
Технические аспекты сегментации клиентов — синхронизация данных
Опубликовано: 2022-04-18«Большой опыт анализа и сегментации баз данных CRM», «Хорошее понимание сегментации аудитории», «Понимание и опыт сегментации данных и предоставления персонализированного контента». Это примеры наиболее распространенных требований, предъявляемых к предложениям о работе в области CRM/маркетинга жизненного цикла. Хотя концепция сегментации клиентов довольно проста и с ней легко начать, чтобы стать профессионалом в области сегментации, необходимо погрузиться в технические детали. В этой статье мы хотим помочь вам совершить этот прыжок.
Оглавление:
- Сложность хранения и формата
- Форматы данных
- Частота синхронизации
- Среда синхронизации данных
- API-первый мир
- Триггеры синхронизации данных
Сегментация клиентов начинается со сбора данных о клиентах в одном центральном месте и подготовки их к группированию и принятию мер. Звучит просто, но увеличение числа источников данных усложняет сбор и анализ данных.
Вот почему эффективная сегментация начинается с обеспечения согласованного потока данных из нескольких источников данных на один сервер. Этот процесс получил название, которое вы, возможно, часто слышали в последнее время — синхронизация данных или просто синхронизация данных . Это процесс установления согласованности между системами и последующего непрерывного обновления для поддержания единообразия.
Множество умных слов означают, что это в первую очередь прерогатива команды инженеров. Но знакомство с ключевыми понятиями очень помогает. Вот обзор:
- Синхронизация данных — в этом разделе мы узнаем, как хранятся данные клиентов, почему люди хотят их перемещать и какие препятствия необходимо преодолеть цифровым командам для этого. В более практическом плане в этой главе объясняется внутренняя часть того, как современные системы CRM обмениваются данными через Интернет с помощью API.
- Целостность и безопасность данных. Следующая часть поможет вам понять, что нужно для поддержания данных в непротиворечивом состоянии после их синхронизации. Мы узнаем, как можно использовать схему для обеспечения уникальности данных и предотвращения их дублирования. Наконец, мы рассмотрим технические аспекты безопасности и конфиденциальности данных, поскольку они стали первоклассными гражданами после GDPR и CCPA.
- Обработка данных — наконец, мы поможем вам научиться свободно говорить, показав несколько советов по фильтрации данных и принятию решений на основе данных в целом.
Сложность хранения и формата
Из-за последних достижений в области технологий стоимость хранения данных снизилась. Это позволило предприятиям собирать огромные объемы данных.
Эти данные можно разделить на две категории: структурированные и неструктурированные . Чтобы сегментация работала, цифровым командам необходимо понять, как перейти от неструктурированного к структурированному.
Под структурированными хранилищами данных чаще всего подразумеваются базы данных SQL или файлы Excel . Это отличные и универсальные инструменты, но есть и свои минусы. SQL трудно выучить людям без технического образования, главное преимущество Excel, гибкость, становится кошмаром для долгосрочного поддержания целостности данных. Вот почему эти программные инструменты общего назначения были заменены более специализированными, такими как CRM, CMS, ERP или инструменты аналитики.
Хотя эти ориентированные на работу инструменты повышают производительность в областях, для которых они наняты, они часто становятся проблемой на уровне отдела/компании. Почему это? Каждый из этих инструментов обычно использует свой собственный формат данных, и, если обе программные платформы не интегрированы друг с другом, обмен данными затруднен. И таких инструментов современный маркетолог использует чертовски много.
Вот почему для большинства процессов синхронизации данных требуется посредник . Он адаптирует формат данных, сгенерированный исходным программным обеспечением (называемым «источником» в мире ИТ), к формату назначения («цели»). Процесс такой адаптации называется ETL. Это аббревиатура от «Извлечь» (данные из источника), «Преобразовать» (таким образом, чтобы они были распознаны и приняты целью), «Загрузить» (это для цели с сохранением согласованности данных).
Какие форматы данных вы можете встретить в индустрии сегментации клиентов?
Форматы данных
В настоящее время программное обеспечение для сегментации в большинстве случаев использует два открытых формата для синхронизации данных. Но что такое «формат данных»? Это не что иное, как текст, структурированный так, чтобы он был понятен для компьютеров. Начнем с первого, более простого.
