
Technische Aspekte der Kundensegmentierung – Datensynchronisation
Veröffentlicht: 2022-04-18„Umfangreiche Erfahrung in der Analyse und Segmentierung von CRM-Datenbanken“, „Ausgeprägtes Verständnis der Zielgruppensegmentierung“, „Verständnis und Erfahrung in der Datensegmentierung und Bereitstellung personalisierter Inhalte.“ Dies sind Beispiele für die häufigsten Anforderungen an Stellenangebote im Bereich CRM/Lifecycle Marketing. Obwohl das Konzept der Kundensegmentierung ziemlich einfach und leicht zu beginnen ist, erfordert es, ein Segmentierungsprofi zu werden, in technische Details einzutauchen. Mit diesem Artikel möchten wir Ihnen helfen, diesen Sprung zu wagen.
Inhaltsverzeichnis:
- Speicher- und Formatkomplexität
- Datenformate
- Synchronisationsfrequenz
- Datensynchronisationsmedium
- API-erste Welt
- Auslöser für die Datensynchronisierung
Die Kundensegmentierung beginnt damit, Kundendaten an einem zentralen Ort zu sammeln und sie für die Gruppierung und Bearbeitung vorzubereiten. Klingt einfach, aber eine zunehmende Anzahl von Datenquellen erhöht die Komplexität beim Sammeln und Verarbeiten von Daten.
Aus diesem Grund beginnt eine effiziente Segmentierung mit der Sicherstellung eines konsistenten Datenflusses von mehreren Datenquellen zu einem einzigen Server. Dieser Prozess hat sich einen Namen verdient, den Sie in letzter Zeit vielleicht schon oft gehört haben – Datensynchronisierung oder einfach Datensynchronisierung . Es ist ein Prozess zur Herstellung von Konsistenz zwischen Systemen und anschließenden kontinuierlichen Aktualisierungen, um die Einheitlichkeit aufrechtzuerhalten.
Viele kluge Worte bedeuten, dass es in erster Linie die Domäne des Ingenieurteams ist. Aber sich mit Schlüsselkonzepten vertraut zu machen, hilft sehr. Hier eine Übersicht:
- Datensynchronisierung – In diesem Abschnitt erfahren Sie, wie Kundendaten gespeichert werden, warum Menschen sie verschieben möchten und welche Hindernisse digitale Teams dafür überwinden müssen. In praktischer Hinsicht erklärt dieses Kapitel die inneren Bestandteile, wie moderne CRM-Systeme Daten über das Internet mit APIs austauschen.
- Datenintegrität und -sicherheit – der nächste Teil hilft Ihnen zu verstehen, was erforderlich ist, um Daten nach der Synchronisierung in einem konsistenten Zustand zu halten. Wir erfahren, wie Sie mithilfe von Schemas für die Eindeutigkeit von Daten sorgen und Duplikate von Daten verhindern können. Abschließend werden wir über die technischen Aspekte der Datensicherheit und des Datenschutzes nachdenken, da sie in den Zeiten nach der DSGVO und dem CCPA zu erstklassigen Bürgern geworden sind.
- Data Crunching – schließlich helfen wir Ihnen dabei, fließend zu sprechen, indem wir Ihnen einige Tipps zur Datenfilterung und zum Treffen datengesteuerter Entscheidungen im Allgemeinen zeigen.
Speicher- und Formatkomplexität
Aufgrund der jüngsten technologischen Entwicklungen sind die Kosten für die Datenspeicherung gesunken. Dadurch konnten Unternehmen enorme Datenmengen sammeln.
Diese Daten können in zwei Kategorien unterteilt werden: strukturierte und unstrukturierte . Damit die Segmentierung funktioniert, müssen digitale Teams herausfinden, wie sie von unstrukturiert zu strukturiert wechseln können.
Unter strukturierter Datenhaltung verstehen wir meist SQL-Datenbanken oder Excel-Dateien . Sie sind großartige und vielseitige Werkzeuge, haben aber auch ihre Nachteile. SQL ist für Menschen ohne technischen Hintergrund schwer zu erlernen, der größte Vorteil von Excel, die Flexibilität, wird zu einem Albtraum für die langfristige Aufrechterhaltung der Datenintegrität. Aus diesem Grund wurden diese Allzweck-Softwaretools durch fokussiertere Tools wie CRM-, CMS-, ERP- oder Analysetools überbaut.
