
Techniczne aspekty segmentacji klientów – synchronizacja danych
Opublikowany: 2022-04-18„Rozległe doświadczenie w analizie i segmentacji baz danych CRM”, „Dobre zrozumienie segmentacji odbiorców”, „Zrozumienie i doświadczenie segmentacji danych i obsługi spersonalizowanych treści”. To są przykłady najczęstszych wymagań stawianych w ofertach pracy CRM/lifecycle marketing. Chociaż koncepcja segmentacji klientów jest dość prosta i łatwa do rozpoczęcia, bycie profesjonalistą w segmentacji wymaga zagłębienia się w szczegóły techniczne. W tym artykule chcemy pomóc Ci wykonać ten krok.
Spis treści:
- Złożoność przechowywania i formatowania
- Formaty danych
- Częstotliwość synchronizacji
- Nośnik synchronizacji danych
- Pierwszy świat API
- Wyzwalacze synchronizacji danych
Segmentacja klientów rozpoczyna się od zebrania danych o klientach w jednym, centralnym miejscu i przygotowania ich do grupowania i działania. Brzmi łatwo, ale rosnąca liczba źródeł danych komplikuje zbieranie i przetwarzanie danych.
Dlatego efektywna segmentacja zaczyna się od zapewnienia spójnego przepływu danych z kilku źródeł danych do jednego serwera. Ten proces zyskał nazwę, o której być może ostatnio słyszałeś — synchronizacja danych lub po prostu synchronizacja danych . Jest to proces ustalania spójności między systemami i kolejnych ciągłych aktualizacji w celu zachowania jednolitości.
Wiele sprytnych słów oznacza, że to przede wszystkim domena zespołu inżynierów. Ale zaznajomienie się z kluczowymi pojęciami bardzo pomaga. Oto przegląd:
- Synchronizacja danych — w tej sekcji dowiemy się, jak przechowywane są dane klientów, dlaczego ludzie chcą je przenosić i jakie przeszkody muszą pokonać cyfrowe zespoły, aby to zrobić. Z bardziej praktycznego punktu widzenia, ten rozdział wyjaśnia wewnętrzną część tego, jak współczesne systemy CRM wymieniają dane przez Internet za pomocą interfejsów API.
- Integralność i bezpieczeństwo danych — kolejna część pomoże Ci zrozumieć, jak utrzymać dane w spójnym stanie po ich zsynchronizowaniu. Dowiemy się, jak za pomocą schematu zadbać o unikalność danych i zapobiec ich duplikacji. Na koniec zastanowimy się nad technicznymi aspektami bezpieczeństwa danych i prywatności, ponieważ stali się obywatelami pierwszej klasy w czasach po RODO i CCPA.
- Analiza danych — na koniec pomożemy Ci osiągnąć biegłość, pokazując kilka wskazówek dotyczących filtrowania danych i podejmowania ogólnych decyzji na podstawie danych.
Złożoność przechowywania i formatowania
Ze względu na niedawny rozwój technologii spadł koszt przechowywania danych. Umożliwiło to przedsiębiorstwom gromadzenie ogromnych ilości danych.
Dane te można podzielić na dwie kategorie: ustrukturyzowane i nieustrukturyzowane . Aby segmentacja działała, zespoły cyfrowe muszą dowiedzieć się, jak przejść od niestrukturalnego do strukturalnego.
Przez uporządkowane magazyny danych rozumiemy głównie bazy danych SQL lub pliki Excel . Są świetnymi i wszechstronnymi narzędziami, ale mają też swoje wady. SQL jest trudny do nauczenia dla osób bez przygotowania technicznego, największa zaleta Excela, elastyczność, staje się koszmarem dla długoterminowego utrzymania integralności danych. Dlatego te uniwersalne narzędzia programowe zostały zastąpione bardziej ukierunkowanymi narzędziami, takimi jak CRM, CMS, ERP lub narzędzia analityczne.
