
Comment créer une pile de données moderne
Publié: 2022-05-06Dans l'économie actuelle axée sur la technologie, le stockage des données est devenu plus complexe que jamais. Selon l'IDC (International Data Corporation), 175 Zettaoctets de données seront générés en 2025, soit près de trois fois la quantité générée en 2021 (61 Zettaoctets).
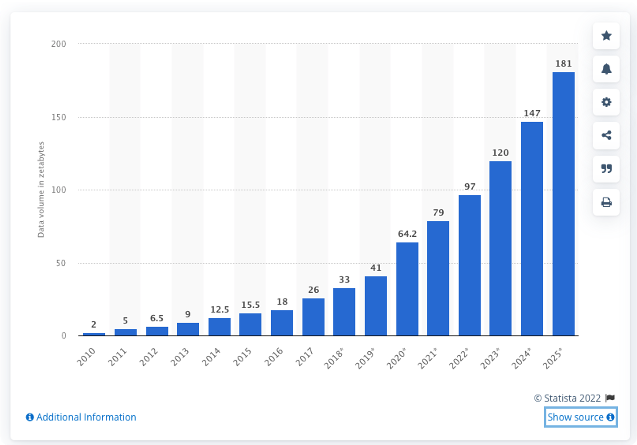
Le volume de données créées, capturées, copiées et consommées dans le monde de 2010 à 2025 par Statista
Si vous souhaitez stocker et gérer correctement les informations de votre entreprise, vous devez comprendre les nombreuses options disponibles et comment elles peuvent être intégrées ensemble.
Heureusement, ce guide vous aidera à créer une pile de données moderne qui vous permettra de collecter, stocker, analyser et finalement utiliser vos données de la manière la plus efficace possible. Ce modèle est suffisamment flexible pour être utilisé par les entreprises à n'importe quel stade de développement, peu importe leur taille ou leur type d'industrie.
Pourquoi avez-vous besoin d'une pile de données moderne ?
Une pile de données moderne est un ensemble intégré d'outils permettant de gérer le cycle de vie des données de bout en bout. Il est conçu pour collecter, traiter et activer des informations en temps réel. Il est essentiel pour toute organisation qui souhaite comprendre les tendances au niveau granulaire (par exemple, au sein de l'organisation d'un client) et agir en conséquence avant qu'elles ne soient définitivement gravées dans le marbre.
Créer une pile de données moderne n'est pas difficile, mais cela nécessite du temps et de l'engagement, ainsi qu'une compréhension exacte de ce dont vous avez besoin à partir de vos données. Si vous êtes sérieux au sujet de l'amélioration des opérations et de l'obtention d'informations sur vos clients, chaque minute d'effort en vaudra la peine. L'astuce est de savoir par où commencer et comment aller de l'avant.
Le reste de ce guide vous donnera toutes les informations dont vous avez besoin pour créer une pile de données moderne. Vous apprendrez comment différents composants fonctionnent ensemble et comment choisir un logiciel pour chaque partie de votre pile de données moderne. Une fois que vous aurez fini de lire, vous aurez tout ce dont vous avez besoin pour commencer à créer une pile de données moderne dans votre organisation dès aujourd'hui !
« Du point de vue des données, les appliances d'entrepôt de données sont une véritable mine d'or. Le rendre accessible aux solutions intégrées verticalement est au cœur de l'idée du cloud industriel. »
Ashish Thusoo
Lacs de données et entrepôts de données : les deux facettes d'une plate-forme de données cloud moderne
Avantages d'une pile de données moderne
Pourquoi investir dans une pile de données moderne ? Voici quelques avantages :
- Extrayez et chargez facilement vos données en quelques minutes vers n'importe quelle destination.
- Analysez de grandes quantités de données non structurées (documents, résultats de recherche, mesures diverses, etc.) sans avoir recours à l'écriture de scripts personnalisés ou à la création de requêtes ad hoc.
- Laissez n'importe quelle équipe commerciale se servir en libre-service avec des données opérationnelles, fiables et à jour dans ses propres outils.
- Déployez plus rapidement les innovations dans votre organisation en intégrant des outils sans code pour les équipes métier
- Les piles de données modernes réduisent les frais généraux d'ingénierie des données en éliminant le besoin de créer et de maintenir un pipeline de données.
