
Aspetti tecnici della segmentazione dei clienti – Sincronizzazione dei dati
Pubblicato: 2022-04-18"Ampia esperienza nell'analisi e nella segmentazione dei database CRM", "Grande conoscenza della segmentazione dell'audience", "Comprensione ed esperienza della segmentazione dei dati e della fornitura di contenuti personalizzati". Questi sono esempi dei requisiti più comuni posti nelle offerte di lavoro di marketing CRM/ciclo di vita. Sebbene il concetto di segmentazione dei clienti sia abbastanza semplice e facile da iniziare, diventare un professionista della segmentazione richiede un'immersione nei dettagli tecnici. Con questo articolo, vogliamo aiutarti a fare questo salto.
Sommario:
- Archiviazione e complessità del formato
- Formati di dati
- Frequenza di sincronizzazione
- Supporto per la sincronizzazione dei dati
- API-primo mondo
- Trigger della sincronizzazione dei dati
La segmentazione dei clienti inizia con la raccolta dei dati dei clienti in un'unica posizione centrale e la loro preparazione per il raggruppamento e l'azione. Sembra facile, ma un numero crescente di origini dati aggiunge complessità alla raccolta e al crunch dei dati.
Ecco perché una segmentazione efficiente inizia assicurando un flusso di dati coerente da diverse origini dati a un unico server. Questo processo si è guadagnato un nome che potresti aver sentito molto di recente: sincronizzazione dei dati o semplicemente sincronizzazione dei dati . È un processo per stabilire la coerenza tra i sistemi e successivi aggiornamenti continui per mantenere l'uniformità.
Molte parole intelligenti significano che è principalmente il dominio del team di ingegneri. Ma familiarizzare con i concetti chiave aiuta molto. Ecco una panoramica:
- Sincronizzazione dei dati: in questa sezione impareremo come vengono archiviati i dati dei clienti, perché le persone vogliono spostarli e quali ostacoli devono superare i team digitali per farlo. In una nota più pratica, questo capitolo spiega le parti interne di come i moderni sistemi CRM scambiano dati su Internet con le API.
- Integrità e sicurezza dei dati: la parte successiva ti aiuterà a capire cosa serve per mantenere i dati in uno stato coerente dopo averli sincronizzati. Impareremo come utilizzare lo schema per occuparci dell'unicità dei dati e prevenire la duplicazione dei dati. Infine, rifletteremo sugli aspetti tecnici della sicurezza e della privacy dei dati poiché sono diventati cittadini di prima classe ai tempi del dopo GDPR e del CCPA.
- Elaborazione dei dati: infine, ti aiuteremo a diventare fluente mostrandoti alcuni suggerimenti sul filtraggio dei dati e prendendo decisioni basate sui dati in generale.
Archiviazione e complessità del formato
A causa dei recenti sviluppi tecnologici, il costo dell'archiviazione dei dati è diminuito. Ciò ha consentito alle aziende di raccogliere enormi quantità di dati.
Questi dati possono essere suddivisi in due categorie: strutturati e non strutturati . Per far funzionare la segmentazione, i team digitali devono capire come passare da non strutturato a strutturato.
Per archivi di dati strutturati intendiamo principalmente database SQL o file Excel . Sono strumenti fantastici e versatili, ma hanno anche i loro contro. SQL è difficile da imparare per le persone senza un background tecnico, il principale vantaggio di Excel, la flessibilità, diventa un incubo per il mantenimento a lungo termine dell'integrità dei dati. Ecco perché questi strumenti software generici sono stati sovrastrutturati con strumenti più mirati come CRM, CMS, ERP o strumenti di analisi.
Sebbene questi strumenti orientati al lavoro aumentino la produttività nelle aree per cui vengono assunti, spesso diventano un problema a livello di reparto/azienda. Perché? Ciascuno di questi strumenti utilizza solitamente un proprio formato di dati e, a meno che entrambe le piattaforme software non siano integrate tra loro, lo scambio di dati è ostacolato. E un marketer moderno usa un sacco di tali strumenti.
Questo è il motivo per cui la maggior parte dei processi di sincronizzazione dei dati richiede un intermediario . Adatta il formato dati generato dal software di authoring (chiamato la “fonte” nel mondo IT) al formato di destinazione (“target”). Il processo di tale adattamento è chiamato ETL. È un'abbreviazione di Estrai (dati dalla fonte), Trasforma (in modo che sia riconosciuto e accettato dalla destinazione), Carica (nella destinazione mantenendo la coerenza dei dati).
Che tipo di formati di dati puoi incontrare nel settore della segmentazione dei clienti?