Obwohl diese berufsorientierten Tools die Produktivität in den Bereichen steigern, für die sie eingestellt werden, werden sie auf Abteilungs-/Unternehmensebene oft zu einem Problem. Warum ist das? Jedes dieser Tools verwendet in der Regel ein eigenes Datenformat und wenn beide Softwareplattformen nicht miteinander integriert sind, wird der Datenaustausch behindert. Und ein moderner Vermarkter verwendet verdammt viele solcher Tools.
Aus diesem Grund erfordern die meisten Datensynchronisierungsprozesse einen Mittelsmann . Es passt das von der Autorensoftware erzeugte Datenformat (in der IT-Welt „Quelle“ genannt) an das Zielformat („Ziel“) an. Der Prozess einer solchen Anpassung wird ETL genannt. Es ist eine Abkürzung für Extract (Daten aus der Quelle), Transform (in einer Weise, die vom Ziel erkannt und akzeptiert wird), Load (es zum Ziel, wobei die Datenkonsistenz beibehalten wird).
Welche Art von Datenformaten können Sie in der Kundensegmentierungsbranche treffen?
Datenformate
Heutzutage verwendet Segmentierungssoftware in den meisten Fällen zwei offene Formate für Datensynchronisierungszwecke. Aber was ist überhaupt das „Datenformat“? Das ist nichts anderes als ein Text, der für Computer verständlich aufgebaut ist. Beginnen wir mit dem ersten, einfacheren.
CSV – Kommagetrennte Werte. Stellen Sie sich vor, Sie nehmen einen Tisch. Eine Stammtabelle aus MS Word reicht vollkommen aus. Lassen Sie uns nun die äußeren Grenzen entfernen und die inneren durch Kommas ersetzen. Voila, Sie haben gerade eine CSV-Datei erstellt.
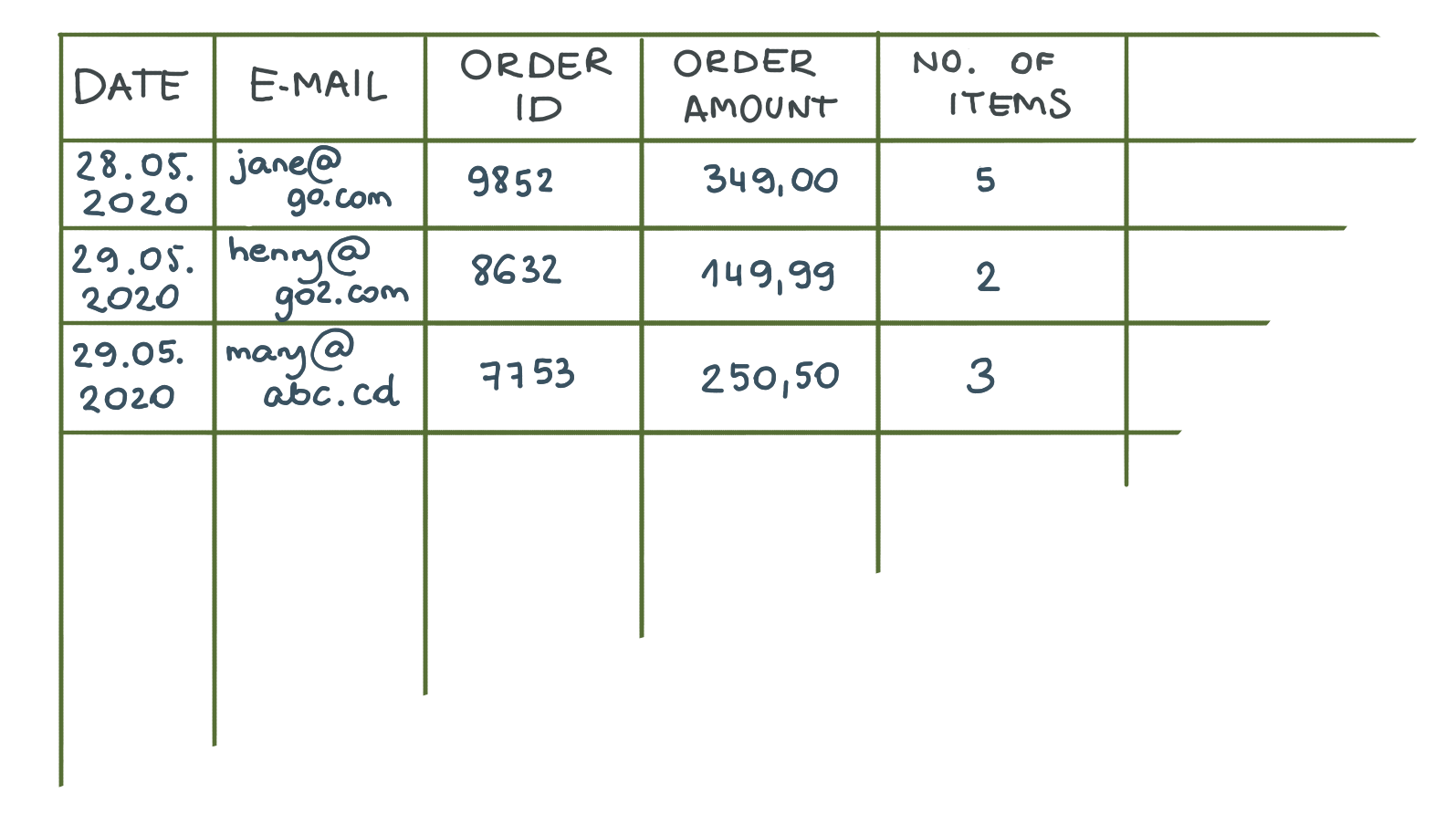
Der größte Vorteil? Einfachheit und Kompaktheit. Entwickler können Daten in diesem Format problemlos exportieren, da SQL- und Excel-Datenbanken Daten in Tabellen speichern.
Auf der anderen Seite hat CSV zwei große Mängel. Erstens können Sie innerhalb einer CSV-Datei keine Hierarchie darstellen. Sie können beispielsweise nicht zeigen, dass ein Wert mit einem anderen zusammenhängt. Der zweitwichtigste Nachteil ist, dass CSV ein festes Format ist. Es ermöglicht Ihnen, Daten gemäß der genauen Anzahl und Art der Spalten auszutauschen, die Sie zu Beginn definiert haben. Wenn Sie eine Spalte hinzufügen, die für ein anderes Zielsystem erforderlich ist, oder einfach eine Spalte entfernen, führt dies zu einem Fehler beim Importversuch. In einem solchen Fall müssen Entwickler den Code anpassen, um die strukturellen Änderungen widerzuspiegeln.