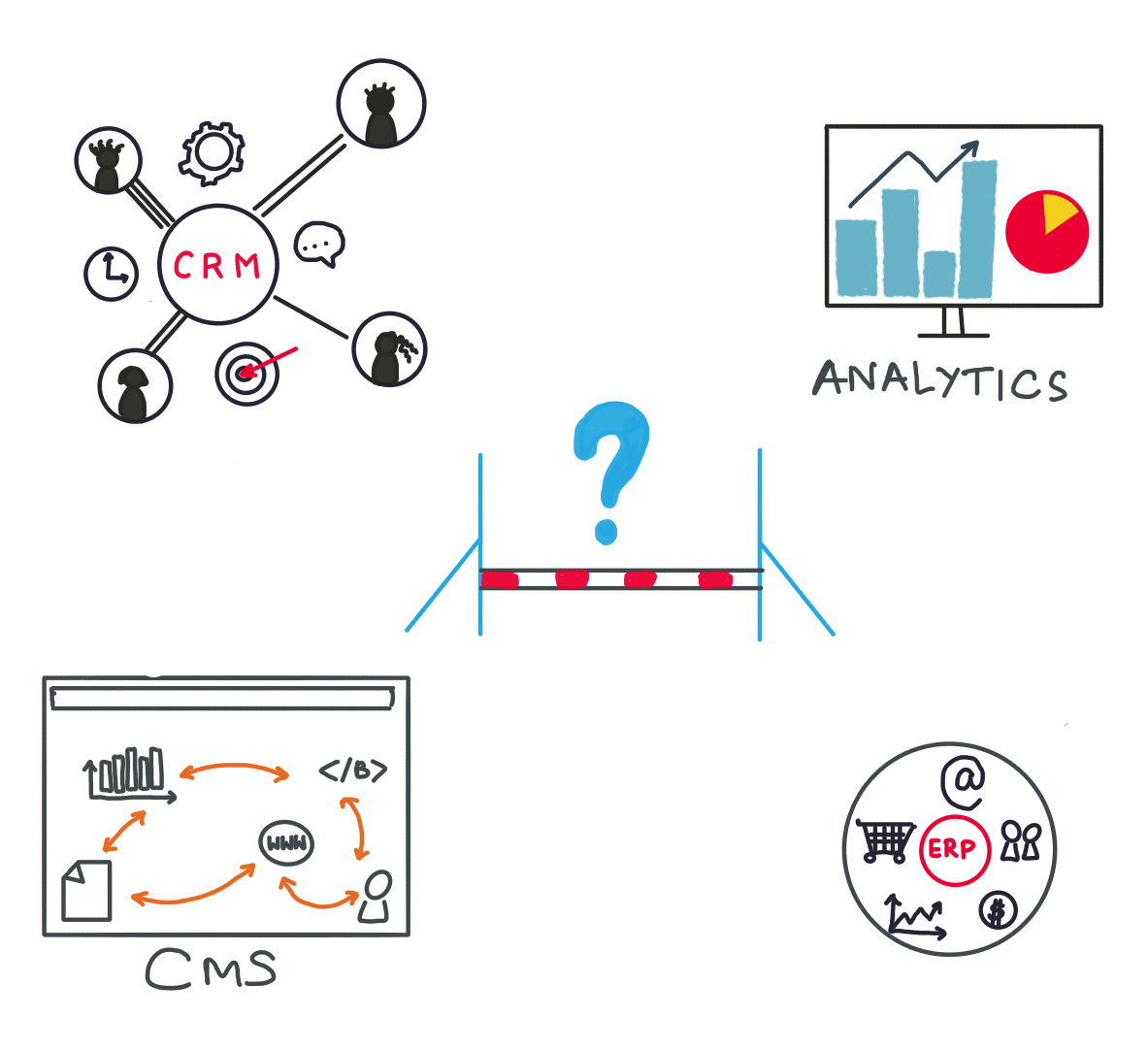
Chociaż te narzędzia zorientowane na pracę zwiększają produktywność w obszarach, do których są zatrudnieni, często stają się problemem na poziomie działu/firmy. Dlaczego tak jest? Każde z tych narzędzi zwykle używa własnego formatu danych i o ile obie platformy oprogramowania nie są ze sobą zintegrowane, wymiana danych jest utrudniona. A współczesny marketer używa cholernie wielu takich narzędzi.