Formati di dati
Al giorno d'oggi, il software di segmentazione utilizza nella maggior parte dei casi due formati aperti per la sincronizzazione dei dati. Ma qual è il "formato dei dati" comunque? Questo non è altro che un testo strutturato in modo comprensibile per i computer. Cominciamo con il primo, più semplice.
CSV – Valori separati da virgola. Immagina di prendere un tavolo. Una tabella normale di MS Word va bene. Ora rimuoviamo i bordi esterni e sostituiamo quelli interni con le virgole. Voilà, hai appena creato un file CSV.
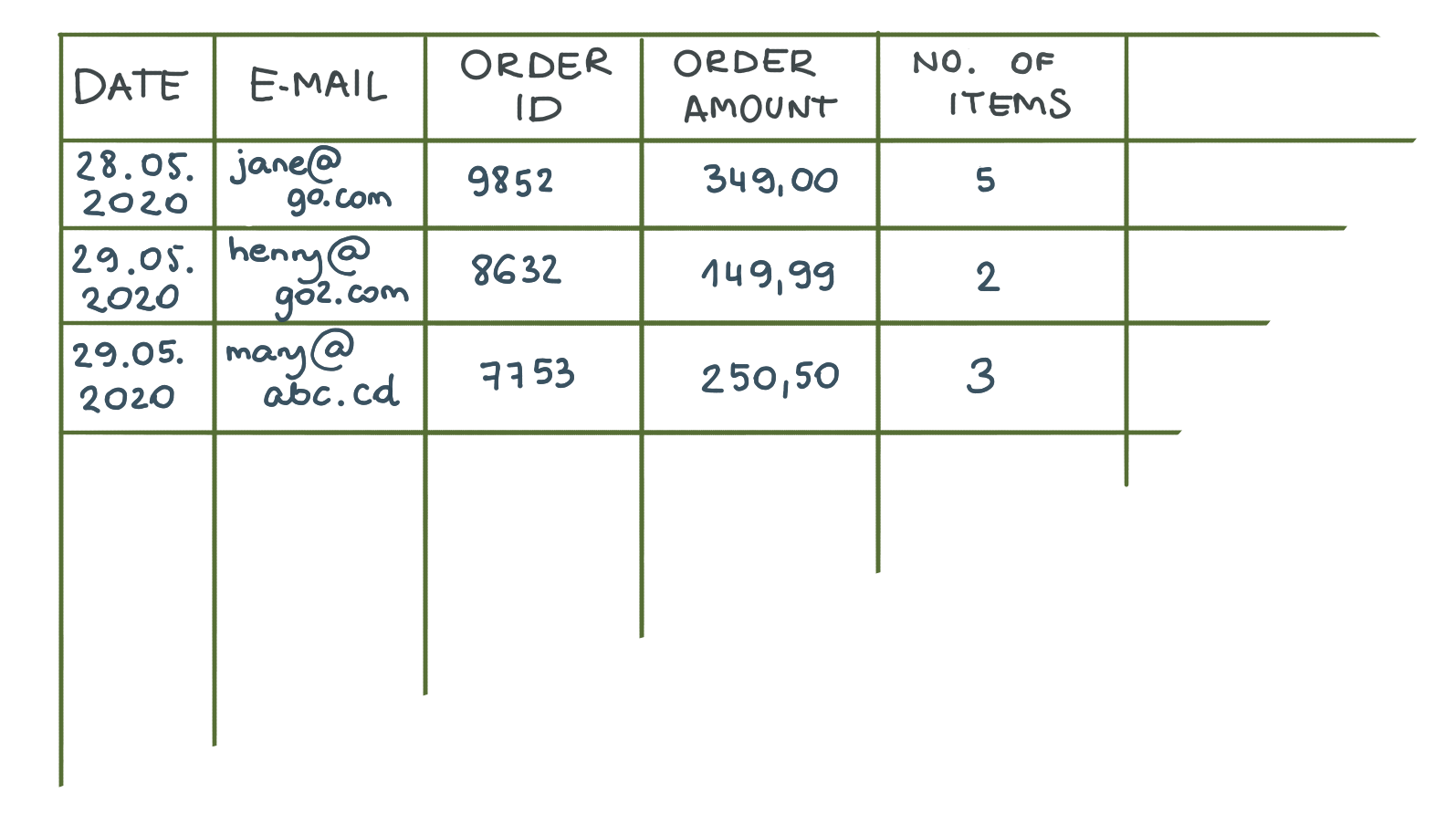
Il vantaggio più grande? Semplicità e compattezza. Gli sviluppatori possono esportare facilmente i dati in questo formato perché i database SQL ed Excel archiviano i dati nelle tabelle.
