
Aspecte tehnice ale segmentării clienților – Sincronizarea datelor
Publicat: 2022-04-18„Experiență vastă în analizarea și segmentarea bazelor de date CRM”, „Cunoașterea puternică a segmentării publicului”, „Înțelegerea și experiența în segmentarea datelor și furnizarea de conținut personalizat”. Acestea sunt exemple ale celor mai frecvente cerințe plasate în ofertele de muncă CRM/marketing ciclului de viață. Deși conceptul de segmentare a clienților este destul de simplu și ușor de început, a deveni un profesionist în segmentare necesită o scufundare în detalii tehnice. Cu acest articol, vrem să vă ajutăm să faceți acest salt.
Cuprins:
- Complexitatea stocării și formatului
- Formate de date
- Frecvența de sincronizare
- Mediu de sincronizare a datelor
- API-prima lume
- Declanșează sincronizarea datelor
Segmentarea clienților începe cu colectarea datelor despre clienți într-un singur loc central și pregătirea acestora pentru grupare și acțiune asupra acestora. Sună ușor, dar un număr tot mai mare de surse de date adaugă complexitate la colectarea și analizarea datelor.
De aceea, segmentarea eficientă începe cu asigurarea fluxului de date consistent de la mai multe surse de date către un singur server. Acest proces a câștigat un nume pe care s-ar putea să-l fi auzit mult recent - sincronizarea datelor sau pur și simplu sincronizarea datelor . Este un proces de stabilire a coerenței între sisteme și actualizări continue ulterioare pentru a menține uniformitatea.
O mulțime de cuvinte inteligente înseamnă că este în primul rând domeniul echipei de ingineri. Dar să te familiarizezi cu conceptele cheie ajută foarte mult. Iată o prezentare generală:
- Sincronizarea datelor – în această secțiune vom afla cum sunt stocate datele clienților, de ce oamenii doresc să le mute și ce obstacole trebuie să depășească echipele digitale pentru a face acest lucru. Într-o notă mai practică, acest capitol explică părțile interioare ale modului în care sistemele CRM moderne schimbă date prin Internet cu API-uri.
- Integritatea și securitatea datelor – următoarea parte vă va ajuta să înțelegeți ce este nevoie pentru a păstra datele într-o stare consecventă după ce le sincronizați. Vom afla cum puteți folosi schema pentru a avea grijă de unicitatea datelor și pentru a preveni duplicarea datelor. În cele din urmă, vom reflecta asupra aspectelor tehnice ale securității și confidențialității datelor, deoarece aceștia au devenit cetățeni de primă clasă în perioada post-GDPR și CCPA.
- Strângerea datelor – în sfârșit, vă vom ajuta să deveniți fluent, arătându-vă câteva sfaturi despre filtrarea datelor și luarea deciziilor bazate pe date în general.
Complexitatea stocării și formatului
Din cauza evoluțiilor recente în tehnologie, costul stocării datelor a scăzut. Acest lucru a permis întreprinderilor să colecteze cantități enorme de date.
Aceste date pot fi împărțite în două categorii: structurate și nestructurate . Pentru ca segmentarea să funcționeze, echipele digitale trebuie să descopere cum să treacă de la nestructurat la structurat.
Prin stocare de date structurate ne referim în principal la baze de date SQL sau fișiere Excel . Sunt instrumente grozave și versatile, dar au și dezavantajele lor. SQL este greu de învățat pentru persoanele fără cunoștințe tehnice, avantajul de top al Excel, flexibilitatea, devine un coșmar pentru menținerea pe termen lung a integrității datelor. De aceea, aceste instrumente software de uz general au fost suprastructurate cu altele mai concentrate, cum ar fi CRM, CMS, ERP sau instrumente de analiză.
Deși aceste instrumente orientate spre locuri de muncă cresc productivitatea în domeniile pentru care sunt angajați, ele devin adesea o problemă la nivel de departament/companie. De ce e așa? Fiecare dintre aceste instrumente folosește de obicei propriul format de date și, cu excepția cazului în care ambele platforme software sunt integrate între ele, schimbul de date este împiedicat. Și, un marketer modern folosește o mulțime de astfel de instrumente.
Acesta este motivul pentru care majoritatea proceselor de sincronizare a datelor necesită un intermediar . Acesta adaptează formatul de date generat de software-ul de creație (numit „sursă” în lumea IT) la formatul de destinație („țintă”). Procesul unei astfel de adaptări se numește ETL. Este o abreviere de la Extract (date de la sursă), Transform (într-un fel în care este recunoscut și acceptat de țintă), Load (încărcare la țintă menținând consistența datelor).
