
So erstellen Sie einen modernen Datenstapel
Veröffentlicht: 2022-05-06In der heutigen technologiegetriebenen Wirtschaft ist die Datenspeicherung komplexer denn je. Laut IDC (International Data Corporation) werden im Jahr 2025 175 Zettabyte an Daten generiert, was fast der dreifachen Menge entspricht, die im Jahr 2021 (61 Zettabyte) generiert wurde.
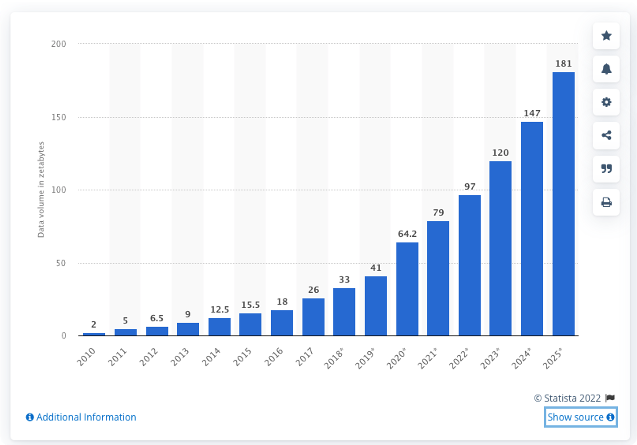
Das Datenvolumen, das von Statista von 2010 bis 2025 weltweit erstellt, erfasst, kopiert und konsumiert wurde
Wenn Sie die Informationen Ihres Unternehmens korrekt speichern und verwalten möchten, müssen Sie die vielen verfügbaren Optionen verstehen und wissen, wie sie miteinander integriert werden können.
Glücklicherweise hilft Ihnen dieser Leitfaden beim Aufbau eines modernen Datenstapels, der es Ihnen ermöglicht, Ihre Daten so effektiv wie möglich zu sammeln, zu speichern, zu analysieren und letztendlich zu nutzen. Diese Blaupause ist flexibel genug, um von Unternehmen in jeder Entwicklungsphase unabhängig von ihrer Größe oder Branche verwendet zu werden.
Warum brauchen Sie einen modernen Datenstack?
Ein moderner Datenstapel ist ein integrierter Satz von Werkzeugen zur Handhabung des End-to-End-Lebenszyklus von Daten. Es wurde entwickelt, um Informationen in Echtzeit zu sammeln, zu verarbeiten und zu aktivieren. Es ist wichtig für jede Organisation, die Trends auf granularer Ebene (z. B. innerhalb der Organisation eines Kunden) verstehen und darauf reagieren möchte, bevor sie dauerhaft in Stein gemeißelt werden.
Das Erstellen eines modernen Datenstapels ist nicht schwer, erfordert jedoch etwas Zeit und Engagement sowie ein Verständnis dafür, was Sie von Ihren Daten erwarten. Wenn Sie es ernst meinen, den Betrieb zu verbessern und Einblicke in Ihre Kunden zu gewinnen, ist es jede Minute Mühe wert. Der Trick besteht darin, zu wissen, wo man anfängt und wie man vorankommt.
Der Rest dieses Leitfadens gibt Ihnen alle Informationen, die Sie zum Erstellen eines modernen Datenstapels benötigen. Sie erfahren, wie verschiedene Komponenten zusammenarbeiten und wie Sie Software für jeden Teil Ihres modernen Datenstapels auswählen. Sobald Sie mit dem Lesen fertig sind, haben Sie alles, was Sie brauchen, um noch heute mit dem Aufbau eines modernen Daten-Stacks in Ihrem Unternehmen zu beginnen!
„Aus Datensicht sind Data-Warehouse-Appliances eine wahre Goldgrube. Sie für vertikal integrierte Lösungen verfügbar zu machen, ist der Kern der Idee der Industrie-Cloud.“
Ashish Thusoo
Data Lakes und Data Warehouses: Die zwei Seiten einer modernen Cloud-Datenplattform
Vorteile eines modernen Datenstacks
Warum in einen modernen Datenstack investieren? Hier sind einige Vorteile:
- Extrahieren und laden Sie Ihre Daten in wenigen Minuten an jeden beliebigen Ort.