D'altra parte, CSV ha due grossi difetti. Innanzitutto, all'interno di un file CSV, non puoi rappresentare la gerarchia. Ad esempio, non puoi mostrare che un valore è correlato a un altro. Il secondo inconveniente più importante è che CSV è un formato fisso. Ti consente di scambiare dati in base al numero esatto e al tipo di colonne che hai definito all'inizio. Se si aggiunge una colonna necessaria per un altro sistema di destinazione o si rimuove semplicemente una colonna, si verificherà un errore al tentativo di importazione. In tal caso, gli sviluppatori dovranno modificare il codice per riflettere i cambiamenti strutturali.
A causa delle dinamiche che la tecnologia di marketing ha acquisito negli ultimi anni, questa limitazione si è rivelata un ostacolo importante.
Per questo motivo, i sistemi moderni hanno iniziato a scambiare dati con dati XML e JSON . Entrambi si basano sullo stesso concetto di rappresentazione dei dati. Descriveremo quest'ultimo perché è più popolare.

Questo è un esempio di un file JSON. Quando confrontiamo il nostro file JSON con la controparte CSV, troveremo immediatamente delle somiglianze: possiamo vedere che questo file memorizza esattamente gli stessi dati.
La differenza notevole è che i nomi delle colonne dei file CSV vengono ripetuti. Sebbene ciò possa sembrare ridondante e ostacolare la leggibilità per gli esseri umani, è la ripetizione che offre flessibilità a JSON: rende irrilevante l'ordine degli elementi. Ciò è utile se è necessario aggiungere una nuova proprietà (una colonna) a un file scambiato. Il software di destinazione che prevede la nuova proprietà la consumerà, mentre i target che hanno elaborato il file prima dell'aggiunta della colonna ignoreranno la nuova proprietà e lavoreranno indisturbati.
Questa funzionalità garantisce che se si aggiungono più campi al formato dati inviato dall'applicazione di origine, non si interromperà la destinazione. Questo è il motivo per cui si dice che il formato JSON sia più scalabile e più flessibile di CSV .
Puoi leggere di più sui file JSON qui.
Frequenza di sincronizzazione
Il requisito comune oggi è che i sistemi di e-commerce siano in tempo reale . I clienti vogliono vedere qual è lo stato del loro ordine, un monitoraggio del pacco in tempo reale o qual è il saldo corrente sul loro conto. Inoltre, gli esperti di marketing vogliono reagire rapidamente, vogliono eseguire campagne in tempo reale che creino esperienze di acquisto tempestive.
Per raggiungere questo obiettivo, gli archivi di dati sottostanti hanno adottato la sincronizzazione in tempo reale .
Tuttavia, ci sono due sfide con la sincronizzazione in tempo reale a cui prestare attenzione.
Innanzitutto, una regola generale: maggiore è la tempestività reale che desideri ottenere, maggiore è il costo . Questo costo si manifesta nel tempo degli sviluppatori ma anche con l'hardware che gestisce i server (oggi si tratta principalmente di soluzioni cloud) necessario per mantenere attivi i sistemi di sincronizzazione dei dati. Quindi, il tuo primo compito prima di definire un requisito "in tempo reale" quando parli con gli ingegneri è considerare il tipo di frequenza di sincronizzazione dei dati di cui hai veramente bisogno. Forse, gli aggiornamenti inviati una volta all'ora o una volta al giorno sono sufficienti per garantire un'esperienza cliente eccezionale riducendo il lavoro degli sviluppatori e risparmiando sul budget.

L'altra sfida sono le capacità di estrazione dei dati degli archivi di dati con cui lavori. A volte la sincronizzazione in tempo reale potrebbe essere impedita quando uno dei sistemi non fornisce un modo semplice per estrarre i dati. Facile che significa adatto agli sviluppatori. Analizziamo questo problema in dettaglio esaminando il modo in cui gli sviluppatori spostano i dati nei sistemi.
Supporto per la sincronizzazione dei dati
Abbiamo appreso come vengono archiviati i dati, quali formati vengono utilizzati per lo scambio e in che modo la frequenza di sincronizzazione può influire sugli sforzi di impostazione dell'intero sistema di sincronizzazione. Ma cosa serve effettivamente per trasferire i dati da un database all'altro? Bene, hai bisogno di un mezzo.