Ce fel de formate de date puteți întâlni în industria de segmentare a clienților?
Formate de date
În zilele noastre, software-ul de segmentare utilizează două formate deschise pentru sincronizarea datelor în majoritatea cazurilor. Dar care este „formatul de date” oricum? Acesta nu este altceva decât un text structurat într-un mod care este de înțeles pentru computere. Să începem cu primul, mai simplu.
CSV – Valori separate prin virgulă. Imaginează-ți că iei o masă. Un tabel obișnuit din MS Word este bine. Acum haideți să eliminăm frontierele externe și să le înlocuim pe cele interne cu virgule. Voila, tocmai ai creat un fișier CSV.
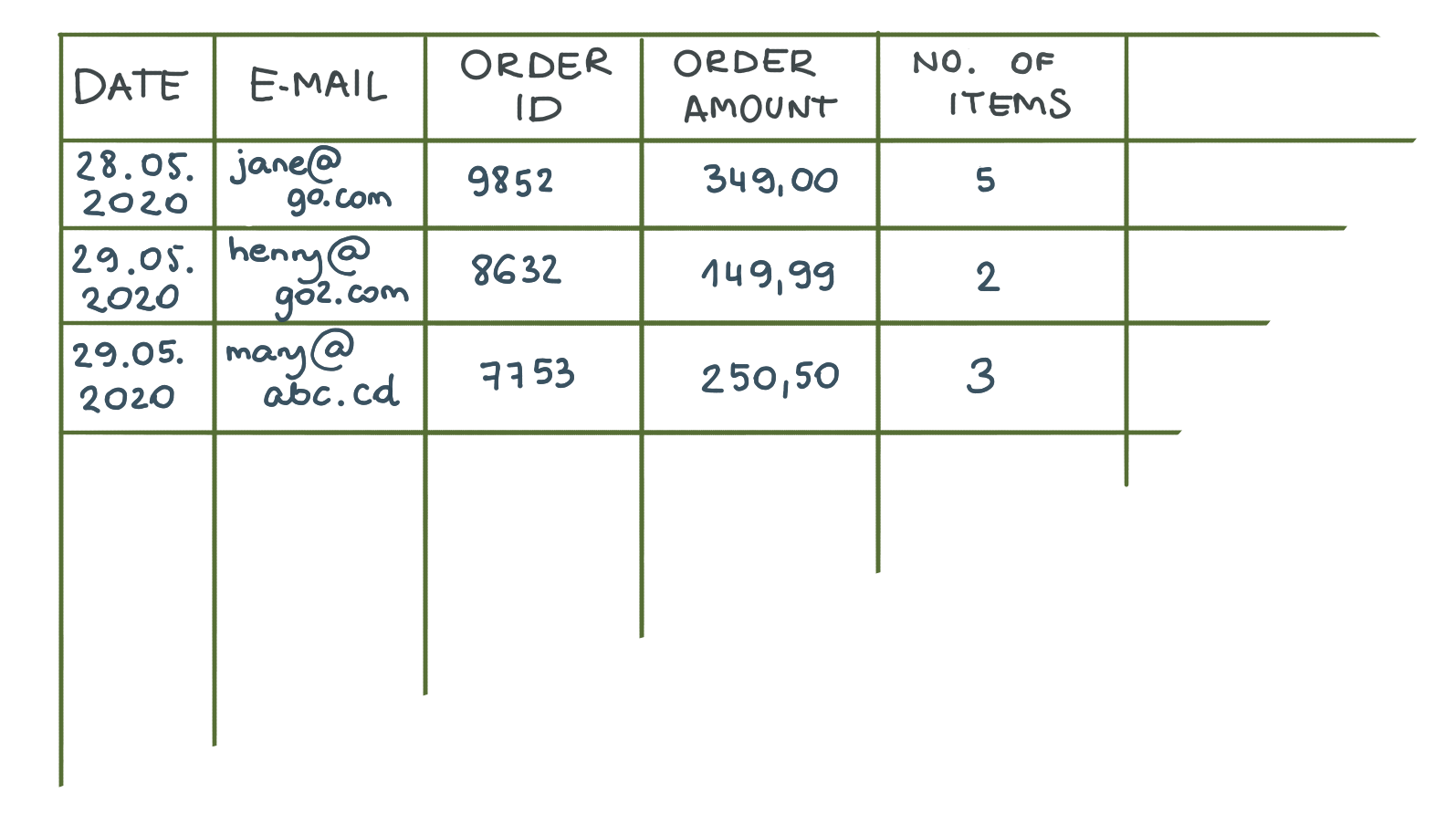
Cel mai mare avantaj? Simplitate și compactitate. Dezvoltatorii pot exporta cu ușurință datele în acest format, deoarece bazele de date SQL și Excel stochează date în tabele.