CSV — значения, разделенные запятыми. Представьте, что вы садитесь за стол. Обычная таблица из MS Word вполне подойдет. Теперь удалим внешние границы и заменим внутренние запятыми. Вуаля, вы только что создали файл CSV.
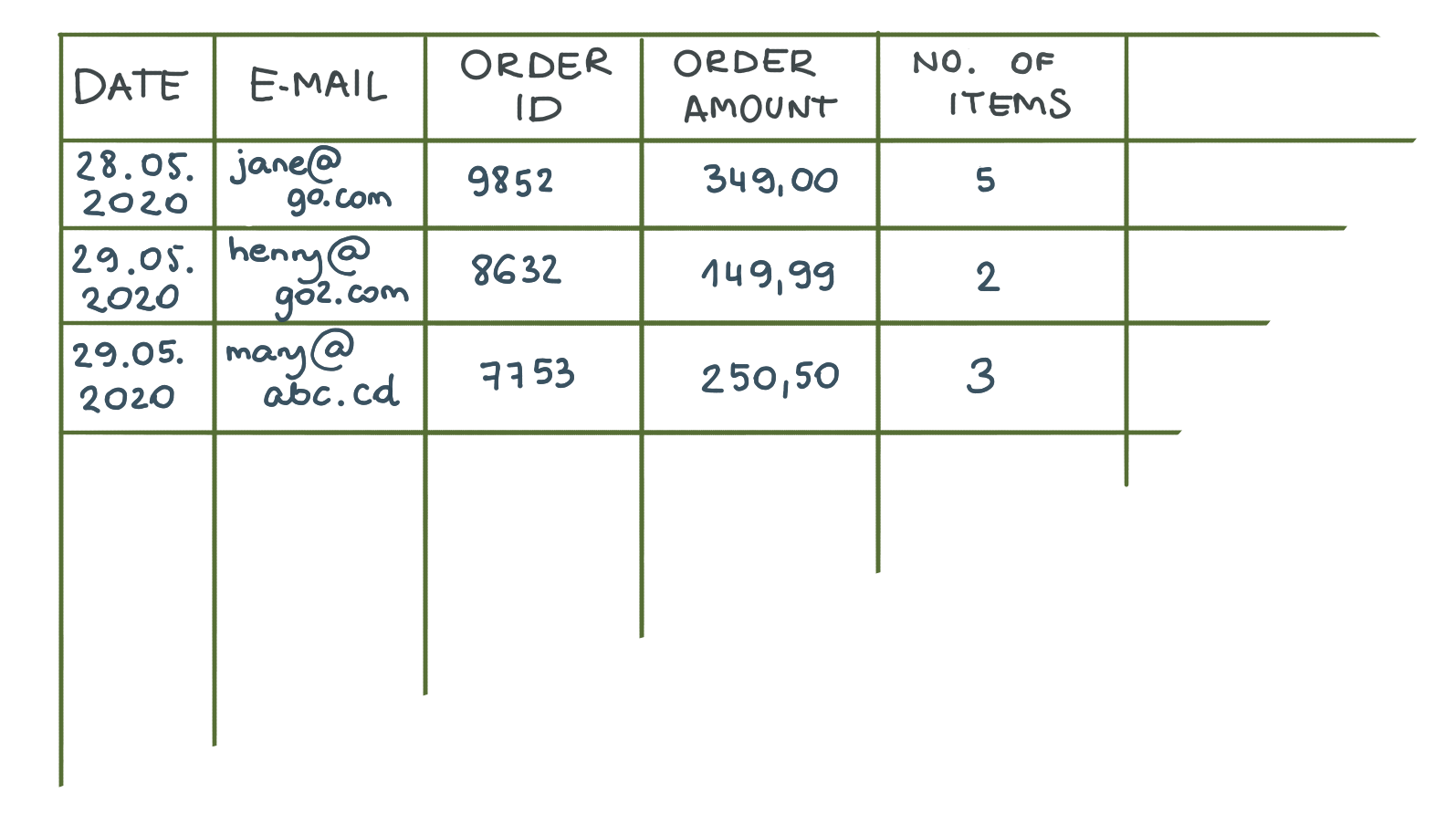
Самое большое преимущество? Простота и компактность. Разработчики могут легко экспортировать данные в этот формат, поскольку базы данных SQL и Excel хранят данные в таблицах.
