
Web Scraping - Une partie intégrante de la science des données
Publié: 2020-02-21Le Web Scraping est devenu une partie intégrante de la science des données est un écosystème en soi et le terme finit souvent par être utilisé comme substitut à l'apprentissage automatique, à l'intelligence artificielle et autres. L'écosystème de la science des données se compose de cinq étapes différentes qui, ensemble, constituent l'ensemble du cycle de vie. Chaque étape se compose de plusieurs options qui permettaient de compléter cette étape-
Méthodes de grattage Web :
Capture de données
- Extraction de données à l'aide de processus tels que le grattage Web.
- Saisie manuelle des données.
- Acquisition de données - en achetant des ensembles de données.
- Capturer les signaux des appareils IoT.

Traitement de l'information
- Exploration de données.
- Classification ou regroupement de données brutes.
- Nettoyage et normalisation des données.
- Modélisation des données.
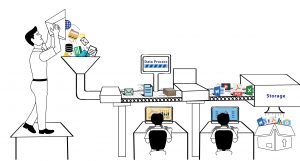
Entretien
- Entreposage de données et lac de données.
- Construire une infrastructure pour gérer et stocker les données et fournir une disponibilité maximale.
Communiquer les résultats
- Visualisation des résultats à l'aide de graphiques.
- Résumer les résultats dans un rapport textuel.
- Intelligence économique et prise de décision.
Analytique
- Analyse exploratoire et confirmatoire.
- Analyse prédictive.
- Régression.
- Exploration de texte.
- Sentiment et analyse qualitative.

Comme nous pouvons le voir dans la liste ci-dessus, rien ne se passerait dans le domaine de la science des données sans la capture de données, c'est-à-dire les données sur lesquelles vous souhaitez exécuter vos algorithmes. Cette première étape est cruciale et constitue la pierre angulaire. À moins que vos systèmes ne génèrent chaque jour des téraoctets de données utilisables, l'option probable pour vous ici est d'explorer les données du Web et de les stocker dans des bases de données, sur lesquelles vous pouvez exécuter vos algorithmes et créer votre moteur de prédiction.
Quels sont les outils qu'un Data Scientist peut utiliser pour le Web-Scraping ?
Si vous êtes un spécialiste des données et que vous avez besoin d'explorer des données sur Internet en écrivant votre code, vous pouvez utiliser Python pour écrire votre code. Non seulement il a une courbe d'apprentissage plus facile, mais il vous permet également d'interagir avec les sites Web de manière automatisée via votre code. Grâce à votre code, vous pouvez interagir avec les sites Web de manière à ce que le site Web reçoive vos demandes comme il le ferait lorsque l'on utilise un navigateur Web. Vous pouvez automatiser vos exigences de scraping, exécuter des scripts en temps opportun ou même maintenir un flux constant de données (à partir de sites Web de médias sociaux tels que Twitter) pour créer votre ensemble de données pour votre projet de science des données. Voici quelques-unes des bibliothèques disponibles en Python qui vous aideraient à relever les différents défis auxquels sont confrontés les utilisateurs lors de la récupération de données pour leurs projets.
Demandes
Lorsque vous souhaitez explorer des données du Web via du code, le premier objectif serait d'accéder à des sites Web à l'aide de code. C'est là qu'intervient la bibliothèque de requêtes . C'est l'une des préférées de la communauté Python en raison de la facilité avec laquelle vous pouvez effectuer des appels vers des pages Web et des API. Cela fait abstraction d'une grande partie du code passe-partout et simplifie les requêtes HTTP par rapport à l'utilisation de la bibliothèque URLLib intégrée. Il comprend plusieurs fonctionnalités telles que la vérification SSL de style navigateur, les requêtes sans tête, le décodage automatique du contenu, la prise en charge du proxy, etc.

Belle soupe
Une fois que vous avez une page Web, que vous avez extraite du Web, vous devez extraire les données des balises et des attributs de la page HTML. Pour cela, vous devez analyser le contenu HTML de sorte que toutes les données deviennent facilement accessibles. BeautifulSoup permet une analyse facile des documents HTML et XML d'une manière qui simplifie la navigation, la recherche et la modification. Il traite le document comme un arbre et vous pouvez naviguer de la même manière que vous naviguez dans une structure de données arborescente.


