificați elementele HTML care conțin datele pe care doriți să le răzuiți pe web.
- Scrieți scriptul Scraping : scrieți un script Python pentru a solicita conținutul paginii web și analiza HTML. Utilizați BeautifulSoup sau altă bibliotecă de analiză pentru a extrage datele de care aveți nevoie.
- Executați scriptul și extrageți datele : executați scriptul și colectați datele. Asigurați-vă că gestionați cu grație excepțiile și erorile.
- Stocați datele răzuite : decideți cum veți stoca datele web răzuite. Opțiunile comune includ fișiere CSV, JSON sau un sistem de baze de date precum SQLite sau MongoDB.
- Practici de scraping respectuoase : implementați întârzieri în scriptul dvs. de scraping pentru a evita copleșirea serverului și respectați confidențialitatea datelor și liniile directoare legale ale site-ului web.

Sursa: https://medium.com/prowebscraper/types-of-web-scraping-tools-940f824622fb
Acest ghid stabilește baza pentru primul tău proiect de scraping web, oferind o imagine de ansamblu asupra instrumentelor și pașilor implicați în crearea unui mediu de scraping de bază, dar eficient.
Tehnici avansate de răzuire web
Se ocupă de site-uri web dinamice și JavaScript
Scrapingul site-urilor web dinamice, în special a celor care se bazează foarte mult pe JavaScript, necesită tehnici mai avansate decât scrapingul tradițional bazat pe HTML. Aceste site-uri încarcă adesea conținut asincron, ceea ce înseamnă că este posibil ca datele de care aveți nevoie să nu fie prezente în răspunsul HTML inițial.
- Înțelegerea AJAX și a API-urilor : multe site-uri web dinamice încarcă date folosind solicitări AJAX (JavaScript asincron și XML). Inspectarea traficului de rețea prin instrumentele de dezvoltare ale browserului dvs. poate dezvălui punctele finale API care returnează date într-un format structurat, cum ar fi JSON, care poate fi mai ușor de răzuit pe web decât analiza HTML.
- Selenium și automatizarea browserului : instrumente precum Selenium vă permit să automatizați un browser web, permițând eliminarea conținutului redat prin JavaScript. Selenium poate simula interacțiunile reale ale utilizatorilor, asigurându-se că tot conținutul dinamic este încărcat.
- Browsere Headless : Instrumente precum Puppeteer pentru Node.js sau Headless Chrome pot reda o pagină web fără GUI, permițând eliminarea eficientă a site-urilor cu JavaScript.
- Gestionarea derulării infinite și a paginii : pentru paginile cu defilare infinită sau cu mai multe pagini, scraper-ul trebuie fie să simuleze acțiunile utilizatorului (cum ar fi defilarea), fie să gestioneze parametrii URL pentru a naviga prin pagini.
Tehnici avansate de analizare și curățare a datelor
După eliminarea cu succes a datelor, următorul pas crucial este analizarea și curățarea pentru a se asigura că sunt utilizabile și semnificative.
- Expresii regulate (Regex) : expresiile regulate sunt un instrument puternic pentru extragerea unor modele specifice din text. Acestea pot fi folosite pentru a extrage numere de telefon, adrese de e-mail și alte formate de date standardizate.
- Transformarea datelor : convertirea datelor web într-un format sau o structură dorită, cum ar fi schimbarea formatelor de date sau îmbinarea câmpurilor de date separate, este esențială pentru o analiză consecventă.
- Gestionarea problemelor cu Unicode și codificare : Datele web pot veni în diferite codificări. Asigurarea manipulării corecte a Unicode și a altor codificări este vitală pentru a menține integritatea datelor web.
- Biblioteci de curățare a datelor : utilizați biblioteci precum Pandas în Python pentru curățarea și transformarea datelor. Pandas oferă funcții extinse pentru gestionarea valorilor lipsă, duplicatelor și conversiilor tipurilor de date.
- Validarea datelor : implementați verificări pentru a valida acuratețea și consistența răzuirii datelor web. Acest pas este crucial pentru identificarea oricăror anomalii sau erori în procesul de răzuire.
