
Google BERT 업데이트: 배경 및 분석
게시 됨: 2019-10-29이는 5년 동안 Google 알고리즘의 가장 큰 변화로, 검색어 10개 중 1개에 영향을 미칩니다. Google BERT 업데이트를 통해 Google은 복잡한 롱테일 검색 쿼리의 해석을 개선하고 보다 관련성 높은 검색 결과를 표시하는 것을 목표로 합니다. Google은 자연어 처리를 사용하여 검색어의 의미적 맥락을 이해하는 능력을 크게 향상시켰습니다.
웹사이트의 검색 엔진 최적화에 대한 지원을 찾고 있다면 다음 전문가로부터 더 많은 정보와 분석을 얻을 수 있습니다.
약속을 정하세요!
Google BERT 업데이트에서 Searchmetrics의 2센트
 “Bert는 Panda, Hummingbird 및 RankBrain의 발자취를 따르는 Google의 논리적 개발입니다. 그러나 이번에는 데이터가 인덱싱되거나 순위가 매겨지는 방식의 변화를 살펴보지 않습니다. 대신 Google은 검색어의 컨텍스트를 식별하고 그에 따라 결과를 제공하려고 합니다. 이것은 Word2Vec 및 GloVe와 같은 컨텍스트 없는 모델이 제공할 수 있는 것에 대한 흥미로운 추가 사항입니다. 음성 검색 및 대화 검색의 경우 가까운 시일 내에 검색 결과의 품질이 크게 향상될 것으로 기대합니다.” – Malte Landwehr, Searchmetrics 제품 부사장
“Bert는 Panda, Hummingbird 및 RankBrain의 발자취를 따르는 Google의 논리적 개발입니다. 그러나 이번에는 데이터가 인덱싱되거나 순위가 매겨지는 방식의 변화를 살펴보지 않습니다. 대신 Google은 검색어의 컨텍스트를 식별하고 그에 따라 결과를 제공하려고 합니다. 이것은 Word2Vec 및 GloVe와 같은 컨텍스트 없는 모델이 제공할 수 있는 것에 대한 흥미로운 추가 사항입니다. 음성 검색 및 대화 검색의 경우 가까운 시일 내에 검색 결과의 품질이 크게 향상될 것으로 기대합니다.” – Malte Landwehr, Searchmetrics 제품 부사장
BERT는 어디에 출시되었습니까?
BERT는 처음에 Google.com의 자연 검색 결과만 사용했지만 2019년 12월 이후 BERT는 전 세계적으로 70개 이상의 언어를 출시했습니다. 텍스트, 테이블 또는 목록과 함께 자연 검색 결과에 0번 위치로 표시되는 추천 스니펫의 경우 BERT는 Google에서 추천 스니펫도 표시하는 25개 언어 모두에서 이미 사용되었습니다.
BERT는 아프리칸스어, 알바니아어, 암하라어, 아랍어, 아르메니아어, 아제르바이잔, 바스크어, 벨로루시어, 불가리아어, 카탈루냐어, 중국어(간체 및 대만), 크로아티아어, 체코어, 덴마크어, 네덜란드어, 영어로 유기 검색 결과 계산을 위해 출시됩니다. , 에스토니아어, 페르시아어, 핀란드어, 프랑스어, 갈리시아어, 그루지야어, 독일어, 그리스어, 구자라트어, 히브리어, 힌디어, 헝가리어, 아이슬란드어, 인도네시아어, 이탈리아어, 일본어, 자바어, 칸나다어, 카자흐어, 크메르어, 한국어, 쿠르드어, 키르기스어, 라오스어, 라트비아어 , 리투아니아어, 마케도니아 말레이어(브루나이 다루살람 및 말레이시아), 말라얄람어, 몰타어, 마라티어, 몽골어, 네팔어, 노르웨이어, 폴란드어, 포르투갈어, 펀자브어, 루마니아어, 러시아어, 세르비아어, 싱할라어, 슬로바키아어, 슬로베니아어, 스페인어 스와힐리어, 스웨덴어, 타갈로그어, 타직어 , 타밀어, 텔루구어, 태국어, 터키어, 우크라이나어, 우르두어, 우즈벡어 및 베트남어.
