
L'importanza della normalizzazione dei dati
Pubblicato: 2021-02-04Le aziende hanno sempre utilizzato i dati per rimanere al top. Quando le aziende lavoravano in negozi fisici, la maggior parte di questa elaborazione dei dati era offline poiché i set di dati erano più piccoli. Poiché sempre più aziende hanno spostato le proprie attività online (o almeno parte di esse), i set di dati sono aumentati di dimensioni e ora raggiungono dimensioni fino a terabyte e petabyte. Questi dataset sono costituiti da:
un). Dati interni che possono contenere dettagli sui prodotti, informazioni sui dipendenti, contratti con i partner, aggiornamenti sulle scorte di magazzino e altro ancora
b). Dati da dispositivi IoT come sensori GPS, robot intelligenti, sensori di tracciamento e gemelli digitali
c). Dati esterni come i dati della concorrenza prelevati dal web
I dati provenienti da origini diverse potrebbero non avere tutti la stessa forma e formato. Puoi avere dati in formato testuale, audio, video e persino tabulare. Dopo averli convertiti tutti in un unico formato strutturato, noterai che non tutti hanno le stesse intestazioni. Anche se lo fanno, le unità potrebbero non essere le stesse. Potrebbero anche essere presenti righe duplicate nei dati.
Che cos'è la normalizzazione dei dati?
L'elaborazione di tutti questi problemi di dati insieme si somma ed è chiamata collettivamente Normalizzazione dei dati. Aiuta principalmente a riorganizzare e utilizzare insieme i dati raccolti da diverse fonti. Migliora inoltre la leggibilità dei dati per il team aziendale e fornisce quindi un approccio più plug and play alla creazione di visualizzazioni dei dati .
La normalizzazione dei dati può comprendere più fasi in cui ciascuna fase può essere ulteriormente suddivisa in fasi diverse per diverse origini dati. Le tecniche o fasi di normalizzazione dei dati più comuni riguardano:
un). Rimozione delle voci duplicate
b). Raggruppamento dei dati in base alla metodologia di raggruppamento logico
c). Creazione di associazioni tra punti dati correlati
d). Risoluzione di voci di dati in conflitto
e). Conversione di diversi set di dati in un unico formato
f). Conversione di dati semistrutturati o non strutturati in set di valori-chiave
g). Consolidamento di dati da più fonti
h). Conversione di tutte le righe di una colonna nelle stesse unità
io). Divisione di colonne con valori numerici grandi per potenze di 10
j). Assegnazione di valori numerici a colonne categoriali
Tali sforzi insieme portano a migliorare la qualità dei dati in generale e aiutano anche a ridurre l'elaborazione richiesta nei flussi di lavoro aziendali in cui questi set di dati vengono eventualmente utilizzati. Tali processi possono essere utilizzati per gestire diversi tipi di campi come nomi, indirizzi, numeri di telefono, codici pin, valori di valuta, distanza tra due punti e altro. Ogni azienda definisce un insieme di formati e regole standard in base ai quali vengono normalizzati tutti i set di dati che entrano nel flusso di dati.
I Dati grezzi possono essere elaborati in diversi modi in base all'insieme delle regole di standardizzazione in atto. Alcuni esempi di standardizzazione dei dati sono riportati nella tabella seguente.
| Dati grezzi | Dati normalizzati |
| 25 parco sud | 25 Parco Sud |
| Sr VP Ad | Vicepresidente senior della pubblicità |
| 1 centimetro | 1 cm |
| 1 piede | 30,48 cm |
| Maschio/Femmina/Altri | M/F/O |
| $ 25 | ₹ 1850 |
E se non normalizzi i tuoi dati?
Sulla base della ricerca condotta da Gartner, quasi il 40% di tutti gli sforzi aziendali viene perso a causa della scarsa qualità dei dati. Dati errati o dati formattati in modo errato influiscono su diverse fasi dei processi aziendali e compromettono l'efficienza operativa e la gestione del rischio. Quando le decisioni basate sui dati si basano su dati errati, la capacità dell'azienda di utilizzare i dati a proprio vantaggio è compromessa. I vantaggi dell'utilizzo dei Big Data per le decisioni aziendali vengono persi quando non si è in grado di standardizzare e adattare diverse origini dati.
Uno dei principali nemici dei dati utilizzabili è la mancanza o la rottura dei dati: le righe in cui non tutti i punti dati potrebbero essere presenti correttamente. Tali problemi possono sorgere a causa di un'errata elaborazione dei dati grezzi oa causa di incongruenze nei dati di origine. L'altro importante problema di dati che rende i dati inutilizzabili è la quantità di dati non strutturati che non sono suddivisi in bit utilizzabili.

Secondo uno studio di Priceonomics, ben il 55% dei dati raccolti dalle aziende rimane inutilizzato . Questi dati inutilizzati che sono stati raccolti dalle aziende ma non possono essere utilizzati a causa di determinati vincoli sono definiti dark-data. Alla domanda sui motivi per cui non è stato possibile utilizzare una frazione così ampia dei dati, il 66% degli intervistati ha scelto "dati mancanti o non funzionanti" come risposta, mentre il 25% ha scelto di lamentarsi dei formati non strutturati.