- Considerații etice și limitarea ratei : răzuiți întotdeauna web în mod responsabil, fără a supraîncărca serverul și respectând termenii și condițiile site-ului. Implementați limitarea ratei și utilizați memorarea în cache pentru a minimiza solicitările serverului.
Prin stăpânirea acestor tehnici avansate de web scraping, puteți gestiona eficient site-urile web dinamice și vă puteți asigura că datele pe care le colectați sunt exacte și curate, gata pentru analiză sau integrare în aplicațiile dvs.

Utilizarea instrumentelor și cadrelor Web Scraping
O prezentare generală a instrumentelor populare de răzuire web și a caracteristicilor acestora
Instrumentele și cadrele de scraping web simplifică foarte mult procesul de extragere a datelor de pe site-uri web. Iată o prezentare generală a unora dintre cele populare:
- BeautifulSoup : O bibliotecă Python pentru analizarea documentelor HTML și XML. Este cunoscut pentru simplitatea și ușurința sa de utilizare, util în special pentru proiectele de răzuire la scară mică. BeautifulSoup vă permite să navigați în arborele de analiză și să căutați elemente după atribute, ceea ce este util pentru extragerea unor date specifice.
- Scrapy : Un alt instrument bazat pe Python, Scrapy este mai mult un cadru complet de crawling și scraping pe web. Este extrem de eficient, scalabil și potrivit pentru proiecte mai mari sau pentru cele care necesită extragerea de date complexe. Scrapy oferă o soluție completă pentru solicitarea adreselor URL, procesarea paginilor returnate și gestionarea datelor răzuite.
- Selenium : Inițial un instrument pentru automatizarea browserelor web în scopuri de testare, Selenium este eficient și pentru eliminarea conținutului dinamic. Vă permite să controlați programatic un browser web, permițând eliminarea conținutului redat prin JavaScript.
- Octoparse : Un instrument de răzuire vizuală fără cod, ideal pentru persoanele fără cunoștințe extinse de programare. Oferă o interfață punct-and-click pentru a selecta datele pe care doriți să le răzuiți pe web, făcând procesul intuitiv.
- Puppeteer și Dramaturg : Aceste biblioteci Node.js sunt folosite pentru automatizarea browserului, în special utile pentru scraping site-uri web cu JavaScript. Ele oferă un nivel ridicat de control asupra Chrome sau Chromium și sunt excelente pentru gestionarea scenariilor complexe de scraping.
Exemple practice: Utilizarea instrumentelor precum Scrapy și BeautifulSoup
Exemplu cu BeautifulSoup :
de la bs4 import BeautifulSoup
cereri de import
url = „http://example.com”
răspuns = requests.get(url)
supă = BeautifulSoup(response.text, 'html.parser')
# Extragerea tuturor linkurilor de pe pagină
pentru link în soup.find_all('a'):
print(link.get('href'))
Acest script simplu folosește BeautifulSoup pentru a analiza o pagină web și a tipări toate hyperlinkurile.
Exemplu cu Scrapy :
Pentru a utiliza Scrapy, de obicei creați un proiect Scrapy cu un păianjen. Iată un exemplu de bază:
import scrapy
clasa ExempluSpider(scrapy.Spider):
nume = „exemplu”
permise_domenii = ['example.com']
start_urls = ['http://example.com/']
def parse(self, response):
# Extragerea conținutului folosind selectoare CSS
titluri = răspuns.css('h2::text').extract()
randament {'titluri': titluri}
Acest păianjen Scrapy va răzui titlurile web (incluse în etichete h2) de pe example.com.
Aceste exemple demonstrează utilizarea de bază a BeautifulSoup pentru sarcini simple și Scrapy pentru proiecte de scraping mai structurate și mai scalabile. Ambele instrumente au punctele lor forte unice, făcându-le potrivite pentru diferite tipuri de nevoi de scraping web.