Pe de altă parte, CSV are două defecte majore. În primul rând, într-un fișier CSV, nu puteți reprezenta ierarhia. De exemplu, nu puteți arăta că o valoare este legată de alta. Al doilea cel mai important dezavantaj este că CSV este un format fix. Vă permite să faceți schimb de date în funcție de numărul exact și tipul de coloane pe care le-ați definit la început. Dacă adăugați o coloană necesară pentru un alt sistem țintă sau pur și simplu eliminați o coloană, va provoca o eroare la încercarea de import. Într-un astfel de caz, dezvoltatorii vor trebui să ajusteze codul pentru a reflecta modificările structurale.
Datorită dinamicii pe care tehnologia de marketing a câștigat-o în ultimii ani, această limitare s-a dovedit a fi un obstacol major.
Din acest motiv, sistemele moderne au început să facă schimb de date cu date XML și JSON . Ambele se bazează pe același concept de reprezentare a datelor. Îl vom descrie pe acesta din urmă pentru că este mai popular.

Acesta este un exemplu de fișier JSON. Când comparăm fișierul nostru JSON cu omologul CSV, vom găsi imediat asemănări - putem vedea că acest fișier stochează exact aceleași date.
Diferența izbitoare este că numele coloanelor din fișierele CSV sunt repetate. Deși acest lucru ar putea părea redundant și poate împiedica lizibilitatea pentru oameni, repetarea este cea care oferă flexibilitate JSON - face ordinea articolelor irelevantă. Acest lucru este util dacă trebuie să adăugați o nouă proprietate (o coloană) la un fișier schimbat. Software-ul țintă care se așteaptă la noua proprietate o va consuma, în timp ce țintele care au procesat fișierul înainte de adăugarea coloanei, vor ignora noua proprietate și vor funcționa netulburați.
Această caracteristică garantează că dacă adăugați mai multe câmpuri la formatul de date trimis de aplicația sursă, nu va rupe ținta. Acesta este motivul pentru care se spune că formatul JSON este mai scalabil și mai flexibil decât CSV .
Puteți citi mai multe despre fișierele JSON aici.
Frecvența de sincronizare
Cerința comună astăzi este ca sistemele de comerț electronic să fie în timp real . Clienții doresc să vadă care este starea comenzii lor, o urmărire în timp real a coletului sau care este soldul curent al contului lor. De asemenea, marketerii doresc să reacționeze rapid, doresc să ruleze campanii în timp real care creează experiențe de cumpărături în timp util.
Pentru a realiza acest lucru, depozitele de date subiacente au adoptat sincronizarea în timp real .
Cu toate acestea, există două provocări legate de sincronizarea în timp real de care trebuie să fiți atenți.
În primul rând, o regulă generală - cu cât doriți să obțineți mai mult timp real, cu atât costă mai mult . Acest cost se manifestă în timpul dezvoltatorilor, dar și cu hardware-ul care rulează serverele (azi sunt în mare parte soluții cloud) de care aveți nevoie pentru a menține sistemele de sincronizare a datelor în funcțiune. Așadar, prima ta sarcină înainte de a pune o cerință „în timp real” atunci când vorbești cu inginerii este să te gândești la ce tip de frecvență de sincronizare a datelor de care ai nevoie cu adevărat. Poate că actualizările trimise o dată pe oră sau o dată pe zi sunt suficiente pentru a asigura o experiență excelentă pentru clienți, reducând în același timp munca dezvoltatorilor și economisind bugetul.

Cealaltă provocare o reprezintă capacitățile de extragere a datelor ale depozitelor de date cu care lucrați. Uneori, sincronizarea în timp real poate fi împiedicată atunci când unul dintre sisteme nu oferă o modalitate ușoară de a extrage date. Înțeles ușor, prietenos pentru dezvoltatori. Să analizăm această problemă în detaliu, examinând modul în care dezvoltatorii mută datele în jurul sistemelor.
Mediu de sincronizare a datelor
Am aflat cum sunt stocate datele, ce formate sunt folosite pentru schimb și cum poate afecta frecvența de sincronizare eforturile de configurare a întregului sistem de sincronizare. Dar ce este nevoie de fapt pentru a transfera date de la o bază de date la alta? Ei bine, ai nevoie de un mediu.
Poate fi o stocare fizică, cum ar fi un DVD, o unitate USB sau o altă sincronizare bazată pe hardware, dar având în vedere cantitățile masive de date și cerințele de sincronizare în timp real, puțini fac asta astăzi. În majoritatea cazurilor, totul se face prin cablu sau, de fapt, prin multe cabluri interconectate de computere de pe tot globul - numite Internet.