- Analysieren Sie große Mengen unstrukturierter Daten – Dokumente, Suchergebnisse, verschiedene Metriken usw. – ohne auf das Schreiben benutzerdefinierter Skripte oder das Erstellen von Ad-hoc-Abfragen zurückgreifen zu müssen.
- Ermöglichen Sie jedem Geschäftsteam die Selbstbedienung mit betrieblichen, vertrauenswürdigen und aktuellen Daten in ihren eigenen Tools.
- Stellen Sie Innovationen in Ihrem Unternehmen schneller bereit, indem Sie No-Code-Tools für Geschäftsteams integrieren
- Moderne Daten-Stacks reduzieren den Aufwand für die Datentechnik, indem sie den Aufbau und die Wartung einer Datenpipeline überflüssig machen.
Verstehen Sie das aktuelle Umfeld
Der erste Schritt beim Entwerfen einer Lösung besteht darin, zu verstehen, was Sie zu beheben versuchen. Treten Sie einen Schritt zurück und sehen Sie sich an, welche aktuellen Tools, Prozesse und Verfahren Ihre Organisation derzeit verwendet. Dann fragen Sie sich: Sind sie effizient? Gibt es Raum für Verbesserungen?
Beim modernen Daten-Stack dreht sich alles um Effizienz. Wenn also Ihr aktueller Prozess Ineffizienzen aufweist (und glauben Sie mir, das gibt es), ist dies ein Bereich, in dem Sie ihn optimieren können.
In einigen Fällen kann es so einfach sein, die Zusammenarbeit zwischen Teams zu verbessern oder Ihre Prozesse zu aktualisieren, aber manchmal kann es auch bedeuten, veraltete Software zu ersetzen oder sogar neue Technologien in Ihre Umgebung einzuführen.
Was auch immer es ist, beginnen Sie damit, die genauen Probleme zu definieren, die Sie lösen möchten, bevor Sie mit der Konstruktionsarbeit fortfahren. Es wird die spätere Implementierung viel einfacher machen.
Identifizieren Sie geschäftliche Anforderungen und Ziele
Bevor Sie eine Datenbank für Ihr Unternehmen auswählen, müssen Sie ihr Datenmodell verstehen, welche Art von Abfragen und Berichten erforderlich sind und wer sie verwenden wird. Antworten auf diese Fragen zu erhalten, wird Ihrem Unternehmen auch dabei helfen, im Voraus zu planen (anstatt später Änderungen vorzunehmen).
Eine Schlüsselfrage dabei ist, wie groß Ihr Datenspeicher sein muss. In einem OLAP-Szenario (Online Analytical Processing) haben Sie beispielsweise viele Zeilen, aber nur wenige Daten in jeder Zeile – aber in einem Online-Transaktionsverarbeitungsszenario (OLTP) haben Sie viele Zeilen mit riesigen Datenmengen in jeder Reihe viel mehr Stauraum benötigen. Und dann gibt es Business Intelligence (BI)-Berichtsanforderungen, die noch mehr Platz benötigen. Für solche Fälle ist BigQuery der perfekte Speicher, der alle drei Szenarien wirklich gut bewältigen kann.
Eine andere Sache, über die Sie nachdenken sollten, ist, ob Sie Cloud- oder On-Premise-Speicher verwenden möchten. Wenn Sie also bereits in eine lokale Infrastruktur investiert haben, ist die Google Cloud Platform möglicherweise nicht das Richtige für Sie.
Berechnen Sie Skalierbarkeit und Leistung
Bei der Auswahl eines Cloud-Anbieters ist es wichtig zu berücksichtigen, ob Ihre Anwendung im Laufe der Zeit wie erwartet skaliert und funktioniert.
Eine weitere wichtige Sache ist zu verstehen, wie Ihre Daten in jeder Umgebung geschützt werden (z. B. können Rechenzentren Naturkatastrophen, Stromausfälle oder Geräteausfälle erleiden).