С другой стороны, у CSV есть два серьезных недостатка. Во-первых, в файле CSV нельзя представить иерархию. Например, вы не можете показать, что одно значение связано с другим. Второй по значимости недостаток заключается в том, что CSV является фиксированным форматом. Это позволяет вам обмениваться данными в соответствии с точным количеством и типом столбцов, которые вы определили в начале. Если вы добавите столбец, необходимый для другой целевой системы, или просто удалите столбец, это вызовет ошибку при попытке импорта. В таком случае разработчикам потребуется скорректировать код, чтобы отразить структурные изменения.
Из-за динамики, которую получили маркетинговые технологии в последние годы, это ограничение оказалось серьезным препятствием.
По этой причине современные системы начали обмениваться данными с данными XML и JSON . Оба они основаны на одной и той же концепции представления данных. Мы опишем последний, потому что он более популярен.

Это пример файла JSON. Когда мы сравним наш файл JSON с аналогом в формате CSV, мы сразу обнаружим сходство — мы увидим, что в этом файле хранятся точно такие же данные.
Разительное отличие состоит в том, что имена столбцов из CSV-файлов повторяются. Хотя это может показаться избыточным и затрудняющим читаемость для людей, именно повторение придает JSON гибкость — оно делает порядок элементов неактуальным. Это полезно, если вам нужно добавить новое свойство (столбец) в обмениваемый файл. Целевое программное обеспечение, которое ожидает новое свойство, использует его, в то время как цели, обработавшие файл до добавления столбца, проигнорируют новое свойство и будут работать без помех.
Эта функция гарантирует, что если вы добавите дополнительные поля в формат данных, отправляемый исходным приложением, это не нарушит цель. Вот почему формат JSON считается более масштабируемым и гибким, чем CSV .
Подробнее о файлах JSON можно прочитать здесь.
Частота синхронизации
Сегодня общее требование состоит в том, чтобы системы электронной коммерции работали в режиме реального времени . Клиенты хотят видеть, каков статус их заказа, отслеживание посылки в режиме реального времени или текущий баланс на их счету. Кроме того, маркетологи хотят быстро реагировать, они хотят проводить кампании в режиме реального времени, которые создают своевременный покупательский опыт.
Для этого базовые хранилища данных используют синхронизацию в реальном времени .
Однако есть две проблемы с синхронизацией в реальном времени, о которых следует помнить.
Во-первых, общее эмпирическое правило: чем большую актуальность вы хотите получить, тем дороже это будет стоить . Эта стоимость проявляется во времени разработчиков, но также и в аппаратном обеспечении, на котором работают серверы (сегодня это в основном облачные решения), необходимо поддерживать системы синхронизации данных в рабочем состоянии. Итак, ваша самая первая задача, прежде чем выдвигать требование «в реальном времени» при разговоре с инженерами, — это подумать, какая частота синхронизации данных вам действительно нужна. Возможно, обновлений, отправляемых раз в час или раз в день, достаточно, чтобы обеспечить отличный клиентский опыт, сократив работу разработчиков и сэкономив бюджет.

Другая проблема связана с возможностями извлечения данных из хранилищ данных, с которыми вы работаете. Иногда синхронизация в реальном времени может быть затруднена, если одна из систем не предоставляет простой способ извлечения данных. Легкий означает удобный для разработчиков. Давайте подробно проанализируем этот вопрос, рассмотрев, как разработчики перемещают данные по системам.
Среда синхронизации данных
Мы узнали, как хранятся данные, какие форматы используются для обмена и как частота синхронизации может повлиять на усилия по настройке всей системы синхронизации. Но что на самом деле нужно для переноса данных из одной базы данных в другую? Ну, вам нужна среда.
Это может быть физическое хранилище, такое как DVD, USB-накопитель или другая аппаратная синхронизация, но из-за огромных объемов данных и требований к синхронизации в реальном времени сегодня мало кто делает это таким образом. В большинстве случаев все это осуществляется по кабелю или, на самом деле, по множеству кабелей, соединенных между собой компьютерами по всему миру, называемыми Интернетом.
