
웹 스크래핑 - 데이터 과학의 필수적인 부분
게시 됨: 2020-02-21웹 스크래핑은 데이터 과학의 필수적인 부분이 되었으며 그 자체로 생태계이며 이 용어는 종종 기계 학습, 인공 지능 및 기타의 대체물로 사용됩니다. 데이터 과학 생태계는 전체 수명 주기를 함께 구성하는 5가지 단계로 구성됩니다. 각 단계는 해당 단계를 완료하는 데 사용된 여러 옵션으로 구성됩니다.
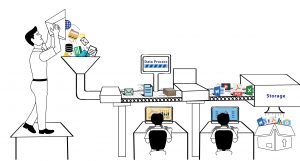
웹 스크래핑 방법:
데이터 캡처
- 웹 스크래핑과 같은 프로세스를 사용한 데이터 추출.
- 수동 데이터 입력.
- 데이터 수집 - 데이터 세트 구매.
- IoT 장치에서 신호를 캡처합니다.

데이터 처리
- 데이터 수집.
- 원시 데이터의 분류 또는 클러스터링.
- 데이터 정리 및 정규화.
- 데이터 모델링.
유지
- 데이터 웨어하우징 및 데이터 레이크.
- 데이터를 관리 및 저장하고 최대 가용성을 제공하기 위한 인프라 구축.
발견 사항 전달
- 그래프를 사용한 결과 시각화.
- 결과를 텍스트 보고서로 요약합니다.
- 비즈니스 인텔리전스 및 의사 결정.
해석학
- 탐색적 및 확증적 분석.
- 예측 분석.
- 회귀.
- 텍스트 마이닝.
- 감정 및 정성 분석.

위의 목록에서 볼 수 있듯이 알고리즘을 실행하려는 데이터가 있는 데이터 캡처 없이는 데이터 과학 분야에서 아무 일도 일어나지 않을 것입니다. 이 첫 번째 단계는 중요하며 주요 구성 요소입니다. 매일 테라바이트의 사용 가능한 데이터를 생성하는 시스템이 없다면 웹에서 데이터를 크롤링하고 데이터베이스에 저장하여 알고리즘을 실행하고 예측 엔진을 구축할 수 있습니다.
데이터 과학자가 웹 스크래핑에 사용할 수 있는 도구는 무엇입니까?
데이터 과학자이고 코드를 작성하여 인터넷에서 데이터를 크롤링해야 하는 경우 Python 을 사용하여 코드를 작성할 수 있습니다. 학습 곡선이 더 쉬울 뿐만 아니라 코드를 통해 자동화된 방식으로 웹 사이트와 상호 작용할 수 있습니다. 코드를 통해 웹사이트가 웹 브라우저를 사용할 때와 같이 요청을 수신하는 방식으로 웹사이트와 상호 작용할 수 있습니다. 스크래핑 요구 사항을 자동화하고, 적시에 스크립트를 실행하거나, 데이터 과학 프로젝트를 위한 데이터 세트를 구축하기 위해 (Twitter와 같은 소셜 미디어 웹사이트에서) 데이터를 안정적으로 공급할 수도 있습니다. 다음은 프로젝트를 위해 데이터를 스크랩할 때 사람들이 직면하는 다양한 문제를 해결하는 데 도움이 되는 Python에서 사용할 수 있는 몇 가지 라이브러리입니다.
요청
코드를 통해 웹에서 데이터를 크롤링하려는 경우 첫 번째 목표는 코드를 사용하여 웹사이트를 방문하는 것입니다. 바로 여기에서 요청 라이브러리가 필요합니다. 웹 페이지 및 API를 쉽게 호출할 수 있기 때문에 Python 커뮤니티에서 선호하는 라이브러리입니다. 이것은 많은 상용구 코드를 추상화하고 내장 URLLib 라이브러리를 사용할 때보다 HTTP 요청을 더 간단하게 만듭니다. 여기에는 브라우저 스타일 SSL 확인, 헤드리스 요청, 자동 콘텐츠 디코딩, 프록시 지원 등과 같은 여러 기능이 포함됩니다.


아름다운 수프
웹에서 스크랩한 웹 페이지가 있으면 HTML 페이지의 태그와 속성에서 데이터를 추출해야 합니다. 이를 위해 모든 데이터에 쉽게 액세스할 수 있도록 HTML 콘텐츠를 구문 분석해야 합니다. BeautifulSoup 을 사용하면 탐색, 검색 및 수정을 간단하게 만드는 방식으로 HTML 및 XML 문서를 쉽게 구문 분석할 수 있습니다. 문서를 트리처럼 취급하며 트리 데이터 구조를 탐색하는 것과 같은 방식으로 탐색할 수 있습니다.

메카니컬 수프
더 복잡한 웹 사이트와 상호 작용할 때. 많은 웹 페이지를 크롤링하는 데 도움이 되는 확장 기능이 필요할 수 있습니다. Mechanical Soup 은 쿠키의 저장 및 전송을 자동화하고 리디렉션을 허용하며 링크를 따라가고 양식을 제출할 수도 있습니다.

