
顧客セグメンテーションの技術的側面–データ同期
公開: 2022-04-18「CRMデータベースの分析とセグメント化に関する豊富な経験」、「オーディエンスセグメンテーションの強力な把握」、「データセグメンテーションとパーソナライズされたコンテンツの提供に関する理解と経験」。 これらは、CRM/ライフサイクルマーケティングの求人に課せられる最も一般的な要件の例です。 顧客セグメンテーションの概念は非常に単純で、開始するのは簡単ですが、セグメンテーションのプロになるには、技術的な詳細に飛び込む必要があります。 この記事で、私たちはあなたがこの飛躍を遂げるのを手伝いたいと思っています。
目次:
- ストレージとフォーマットの複雑さ
- データ形式
- 同期周波数
- データ同期媒体
- APIファーストの世界
- データ同期トリガー
顧客のセグメンテーションは、顧客データを1つの中心的な場所に収集し、グループ化して対応できるようにすることから始まります。 簡単に聞こえますが、データソースの数が増えると、データの収集と処理が複雑になります。
そのため、効率的なセグメンテーションは、複数のデータソースから単一のサーバーへの一貫したデータフローを確保することから始まります。 このプロセスは、最近よく耳にするかもしれない名前を獲得しました—データ同期または単にデータ同期。 これは、システム間の一貫性を確立し、その後の継続的な更新によって均一性を維持するプロセスです。
多くの巧妙な言葉は、それが主にエンジニアリングチームのドメインであることを意味します。 しかし、重要な概念に精通することは大いに役立ちます。 概要は次のとおりです。
- データの同期–このセクションでは、顧客データがどのように保存されるか、人々がデータを移動する理由、およびデジタルチームがそのために克服する必要のある障害について学習します。 より実用的なメモとして、この章では、最新のCRMシステムがインターネットを介してAPIを使用してデータを交換する方法の内部について説明します。
- データの整合性とセキュリティ–次のパートでは、データを同期した後、データを一貫した状態に保つために必要なことを理解するのに役立ちます。 スキーマを使用してデータの一意性を処理し、データの重複を防ぐ方法を学習します。 最後に、GDPR後とCCPAの時代に一流の市民になったため、データのセキュリティとプライバシーの技術的側面について考察します。
- データクランチ–最後に、データフィルタリングと一般的なデータ主導の意思決定に関するヒントをいくつか紹介することで、流暢になるのを支援します。
ストレージとフォーマットの複雑さ
最近の技術開発により、データストレージのコストは下がっています。 これにより、企業は膨大な量のデータを収集できるようになりました。
これらのデータは、構造化データと非構造化データの2つのカテゴリに分類できます。 セグメンテーションを機能させるには、デジタルチームは非構造化から構造化に移行する方法を理解する必要があります。
構造化データストレージとは、主にSQLデータベースまたはExcelファイルを意味します。 それらは素晴らしく用途の広いツールですが、短所もあります。 SQLは、技術的なバックグラウンドがない人にとっては習得が困難です。Excelの最大の利点である柔軟性は、データの整合性を長期的に維持するための悪夢になります。 そのため、これらの汎用ソフトウェアツールは、CRM、CMS、ERP、分析ツールなど、より焦点を絞ったツールで超構造化されています。
これらの仕事指向のツールは、雇用されている分野の生産性を向上させますが、部門/会社レベルで問題になることがよくあります。 なんで? これらのツールは通常、独自のデータ形式を使用しており、両方のソフトウェアプラットフォームが相互に統合されていない限り、データ交換が妨げられます。 そして、現代のマーケティング担当者は、そのようなツールをたくさん使用しています。
これが、ほとんどのデータ同期プロセスに仲介者が必要な理由です。 これは、オーサリングソフトウェア(ITの世界では「ソース」と呼ばれます)によって生成されたデータ形式を宛先形式(「ターゲット」)に適合させます。 このような適応のプロセスはETLと呼ばれます。 これは、Extract(ソースからのデータ)、Transform(ターゲットによって認識され、受け入れられる方法)、Load(データの一貫性を維持するターゲットへのデータ)の略語です。
カスタマーセグメンテーション業界では、どのようなデータ形式に対応できますか?