Dlatego większość procesów synchronizacji danych wymaga pośrednika . Przystosowuje format danych generowany przez oprogramowanie autorskie (zwany „źródłem” w świecie IT) do formatu docelowego („docelowego”). Proces takiej adaptacji nazywa się ETL. Jest to skrót od Extract (dane ze źródła), Transform (w sposób rozpoznawany i akceptowany przez cel), Load (do celu z zachowaniem spójności danych).
Jakie formaty danych można spotkać w branży segmentacji klientów?
Formaty danych
Obecnie oprogramowanie do segmentacji w większości przypadków wykorzystuje dwa otwarte formaty do celów synchronizacji danych. Ale czym właściwie jest „format danych”? To nic innego jak tekst skonstruowany w sposób zrozumiały dla komputerów. Zacznijmy od pierwszego, prostszego.
CSV — wartości oddzielone przecinkami. Wyobraź sobie, że zajmujesz stolik. Zwykła tabela z MS Word jest w porządku. Teraz usuńmy granice zewnętrzne, a wewnętrzne zastąpmy przecinkami. Voila, właśnie utworzyłeś plik CSV.
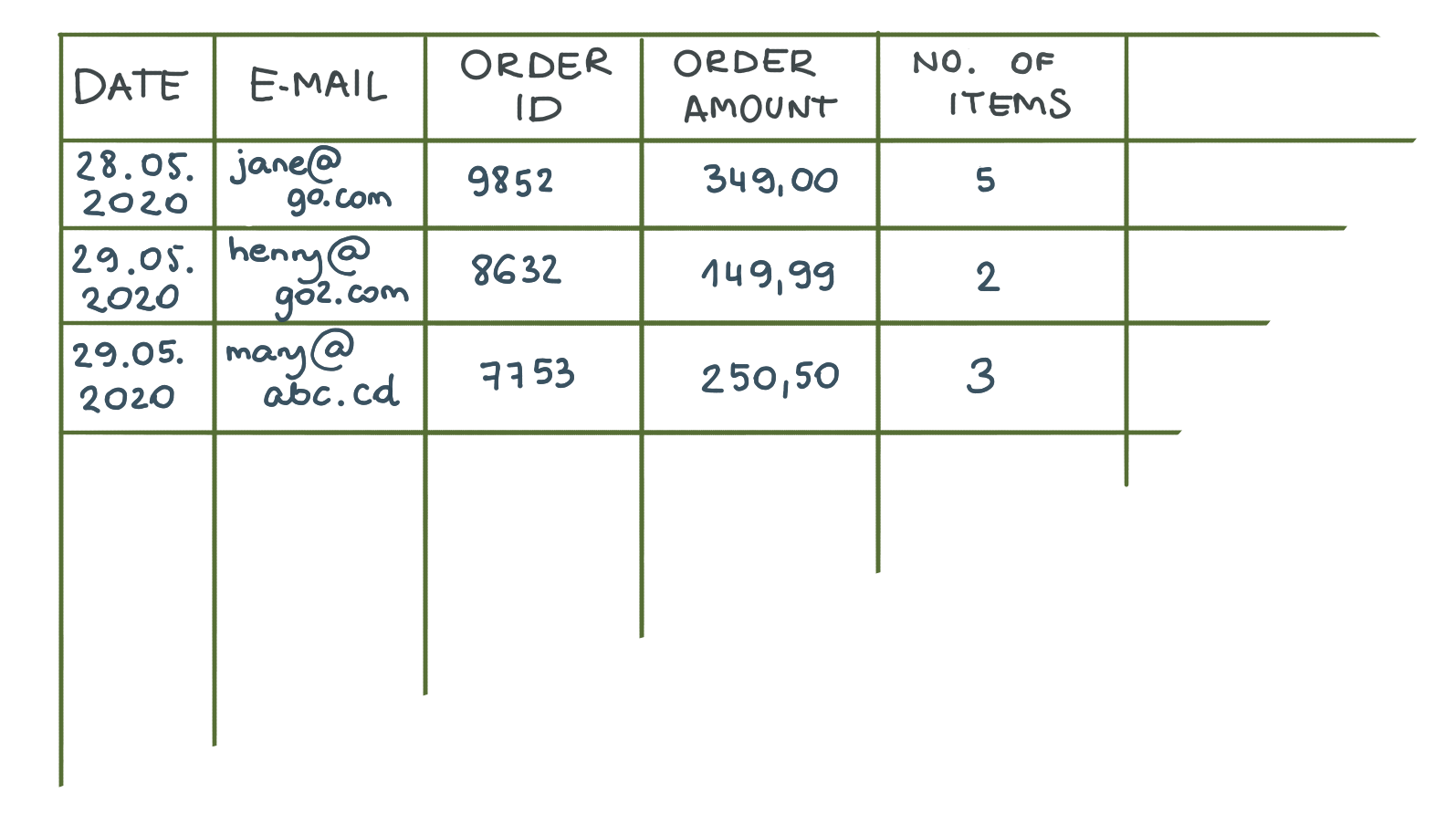
Największa zaleta? Prostota i zwartość. Programiści mogą łatwo eksportować dane w tym formacie, ponieważ bazy danych SQL i Excel przechowują dane w tabelach.
Z drugiej strony CSV ma dwie główne wady. Po pierwsze, w pliku CSV nie można reprezentować hierarchii. Na przykład nie można pokazać, że jedna wartość jest powiązana z inną. Drugą najważniejszą wadą jest to, że CSV jest stałym formatem. Pozwala na wymianę danych zgodnie z dokładną liczbą i typem kolumn, które zdefiniowałeś na początku. Jeśli dodasz kolumnę niezbędną dla innego systemu docelowego lub po prostu usuniesz kolumnę, spowoduje to błąd podczas próby importu. W takim przypadku programiści będą musieli dostosować kod, aby odzwierciedlić zmiany strukturalne.