Чтобы быть более конкретным, современные программные платформы используют протокол передачи гипертекста (HTTP), который является основой Всемирной паутины.
Если вам интересно (а вам лучше бы это было!) узнать, как серверы взаимодействуют друг с другом через Интернет, мы настоятельно рекомендуем ознакомиться с этим руководством по серверам для неспециалистов.

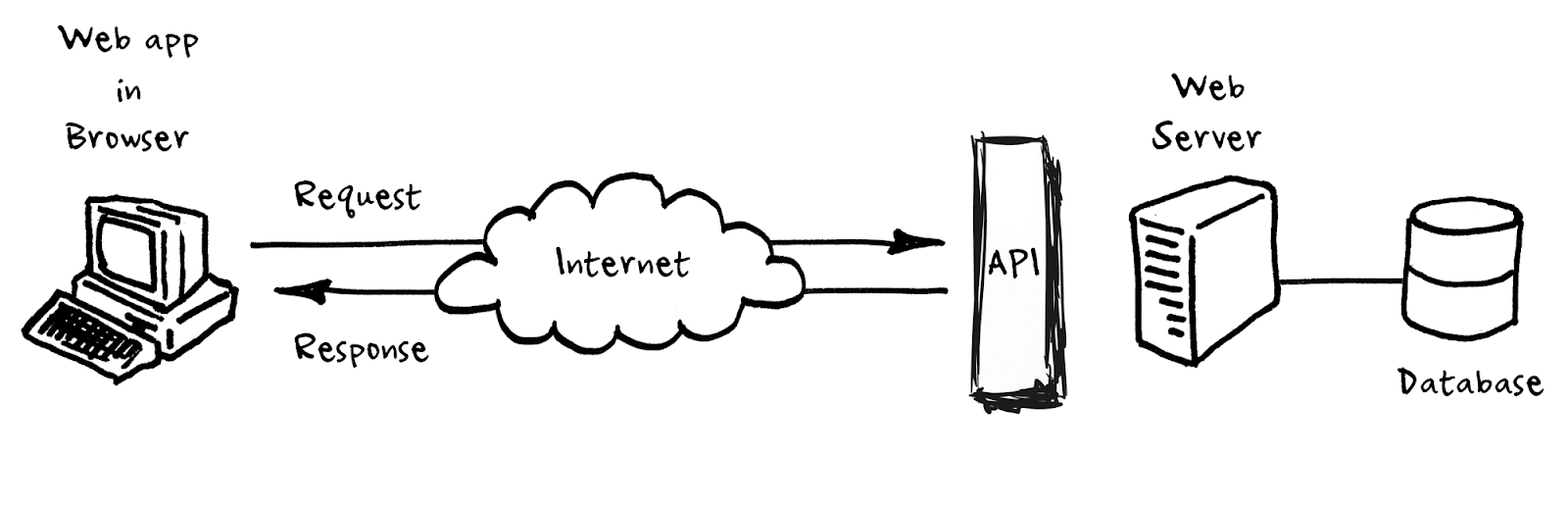
В двух словах, вы можете относиться к протоколу HTTP как к рекомендациям, сообщающим разработчикам, как они отправляют данные через Интернет. Поверх HTTP разработчики создают интерфейсы прикладного программирования (API) , которые представляют собой конкретные описания того, какими данными и в каком порядке можно обмениваться между двумя системами.
Программное обеспечение, которое делает API доступным в Интернете и делает его доступным для других систем (аналогично тому, как вы посещаете обычную веб-страницу), называется сервером приложений. Все, что он делает, — это слушает и отвечает на запросы, поступающие от других серверов приложений, и в зависимости от запроса добавляет или получает информацию из базовой базы данных. Полезная информация: когда люди упоминают API, часто это ярлык для сервера приложений, который предоставляет API в Интернет.
Тогда давайте поиграем с API.
API-первый мир
API-интерфейсы стали лингва-франка современного цифрового маркетинга. Большая часть работы по синхронизации данных сегодня связана с изучением API, чтобы иметь возможность извлекать из него данные. Это похоже на изучение еще одного набора слов иностранного языка, если вы знаете грамматику, которая в данном случае определяется HTTP.