データ形式
現在、セグメンテーションソフトウェアは、ほとんどの場合、データ同期の目的で2つのオープンフォーマットを使用しています。 しかし、とにかく「データ形式」とは何ですか? これは、コンピューターが理解できるように構造化されたテキストにすぎません。 最初の、より単純なものから始めましょう。
CSV –カンマ区切り値。 あなたがテーブルを取ると想像してください。 MSWordの通常のテーブルで十分です。 次に、外部の境界線を削除し、内部の境界線をコンマに置き換えましょう。 出来上がり、CSVファイルを作成しました。
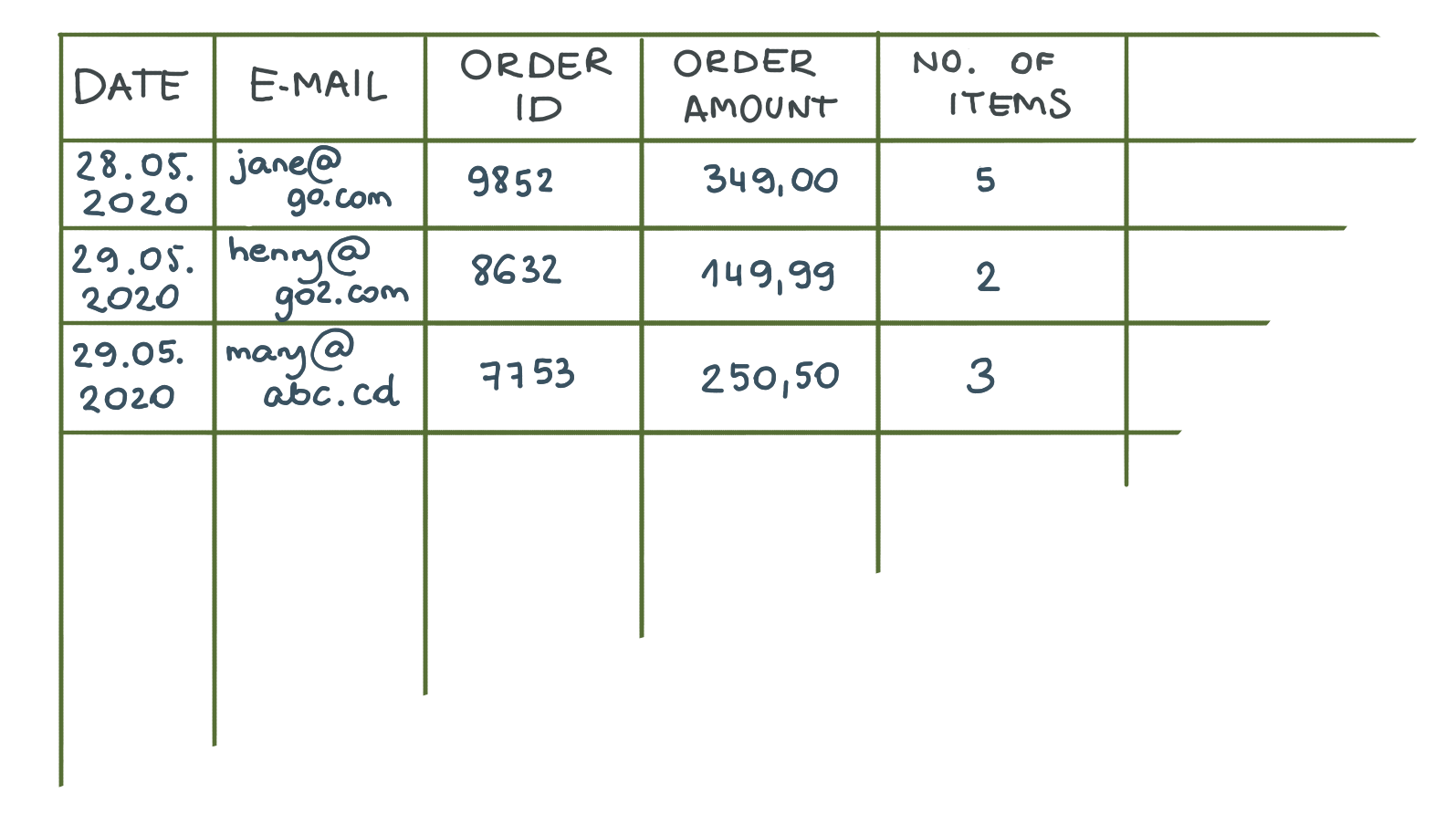
最大の利点は? シンプルさとコンパクトさ。 SQLおよびExcelデータベースはデータをテーブルに格納するため、開発者はこの形式でデータを簡単にエクスポートできます。
一方、CSVには2つの大きな欠陥があります。 まず、CSVファイル内では、階層を表すことはできません。 たとえば、ある値が別の値に関連していることを示すことはできません。 2番目に重要な欠点は、CSVが固定形式であることです。 最初に定義した列の正確な数とタイプに従ってデータを交換できます。 別のターゲットシステムに必要な列を追加したり、単に列を削除したりすると、インポートの試行でエラーが発生します。 このような場合、開発者は構造上の変更を反映するようにコードを調整する必要があります。
マーケティングテクノロジーが近年獲得したダイナミクスのために、この制限は大きな障害であることが判明しました。
このため、最近のシステムはXMLおよびJSONデータとデータを交換し始めました。 これらは両方とも、データ表現の同じ概念に基づいています。 後者の方が人気があるので説明します。

これはJSONファイルの例です。 JSONファイルをCSVファイルと比較すると、すぐに類似点が見つかります。このファイルにはまったく同じデータが格納されていることがわかります。
顕著な違いは、CSVファイルの列名が繰り返されることです。 これは冗長で人間の可読性を妨げるように見えるかもしれませんが、JSONの柔軟性を与えるのは繰り返しであり、アイテムの順序は無関係になります。 これは、交換されたファイルに新しいプロパティ(列)を追加する必要がある場合に役立ちます。 新しいプロパティを期待するターゲットソフトウェアはそれを消費しますが、列を追加する前にファイルを処理したターゲットは新しいプロパティを無視し、邪魔されずに動作します。
この機能は、ソースアプリケーションによって送信されたデータ形式にさらにフィールドを追加しても、ターゲットを壊さないことを保証します。 これが、 JSON形式がCSVよりもスケーラブルで柔軟性があると言われている理由です。
JSONファイルの詳細については、こちらをご覧ください。
同期周波数