Comprendre l'environnement actuel
La première étape pour concevoir une solution consiste à comprendre ce que vous essayez de corriger. Prenez du recul et examinez les outils, processus et procédures actuels que votre organisation utilise actuellement. Alors demandez-vous : Sont-ils efficaces ? Y a-t-il place à amélioration?
La pile de données moderne est une question d'efficacité, donc s'il y a des inefficacités dans votre processus actuel (et croyez-moi, il y en a), c'est un domaine où vous pouvez rationaliser.
Dans certains cas, cela peut être aussi simple que d'augmenter la collaboration entre les équipes ou de mettre à jour vos processus, mais parfois cela peut signifier remplacer des logiciels obsolètes ou même introduire de nouvelles technologies dans votre environnement.
Quoi qu'il en soit, commencez par définir les problèmes exacts que vous résolvez avant de poursuivre tout travail de conception. Cela rendra la mise en œuvre beaucoup plus facile sur la route.
Identifier les besoins et les objectifs de l'entreprise
Avant de choisir une base de données pour votre entreprise, vous devez comprendre son modèle de données, le type de requêtes et de rapports dont elle aura besoin et qui l'utilisera. Obtenir des réponses à ces questions aidera également votre entreprise à démarrer une planification initiale (au lieu d'apporter des modifications plus tard).
Une question clé ici est de savoir quelle taille votre magasin de données doit avoir. Par exemple, dans un scénario OLAP (traitement analytique en ligne), vous aurez beaucoup de lignes mais peu de données dans chacune - mais dans un scénario de traitement des transactions en ligne (OLTP), vous aurez beaucoup de lignes avec d'énormes quantités de données dans chaque rangée nécessitant beaucoup plus d'espace de stockage. Et puis, il y a les besoins de reporting de Business Intelligence (BI) qui nécessitent encore plus d'espace. Dans de tels cas, BigQuery est le stockage parfait qui peut très bien gérer les trois scénarios.
Une autre chose à laquelle vous devez réfléchir est de savoir si vous souhaitez utiliser le stockage dans le cloud ou sur site. Par conséquent, si vous avez déjà investi dans une infrastructure sur site, Google Cloud Platform peut ne pas vous convenir.
Calculer l'évolutivité et les performances
Lors du choix d'un fournisseur de cloud, il est important de déterminer si votre application évoluera et fonctionnera comme prévu au fil du temps.
Une autre chose cruciale est de comprendre comment vos données seront protégées dans chaque environnement (par exemple, les centres de données peuvent subir des catastrophes naturelles, des pannes de courant ou des pannes d'équipement).
Comme pour toutes ces étapes, il est essentiel de faire des recherches et de poser des questions. Des entreprises telles que New Relic proposent des outils qui peuvent vous aider à surveiller les performances et le trafic de vos applications.
De plus, des organisations comme Netflix ont créé des technologies open source conçues spécifiquement pour les applications modernes fonctionnant sur des clouds publics. Par exemple, Netflix a développé Security Monkey, un logiciel qui permet de surveiller et de sécuriser de grands environnements basés sur AWS.
Il vaut la peine d'approfondir ces technologies lors de l'évaluation des fournisseurs de cloud. Ce type de connaissances provient de discussions avec des ingénieurs de différentes entreprises et de la compréhension de leurs expériences.
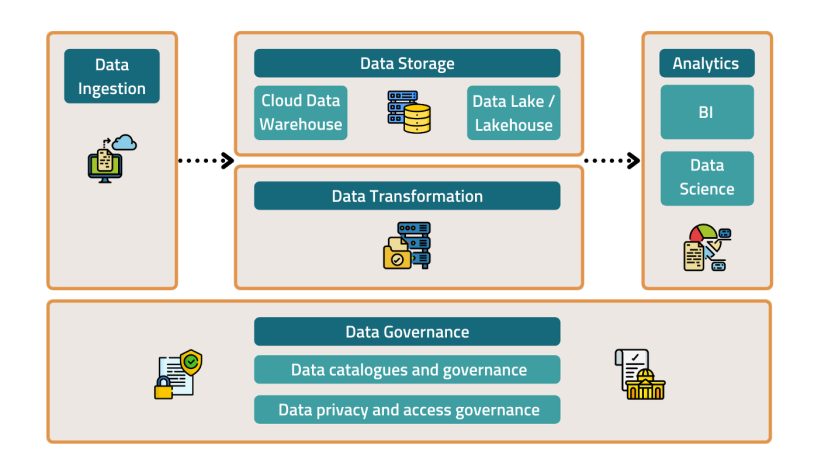
Les composants d'une pile de données moderne
Les données sont un atout stratégique. Afin d'en tirer le meilleur parti, vous devez comprendre les différents composants qui composent une pile de données et comment ils fonctionnent ensemble.