Ze względu na dynamikę, jaką technologia marketingowa zyskała w ostatnich latach, ograniczenie to okazało się poważną przeszkodą.
Z tego powodu nowoczesne systemy zaczęły wymieniać dane z danymi XML i JSON . Oba są oparte na tej samej koncepcji reprezentacji danych. Opiszemy to drugie, ponieważ jest bardziej popularne.

To jest przykład pliku JSON. Kiedy porównamy nasz plik JSON z odpowiednikiem CSV, od razu dostrzeżemy podobieństwa — widzimy, że ten plik przechowuje dokładnie te same dane.
Uderzająca różnica polega na tym, że nazwy kolumn z plików CSV są powtarzane. Chociaż może się to wydawać zbędne i utrudniać czytelność dla ludzi, to właśnie powtarzalność zapewnia elastyczność JSON – sprawia, że kolejność elementów jest nieistotna. Jest to przydatne, jeśli chcesz dodać nową właściwość (kolumnę) do wymienianego pliku. Oprogramowanie docelowe, które oczekuje nowej właściwości, zużyje ją, podczas gdy cele, które przetworzyły plik przed dodaniem kolumny, zignorują nową właściwość i będą działać bez zakłóceń.
Ta funkcja gwarantuje, że jeśli dodasz więcej pól do formatu danych przesyłanych przez aplikację źródłową, nie spowoduje to naruszenia celu. Dlatego mówi się, że format JSON jest bardziej skalowalny i bardziej elastyczny niż CSV .
Możesz przeczytać więcej o plikach JSON tutaj.
Częstotliwość synchronizacji
Obecnie powszechnym wymogiem jest, aby systemy e-commerce działały w czasie rzeczywistym . Klienci chcą zobaczyć, jaki jest status ich zamówienia, śledzenie przesyłki w czasie rzeczywistym lub jakie jest aktualne saldo na ich koncie. Ponadto marketerzy chcą szybko reagować, chcą prowadzić kampanie w czasie rzeczywistym, które zapewniają terminowe doświadczenia zakupowe.