Aufgrund der Dynamik, die die Marketingtechnologie in den letzten Jahren gewonnen hat, stellte sich diese Einschränkung als großes Hindernis heraus.
Aus diesem Grund begannen moderne Systeme, Daten mit XML- und JSON -Daten auszutauschen. Beide basieren auf dem gleichen Konzept der Datenrepräsentation. Wir beschreiben letzteres, weil es beliebter ist.

Dies ist ein Beispiel für eine JSON-Datei. Wenn wir unsere JSON-Datei mit dem CSV-Gegenstück vergleichen, werden wir sofort Ähnlichkeiten feststellen – wir können sehen, dass diese Datei genau die gleichen Daten speichert.
Der markante Unterschied besteht darin, dass die Spaltennamen aus CSV-Dateien wiederholt werden. Während dies überflüssig erscheinen mag und die Lesbarkeit für Menschen beeinträchtigt, ist es die Wiederholung, die JSON Flexibilität verleiht – sie macht die Reihenfolge der Elemente irrelevant. Dies ist hilfreich, wenn Sie einer ausgetauschten Datei eine neue Eigenschaft (eine Spalte) hinzufügen müssen. Die Zielsoftware, die die neue Eigenschaft erwartet, wird sie verbrauchen, während die Ziele, die die Datei vor dem Hinzufügen der Spalte verarbeitet haben, die neue Eigenschaft ignorieren und ungestört arbeiten werden.
Diese Funktion garantiert, dass das Ziel nicht beschädigt wird, wenn Sie dem von der Quellanwendung gesendeten Datenformat weitere Felder hinzufügen. Aus diesem Grund gilt das JSON-Format als skalierbarer und flexibler als CSV .
Hier können Sie mehr über JSON-Dateien lesen.
Synchronisationsfrequenz
Die heute übliche Anforderung ist, dass die E-Commerce -Systeme in Echtzeit arbeiten . Kunden möchten den Status ihrer Bestellung, eine Echtzeit-Paketverfolgung oder den aktuellen Kontostand sehen. Außerdem möchten Vermarkter schnell reagieren, sie möchten Echtzeit-Kampagnen durchführen, die zeitnahe Einkaufserlebnisse schaffen.