Poiché le aziende continuano ad aggregare i dati da fonti interne ed esterne, la dimensione netta dei dati continua ad aumentare. Oggi la maggior parte delle aziende utilizza servizi di cloud storage tramite servizi come AWS o GCP ed è facile dimenticare quanto stanno aumentando le tue fatture infra. Sebbene la maggior parte dei servizi ti addebiti in base alle query eseguite e non alle dimensioni dei dati archiviati, dovrai comunque tenere conto di tre cose:
un). All'aumentare del volume di dati, le query dovranno analizzare un numero sempre maggiore di dati e l'esecuzione richiederà più tempo
b). A causa delle query che richiedono più tempo per l'esecuzione, più query eseguite contemporaneamente possono causare un errore di timeout
c). Con l'aumento della quantità di dati analizzati per ogni query, i costi sostenuti per i servizi cloud aumenterebbero costantemente
I vantaggi della normalizzazione dei dati
Uno dei maggiori vantaggi della normalizzazione dei dati è la possibilità di implementare la segmentazione dei dati. La segmentazione dei dati è la capacità di raggruppare i dati in base a parametri diversi in modo che possano essere utilizzati più facilmente da diversi team interni. I dati possono essere segmentati in base a diversi fattori come il sesso dei clienti, l'ubicazione (urbana o rurale), il tipo di settore e altro ancora.
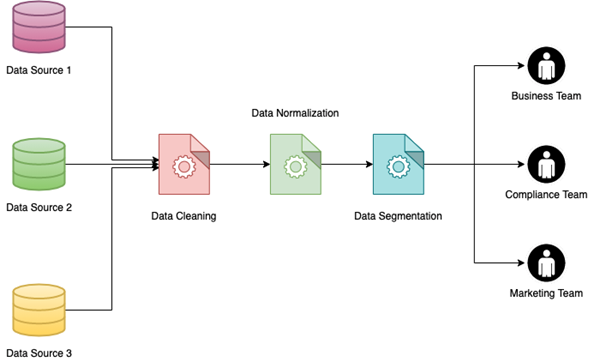
L'implementazione della segmentazione dei dati su un set di dati di grandi dimensioni, in particolare uno che è stato compilato unendo più origini di dati, può essere un compito arduo. Sarà molte volte più facile se i dati sono già stati normalizzati. I vantaggi di questo sono molteplici:
un). Se i dati vengono normalizzati e segmentati, team diversi possono estrarre dati diversi senza preoccuparsi della necessità di filtrare dati sporchi o danneggiati.
b). Le aziende possono utilizzare un approccio pubblicitario e di marketing mirato utilizzando dati segmentati per ottenere tassi di conversione migliori nei loro budget di marketing limitati.
c). I dati segmentati possono anche aiutare le aziende ad analizzare i loro risultati e il feedback dei clienti e capire cosa è andato bene e cosa è andato in discesa. Queste informazioni possono creare o distruggere un'azienda a seconda che vengano consumate o lasciate sul tavolo.
La previsione del comportamento dei clienti e il rilevamento delle anomalie sono alcuni degli obiettivi principali per le grandi imprese che analizzano grandi volumi di dati e cercano di creare modelli predittivi. Gli sforzi alla base di tali sforzi possono essere notevolmente ridotti se i dati grezzi stessi sono stati archiviati dopo la normalizzazione e la standardizzazione. Sia che il tuo team di Data Science stia lavorando a un nuovo modello di machine learning o che il tuo team aziendale stia lavorando per creare un sistema di suggerimenti che possa essere paragonato a quelli di Netflix, i dati puliti e normalizzati sono una necessità assoluta come punto di partenza.
Quanto possono peggiorare le cose?
La normalizzazione dei dati può essere utile quando più team utilizzano la stessa origine dati o comunicano tra loro tramite i dati. Maggiore è il numero di origini dati e maggiore è il numero di team e individui coinvolti, maggiori sono i rischi di dati non normalizzati. Uno dei principali eventi storici che si sono verificati per i dati non normalizzati è stato quello della sonda Marte da 125 milioni di dollari che è andata perduta poiché gli ingegneri non sono riusciti a convertire i valori dal sistema inglese al sistema metrico. Le conversioni di unità per mantenere l'uniformità rimangono una delle principali tecniche di normalizzazione dei dati.
Le tue perdite potrebbero non rappresentare un valore così alto, ma potresti non essere in grado di calcolare le perdite che si verificano a causa di dati disordinati. Si infiltrerebbe lentamente in uno dei motivi principali dell'inutilizzabilità dei dati. Indirettamente, la percentuale di dati inutilizzati presso la tua azienda significherebbe la perdita dovuta al mancato impegno per normalizzare i dati.
Anche se abbiamo parlato molto di normalizzazione e standardizzazione dei dati, il recupero dei dati in modo corretto è metà del lavoro svolto. Se estrai i dati in modo pulito da fonti esterne , i tuoi sforzi per la normalizzazione possono essere notevolmente ridotti. Il nostro team di PromptCloud è orgoglioso di fornire ai clienti una soluzione DaaS (Data as a Service) utilizzando la quale le aziende possono semplicemente fornirci i loro requisiti di scraping web e offriamo i dati in un formato plug and play. Possiamo raccogliere dati da più siti Web e fornire dati da ciascuno in contenitori diversi o tramite API diverse. Una volta fatto, puoi quindi scrivere i tuoi moduli di normalizzazione dei dati per aggregare i dati e arricchirli, consentendo così al tuo team di prendere decisioni basate sui dati.