
數據規範化的重要性
已發表: 2021-02-04公司一直使用數據來保持領先地位。 當企業在實體店中工作時,由於數據集較小,大部分數據處理都是離線的。 隨著越來越多的公司將其業務轉移到網上(或至少部分轉移),數據集的規模不斷擴大,現在達到 TB 和 PB 的規模。 這些數據集由以下部分組成:
一個)。 可能包含產品詳細信息、員工信息、合作夥伴合同、倉庫庫存更新等的內部數據
乙)。 來自物聯網設備的數據,如 GPS 傳感器、智能機器人、跟踪傳感器和數字雙胞胎
C)。 從網絡上抓取的競爭對手數據等外部數據
來自不同來源的數據可能並不都具有相同的形狀和格式。 您可以擁有文本、音頻、視頻甚至表格格式的數據。 將它們全部轉換為單一結構化格式後,您會發現並非所有它們都具有相同的標題。 即使他們這樣做,單位也可能不一樣。 數據中也可能存在重複的行。
什麼是數據規範化?
所有此類數據問題的處理加在一起,統稱為數據規範化。 它主要有助於將來自不同來源的數據進行重組和一起使用。 它還為業務團隊提高了數據的可讀性,從而提供了一種更加即插即用的方法來創建數據可視化。
數據規範化可以包括多個階段,其中每個階段可以進一步分為針對不同數據源的不同步驟。 最常見的數據規範化技術或階段包括:
一個)。 刪除重複條目
乙)。 基於邏輯分組方法對數據進行分組
C)。 在相關數據點之間創建關聯
d)。 解決衝突的數據條目
e)。 將不同的數據集轉換為單一格式
F)。 半結構化或非結構化數據到鍵值集的轉換
G)。 整合來自多個來源的數據
H)。 將列中的所有行轉換為相同的單位
一世)。 將具有大數值的列除以 10 的冪
j)。 為分類列分配數值
這些努力共同導致總體數據質量的提高,也有助於減少最終使用這些數據集的業務工作流程中所需的處理。 此類過程可用於處理不同類型的字段,例如姓名、地址、電話號碼、pin 碼、貨幣值、兩點之間的距離等。 每家公司都定義了一組標準格式和規則,根據這些格式和規則對進入數據流的所有數據集進行規範化。
原始數據可以根據現有的標準化規則集以不同的方式進行處理。 下表顯示了一些數據標準化的示例。
| 原始數據 | 標準化數據 |
| 25 南公園 | 25 南方公園 |
| 高級副總裁廣告 | 廣告高級副總裁 |
| 1 厘米 | 1厘米 |
| 1 英尺 | 30.48cm |
| 男/女/其他 | 中/下/下 |
| 25 美元 | ¥1850 |
如果你不規範化你的數據怎麼辦?
根據 Gartner 進行的研究,由於數據質量差,幾乎40% 的業務努力都白費了。 不良數據或格式錯誤的數據會影響業務流程的不同階段,並損害運營效率和風險管理。 當數據支持的決策基於錯誤數據時,企業利用數據發揮自身優勢的能力就會受到影響。 當您無法標準化和適應不同的數據源時,將失去使用大數據進行業務決策的好處。

可用數據的主要敵人之一是丟失或損壞的數據——並非所有數據點都正確存在的行。 由於原始數據處理不正確或源數據不一致,可能會出現此類問題。 導致數據不可用的另一個主要數據問題是未分解為可用位的非結構化數據量。
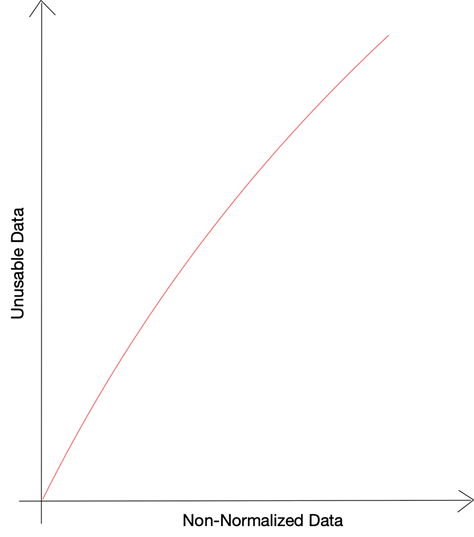