Aby to osiągnąć, w bazowych magazynach danych zastosowano synchronizację w czasie rzeczywistym .
Istnieją jednak dwa wyzwania związane z synchronizacją w czasie rzeczywistym, o których należy pamiętać.
Po pierwsze, ogólna zasada — im więcej terminowości chcesz uzyskać, tym więcej to kosztuje . Koszt ten przejawia się w czasie programistów, ale także w sprzęcie, który obsługuje serwery (dziś są to głównie rozwiązania chmurowe), który jest potrzebny do utrzymania systemów synchronizacji danych w stanie gotowości. Tak więc Twoim pierwszym zadaniem przed określeniem wymogu „czasu rzeczywistego” podczas rozmowy z inżynierami jest zastanowienie się, jakiej częstotliwości synchronizacji danych naprawdę potrzebujesz. Być może aktualizacje wysyłane raz na godzinę lub raz dziennie wystarczą, aby zapewnić klientom świetne wrażenia przy jednoczesnym ograniczeniu pracy programistów i oszczędności budżetu.

Drugim wyzwaniem są możliwości ekstrakcji danych z magazynów danych, z którymi pracujesz. Czasami synchronizacja w czasie rzeczywistym może być utrudniona, gdy jeden z systemów nie zapewnia łatwego sposobu na wyodrębnienie danych. Łatwy, czyli przyjazny programistom. Przeanalizujmy szczegółowo ten problem, analizując, w jaki sposób programiści przenoszą dane w systemach.
Nośnik synchronizacji danych
Dowiedzieliśmy się, w jaki sposób dane są przechowywane, jakie formaty są używane do wymiany i jak częstotliwość synchronizacji może wpłynąć na wysiłki związane z konfiguracją całego systemu synchronizacji. Ale czego właściwie potrzeba, aby przenieść dane z jednej bazy danych do drugiej? Cóż, potrzebujesz medium.
Może to być fizyczna pamięć masowa, taka jak DVD, dysk USB lub inna synchronizacja sprzętowa, ale przy ogromnych ilościach danych i wymaganiach synchronizacji w czasie rzeczywistym niewiele osób robi to dzisiaj w ten sposób. W większości przypadków wszystko odbywa się za pomocą kabla, a właściwie wielu kabli połączonych ze sobą przez komputery na całym świecie — zwane Internetem.
Mówiąc bardziej konkretnie, nowoczesne platformy oprogramowania wykorzystują protokół przesyłania hipertekstu (HTTP), który jest podstawą sieci WWW.
Jeśli interesuje Cię (i lepiej!) sposób, w jaki serwery komunikują się ze sobą przez Internet, zdecydowanie zalecamy zapoznanie się z tym nietechnicznym przewodnikiem po serwerach.