Хотя это работа разработчика, погружение в эту тему может помочь вам ориентироваться в мире маркетинговых технологий.
Мы создали специальную статью с некоторыми практическими примерами понимания API, поэтому, если вы хотите освоить ее (и опять же, вы должны), прочтите ее здесь .
Вот самый важный отрывок из него:
«Если вы идете в ресторан в качестве клиента, вам нельзя входить на кухню. Вы должны знать, что доступно. Для этого у вас есть меню. Ознакомившись с меню, вы делаете заказ официанту, который передает его на кухню и доставляет то, что вы просили. Официант может доставить только то, что может предоставить кухня.
Как это связано с API? Официант — это API. Вы тот, кто просит об услуге. Другими словами, вы являетесь клиентом или потребителем API. Меню — это документация, объясняющая, что вы можете запросить у API. Кухня — это, например, сервер; базу данных, которая содержит только определенный тип данных — все, что покупатель купил для ресторана в качестве ингредиентов, что шеф-повар решил предложить и что повара умеют готовить».
- Кухня — База данных, клиентам не разрешено защищать целостность данных.
- Официант — API, посредник, который знает, как обслуживать данные из базы данных, не нарушая ее функционирования.
- Клиент — внешняя система, которая хочет получить свои данные.
- Меню — ссылка на формат данных, который внешние системы должны использовать для выполнения своей работы.
- Заказ — фактический отдельный вызов API.
Возвращаясь к синхронизации, теперь остается выяснить, при каких условиях две системы должны обмениваться данными.
Триггеры синхронизации данных
Предположим, у нас есть два сервера приложений, готовых к обмену информацией. Чтобы быть более конкретным, давайте представим, что ваш поставщик услуг электронной почты ( ESP ) хочет знать количество заказов клиентов (интернет-магазин), чтобы отправить им промо-купон после десятого заказа. Теперь, какой поток данных мы можем реализовать для реализации этого сценария? Мы можем выделить три «триггера», которые могут запустить механизм электронных купонов на стороне ESP.
а) Опрос данных – в этом случае ESP повторно запрашивает API интернет-магазина: «Сообщите мне общую сумму заказа для Джейн Доу». Он делает это каждую минуту, час, день и т. д. Когда ESP получает информацию, он будет пересчитывать условия отправки купона при каждом запросе API. Ваша интуиция верна, если вы думаете, что вызывать и обрабатывать данные таким образом может быть неоптимально. Какая альтернатива?

б) Передача данных — что, если бы интернет-магазин мог уведомить приложение ESP в тот момент, когда Джейн сделала свой 10-й заказ? Это верно. Современные платформы электронной коммерции осознали эти недостатки и включили такие уведомления в свой набор функций. Их обычно называют веб- перехватчиками или вызовами. Это простая, но мощная функция. Это позволяет вам определить, когда и какие приложения должны быть уведомлены при определенных условиях. Вы также можете определить, какую информацию должно включать в себя уведомление — иногда разумно отправить полную информацию, но часто достаточно только измененного свойства.

в) Пакетная обработка — иногда количество запросов настолько велико, что ни один из этих двух методов не является разумным. Объем вычислительной мощности, необходимый для обработки нагрузки, нанесет ущерб одной (или даже обеим) сторонам. В этом случае разработчики группируют всю информацию в «пакет» и планируют обмен данными на ночь или, в более общем смысле, когда серверы не загружены дневным трафиком. Это помогает контролировать трафик к приложениям и предотвращает потенциальную нагрузку на сервер.

Полезные термины: чтобы предотвратить отправку слишком большого количества запросов на сервер, разработчики приложений применяют к своим приложениям ограничители скорости . Он ограничивает количество вызовов API в заданный период, например, 5000 вызовов в минуту. Часто вызовы, превышающие квоту, блокируются . Это означает, что они будут обслуживаться в конце концов (вместо того, чтобы полностью отбрасываться), но с некоторой задержкой.
Итак, мы узнали, как синхронизируются данные клиентов. Но прежде чем можно будет произвести фактическую сегментацию клиентов, нам нужно понять, как обеспечить согласованность данных в вашей базе данных. В следующей части мы опишем, как обеспечить целостность и безопасность данных для повышения эффективности кампаний.