根據 Priceonomics 的一項研究,公司收集的數據中有多達 55% 未被使用。 這種由公司收集但由於某些限製而無法使用的未使用數據被稱為暗數據。 當被問及無法使用這麼大一部分數據的原因時,66% 的受訪者選擇“丟失或損壞的數據”作為答案,而 25% 的受訪者選擇抱怨非結構化格式。
隨著公司不斷匯總來自內部和外部來源的數據,淨數據規模不斷增加。 如今,大多數公司都通過 AWS 或 GCP 等服務使用雲存儲服務,很容易忘記您的基礎設施賬單有多大。 雖然大多數服務根據您執行的查詢而不是存儲的數據大小向您收費,但您仍然需要考慮三件事:
一個)。 隨著數據量的增長,查詢將需要解析越來越多的數據並且執行時間會更長
乙)。 由於查詢執行時間較長,多個查詢同時運行可能會導致超時錯誤
C)。 隨著每次查詢解析的數據量增加,雲服務產生的成本將穩步上升
數據規範化的好處
數據規範化的最大好處之一是實現數據分割的能力。 數據分段是基於不同參數對數據進行分組的能力,以便不同的內部團隊可以更輕鬆地使用它們。 數據可以按客戶性別、位置(城市或農村)、行業類型等不同因素進行細分。
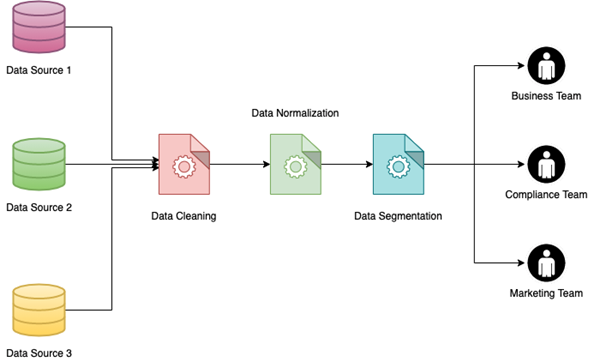
在大型數據集上實施數據分割,尤其是通過連接多個數據源編譯的數據集,可能是一項艱鉅的任務。 如果數據已經標準化,這將容易很多倍。 這樣做的好處是多方面的:
一個)。 如果數據被規範化和分段,不同的團隊可以提取不同的數據,而不用擔心需要過濾不干淨或損壞的數據。
乙)。 公司可以使用有針對性的廣告和營銷方法,使用分段數據,在其有限的營銷預算中獲得更好的轉化率。
C)。 分段數據還可以幫助公司分析他們的結果和客戶反饋,並了解什麼是正確的,什麼是走下坡路。 這些信息可以根據是否被消費或留在桌子上來決定公司的成敗。
預測客戶行為和檢測異常是分析大量數據並嘗試創建預測模型的大型企業的一些主要目標。 如果原始數據本身已經在標準化和標準化之後存儲,則可以大大減少這些努力背後的努力。 無論您的數據科學團隊正在開發新的機器學習模型,還是您的業務團隊正在構建一個可以與 Netflix 相媲美的推薦系統,乾淨和規範化的數據都是絕對必要的起點。
事情會變得多糟糕?
當多個團隊使用相同的數據源或通過數據在他們之間進行通信時,數據規範化會很有幫助。 數據源數量越多,涉及的團隊和個人越多,非規範化數據的風險就越高。 非標準化數據發生的主要歷史事件之一是價值 1.25 億美元的火星探測器,由於工程師未能將值從英制轉換為公制,該探測器丟失了。 保持一致性的單位轉換仍然是核心數據規範化技術之一。
您的損失可能算不上這麼高的價值,但您可能無法計算由於數據混亂而發生的損失。 它會慢慢滲透到數據不可用的主要原因之一。 間接地,貴公司未使用數據的百分比表示由於未努力規範數據而造成的損失。
雖然我們談了很多關於數據的規範化和標準化,但正確地獲取數據本身就是完成了一半的工作。 如果您從外部來源乾淨地抓取數據,則可以大大減少標準化工作。 我們在 PromptCloud 的團隊以為客戶提供 DaaS(數據即服務)解決方案而自豪,公司可以使用該解決方案向我們提供他們的網絡抓取要求,我們以即插即用的格式提供數據。 我們可以從多個網站抓取數據,並在不同的容器中或通過不同的 API 提供來自每個網站的數據。 完成此操作後,您可以編寫數據規範化模塊來聚合數據並豐富它們——從而使您的團隊能夠做出數據支持的決策。