Gestionarea provocărilor comune de web scraping
Depășirea CAPTCHA-urilor și a interdicțiilor IP
Una dintre provocările majore în web scraping este abordarea CAPTCHA-urilor și a interdicțiilor IP, care sunt mecanisme pe care site-urile web le folosesc pentru a preveni accesul automat.
Confruntarea cu CAPTCHA-urile :
- Servicii de rezolvare CAPTCHA : Utilizați servicii de rezolvare CAPTCHA terțe. Aceste servicii folosesc o combinație de AI și input uman pentru a rezolva CAPTCHA contra cost.
- Evitați declanșarea CAPTCHA-urilor : implementați strategii precum rotația agenților utilizatori, respectarea site-ului robots.txt și efectuarea de solicitări la un interval asemănător uman pentru a evita CAPTCHA-urile.
- Recunoaștere optică a caracterelor (OCR) : pentru CAPTCHA mai simple, instrumentele OCR pot fi uneori eficiente în decodarea textului.
Evitarea și gestionarea interdicțiilor IP :
- Rotație IP : Utilizați un grup de adrese IP și rotiți-le pentru a evita blocarea. Acest lucru poate fi realizat prin servicii de proxy.
- Scraping respectuos : respectați politicile de scraping ale site-ului web, mențineți o rată de solicitare lentă și constantă și evitați scraping în timpul orelor de vârf.
- Mecanisme de reîncercare : implementați mecanisme de reîncercare cu strategii de retragere exponențială pentru a gestiona interzicerea temporară a IP-ului sau problemele de rețea.
Strategii eficiente de gestionare și stocare a datelor
Stocarea și gestionarea adecvată a datelor sunt cruciale pentru manipularea eficientă a datelor colectate prin web scraping.
Alegerea soluției potrivite de stocare :
- Baze de date : Pentru datele structurate, bazele de date relaționale precum MySQL sau PostgreSQL sunt ideale. Pentru scheme mai flexibile sau date nestructurate, pot fi folosite baze de date NoSQL precum MongoDB.
- Stocare bazată pe fișiere : proiecte simple sau cantități mici de date pot fi stocate în formate de fișiere precum CSV, JSON sau XML.
Normalizarea datelor și proiectarea schemei :
- Asigurați-vă că schema bazei de date reprezintă în mod eficient datele pe care le colectați. Normalizați datele pentru a reduce redundanța și pentru a îmbunătăți integritatea.
Curățarea și transformarea datelor :
- Curățați și transformați datele răzuite înainte de a le stoca. Aceasta include eliminarea duplicatelor, corectarea erorilor și conversia datelor în formatul dorit.
Scalabilitate și performanță :
- Luați în considerare scalabilitatea dacă aveți de-a face cu răzuire la scară largă. Utilizați indexarea bazei de date, interogări optimizate și mecanisme de stocare în cache pentru a îmbunătăți performanța.
Backup și recuperare :
- Faceți în mod regulat copii de rezervă ale datelor pentru a preveni pierderea din cauza defecțiunilor hardware sau a altor probleme. Aveți un plan de recuperare în vigoare.
Confidențialitatea și securitatea datelor :
- Fiți atenți la legile privind confidențialitatea datelor și la considerentele etice. Asigurați-vă stocarea și transmisia datelor pentru a proteja informațiile sensibile.
Prin abordarea eficientă a acestor provocări comune, vă puteți asigura că proiectele dvs. de web scraping nu sunt doar de succes, ci și respectă limitele legale și etice și că datele pe care le adunați sunt stocate și gestionate eficient.
Cele mai bune practici și sfaturi pentru un web scraping eficient

Sursa: https://scrape-it.cloud/blog/web-scraping-what-it-is-and-how-to-use-it
Web scraping, atunci când se realizează eficient, poate produce date de înaltă calitate cu cheltuieli minime de resurse. Iată câteva dintre cele mai bune practici și sfaturi pentru a îmbunătăți eficiența și eficacitatea eforturilor dvs. de web scraping.