Voici les composants clés d'une pile de données à inclure lors de la conception de votre propre infrastructure de données pour votre produit :
- Ingestion de données
- Stockage de données
- Transformation des données
- Analyse des données
- Gouvernance des données
1. Ingestion de données
L'ingestion de données est l'importation de données d'un emplacement vers une nouvelle destination, telle qu'un entrepôt de données ou un lac de données, pour un stockage et une analyse supplémentaires.
La première étape de la création d'une pile de données moderne consiste à identifier vos sources de données. Grâce aux outils d'ingestion de données, vous pourrez importer toutes vos données en quelques minutes.
Disons que vous dirigez une entreprise de commerce électronique, les demandes de renseignements doivent être limitées aux produits que vous vendez et à leurs variations. Vous ne voulez pas que des centaines de requêtes par jour arrivent dans votre base de données parce que quelqu'un a interrogé un article qu'il n'achète même pas. Classez et filtrez vos produits par groupe de clients, SKU ou autres filtres et offrez un accès convivial via un bouton "Visiter ma boutique" afin que les clients puissent facilement récupérer l'historique de leurs commandes pour les ventes effectuées via votre site.
Exemples d'outils : Improvado, Fivetran, Stitch, Airflow
️Notre liste des 16 meilleurs outils d'ingestion de données vous aidera à choisir le meilleur pour votre pile de données️
2. Stockage des données
Avec l'essor des applications et des microservices natifs du cloud, la plupart des entreprises génèrent d'énormes quantités de données qui doivent être stockées et gérées. C'est une tâche difficile pour les bases de données relationnelles traditionnelles, qui ont été conçues pour des données structurées.
Les bases de données NoSQL sont idéales pour les données non structurées, mais elles peuvent être difficiles à déployer à grande échelle, en particulier dans les environnements hybrides.
Les fournisseurs de cloud proposent leurs propres solutions gérées pour vous aider dans cette étape. Par exemple, AWS propose une solution appelée Amazon Simple Storage Service (S3) pour le stockage d'objets. Google propose BigQuery dans le cadre de Cloud Platform. Les deux services fournissent une plate-forme à faible latence pour stocker de gros volumes de données à grande échelle.
Exemples d'outils : Snowflake, Databricks, AWS, GCP
Lisez notre liste des 15 meilleurs outils d'entreposage de données pour trouver celui qui répond aux besoins de votre entreprise
3. Transformation des données
La transformation des données est le processus de conversion des données d'un format ou d'une structure vers un autre format ou une autre structure. Habituellement, la transformation des données est effectuée à l'aide de techniques d'extraction, de transformation et de chargement (ETL).
Découvrez comment le processus ETL accélère les opérations manuelles sur les données
La transformation des données est cruciale dans le processus d'intégration des données, car elle prépare et normalise les données pour une analyse, un rapport et une visualisation plus poussés. La transformation des données peut être effectuée sur n'importe quel type d'ensemble de données, quel que soit son format ou sa désignation d'origine.