Può essere un archivio fisico come DVD, unità USB o altra sincronizzazione basata su hardware, ma con le enormi quantità di dati e i requisiti di sincronizzazione in tempo reale, pochi lo fanno in questo modo oggi. Nella maggior parte dei casi, è tutto fatto via cavo, o in realtà molti cavi interconnessi da computer in tutto il mondo, chiamati Internet.
Per essere più specifici, le moderne piattaforme software utilizzano l'Hypertext Transfer Protocol (HTTP), che è alla base del World Wide Web.
Se sei interessato (e faresti meglio a esserlo!) nel modo in cui i server comunicano tra loro attraverso Internet, ti consigliamo vivamente di passare a questa guida non tecnica ai server.

In poche parole, puoi trattare il protocollo HTTP come linee guida che dicono agli sviluppatori come inviano i dati su Internet. Oltre a HTTP, gli sviluppatori creano API (Application Programming Interface) che sono descrizioni specifiche di quali dati e in quale ordine possono essere scambiati tra due sistemi.
Il software che rende disponibile un'API in Internet e la rende accessibile da altri sistemi (in modo simile al modo in cui si visita una normale pagina Web) è chiamato server delle applicazioni. Tutto ciò che fa è ascoltare e rispondere alle richieste che arrivano da altri server delle applicazioni e, a seconda della richiesta, aggiunge o ottiene informazioni dal database sottostante. Informazioni utili: quando le persone menzionano API, è spesso una scorciatoia per il server delle applicazioni che espone API a Internet.
Allora giochiamo con le API.
API-primo mondo
Le API sono diventate una lingua franca del marketing digitale di oggi. La maggior parte del lavoro di sincronizzazione dei dati oggi consiste nell'apprendere un'API per essere in grado di estrarre dati da essa. È come imparare un altro insieme di parole da una lingua straniera, supponendo che tu conosca la grammatica, che in questo caso è definita da HTTP.
Sebbene sia il lavoro di uno sviluppatore, approfondire questo argomento potrebbe aiutarti a navigare nel mondo della tecnologia di marketing.
Abbiamo creato un articolo dedicato con alcuni esempi pratici sulla comprensione delle API, quindi se vuoi padroneggiarlo (e di nuovo dovresti), leggilo qui .
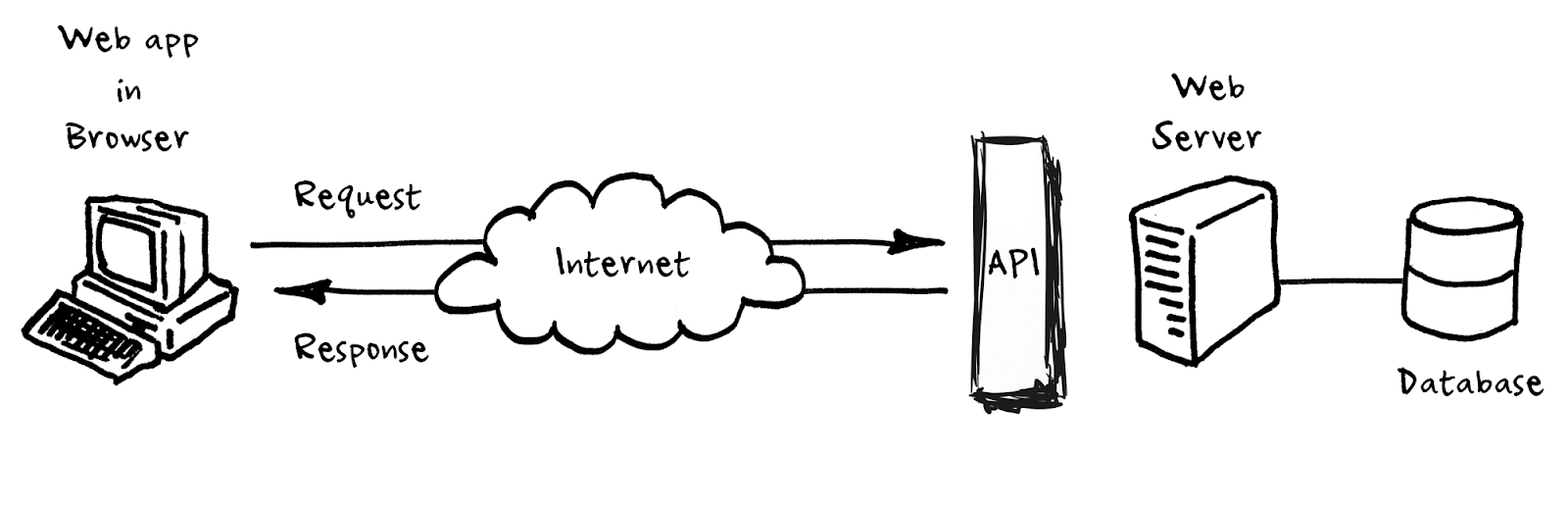
Questo è l'estratto più importante da esso:
“Se vai in un ristorante come cliente, non ti è permesso entrare in cucina. Devi sapere cosa è disponibile. Per questo, hai il menu. Dopo aver visto il menu, fai un ordine a un cameriere, che lo passa in cucina e che poi consegnerà ciò che hai chiesto. Il cameriere può consegnare solo ciò che la cucina può fornire.