Wie bei all diesen Schritten sind Nachforschungen und das Stellen von Fragen unerlässlich. Unternehmen wie New Relic bieten Tools an, mit denen Sie die Leistung und den Datenverkehr Ihrer Anwendung überwachen können.
Darüber hinaus haben Organisationen wie Netflix Open-Source-Technologien entwickelt, die speziell für moderne Anwendungen entwickelt wurden, die in öffentlichen Clouds ausgeführt werden. Zum Beispiel hat Netflix Security Monkey entwickelt, eine Software, die hilft, große AWS-basierte Umgebungen zu überwachen und zu sichern.
Es lohnt sich, sich bei der Bewertung von Cloud-Anbietern mit diesen Technologien zu befassen – diese Art von Wissen stammt aus Gesprächen mit Ingenieuren verschiedener Unternehmen und dem Verständnis ihrer Erfahrungen.
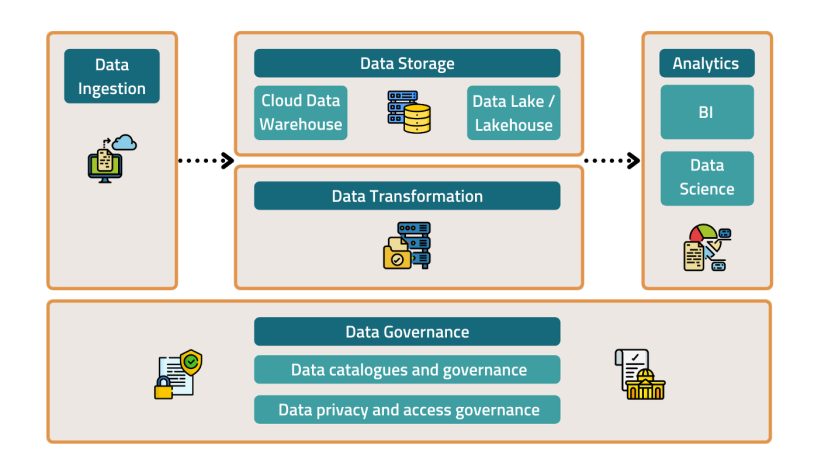
Die Komponenten eines modernen Datenstacks
Daten sind ein strategisches Gut. Um das Beste daraus zu machen, müssen Sie die verschiedenen Komponenten verstehen, aus denen ein Datenstapel besteht, und wie sie zusammenarbeiten.
Hier sind die Schlüsselkomponenten eines Datenstapels, die Sie beim Entwerfen Ihrer eigenen Dateninfrastruktur für Ihr Produkt berücksichtigen sollten:
- Datenaufnahme
- Datenspeicher
- Datentransformation
- Datenanalyse
- Datenamt
1. Datenaufnahme
Datenaufnahme ist das Importieren von Daten von einem Ort an ein neues Ziel, wie z. B. ein Data Warehouse oder einen Data Lake, zur weiteren Speicherung und Analyse.
Ihr erster Schritt beim Erstellen eines modernen Datenstapels besteht darin, Ihre Datenquellen zu identifizieren. Dank Datenerfassungstools können Sie alle Ihre Daten in wenigen Minuten importieren.
Angenommen, Sie betreiben ein E-Commerce-Geschäft. Anfragen müssen sich auf die von Ihnen verkauften Produkte und deren Variationen beschränken. Sie möchten nicht, dass Hunderte von Abfragen pro Tag Ihre Datenbank treffen, weil jemand einen Artikel abgefragt hat, den er nicht einmal kauft. Ordnen und filtern Sie Ihre Produkte nach Kundengruppe, SKU oder anderen Filtern und bieten Sie benutzerfreundlichen Zugriff über die Schaltfläche „Besuchen Sie meinen Shop“, damit Kunden ihre Bestellhistorie für Verkäufe, die über Ihre Website getätigt wurden, einfach abrufen können.