이 트윗에서 Google은 BERT의 글로벌 출시를 발표했습니다.
Google 검색에서 언어를 더 잘 이해할 수 있는 새로운 방법인 BERT는 현재 전 세계적으로 70개 이상의 언어로 배포되고 있습니다. 미국 영어용으로 10월에 처음 출시되었습니다. 아래에서 BERT에 대한 자세한 내용을 읽을 수 있으며 전체 언어 목록은 이 스레드에 있습니다. https://t.co/NuKVdg6HYM
— Google SearchLiaison(@searchliaison) 2019년 12월 9일
한편 웹마스터 트렌드 분석가인 John Mueller는 사용자가 트래픽이 40% 감소하고 BERT가 원인이라고 의심한 후 자신의 Google 웹마스터 행아웃 중 하나에서 연설했습니다. Mueller는 BERT가 이러한 순위 및 트래픽 감소에 대한 책임이 아니라 정기 업데이트 또는 핵심 업데이트 중 하나라고 설명했습니다. 알고리즘이 변경되는 기준에 따라 Mueller는 동영상에서 30분 46초부터 Google의 개발이 어떻게 작동하는지 자세히 설명합니다.

BERT은 무슨 뜻인가요?
'BERT'는 Bidirectional Encoder Representations from Transformers의 약자로 신경망 기반의 알고리즘 모델을 의미합니다. 자연어 처리(NLP)의 도움으로 기계 시스템은 인간 언어의 복잡성을 해석하려고 시도합니다. Google의 AI 블로그에서 BERT에 대한 자세한 문서를 찾을 수 있습니다.
간단히 말해서 Google은 BERT를 사용하여 검색어의 컨텍스트를 더 잘 이해하고 개별 단어의 의미를 더 정확하게 해석하려고 합니다. 이 혁신은 Transformers라는 수학적 모델을 기반으로 합니다. 이 모델은 문장의 다른 모든 단어와 관련하여 단어를 분석합니다. 또는 Google 검색 쿼리의 경우 단어의 의미를 따로 따로 보지 않습니다. 이는 전치사의 의미와 검색어 내 개별 단어의 위치를 해석할 때 특히 유용합니다.
Google에서 BERT 업데이트가 중요한 이유는 무엇입니까?
Google에 따르면 모든 검색어의 약 15%가 새로운 것입니다. 즉, 처음으로 검색되는 것입니다. 또한 부분적으로는 음성 검색과 같은 기술 발전의 영향으로 검색어의 표현이 실제 인간의 의사 소통에 점점 더 가까워지고 있습니다. 통계 서비스 Comscore는 음성 검색의 비율이 2년 내에 50%에 도달할 것이라고 전문가입니다. 또 다른 요인은 검색 쿼리의 길이가 증가한다는 점입니다. 오늘날 검색의 70%는 롱테일로 간주될 수 있습니다. 사람들은 완전히 공식화된 질문으로 Google을 찾고 1초 미만의 찰나의 순간에 정확한 답변을 기대합니다. 이제 BERT는 이를 가능하게 하는 기술의 중요한 부분을 차지합니다.
Google은 수년 동안 새로운 검색어에 올바르게 응답하고 콘텐츠 해석을 개선할 수 있는 신경망을 연구해 왔습니다.
- Hummingbird: 2013년에 Hummingbird는 Google 알고리즘에 통합되었습니다. 이 알고리즘 업데이트를 통해 쿼리 내에서 개별 단어를 검색하는 것보다 전체 검색 쿼리를 더 잘 해석할 수 있습니다.
- RankBrain : 2015년 RankBrain은 Google 알고리즘의 일부가 되었으며 세 번째로 중요한 순위 요소로 선언되었습니다. 이를 통해 여러 의미를 가진 검색어를 처리하거나 일반적인 롱테일 검색을 넘어서는 복잡한 쿼리를 처리할 수 있었습니다. RankBrain을 사용하면 최초 검색, 구어체, 대화 및 신조어를 처리하는 것도 가능해졌습니다.