今日の一般的な要件は、eコマースシステムがリアルタイムであることです。 顧客は、注文のステータス、リアルタイムの小包追跡、またはアカウントの現在の残高を確認したいと考えています。 また、マーケターは迅速に対応したいと考えており、タイムリーなショッピング体験を生み出すリアルタイムキャンペーンを実行したいと考えています。
これを実現するために、基盤となるデータストレージはリアルタイム同期を採用しています。
ただし、リアルタイム同期には注意が必要な2つの課題があります。
まず、一般的な経験則—取得したいリアルタイム性が高いほど、コストも高くなります。 このコストは開発者の時代に現れますが、サーバーを実行するハードウェア(現在はほとんどがクラウドソリューション)でも、データ同期システムを稼働させ続ける必要があります。 したがって、エンジニアと話すときに「リアルタイム」要件を設定する前の最初のタスクは、実際に必要なデータ同期頻度の種類を検討することです。 おそらく、1時間に1回または1日に1回送信される更新は、開発者の作業を削減し、予算を節約しながら、優れたカスタマーエクスペリエンスを保証するのに十分です。

もう1つの課題は、使用するデータストレージのデータ抽出機能です。 システムの1つがデータを抽出する簡単な方法を提供していない場合、リアルタイム同期が妨げられることがあります。 簡単な意味は開発者に優しい。 開発者がシステム内でデータを移動する方法を見て、この問題を詳細に分析してみましょう。
データ同期媒体
データの保存方法、交換に使用される形式、同期頻度が同期システム全体の設定作業にどのように影響するかを学びました。 しかし、あるデータベースから別のデータベースにデータを転送するには、実際に何が必要ですか? さて、あなたは媒体が必要です。
DVD、USBドライブ、またはその他のハードウェアベースの同期などの物理ストレージにすることができますが、大量のデータとリアルタイムの同期要件があるため、今日この方法で実行するものはほとんどありません。 ほとんどの場合、それはすべてケーブルを介して、または実際にはインターネットと呼ばれる世界中のコンピューターによって相互接続された多くのケーブルを介して行われます。
具体的には、最新のソフトウェアプラットフォームは、ワールドワイドウェブの基盤であるハイパーテキスト転送プロトコル(HTTP)を使用しています。
サーバーがインターネットを介して相互に通信する方法に興味がある場合(そして興味がある場合は!)、この技術者以外のサーバーガイドにジャンプすることを強くお勧めします。

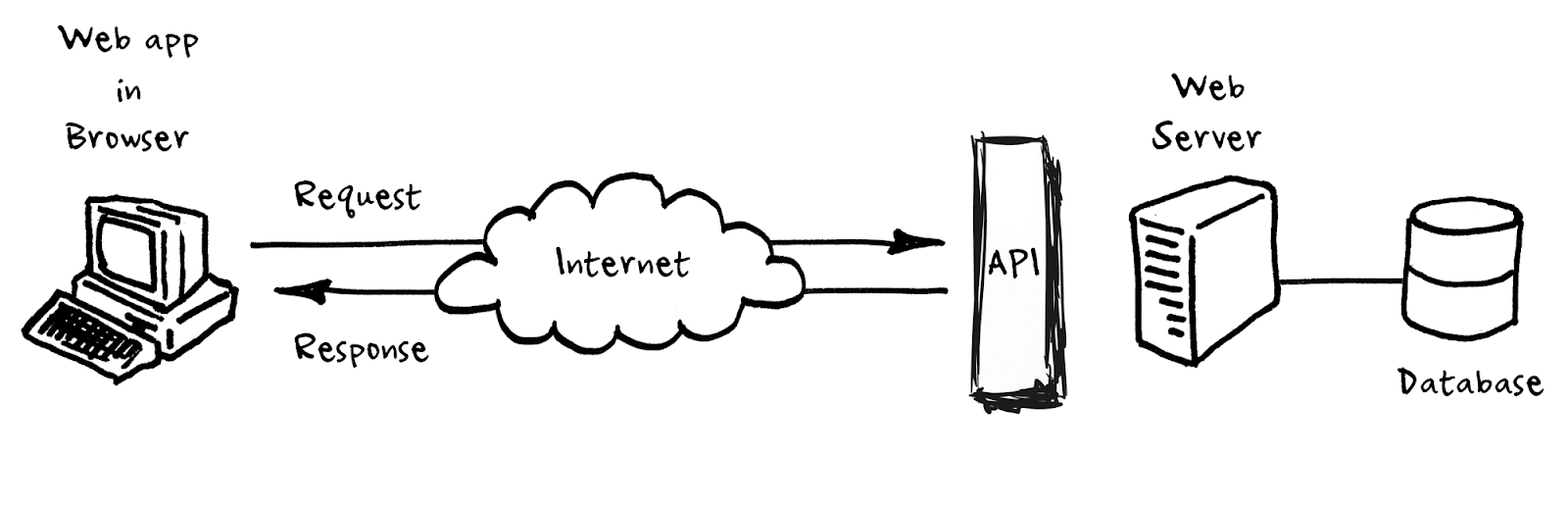
一言で言えば、HTTPプロトコルを、開発者がインターネット経由でデータを送信する方法を指示するガイドラインのように扱うことができます。 開発者は、HTTPに加えて、2つのシステム間で交換できるデータと順序の具体的な説明であるアプリケーションプログラミングインターフェイス(API)を作成します。