Optimizarea codului de scraping pentru viteză și eficiență
- Utilizare eficientă a selectorului : utilizați selectoare eficiente, care sunt specifice și directe. Evitați selectoarele XPath sau CSS prea largi sau complexe, deoarece pot încetini procesul de analizare.
- Cereri concurente : implementați cereri concurente, dar în limite rezonabile pentru a evita supraîncărcarea serverului. Instrumente precum Scrapy permit configurarea ușoară a solicitărilor concurente.
- Memorarea în cache : implementați mecanisme de stocare în cache pentru a stoca și reutiliza datele preluate anterior, ceea ce poate reduce semnificativ nevoia de a face cereri redundante.
- Gestionarea încărcării leneșe : pentru paginile care utilizează încărcare leneră, asigurați-vă că scraperul declanșează încărcarea tuturor elementelor necesare, eventual prin simularea acțiunilor de defilare.
- Eficiența extracției datelor : extrageți numai datele necesare. Evitați să descărcați conținut inutil, cum ar fi imagini sau stiluri, dacă nu este necesar pentru obiectivele dvs. de scraping.
- Gestionarea sesiunilor : Folosiți sesiunile și modulele cookie cu înțelepciune pentru a menține starea acolo unde este necesar, ceea ce poate fi util în special pentru site-urile care necesită autentificare.
Menținerea codului dvs. de scraping: actualizări și scalabilitate
- Recenzii regulate ale codului : revizuiți și actualizați în mod regulat codul de scraping pentru a se adapta la orice modificări ale structurii sau conținutului site-ului web.
- Design modular : Structurați codul într-un mod modular, astfel încât, dacă o parte a site-ului web se modifică, trebuie doar să actualizați un anumit modul al scraper-ului.
- Gestionarea erorilor : implementați o gestionare robustă a erorilor și înregistrarea în jurnal pentru a identifica și remedia rapid problemele. Aceasta include gestionarea erorilor HTTP, a expirării timpului de conectare și a erorilor de analizare a datelor.
- Considerații privind scalabilitatea : Proiectați-vă soluția de scraping pentru a fi scalabilă. Pe măsură ce nevoile dvs. de date cresc, asigurați-vă că sistemul dumneavoastră poate gestiona încărcături și volume de date crescute fără reluări semnificative.
- Testare automată : implementați teste automate pentru a verifica funcționalitatea continuă a racletei dvs. Testele regulate vă pot alerta cu privire la eșecurile cauzate de modificările site-ului țintă.
- Documentație : păstrați codul bine documentat. Documentația clară este crucială pentru întreținere, mai ales dacă baza de cod este partajată între o echipă sau predată pentru întreținere ulterioară.
- Razuire respectuoasă : urmați întotdeauna liniile directoare etice de răzuire. Mențineți un echilibru între nevoile dvs. de date și impactul asupra serverelor site-ului țintă.
Prin aderarea la aceste practici, nu numai că vă faceți procesele de web scraping mai eficiente și mai eficiente, dar vă asigurați și că sunt durabile și adaptabile la schimbările în timp.