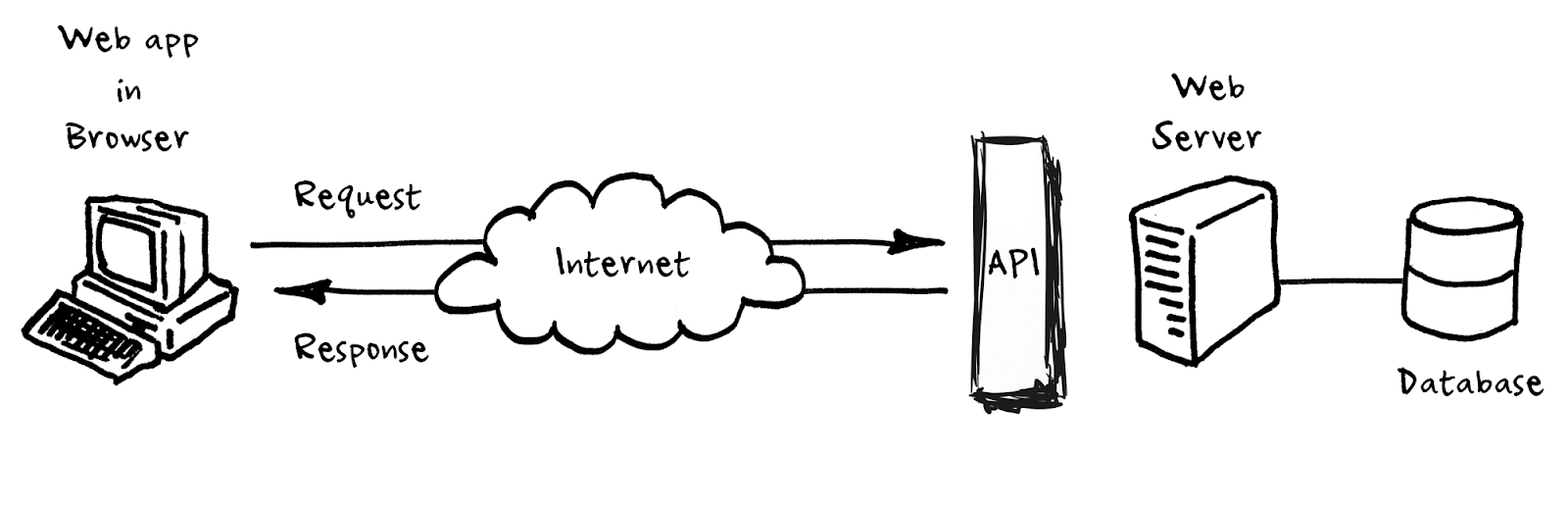
Krótko mówiąc, protokół HTTP można traktować jak wytyczne informujące programistów, w jaki sposób przesyłają dane przez Internet. Oprócz protokołu HTTP programiści tworzą interfejsy programowania aplikacji (API) , które są konkretnymi opisami, jakie dane i w jakiej kolejności mogą być wymieniane między dwoma systemami.
Oprogramowanie, które udostępnia API w Internecie i udostępnia je innym systemom (podobnie jak odwiedzasz zwykłą stronę internetową), nazywamy serwerem aplikacji. Wszystko, co robi, to nasłuchiwanie i odpowiadanie na żądania przychodzące z innych serwerów aplikacji i, w zależności od żądania, dodaje lub pobiera informacje z bazowej bazy danych. Przydatne informacje: kiedy ludzie wspominają o API, często jest to skrót do serwera aplikacji, który udostępnia API w Internecie.
Pobawmy się zatem z API.
Pierwszy świat API
Interfejsy API stały się lingua franca współczesnego marketingu cyfrowego. Większość dzisiejszych prac związanych z synchronizacją danych polega na uczeniu się interfejsu API, aby móc z niego wyodrębniać dane. To jak nauka kolejnego zestawu słów z obcego języka, zakładając, że znasz gramatykę, która w tym przypadku jest zdefiniowana przez HTTP.
Chociaż jest to praca programisty, zagłębienie się w ten temat może pomóc w poruszaniu się po świecie technologii marketingowych.
Stworzyliśmy dedykowany artykuł z kilkoma praktycznymi przykładami zrozumienia interfejsów API, więc jeśli chcesz go opanować (i znowu powinieneś), przeczytaj go tutaj .
Oto najważniejszy fragment z niego:
„Jeśli idziesz do restauracji jako klient, nie możesz wejść do kuchni. Musisz wiedzieć, co jest dostępne. Do tego masz menu. Po obejrzeniu menu składasz zamówienie do kelnera, który przekazuje je do kuchni, a następnie dostarcza to, o co prosiłeś. Kelner może dostarczyć tylko to, co może zapewnić kuchnia.
Jak to się ma do API? Kelner to API. Jesteś kimś, kto prosi o usługi. Innymi słowy, jesteś klientem lub konsumentem API. Menu to dokumentacja wyjaśniająca, o co można poprosić w interfejsie API. Kuchnia to na przykład serwer; baza danych, która zawiera tylko pewien rodzaj danych — cokolwiek kupujący kupił dla restauracji jako składniki i co szef kuchni zdecydował, że zaoferuje, i co kucharze wiedzą, jak przygotować”.