BERT의 영향을 받는 검색어는 무엇입니까?
BERT의 영향은 롱테일 검색 쿼리에 영향을 미칩니다. BERT는 검색창에 질문 또는 단어 그룹으로 입력되는(또는 음성 검색을 위해 말하는) 더 긴 쿼리에 대한 컨텍스트 해석을 개선합니다.
Google은 블로그에서 BERT가 더 잘 이해하는 데 도움이 되고 이제 검색 엔진이 더 관련성 높은 결과를 제공하는 검색어의 몇 가지 예를 제공했습니다.
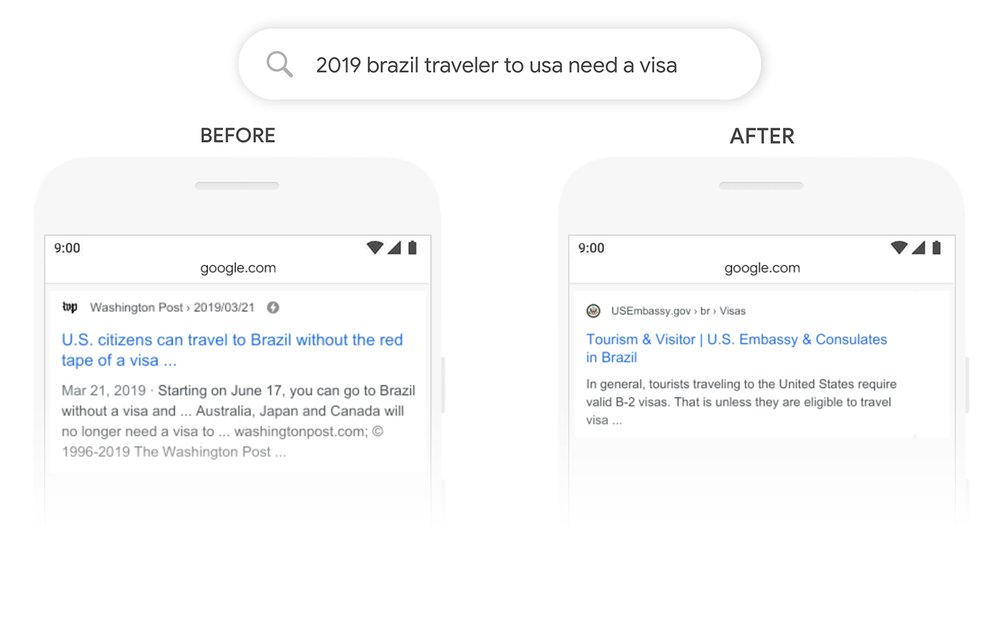
Google에 따르면 이 유기적 검색 결과의 예에서 "to"라는 단어의 중요성과 다른 단어와의 관계는 이전에 과소 평가되었습니다. 그러나 "to"라는 단어는 문장의 의미에서 필수적인 역할을 합니다. 우리는 미국으로 여행 하기 를 원하는 브라질 사람 을 상대하고 있습니다. 그 반대는 아닙니다. 새로운 BERT 모델을 통해 Google은 이러한 구분을 올바르게 이해하고 실제 검색 의도에 해당하는 결과를 제공할 수 있습니다.