În concluzie
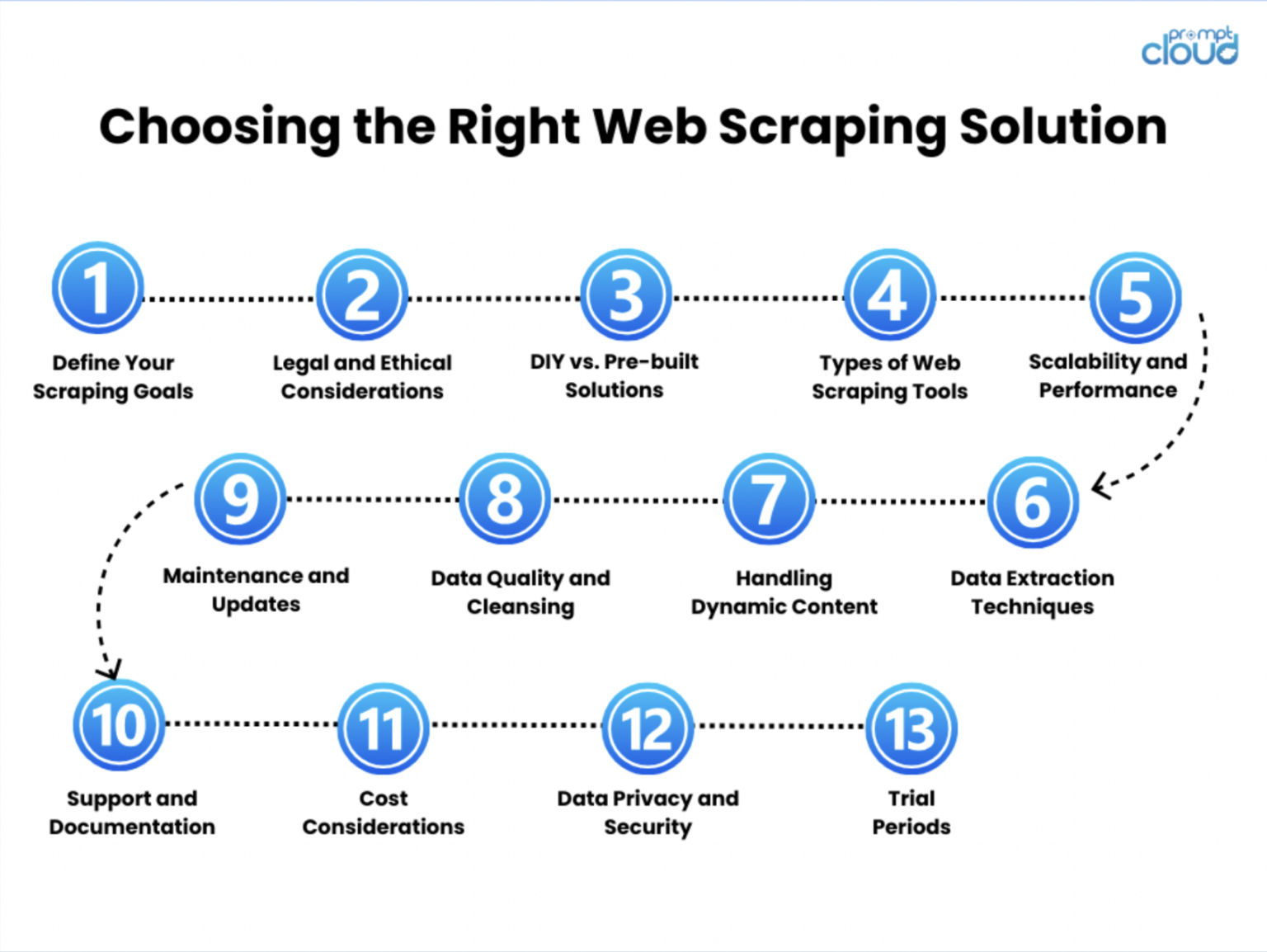
În acest ghid cuprinzător, am explorat diferitele fațete ale web scraping, oferind informații despre tehnicile, instrumentele și cele mai bune practici ale acestuia. De la înțelegerea de bază a web scraping și importanța acesteia în lumea actuală bazată pe date, până la tehnici avansate de tratare a site-urilor web dinamice și grele de JavaScript, am acoperit aspecte esențiale pentru a vă dota cu cunoștințele necesare pentru a colecta și utiliza în mod eficient datele web.
Sunteți gata să valorificați puterea web scraping pentru afacerea sau proiectul dvs.? PromptCloud este aici pentru a vă ghida în această călătorie. Cu expertiza noastră și soluțiile personalizate, vă putem ajuta să navigați în peisajul complex al web scraping, asigurându-vă că obțineți valoare maximă din eforturile dvs. de extragere a datelor. Contactați PromptCloud astăzi și deblocați întregul potențial al datelor web pentru întreprinderea dvs.!
Profitați de serviciile noastre pentru a vă transforma abordarea cu privire la colectarea și analiza datelor. Să pornim împreună în această călătorie bazată pe date – contactați PromptCloud acum!