- Kuchnia – Baza danych, brak klientów pozwoliło na ochronę integralności danych.
- Kelner – API, pośrednik, który wie, jak obsłużyć dane z bazy danych bez zakłócania jej funkcjonowania.
- Klient – Zewnętrzny system, który chce uzyskać ich dane.
- Menu — format danych odnosi się do systemów zewnętrznych, których muszą używać do wykonywania swoich operacji.
- Order — rzeczywiste pojedyncze wywołanie interfejsu API.
Wracając do synchronizacji, pozostaje pytanie, w jakich warunkach dwa systemy powinny wymieniać dane.
Wyzwalacze synchronizacji danych
Załóżmy, że mamy dwa serwery aplikacji gotowe do wymiany informacji. Mówiąc dokładniej, wyobraźmy sobie, że dostawca usług poczty e-mail ( ESP ) chce poznać liczbę zamówień klientów (sklep internetowy), aby wysłać im kupon promocyjny po dziesiątym zamówieniu. Jaki przepływ danych możemy wdrożyć, aby osiągnąć ten scenariusz? Możemy wyróżnić trzy „wyzwalacze”, które mogą uruchomić maszynę kuponów e-mail po stronie ESP.
a) Odpytywanie danych – w tym przypadku ESP wielokrotnie pyta API sklepu internetowego: „Daj mi znać całkowitą kwotę zamówienia dla Jane Doe”. Robi to co minutę, godzinę, dzień itp. Kiedy ESP otrzyma informacje, przeliczy warunki wysłania kuponu przy każdym żądaniu API. Twoje przeczucie jest słuszne, jeśli uważasz, że dzwonienie i przetwarzanie danych w ten sposób może być nieoptymalne. Jaka jest alternatywa?

b) Popychanie danych – co by było, gdyby e-sklep mógł powiadomić aplikację ESP w momencie, gdy Jane złożyła 10 zamówienia? Zgadza się. Nowoczesne platformy e-commerce zdały sobie sprawę z tych niedociągnięć i włączyły takie powiadomienia do swojego zestawu funkcji. Są one zwykle nazywane webhookami lub wywołaniami. To prosta, ale potężna funkcjonalność. Pozwala zdefiniować, kiedy i które aplikacje powinny być zgłaszane w określonych warunkach. Możesz również określić, jakie informacje ma zawierać powiadomienie — czasami sensowne jest przesłanie pełnej informacji, ale często wystarczy tylko zmieniona właściwość.

c) Przetwarzanie wsadowe – czasami liczba żądań jest tak duża, że żadna z tych dwóch metod nie jest uzasadniona. Ilość mocy obliczeniowej niezbędnej do obsługi obciążenia zaszkodziłaby jednej (lub nawet obu) ze stron. W tym przypadku programiści grupują wszystkie informacje w „partiach” i planują wymianę danych w nocy lub, bardziej ogólnie, gdy serwery nie są zajęte codziennym ruchem. Pomaga to kontrolować ruch do aplikacji i zapobiega potencjalnemu obciążeniu serwera.

Przydatne terminy: aby zapobiec wysyłaniu zbyt wielu żądań do serwera, twórcy aplikacji stosują w swoich aplikacjach ograniczniki szybkości . Ogranicza liczbę wywołań API w danym okresie np. 5000 wywołań na minutę. Często połączenia przekraczające limit są ograniczane . Oznacza to, że zostaną one w końcu obsłużone (zamiast całkowicie je porzucić), ale z pewnym opóźnieniem.
Jak dotąd dowiedzieliśmy się, jak synchronizowane są dane klientów. Zanim jednak nastąpi faktyczna segmentacja klientów, musimy zrozumieć, jak zachować spójność danych w Twojej bazie danych. W następnej części opiszemy, jak zapewnić integralność i bezpieczeństwo danych, aby uzyskać skuteczne kampanie.