Beispiele für Tools: Improvado, Fivetran, Stitch, Airflow
️Unsere Liste der 16 besten Datenerfassungstools hilft Ihnen bei der Auswahl des besten Tools für Ihren Datenstapel️
2. Datenspeicherung
Mit dem Aufkommen von Cloud-nativen Anwendungen und Microservices erzeugen die meisten Unternehmen riesige Datenmengen, die gespeichert und verwaltet werden müssen. Dies ist eine herausfordernde Aufgabe für herkömmliche relationale Datenbanken, die für strukturierte Daten entwickelt wurden.
NoSQL-Datenbanken sind ideal für unstrukturierte Daten, aber sie können schwierig in großem Umfang bereitgestellt werden, insbesondere in hybriden Umgebungen.
Cloud-Anbieter bieten ihre eigenen verwalteten Lösungen an, um bei diesem Schritt zu helfen. Beispielsweise bietet AWS eine Lösung namens Amazon Simple Storage Service (S3) für die Objektspeicherung an. Google bietet BigQuery als Teil der Cloud Platform an. Beide Dienste bieten eine Plattform mit geringer Latenz zum Speichern großer Datenmengen im großen Maßstab.
Beispiele für Tools: Snowflake, Databricks, AWS, GCP
Lesen Sie unsere Liste der 15 besten Data-Warehousing-Tools, um dasjenige zu finden, das Ihren Geschäftsanforderungen entspricht
3. Datentransformation
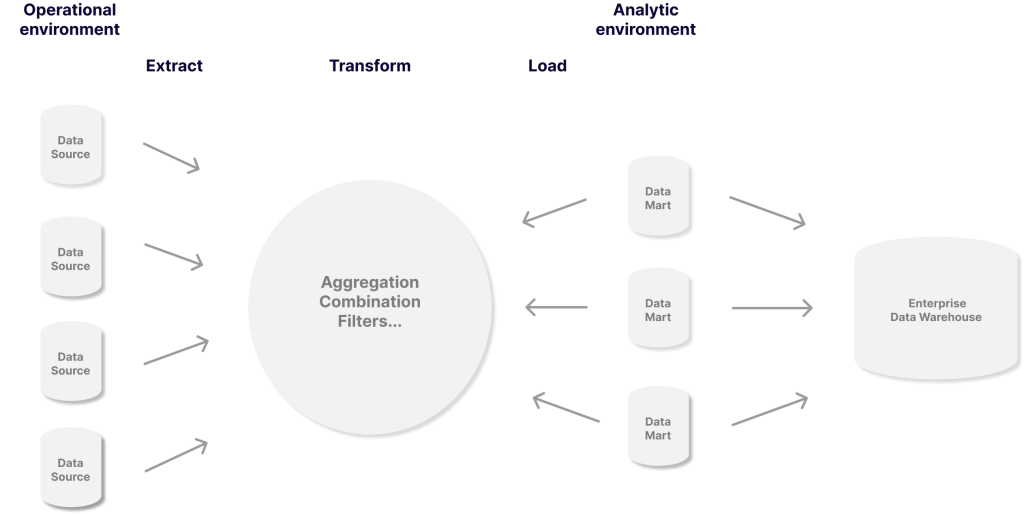
Datentransformation ist der Prozess der Konvertierung von Daten von einem Format oder einer Struktur in ein anderes Format oder eine andere Struktur. Normalerweise wird die Datentransformation unter Verwendung von Extraktions-, Transformations- und Ladetechniken (ETL) durchgeführt.
Erfahren Sie, wie der ETL-Prozess manuelle Datenoperationen beschleunigt
Die Datentransformation ist im Datenintegrationsprozess von entscheidender Bedeutung, da sie Daten für die weitere Analyse, Berichterstattung und Visualisierung vorbereitet und normalisiert. Die Datentransformation kann für jede Art von Datensatz durchgeführt werden, unabhängig von seinem ursprünglichen Format oder seiner ursprünglichen Bezeichnung.