Um dies zu erreichen, haben die zugrunde liegenden Datenspeicher eine Echtzeitsynchronisierung eingeführt.
Es gibt jedoch zwei Herausforderungen bei der Echtzeitsynchronisierung, die beachtet werden müssen.
Zunächst eine allgemeine Faustregel: Je mehr Echtzeit Sie erreichen möchten, desto mehr kostet es . Diese Kosten manifestieren sich in der Zeit der Entwickler, aber auch in der Hardware, auf der Server ausgeführt werden (heute sind es meist Cloud-Lösungen), die Sie benötigen, um die Datensynchronisierungssysteme am Laufen zu halten. Ihre allererste Aufgabe, bevor Sie im Gespräch mit Ingenieuren eine „Echtzeit“-Anforderung stellen, besteht also darin, zu überlegen, welche Art von Datensynchronisierungsfrequenz Sie wirklich benötigen. Vielleicht reichen Updates, die einmal pro Stunde oder einmal am Tag gesendet werden, aus, um ein großartiges Kundenerlebnis zu gewährleisten und gleichzeitig die Arbeit der Entwickler zu reduzieren und Budget zu sparen.

Die andere Herausforderung sind die Datenextraktionsfunktionen der Datenspeicher, mit denen Sie arbeiten. Manchmal kann die Echtzeitsynchronisierung behindert werden, wenn eines der Systeme keine einfache Möglichkeit bietet, Daten zu extrahieren. Einfach bedeutet entwicklerfreundlich. Lassen Sie uns dieses Problem im Detail analysieren, indem wir durchgehen, wie Entwickler Daten in Systemen verschieben.
Datensynchronisationsmedium
Wir haben gelernt, wie die Daten gespeichert werden, welche Formate für den Austausch verwendet werden und wie sich die Synchronisierungshäufigkeit auf den Aufwand für die Einrichtung des gesamten Synchronisierungssystems auswirken kann. Aber was braucht es eigentlich, um Daten von einer Datenbank in die andere zu übertragen? Nun, Sie brauchen ein Medium.
Es kann ein physischer Speicher wie DVD, USB-Laufwerk oder eine andere Hardware-basierte Synchronisierung sein, aber angesichts der riesigen Datenmengen und der Echtzeit-Synchronisierungsanforderungen tun dies heute nur noch wenige auf diese Weise. In den meisten Fällen geschieht dies alles über Kabel oder tatsächlich über viele Kabel, die durch Computer auf der ganzen Welt miteinander verbunden sind – das sogenannte Internet.
Genauer gesagt verwenden moderne Softwareplattformen das Hypertext Transfer Protocol (HTTP), das die Grundlage des World Wide Web darstellt.
Wenn Sie daran interessiert sind (und das sollten Sie besser!), wie Server über das Internet miteinander kommunizieren, empfehlen wir Ihnen dringend, sich diesen Server-Leitfaden für Nicht-Techniker anzusehen.

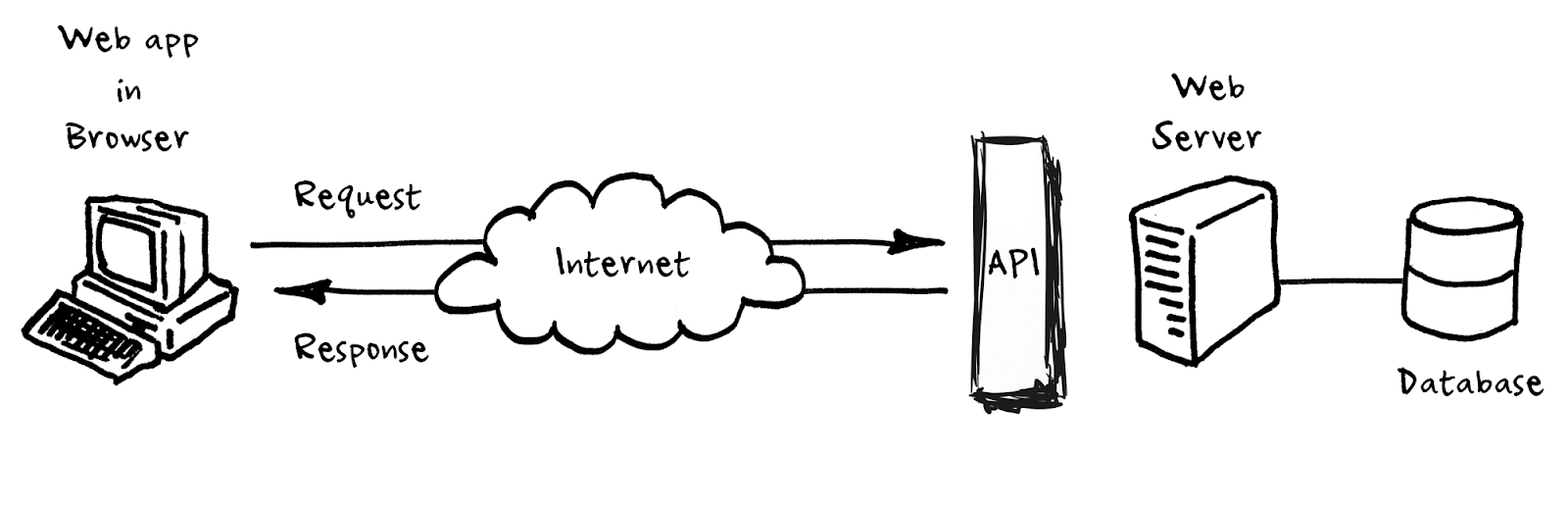