Pentru a fi mai specific, platformele software moderne folosesc Hypertext Transfer Protocol (HTTP), care este fundamentul World Wide Web.
Dacă sunteți interesat (și ar fi bine să fiți!) de modul în care serverele vorbesc între ele prin intermediul internetului, vă recomandăm cu tărie să accesați acest ghid pentru servere pentru non-tehnie.

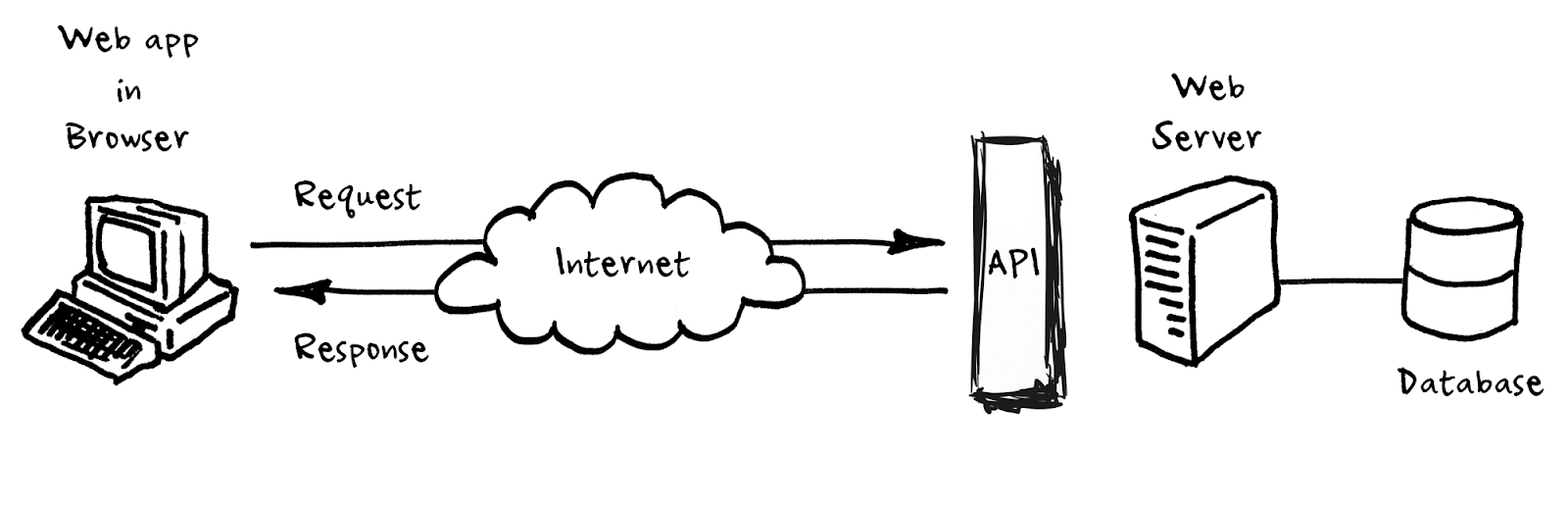
Pe scurt, puteți trata protocolul HTTP ca niște ghiduri care le spun dezvoltatorilor cum trimit datele prin Internet. Pe lângă HTTP, dezvoltatorii creează interfețe de programare a aplicațiilor (API) , care sunt descrieri specifice ale datelor și în ce ordine pot fi schimbate între două sisteme.
Software-ul care face un API disponibil pe Internet și îl face accesibil de către alte sisteme (în mod similar modului în care vizitați o pagină web obișnuită) se numește server de aplicații. Tot ce face este să asculte și să răspundă la solicitările care vin de la alte servere de aplicații și, în funcție de cerere, adaugă sau obține informații din baza de date de bază. Informații utile: când oamenii menționează API, este adesea o comandă rapidă pentru serverul de aplicații care expune API-ul la Internet.
Atunci să ne jucăm cu API-urile.
API-prima lume
API-urile au devenit o lingua franca a marketingului digital din zilele noastre. Cea mai mare parte a activității de sincronizare a datelor de astăzi este învățarea unui API pentru a putea extrage date din acesta. Este ca și cum ai învăța un alt set de cuvinte dintr-o limbă străină, presupunând că cunoști gramatica, care în acest caz este definită de HTTP.
Deși este treaba unui dezvoltator, aprofundarea acestui subiect vă poate ajuta să navigați în lumea tehnologiei de marketing.