Beispiele für Tools: Improvado DataPrep, Dbt, MCDM, Matillon, Alteryx, RestApp

4. Datenanalyse
Die Analyseschicht ist für die Aggregation, Analyse und Präsentation der Daten für Benutzer verantwortlich. Ihre Analyseebene sollte Fragen beantworten wie:
- Was sind die wichtigsten Kennzahlen für mein Unternehmen?
- Wie ändern sich diese Metriken im Laufe der Zeit?
- Wie wirkt sich eine Metrik auf eine andere aus?
Meistens bedeutet dies, dass Ihre Daten in Grafiken, Diagramme, Tabellen und andere visuelle Darstellungen umgewandelt werden, die Sie sofort verstehen können.
Einige neuere Datenanalyseplattformen verfügen über Funktionen, die es technisch nicht versierten Personen ermöglichen, Daten ohne SQL-Kenntnisse zu untersuchen.
Beispieltools: Looker, Tableau, Power BI
„Ohne Big-Data-Analytik sind Unternehmen blind und taub und wandern wie Rehe auf der Autobahn ins Internet.“
Geoffrey Moore, Autor und Berater.
5. Datenverwaltung
Es ist wichtig, für jeden Schritt in der Datenpipeline eine klare Eigentümerschaft und einen klaren Prozess sicherzustellen. Dazu gehört das Festlegen von Standards für die Arten von Daten, die gesammelt werden und wie sie gespeichert und abgerufen werden, sowie Prozesse, um sicherzustellen, dass diese Standards befolgt und durchgesetzt werden.
Angenommen, Ihr Ziel ist es, Daten zur Verbesserung der betrieblichen Effizienz zu verwenden. Sie könnten entscheiden, dass alle Ihre Bestandssysteme dasselbe Barcode-System verwenden sollten, damit Sie sich ein vollständiges Bild Ihrer Lieferkette machen können, ohne verschiedene Codes oder Systeme manuell abgleichen zu müssen.
Beispieltools: Atlan, Microsoft Azure Data Catalog, Informatica
Reverse-ETL-Alternative
Viele Unternehmen haben ihre Datenstacks mit ETL-Technologien aufgebaut. Diese Technologien sind nützlich, um große Datenmengen aus mehreren Quellen zu verarbeiten und in ein zentrales Data Warehouse zu verschieben. Dieser Ansatz erhöht jedoch die Komplexität Ihrer Infrastruktur und verlangsamt die Lieferzeit.
In der heutigen Welt werden Geschäftsentscheidungen zunehmend auf der Grundlage von Echtzeitdaten getroffen, sei es in den Bereichen Finanzen, Lieferkettenmanagement oder Kundenbeziehungen. Ein moderner Daten-Stack ermöglicht es Ihnen, Echtzeit-Einblicke in das gesamte Unternehmen zu liefern, indem Sie Ihre Daten aktuell, zugänglich und sicher halten.
An dieser Stelle kann Ihnen Reverse ETL dabei helfen, einen modernen Datenstapel aufzubauen, der dem Unternehmen einen Mehrwert in Echtzeit liefert und das Ausfallrisiko aufgrund veralteter Informationen eliminiert.
Reverse ETL ist eine Reihe von Methoden oder Prozessen, die Daten aus einem Data Warehouse mit operativen Tools wie CRM, CMS, Produkten oder anderen Business-Tools (Slack, Google Sheet usw.) synchronisieren.
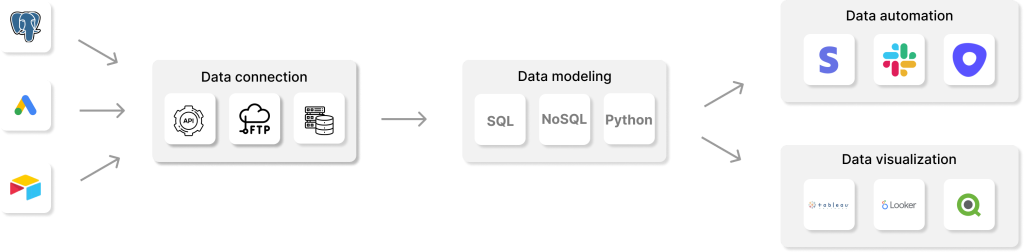
Die Idee hinter diesem Prozess ist die Schaffung einer einzigen, umfassenden Datenquelle, die eine zusammenhängende, vertrauenswürdige Ansicht der Unternehmensdaten bietet. Reverse-ETL-Prozesse werden im Allgemeinen verwendet, um bestehende ETL-Prozesse zu erweitern, und sie laufen in definierten Zeitintervallen. Außerdem ermöglicht Reverse ETL Operational Analytics.