Kurz gesagt, Sie können das HTTP-Protokoll wie Richtlinien behandeln, die Entwicklern mitteilen, wie sie Daten über das Internet senden. Zusätzlich zu HTTP erstellen Entwickler Application Programming Interfaces (APIs) , bei denen es sich um spezifische Beschreibungen darüber handelt, welche Daten und in welcher Reihenfolge zwischen zwei Systemen ausgetauscht werden können.
Die Software, die eine API im Internet verfügbar macht und von anderen Systemen zugänglich macht (ähnlich wie Sie eine normale Webseite besuchen), wird als Anwendungsserver bezeichnet. Es lauscht lediglich Anfragen, die von anderen Anwendungsservern eingehen, und antwortet auf Anfragen, und abhängig von der Anfrage fügt es Informationen aus der zugrunde liegenden Datenbank hinzu oder ruft sie ab. Nützliche Informationen: Wenn von API die Rede ist, handelt es sich oft um eine Abkürzung für den Anwendungsserver, der die API dem Internet zugänglich macht.
Lassen Sie uns dann mit den APIs spielen.
API-erste Welt
APIs sind zu einer Lingua Franca des heutigen digitalen Marketings geworden. Der größte Teil der Datensynchronisierungsarbeit besteht heute darin, eine API zu lernen, um Daten daraus extrahieren zu können. Es ist, als würde man einen weiteren Satz Wörter aus einer Fremdsprache lernen, vorausgesetzt, Sie kennen die Grammatik, die in diesem Fall durch HTTP definiert wird.
Obwohl es die Aufgabe eines Entwicklers ist, kann Ihnen das Eintauchen in dieses Thema helfen, sich in der Welt der Marketingtechnologie zurechtzufinden.
Wir haben einen speziellen Artikel mit einigen praktischen Beispielen zum Verständnis von APIs erstellt. Wenn Sie es also beherrschen möchten (und auch hier sollten Sie es tun), lesen Sie es hier .
Das ist der wichtigste Auszug daraus:
„Wenn Sie als Kunde in ein Restaurant gehen, dürfen Sie die Küche nicht betreten. Sie müssen wissen, was verfügbar ist. Dafür haben Sie das Menü. Nachdem Sie sich die Speisekarte angesehen haben, geben Sie eine Bestellung bei einem Kellner auf, der sie an die Küche weitergibt und der Ihnen dann liefert, was Sie bestellt haben. Der Kellner kann nur liefern, was die Küche hergibt.
Wie hängt das mit einer API zusammen? Der Kellner ist die API. Sie sind jemand, der um Service bittet. Mit anderen Worten, Sie sind ein API-Kunde oder -Verbraucher. Das Menü ist die Dokumentation, die erklärt, was Sie von der API verlangen können. Die Küche ist zum Beispiel ein Server; eine Datenbank, die nur eine bestimmte Art von Daten enthält – was auch immer der Käufer als Zutaten für das Restaurant gekauft hat und was der Küchenchef entschieden hat, es anzubieten, und was die Köche zuzubereiten wissen.“
- Küche – Die Datenbank, keine Kunden dürfen die Datenintegrität schützen.