Come si collega a un'API? Il cameriere è l'API. Sei una persona che chiede servizio. In altre parole, sei un cliente o consumatore API. Il menu è la documentazione che spiega cosa puoi chiedere all'API. La cucina è, ad esempio, un server; un database che contiene solo un certo tipo di dati: tutto ciò che l'acquirente ha acquistato per il ristorante come ingredienti e ciò che lo chef ha deciso che offriranno e ciò che i cuochi sanno come preparare".
- Cucina: il database, nessun cliente è autorizzato a proteggere l'integrità dei dati.
- Waiter – L'API, un intermediario che sa come servire i dati dal database senza interromperne il funzionamento.
- Cliente: un sistema esterno che desidera ottenere i propri dati.
- Menu – Il formato dati di riferimento che i sistemi esterni devono utilizzare per eseguire le proprie operazioni.
- Ordine: una vera singola chiamata API.
Tornando alla sincronizzazione, la questione che resta ora è capire a quali condizioni due sistemi dovrebbero scambiarsi dati.
Trigger della sincronizzazione dei dati
Supponiamo di avere due server applicativi pronti per lo scambio di informazioni. Per essere più specifici, immaginiamo che il tuo provider di servizi di posta elettronica ( ESP ) voglia conoscere il numero di ordini dei clienti (e-shop) per inviare loro un coupon promozionale dopo il decimo ordine. Ora, che tipo di flusso di dati possiamo implementare per realizzare questo scenario? Possiamo distinguere tre "trigger" che possono avviare il meccanismo dei coupon e-mail sul lato ESP.
a) Sondaggio dei dati : in questo caso ESP chiede ripetutamente all'API dell'e-shop: "Fammi sapere l'importo totale dell'ordine per Jane Doe". Lo fa ogni minuto, un'ora o un giorno ecc. Quando ESP riceve le informazioni, ricalcolerà le condizioni di invio del coupon ogni richiesta API. Il tuo istinto è giusto se stai pensando che potrebbe non essere ottimale chiamare ed elaborare i dati in questo modo. Qual è l'alternativa?

b) Data push : e se un e-shop potesse notificare l'applicazione ESP nel momento in cui Jane ha effettuato il suo decimo ordine? Giusto. Le moderne piattaforme di e-commerce si sono rese conto di queste carenze e hanno incluso tali notifiche nel loro set di funzionalità. Di solito sono chiamati webhook o call-out. È una funzionalità semplice ma potente. Consente di definire quando e quali applicazioni devono essere notificate a condizioni specifiche. Puoi anche definire che tipo di informazioni dovrebbe includere una notifica: a volte è ragionevole inviare informazioni complete, ma spesso è sufficiente solo una proprietà modificata.

c) Elaborazione batch – a volte, il numero di richieste è così grande che nessuno di questi due metodi è ragionevole. La quantità di potenza di elaborazione necessaria per gestire il carico danneggerebbe una (o anche entrambe) delle parti. In questo caso, gli sviluppatori raggruppano tutte le informazioni in un “batch” e pianificano lo scambio di dati di notte o, più in generale, quando i server non sono occupati dal traffico quotidiano. Ciò aiuta a controllare il traffico verso le applicazioni e previene potenziali sollecitazioni sul server.

Termini utili: per evitare di inviare troppe richieste a un server, gli sviluppatori di applicazioni applicano dei limitatori di velocità alle loro applicazioni. Limita il numero di chiamate API in un determinato periodo, ad esempio 5000 chiamate al minuto. Spesso le chiamate che superano la quota vengono limitate . Ciò significa che alla fine verranno serviti (invece di eliminarli del tutto) ma con un certo ritardo.
Finora, abbiamo imparato come vengono sincronizzati i dati dei clienti. Ma prima che possa avvenire l'effettiva segmentazione dei clienti, dobbiamo capire come mantenere coerenti i dati nel database. Nella parte successiva, descriveremo come garantire l'integrità e la sicurezza dei dati per ottenere campagne dal buon rendimento.