APIをインターネットで利用可能にし、他のシステムからアクセスできるようにするソフトウェア(通常のWebページにアクセスする方法と同様)は、アプリケーションサーバーと呼ばれます。 他のアプリケーションサーバーからのリクエストをリッスンして応答するだけで、リクエストに応じて、基盤となるデータベースから情報を追加または取得します。 有用な情報:人々がAPIについて言及するとき、それは多くの場合、APIをインターネットに公開するアプリケーションサーバーへのショートカットです。
それでは、APIを試してみましょう。
APIファーストの世界
APIは、今日のデジタルマーケティングの共通語になっています。 今日のデータ同期作業のほとんどは、APIからデータを抽出できるようにするためのAPIを学習しています。 これは、文法を知っていると仮定して、外国語から別の単語のセットを学習するようなものです。この場合、文法はHTTPで定義されています。
これは開発者の仕事ですが、このトピックに飛び込むと、マーケティングテクノロジーの世界をナビゲートするのに役立つ場合があります。
APIを理解するためのいくつかの実用的な例を含む専用の記事を作成したので、それを習得したい場合(そしてまたそうすべきです)、ここを読んでください。
これはそれからの最も重要な抜粋です:
「お客様としてレストランに行く場合、厨房に入ることはできません。 何が利用できるかを知る必要があります。 そのために、あなたはメニューを持っています。 メニューを見た後、ウェイターに注文します。ウェイターはそれをキッチンに渡し、ウェイターがあなたが求めていたものを配達します。 ウェイターは、キッチンが提供できるものだけを配達できます。
それはAPIとどのように関連していますか? ウェイターはAPIです。 あなたはサービスを求めている人です。 言い換えれば、あなたはAPIの顧客または消費者です。 メニューは、APIに何を求めることができるかを説明するドキュメントです。 キッチンは、たとえばサーバーです。 特定の種類のデータのみを保持するデータベース。バイヤーがレストランのために材料として購入したもの、シェフが提供することを決定したもの、料理人が準備する方法を知っているものは何でも。」
- キッチン–データベース。データの整合性を保護することを許可された顧客はありません。
- ウェイター– API、データベースの機能を中断することなくデータベースからデータを提供する方法を知っている仲介者。
- 顧客–データを取得したい外部システム。
- メニュー–外部システムが操作を実行するために使用する必要のあるデータ形式参照。
- 注文–実際の単一のAPI呼び出し。
同期に戻ると、残りの問題は、2つのシステムがどのような条件下でデータを交換する必要があるかを理解することです。
データ同期トリガー