Am creat un articol dedicat cu câteva exemple practice despre înțelegerea API-urilor, așa că, dacă vrei să-l stăpânești (și din nou, ar trebui), citește-l aici .
Acesta este cel mai important fragment din el:
„Dacă mergi la restaurant ca client, nu ai voie să intri în bucătărie. Trebuie să știi ce este disponibil. Pentru asta ai meniul. După ce te uiți la meniu, faci o comandă unui chelner, care o trece în bucătărie și care apoi va livra ceea ce ai cerut. Chelnerul poate livra doar ceea ce poate oferi bucataria.
Cum se leagă asta cu un API? Chelnerul este API-ul. Ești o persoană care cere servicii. Cu alte cuvinte, sunteți client sau consumator API. Meniul este documentația care explică ce poți cere de la API. Bucătăria este, de exemplu, un server; o bază de date care deține doar un anumit tip de date – orice a cumpărat cumpărătorul pentru restaurant ca ingrediente și ce a decis bucătarul că va oferi și ce știu bucătarii să pregătească.”
- Bucătărie – Baza de date, nu au permis clienților să protejeze integritatea datelor.
- Waiter – API-ul, un intermediar care știe să servească date din baza de date fără a perturba funcționarea acesteia.
- Client – Un sistem extern care dorește să-și obțină datele.
- Meniu – Formatul de date face referire la sistemele externe pe care trebuie să le folosească pentru a-și efectua funcționarea.
- Comanda – Un singur apel API real.
Revenind la sincronizare, întrebarea care rămâne acum este să ne dăm seama în ce condiții ar trebui să schimbe date două sisteme.
Declanșează sincronizarea datelor
Să presupunem că avem două servere de aplicații gata să facă schimb de informații. Pentru a fi mai precis, să ne imaginăm că furnizorul de servicii de e-mail ( ESP ) dorește să cunoască numărul de comenzi ale clienților (e-shop) pentru a le trimite un cupon promoțional după a zecea comandă. Acum, ce fel de flux de date putem implementa pentru a realiza acest scenariu? Putem distinge trei „declanșatoare” care pot porni mașina de cupon de e-mail din partea ESP.
a) Sondaj de date – în acest caz, ESP solicită în mod repetat API-ului magazinului electronic: „Anunțați-mi suma totală a comenzii pentru Jane Doe”. Face acest lucru la fiecare minut, o oră sau o zi etc. Când ESP primește informațiile, va recalcula condițiile de expediere a cuponului pentru fiecare solicitare API. Sentimentul tău este corect dacă te gândești că acest lucru ar putea fi suboptim să apelezi și să procesezi datele în acest fel. Care este alternativa?

b) Impingerea datelor – ce se întâmplă dacă un magazin electronic ar putea notifica aplicația ESP în momentul în care Jane a făcut cea de-a zecea comandă? Asta e corect. Platformele moderne de comerț electronic și-au dat seama de aceste deficiențe și au inclus astfel de notificări în setul lor de funcții. Ele sunt de obicei numite webhooks sau call-outs. Este o funcționalitate simplă, dar puternică. Vă permite să definiți când și ce aplicații trebuie notificate în anumite condiții. De asemenea, puteți defini ce fel de informații ar trebui să includă o notificare - uneori este rezonabil să trimiteți informații complete, dar adesea doar o proprietate modificată este suficientă.

c) Procesare în lot – uneori, numărul de solicitări este atât de mare încât niciuna dintre aceste două metode nu este rezonabilă. Cantitatea de putere de procesare necesară pentru a gestiona sarcina ar dăuna uneia (sau chiar ambelor) părți. În acest caz, dezvoltatorii grupează toate informațiile într-un „lot” și programează schimbul de date noaptea sau, mai general, când serverele nu sunt ocupate cu traficul zilnic. Acest lucru ajută la controlul traficului către aplicații și previne tensiunea potențială a serverului dvs.

Termeni utili: pentru a preveni trimiterea prea multor solicitări către un server, dezvoltatorii de aplicații aplică limitatoare de rată aplicațiilor lor. Limitează numărul de apeluri API într-o anumită perioadă, de exemplu, 5000 de apeluri pe minut. Adesea, apelurile care depășesc cota sunt accelerate . Aceasta înseamnă că vor fi servite în cele din urmă (în loc să le scapi cu totul), dar cu o oarecare întârziere.
Până acum, am aflat cum sunt sincronizate datele clienților. Dar înainte ca segmentarea propriu-zisă a clienților să aibă loc, trebuie să înțelegem cum să păstrăm datele consistente în baza ta de date. În partea următoare, vom descrie cum să asigurăm integritatea și securitatea datelor pentru a realiza campanii performante.