Exemples d'outils : Improvado DataPrep, Dbt,MCDM, Matillon, Alteryx, RestApp
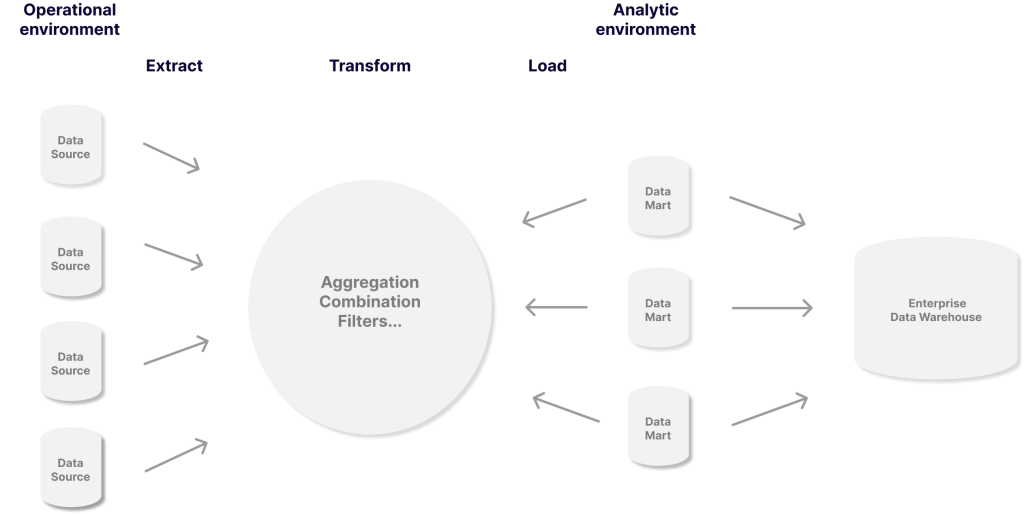
4. Analyse des données
La couche d'analyse est responsable de l'agrégation, de l'analyse et de la présentation des données aux utilisateurs. Votre couche d'analyse doit répondre à des questions telles que :

- Quels sont les indicateurs clés pour mon entreprise ?
- Comment ces mesures évoluent-elles au fil du temps ?
- Comment une métrique impacte-t-elle une autre ?
La plupart du temps, cela signifie que vos données seront transformées en graphiques, tableaux, tableaux et autres représentations visuelles que vous pourrez comprendre immédiatement.
Certaines plates-formes récentes d'analyse de données ont des capacités qui permettent à des personnes non techniques d'étudier des données sans connaître SQL.
Exemples d'outils : Looker, Tableau, Power BI
"Sans analyses de données volumineuses, les entreprises sont aveugles et sourdes, errant sur le Web comme des cerfs sur une autoroute."
Geoffrey Moore, auteur et consultant.
5. Gouvernance des données
Il est essentiel d'assurer une propriété et un processus clairs pour chaque étape du pipeline de données. Cela inclut l'établissement de normes pour les types de données qui sont collectées et la manière dont elles sont stockées et accessibles, ainsi que des processus pour garantir que ces normes sont suivies et appliquées.
Supposons que votre objectif soit d'utiliser les données pour améliorer l'efficacité opérationnelle. Vous pouvez décider que tous vos systèmes d'inventaire doivent utiliser le même système de codes-barres afin d'obtenir une image complète de votre chaîne d'approvisionnement sans avoir à rapprocher manuellement différents codes ou systèmes.
Exemples d'outils : Atlan, Microsoft Azure Data Catalog, Informatica
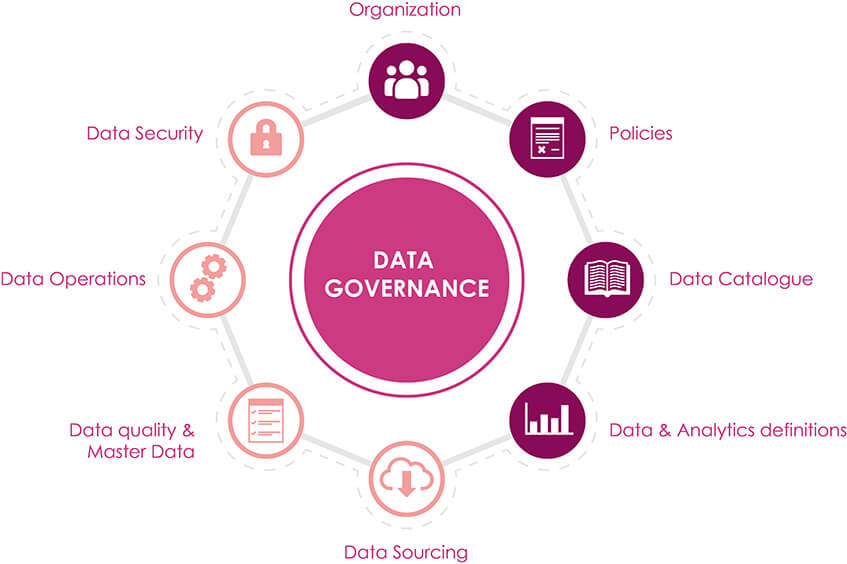
Alternative ETL inversée
De nombreuses entreprises ont construit leurs piles de données à l'aide des technologies ETL. Ces technologies sont utiles pour traiter de grandes quantités de données provenant de plusieurs sources et les transférer dans un entrepôt de données centralisé. Cependant, cette approche augmente la complexité de votre infrastructure et ralentit le délai de livraison.