- Kellner – Die API, ein Mittelsmann, der weiß, wie man Daten aus der Datenbank bereitstellt, ohne deren Funktion zu stören.
- Kunde – Ein externes System, das seine Daten abrufen möchte.
- Menü – Die Datenformatreferenz, die die externen Systeme verwenden müssen, um ihren Betrieb auszuführen.
- Bestellung – Ein tatsächlicher einzelner API-Aufruf.
Zurück zur Synchronisation, die verbleibende Frage ist nun herauszufinden, unter welchen Bedingungen zwei Systeme Daten austauschen sollten.
Auslöser für die Datensynchronisierung
Nehmen wir an, wir haben zwei Anwendungsserver, die bereit sind, Informationen auszutauschen. Um genauer zu sein, stellen wir uns vor, Ihr E-Mail-Dienstleister ( ESP ) möchte die Anzahl der Kundenbestellungen (E-Shop) wissen, um ihm nach der zehnten Bestellung einen Aktionsgutschein zuzusenden. Welche Art von Datenfluss können wir nun implementieren, um dieses Szenario zu erreichen? Wir können drei „Auslöser“ unterscheiden, die die E-Mail-Coupon-Maschinerie auf der ESP-Seite starten können.
a) Datenabfrage – in diesem Fall fragt ESP die E-Shop-API wiederholt: „Teilen Sie mir die Gesamtbestellsumme für Jane Doe mit“. Dies geschieht jede Minute, jede Stunde oder jeden Tag usw. Wenn ESP die Informationen erhält, berechnet es die Versandbedingungen für Gutscheine bei jeder API-Anforderung neu. Ihr Bauchgefühl hat Recht, wenn Sie denken, dass es suboptimal sein könnte, Daten auf diese Weise abzurufen und zu verarbeiten. Was ist die Alternative?

b) Data Pushing – was wäre, wenn ein E-Shop die ESP-Anwendung in dem Moment benachrichtigen könnte, in dem Jane ihre 10. Bestellung aufgegeben hat? Stimmt. Moderne E-Commerce-Plattformen haben diese Mängel erkannt und solche Benachrichtigungen in ihren Funktionsumfang aufgenommen. Sie werden normalerweise als Webhooks oder Call-Outs bezeichnet. Es ist eine einfache, aber leistungsstarke Funktionalität. Sie können festlegen, wann und welche Anwendungen unter bestimmten Bedingungen benachrichtigt werden sollen. Sie können auch festlegen, welche Art von Informationen eine Benachrichtigung enthalten soll – manchmal ist es sinnvoll, vollständige Informationen zu senden, aber oft reicht nur eine geänderte Eigenschaft aus.

c) Stapelverarbeitung – manchmal ist die Anzahl der Anfragen so groß, dass keine dieser beiden Methoden sinnvoll ist. Die zur Bewältigung der Last erforderliche Menge an Rechenleistung würde einer (oder sogar beiden) der Parteien schaden. In diesem Fall gruppieren die Entwickler alle Informationen in einem „Batch“ und planen den Datenaustausch nachts oder allgemeiner, wenn die Server nicht mit dem täglichen Datenverkehr beschäftigt sind. Dies hilft bei der Kontrolle des Datenverkehrs zu Anwendungen und verhindert eine potenzielle Belastung Ihres Servers.

Nützliche Begriffe: Um zu verhindern, dass zu viele Anfragen an einen Server gesendet werden, wenden Anwendungsentwickler Ratenbegrenzungen auf ihre Anwendungen an. Es begrenzt die Anzahl der API-Aufrufe in einem bestimmten Zeitraum, z. B. 5000 Aufrufe pro Minute. Häufig werden Anrufe, die das Kontingent überschreiten, gedrosselt . Das bedeutet, dass sie schließlich bedient werden (anstatt sie ganz fallen zu lassen), aber mit einer gewissen Verzögerung.
Bisher haben wir gelernt, wie Kundendaten synchronisiert werden. Aber bevor die eigentliche Kundensegmentierung stattfinden kann, müssen wir verstehen, wie Sie die Daten in Ihrer Datenbank konsistent halten. Im nächsten Teil beschreiben wir, wie Sie die Datenintegrität und -sicherheit gewährleisten, um gut funktionierende Kampagnen zu erzielen.