예 2: "연석이 없는 언덕에 주차"
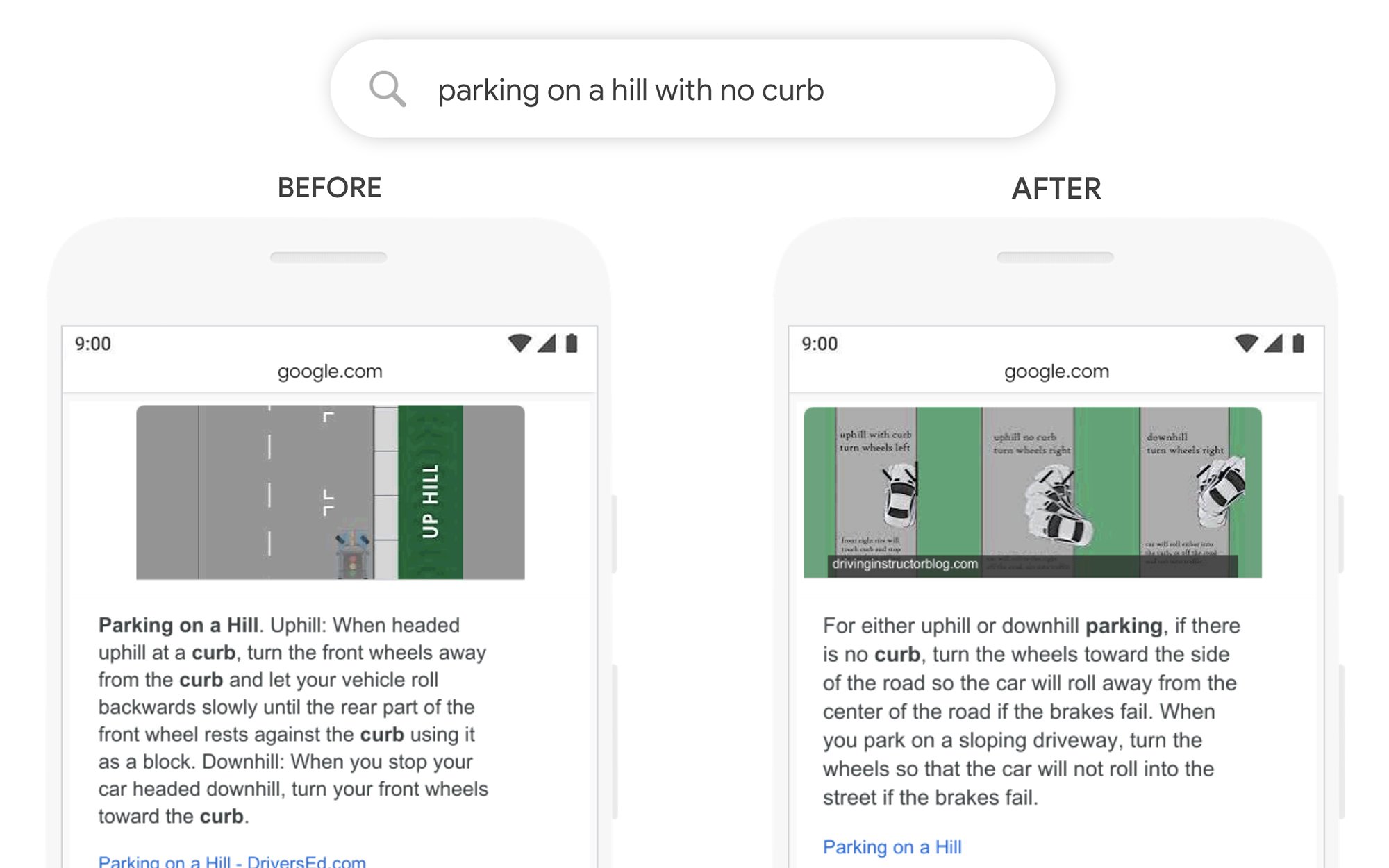
가장 관련성이 높은 추천 스니펫을 선택하기 위해 검색 결과를 평가하는 것을 다루는 Google 블로그 게시물의 이 예에서 초점은 "no"라는 단어의 중요성을 무시하고 "curb"라는 단어에 너무 많이 두었습니다. 이는 검색자가 제기한 질문과 반대되는 질문에 실제로 답변했기 때문에 거의 사용되지 않은 추천 스니펫이 표시되었음을 의미합니다.
SEO와 웹마스터는 무엇을 할 수 있습니까?
BERT에 대응하는 방법에 대한 간단한 답은 없습니다. 갑자기 웹사이트 순위를 높이거나 손실을 복구하는 데 사용할 수 있는 쉬운 전술은 없습니다. 대신, 알고리즘뿐만 아니라 사람들을 위해 콘텐츠를 작성하고 웹사이트를 구축해야 한다는 점을 명심하는 것이 중요합니다. 웹사이트를 방문하고 상호작용할 잠재 사용자와 고객을 위한 것입니다.