Dans le monde d'aujourd'hui, les décisions commerciales sont de plus en plus prises sur la base de données en temps réel, qu'il s'agisse de la finance, de la gestion de la chaîne d'approvisionnement ou des relations clients. Une pile de données moderne vous permet de fournir des informations en temps réel à l'ensemble de l'organisation en gardant vos données à jour, accessibles et sécurisées.
C'est là que Reverse ETL peut vous aider à créer une pile de données moderne qui offre une valeur en temps réel à l'entreprise et élimine le risque d'échec dû à des informations obsolètes.
L'ETL inversé est un ensemble de méthodes ou de processus qui synchronisent les données d'un entrepôt de données vers des outils opérationnels tels que CRM, CMS, produit ou tout outil métier (Slack, Google Sheet, etc.).
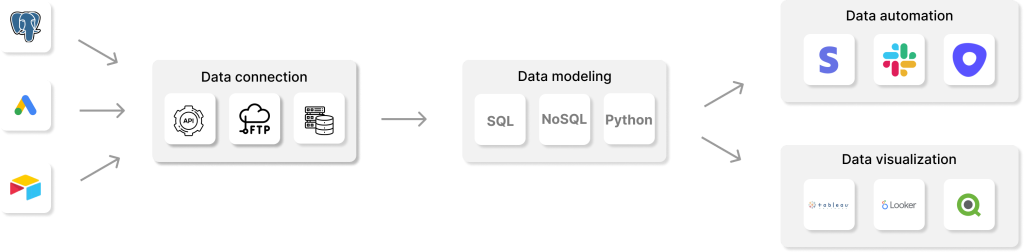
L'idée derrière ce processus est de créer une source de données unique et complète qui fournit une vue cohérente et fiable des données d'entreprise. Les processus ETL inversés sont généralement utilisés pour augmenter les processus ETL existants et s'exécutent à des intervalles de temps définis. De plus, Reverse ETL permet l'analyse opérationnelle.
Analytique opérationnelle vs Business Intelligence
L'analyse opérationnelle est l'utilisation de données, d'analyses prédictives et d'outils d'intelligence d'affaires pour mieux comprendre les opérations commerciales et générer des actions en temps réel grâce à des données activées.
L'intelligence économique (BI) est définie par Investopedia comme l'infrastructure procédurale et technique qui collecte, stocke et analyse les données produites par les activités d'une entreprise.
La Business Intelligence se concentre sur l'analyse des données historiques.
Cela vous aide à comprendre ce qui s'est passé et pourquoi. Il est utilisé pour soutenir la prise de décision des entreprises en identifiant des modèles et des tendances grâce à des comparaisons de données, des points de repère et d'autres techniques statistiques.
Par exemple, il est logique de créer un rapport indiquant le nombre de commandes passées au cours d'une période donnée, la valeur moyenne des commandes et le nombre total de commandes.
L'analytique opérationnelle est une notion centrée sur le temps réel et l'avenir. Il se concentre sur ce qui se passe maintenant et prévoit ce qui se passera ensuite afin de pouvoir tirer le meilleur parti des opportunités futures.
En résumé, l'Analyse Opérationnelle montre où nous devons agir maintenant, tandis que la Business Intelligence révèle ce qui a été mal fait et quels sont les points à améliorer.
L'analyse opérationnelle ne se limite plus aux géants du numérique comme Google, Facebook et Netflix. Grâce aux données en temps réel, toute entreprise qui utilise une pile de données moderne prend davantage de décisions basées sur les données.
Une évolution organisationnelle est nécessaire
Lorsqu'une entreprise met en œuvre une pile de données moderne, il y a trois changements majeurs dans la façon dont les données sont gérées :
Un passage de l'informatique aux utilisateurs professionnels
Auparavant, le service informatique répondait aux demandes de données des services et des analystes. Le développement d'outils d'analyse en libre-service tels que Tableau et Looker a permis aux utilisateurs professionnels d'accéder et d'analyser directement les données.
Ce changement a d'énormes implications sur la façon dont les entreprises organisent leurs ressources autour des données.