情報を交換する準備ができている2つのアプリケーションサーバーがあると仮定します。 具体的には、電子メールサービスプロバイダー( ESP )が、10回目の注文後にプロモーションクーポンを送信するために顧客の注文(eショップ)の数を知りたいと考えているとします。 では、このシナリオを実現するために、どのようなデータフローを実装できますか? ESP側でメールクーポン機構を起動できる3つの「トリガー」を区別できます。
a)データポーリング–この場合、ESPはe-shop APIに繰り返し要求しています:「JaneDoeの合計注文額を教えてください」。 これは、1分ごと、1時間ごと、または1日ごとなどに行われます。ESPは情報を受信すると、APIリクエストごとにクーポンの送信条件を再計算します。 これがこの方法でデータを呼び出して処理するのに最適ではないかもしれないと考えているなら、あなたの腸の感覚は正しいです。 代替手段は何ですか?

b)データプッシュ–ジェーンが10回目の注文をした瞬間に、eショップがESPアプリケーションに通知できるとしたらどうでしょうか。 それは正しい。 最新のeコマースプラットフォームはこれらの欠点を認識しており、そのような通知を機能セットに含めています。 それらは通常、 Webhookまたはコールアウトと呼ばれます。 シンプルでありながら強力な機能です。 特定の条件下でいつ、どのアプリケーションに通知するかを定義できます。 通知に含める情報の種類を定義することもできます。完全な情報を送信するのが合理的な場合もありますが、多くの場合、変更されたプロパティだけで十分です。

c)バッチ処理–リクエストの数が非常に多いため、これら2つの方法のどちらも合理的でない場合があります。 負荷を処理するために必要な処理能力の量は、一方(または両方)の当事者に害を及ぼします。 この場合、開発者はすべての情報を「バッチ」にグループ化し、夜間、またはより一般的にはサーバーが毎日のトラフィックでビジーでないときにデータ交換をスケジュールします。 これは、アプリケーションへのトラフィックを制御し、サーバーへの潜在的な負担を防ぐのに役立ちます。

有用な用語:サーバーに送信するリクエストが多すぎるのを防ぐために、アプリケーション開発者はアプリケーションにレートリミッターを適用します。 これにより、特定の期間のAPI呼び出しの数が制限されます。たとえば、1分あたり5000回の呼び出しです。 多くの場合、クォータを超える呼び出しは抑制されます。 これは、それらが最終的に(完全に削除されるのではなく)提供されることを意味しますが、多少の遅延があります。
これまで、顧客データがどのように同期されるかを学びました。 ただし、実際の顧客セグメンテーションが発生する前に、データベース内のデータの一貫性を維持する方法を理解する必要があります。 次のパートでは、データの整合性とセキュリティを確保して、パフォーマンスの高いキャンペーンを実現する方法について説明します。