Operational Analytics vs. Business Intelligence
Operational Analytics ist die Nutzung von Daten, Predictive Analytics und Business-Intelligence-Tools, um Einblicke in den Geschäftsbetrieb zu gewinnen und dank aktivierter Daten Echtzeit-Aktionen zu generieren.
Business Intelligence (BI) wird von Investopedia als die prozedurale und technische Infrastruktur definiert, die die durch die Aktivitäten eines Unternehmens erzeugten Daten sammelt, speichert und analysiert.
Business Intelligence konzentriert sich auf die Analyse historischer Daten.
Es hilft Ihnen zu verstehen, was passiert ist und warum. Es wird verwendet, um Geschäftsentscheidungen zu unterstützen, indem Muster und Trends durch Datenvergleiche, Benchmarks und andere statistische Techniken identifiziert werden.
Beispielsweise ist es sinnvoll, einen Bericht zu erstellen, der die Anzahl der Bestellungen in einem bestimmten Zeitraum, den durchschnittlichen Bestellwert und die Gesamtzahl der Bestellungen anzeigt.
Operational Analytics ist ein Begriff, der sich auf Echtzeit und die Zukunft konzentriert. Es konzentriert sich auf das, was jetzt passiert, und auf die Vorhersage, was als nächstes passieren wird, damit es dabei helfen kann, das Beste aus zukünftigen Chancen zu machen.
Zusammenfassend zeigt Operational Analytics, wo wir jetzt handeln müssen, während Business Intelligence aufzeigt, was falsch gemacht wurde und wo Verbesserungsbedarf besteht.
Operational Analytics ist nicht mehr auf digitale Giganten wie Google, Facebook und Netflix beschränkt. Dank Echtzeitdaten trifft jedes Unternehmen, das einen modernen Datenstapel verwendet, mehr datengesteuerte Entscheidungen.
Eine organisatorische Weiterentwicklung ist erforderlich
Wenn ein Unternehmen einen modernen Datenstapel implementiert, gibt es drei große Veränderungen in der Art und Weise, wie Daten verwaltet werden:
Eine Verlagerung von der IT hin zu Geschäftsanwendern
In der Vergangenheit hat die IT-Abteilung Anfragen nach Daten von Abteilungen und Analysten entgegengenommen. Die Entwicklung von Self-Service-Analysetools wie Tableau und Looker hat es Geschäftsanwendern ermöglicht, direkt auf Daten zuzugreifen und diese zu analysieren.
Diese Verschiebung hat enorme Auswirkungen darauf, wie Unternehmen ihre Ressourcen rund um Daten organisieren.
Von der Batch- bis zur Echtzeit-Datenverarbeitung
. Da Datenpipelines rationalisiert und Daten im gesamten Unternehmen zugänglicher werden, muss die Verzögerungszeit zwischen dem Eintreten eines Ereignisses und seiner Analyse verkürzt werden.
Dies bedeutet, dass immer mehr Unternehmen die Echtzeitverarbeitung ihrer Daten in Betracht ziehen, anstatt Daten über längere Zeiträume zu aggregieren.
Von isolierten Datenbanken zu föderiertem Eigentum (Domains)
Herkömmliche Datenarchitekturen basieren auf isolierten Datenbanken und föderiertem Eigentum, was zur Verbreitung von Data Lakes, Data Marts und Data Warehouses geführt hat.
Diese Architekturen konzentrierten sich auf zentralisierte Rechen- und Speicherinfrastruktur. Da Cloud-Dienste ausgereift und modernisiert wurden, sollte dies auch der Ansatz zur Architektur von Datenstapeln sein.