스크랩
가장 강력한 Python 기반 웹 스크래핑 라이브러리 중 하나인 Scrapy 는 오픈 소스 및 협업 프레임워크를 제공합니다. 데이터 마이닝 작업, 자동화된 스파이더, 웹의 주기적인 크롤링을 설정하는 데 사용되는 고급 스크래핑 라이브러리입니다. Scrapy는 Spider라는 것을 사용합니다. 웹 페이지에서 정보를 추출하는 데 사용되는 사용자 정의 클래스입니다.

셀렌
일반적으로 웹 페이지 및 해당 기능을 테스트하는 데 사용되는 Selenium 은 스크린샷을 사용하여 웹에서 데이터 스크래핑, 클릭 자동화 및 노출된 데이터 스크래핑 등과 같은 자동 수동 작업에도 사용할 수 있습니다.

웹 스크래핑과 기타 데이터 소스:
오늘날 여러 데이터 소스를 사용할 수 있지만 웹 스크래핑은 회사에서 데이터를 조달하는 가장 인기 있는 프로세스 중 하나로 부상했습니다(이는 결국 처리되어 사용 가능한 정보로 변환됨). 그 이면의 가장 큰 이유 중 하나는 데이터 과학 프로젝트에서 작업할 때 이전에 파생되지 않은 논문을 작성하거나 결과를 예측할 수 있는 새로운 사용되지 않은 데이터를 선호하기 때문입니다. 데이터는 새로운 오일이지만 데이터의 가치는 시간이 지남에 따라 감소합니다. 이런 식으로 웹 스크래핑은 신의 선물입니다. 웹의 데이터가 매초마다 업데이트되기 때문입니다. 새로운 데이터로 대체되지 않는 한 유효합니다. 예를 들어 웹사이트에 있는 항목의 가격은 $1000일 수 있습니다.
보고서를 검색하여 출처에서 가격 목록을 얻을 수 있습니다. 가격 목록이 $1000 마크와 함께 귀하에게 도달할 때까지 품목 가격은 $900로 하락했을 수 있습니다. 그러므로 당신이 가지고 있는 가격에 근거한 당신의 결정은 잘못된 것으로 판명될 것입니다. 대신 지금 항목의 가격을 크롤링하면 그 순간의 가격을 알 수 있습니다. 그런 다음 정기적인 빈도로 스크레이퍼를 계속 실행하여 10초마다 가격 변동을 캡처할 수 있습니다. 따라서 데이터와 함께 앉아 결정을 내릴 때 업데이트된 데이터와 과거 데이터를 모두 갖게 되며 결과를 개선할 수 있습니다. 끝없는 데이터의 꾸준한 흐름은 웹 스크래핑이 제공하는 것입니다. 그것이 마케팅 관리자든 연구 과학자든 데이터 과학의 주된 이유입니다.
데이터 과학에서 스크랩한 데이터를 사용할 때의 과제:
웹 스크래핑으로 얻는 데이터는 방대하고 규칙적입니다. 중요한 사실은 웹에서 추출한 데이터에는 일반적으로 많은 양의 깨끗하지 않고 구조화되지 않은 데이터가 포함되어 있다는 것입니다 . 또한 확인되지 않은 데이터 요소뿐만 아니라 중복 항목도 확인되었습니다. 데이터 소스를 수정하는 것이 중요하므로 데이터는 항상 확인되고 알려진 웹사이트에서 크롤링해야 합니다. 동시에 많은 데이터 소스가 데이터를 확인하는 데 사용되었습니다. 일부 지능형 코딩을 사용하여 데이터를 정리하고 중복 항목이 없는지 확인합니다. 그러나 비정형 데이터를 정형 데이터로 변환하는 것은 여전히 가장 어려운 웹 스크래핑 문제 중 하나로 남아 있으며 솔루션은 경우에 따라 다릅니다.
다른 주요 문제는 보안, 합법성 및 개인 정보 보호에서 발생합니다. 점점 더 많은 국가에서 데이터 개인 정보 보호 및 데이터 액세스 제한이 높아짐에 따라 로그인 페이지를 통해서만 액세스할 수 있는 웹 사이트가 점점 더 많아지고 있습니다. 데이터를 크롤링하지 않는 한 이에 대한 패널티가 있을 수 있습니다. 귀하의 IP가 차단되는 것에서 시작하여 귀하를 상대로 소송을 제기할 수 있습니다.
결론:
모든 기회에는 도전이 따릅니다. 도전이 클수록 보상도 높아집니다. 따라서 웹 스크래핑은 비즈니스 워크플로에 통합되어야 하고 데이터 과학 프로젝트는 해당 데이터에서 사용 가능한 정보를 생성해야 합니다. 그러나 회사나 스타트업을 위해 웹사이트에서 데이터를 스크랩하는 데 도움이 필요한 경우 PromptCloud 팀에서 요구 사항을 알려주고 스크랩 엔진을 설정하는 완전 관리형 DaaS 솔루션을 제공합니다.