Soupe Mécanique
Lors de l'interaction avec des sites Web plus complexes. Il pourrait y avoir un besoin de fonctionnalités étendues qui aideraient à explorer de nombreuses pages Web. Mechanical Soup aide à l'automatisation du stockage et de l'envoi de cookies, permet des redirections et peut suivre des liens et même soumettre des formulaires.

Scrapy
L'une des bibliothèques de grattage Web basées sur Python les plus puissantes, Scrapy fournit un cadre open source et collaboratif. Il s'agit d'une bibliothèque de grattage de haut niveau utilisée pour mettre en place des opérations d'exploration de données, des araignées automatisées, une exploration périodique du Web. Scrapy utilise quelque chose appelé Spiders. Ce sont des classes définies par l'utilisateur utilisées pour extraire des informations de pages Web.

Sélénium
Habituellement utilisé pour tester les pages Web et leurs fonctionnalités, Selenium peut également être utilisé pour des tâches manuelles automatiques telles que la récupération de données sur le Web à l'aide de captures d'écran, l'automatisation des clics et la récupération des données exposées, etc.

Web Scraping vs autres sources de données :
Bien qu'il existe de nombreuses sources de données disponibles aujourd'hui, le web scraping est devenu l'un des processus les plus populaires par lesquels les entreprises se procurent des données (qui finissent par être traitées et converties en informations utilisables). L'une des principales raisons derrière cela est que lorsque vous travaillez sur un projet de science des données, vous préféreriez disposer de données fraîches inutilisées, à l'aide desquelles vous pouvez construire une thèse ou prédire un résultat, qui n'a pas été dérivé auparavant. Bien que les données soient le nouveau pétrole, la valeur des données diminue avec le temps. De cette façon, le web-scraping est une aubaine, puisque les données sur le web sont mises à jour chaque seconde. Il n'est valide que tant qu'il n'est pas remplacé par de nouvelles données. Par exemple, le prix d'un article sur un site Web peut être de 1 000 $.
Vous pouvez demander un rapport pour obtenir la liste de prix d'une source. Au moment où la liste de prix vous parvient avec la barre des 1 000 $, le prix de l'article peut avoir baissé à 900 $. Par conséquent, votre décision basée sur le prix que vous avez sous la main se révélerait erronée. Au lieu de cela, si vous explorez le prix d'un article en ce moment, vous obtiendrez son prix en ce moment. Ensuite, vous pouvez faire fonctionner un grattoir à une fréquence régulière pour capturer le changement de prix toutes les 10 secondes. Par conséquent, lorsque vous vous asseyez avec les données, pour prendre une décision, vous disposez à la fois de données mises à jour et historiques, ce qui peut améliorer les résultats. Un flux constant de données sans fin est ce que le web-scraping offre. C'est la principale raison d'être des sciences des données, que ce soit par un responsable marketing ou un chercheur.
Les enjeux de l'utilisation des données scrapées en Data Science :
Alors que les données que vous obtenez par le web-scraping sont massives et régulières. Un fait important est que les données extraites du Web contiennent généralement une grande quantité de données impures et non structurées . Ce que l'on voit également, c'est la présence de doublons ainsi que de points de données non vérifiés. Obtenir vos sources de données correctes est important et, par conséquent, les données doivent toujours être analysées à partir de sites Web vérifiés et connus. Dans le même temps, de nombreuses sources de données utilisées pour confirmer les données. Nettoyer les données et s'assurer que les doublons sont absents à l'aide d'un codage intelligent. Mais la conversion de données non structurées en données structurées reste l'un des problèmes les plus difficiles de web-scraping et les solutions varient d'un cas à l'autre.
L'autre problème majeur découle de la sécurité, de la légalité et de la confidentialité. Avec de plus en plus de pays autorisant la confidentialité des données et des limites plus élevées d'accès aux données, de plus en plus de sites Web ne sont aujourd'hui accessibles que via une page de connexion. À moins que vous n'exploriez des données, il existe une possibilité de pénalité pour la même chose. Cela peut aller du blocage de votre adresse IP à un procès contre vous.
Conclusion:
Chaque opportunité vient avec ses défis. Plus le défi est grand, plus la récompense est élevée. Par conséquent, le web scraping doit s'intégrer dans le flux de travail de votre entreprise, et les projets de science des données doivent générer des informations utilisables à partir de ces données. Mais si vous avez besoin d'aide pour récupérer les données des sites Web de votre entreprise ou de votre startup, notre équipe de PromptCloud fournit une solution DaaS entièrement gérée dans laquelle vous nous indiquez les exigences et nous configurons votre moteur de récupération.