Du traitement de données par lots au traitement de données en temps réel
. À mesure que les pipelines de données deviennent plus rationalisés et que les données deviennent plus accessibles dans toute l'organisation, le décalage entre le moment où un événement se produit et le moment où il est analysé doit se réduire.
Cela signifie que de plus en plus d'entreprises envisagent le traitement en temps réel de leurs données plutôt que de les agréger sur de plus longues périodes.
Des bases de données cloisonnées à la propriété fédérée (Domaines)
Les architectures de données traditionnelles sont construites autour de bases de données cloisonnées et d'une propriété fédérée, ce qui a conduit à la prolifération de lacs de données, de datamarts et d'entrepôts de données.
Ces architectures se concentraient sur les calculs centralisés et l'infrastructure de stockage. À mesure que les services cloud ont mûri et se sont modernisés, l'approche de l'architecture des piles de données devrait également évoluer.
Les architectures de données d'aujourd'hui doivent être capables de gérer l'échelle et la complexité des applications modernes qui sont réparties sur une gamme de technologies. C'est là qu'intervient le concept de maillage de données - une nouvelle architecture qui permet à tous les types de données d'être accessibles en toute sécurité, gouvernées facilement et consommées par n'importe quelle application n'importe où.
Appuyez-vous sur vos parties prenantes
Il existe trois principaux types de parties prenantes en ce qui concerne la pile de données moderne.
Intervenants internes
Ce sont les personnes au sein de votre organisation qui utiliseront les données dans leur travail quotidien.
Par exemple, l'équipe de vente peut être intéressée par le montant des revenus générés par chaque client et par la manière d'augmenter ces revenus. Ou peut-être que l'équipe marketing s'intéresse aux types de contenu qui génèrent le plus de trafic sur le site Web.
Les parties prenantes internes doivent avoir leur mot à dire sur les données que vous collectez, la manière dont vous structurez ces données et les outils que vous utilisez pour les analyser.
Parties prenantes externes
Ce sont des personnes extérieures à votre entreprise, mais elles ont toujours un intérêt dans votre réussite.
Par exemple, si votre entreprise est une entreprise de logiciels en tant que service (SaaS), les utilisateurs de votre produit sont des parties prenantes externes. Si votre entreprise vend des produits en ligne et les expédie dans tout le pays ou dans le monde, les clients et les fournisseurs sont des parties prenantes externes.
Il est important de comprendre ce qu'ils attendent de vous afin que vous puissiez fournir ces données correctement et efficacement.
Intervenants tiers
Ce sont des personnes extérieures à votre organisation qui fournissent également des services à votre entreprise. Par exemple, les fournisseurs qui fournissent les matières premières ou les consultants informatiques qui vous aident à configurer votre infrastructure technologique. Si vous voulez éviter les mouches aveugles en termes de données, vous devez maîtriser l'analyse des données. Cela nécessitera de plus en plus le développement de données en dehors de vos quatre murs.
La pile de données moderne renforce la relation entre l'entreprise et ses parties prenantes avec un partage plus efficace des données grâce à des domaines définis pour chaque équipe et la possibilité de l'utiliser dans un environnement sans code.
Les domaines de données renforcent la relation entre les équipes puisqu'elles opèrent toutes dans ce même domaine.
Par exemple, une équipe marketing souhaite savoir combien de personnes s'inscrivent à leur nouveau produit ou service et combien de revenus il génère après l'inscription. Les données générées par l'équipe produit sont pertinentes pour l'équipe marketing car elles travaillent toutes les deux dans un espace similaire.
Conclusion
Comme vous pouvez le constater, de nombreux éléments doivent être pris en compte lors de la configuration de votre pile de données. Compte tenu de tous les différents composants impliqués, il s'agit d'une entreprise de grande envergure et il peut être difficile de maîtriser toutes les pièces mobiles.
Comprendre pourquoi vous avez besoin d'une pile de données et comment cela profitera à votre entreprise vous permet de planifier à long terme en définissant des processus et des délais de mise en œuvre clairs. Les avantages de l'utilisation d'une pile de données moderne sont supérieurs à tous les défis en cours de route, non seulement en termes de projets et d'initiatives individuels, mais également en termes d'établissement d'une base solide qui vous aide à prendre de meilleures décisions dans l'ensemble.