Heutige Datenarchitekturen müssen in der Lage sein, den Umfang und die Komplexität moderner Anwendungen zu bewältigen, die über eine Reihe von Technologien verteilt sind. Hier kommt das Konzept eines Datennetzes ins Spiel – eine neue Architektur, die es ermöglicht, auf alle Arten von Daten sicher zuzugreifen, sie einfach zu verwalten und von jeder Anwendung überall zu nutzen.
Verlassen Sie sich auf Ihre Stakeholder
Es gibt drei Haupttypen von Stakeholdern, wenn es um den modernen Datenstapel geht.
Interne Stakeholder
Dies sind die Personen in Ihrem Unternehmen, die Daten bei ihrer täglichen Arbeit verwenden werden.
Beispielsweise könnte das Vertriebsteam daran interessiert sein, wie viel Umsatz jeder Kunde einbringt und wie dieser Umsatz gesteigert werden kann. Oder vielleicht interessiert sich das Marketingteam dafür, welche Arten von Inhalten den meisten Website-Traffic generieren.
Die internen Stakeholder sollten ein Mitspracherecht darüber haben, welche Daten Sie sammeln, wie Sie diese Daten strukturieren und welche Tools Sie verwenden, um sie zu analysieren.
Externe Stakeholder
Dies sind die Personen außerhalb Ihres Unternehmens, die dennoch an Ihrem Erfolg beteiligt sind.
Wenn Ihr Unternehmen beispielsweise ein Software-as-a-Service-Unternehmen (SaaS) ist, dann sind die Benutzer Ihres Produkts externe Stakeholder. Wenn Ihr Unternehmen Produkte online verkauft und sie landesweit oder weltweit versendet, dann sind Kunden und Lieferanten externe Stakeholder.
Es ist wichtig zu verstehen, was sie von Ihnen benötigen, damit Sie diese Daten richtig und effizient bereitstellen können.
Beteiligte Dritter
Dies sind Personen außerhalb Ihrer Organisation, die auch Dienstleistungen für Ihr Unternehmen erbringen. Zum Beispiel Lieferanten, die Rohstoffe liefern, oder IT-Berater, die beim Aufbau Ihrer Technologieinfrastruktur helfen. Wer blinde Fliegen in Sachen Daten vermeiden will, muss die Datenanalyse beherrschen. Dies erfordert zunehmend die Entwicklung von Daten außerhalb der eigenen vier Wände.
Ein moderner Datenstapel stärkt die Beziehung zwischen dem Unternehmen und seinen Stakeholdern durch einen effizienteren Datenaustausch dank definierter Domänen für jedes Team und der Möglichkeit, sie in einer No-Code-Umgebung zu verwenden.
Datendomänen stärken die Beziehung zwischen Teams, da sie alle in derselben Domäne arbeiten.
Beispielsweise möchte ein Marketingteam wissen, wie viele Personen sich für ihr neues Produkt oder ihre neue Dienstleistung anmelden und wie viel Umsatz nach der Anmeldung generiert wird. Die vom Produktteam generierten Daten sind für das Marketingteam relevant, da beide in einem ähnlichen Bereich arbeiten.
Fazit
Wie Sie sehen, gibt es beim Einrichten Ihres Datenstacks viele Dinge zu beachten. Angesichts all der verschiedenen beteiligten Komponenten ist dies ein großes Unterfangen, und es kann schwierig sein, alle beweglichen Teile zu umarmen.
Wenn Sie verstehen, warum Sie einen Daten-Stack benötigen und wie Ihr Unternehmen davon profitiert, können Sie langfristig planen, indem Sie klare Prozesse und Zeitpläne für die Implementierung festlegen. Die Vorteile der Verwendung eines modernen Datenstapels bestehen darin, alle Herausforderungen auf dem Weg zu überwiegen, nicht nur in Bezug auf einzelne Projekte und Initiativen, sondern auch in Bezug auf die Schaffung einer starken Grundlage, die Ihnen hilft, insgesamt bessere Entscheidungen zu treffen.