
La importancia de la normalización de datos
Publicado: 2021-02-04Las empresas siempre han utilizado los datos para mantenerse en la cima. Cuando las empresas trabajaban fuera de las tiendas físicas, la mayor parte de este procesamiento de datos se realizaba fuera de línea, ya que los conjuntos de datos eran más pequeños. A medida que más empresas han movido sus negocios en línea (o al menos partes de ellos), los conjuntos de datos han crecido en tamaño y ahora alcanzan tamaños de hasta terabytes y petabytes. Estos conjuntos de datos están compuestos por:
a). Datos internos que pueden contener detalles de productos, información de empleados, contratos de socios, actualizaciones de existencias en almacén y más
b). Datos de dispositivos IoT como sensores GPS, robots inteligentes, sensores de seguimiento y gemelos digitales
C). Datos externos, como datos de la competencia extraídos de la web
Es posible que no todos los datos de diferentes fuentes tengan la misma forma y formato. Puede tener datos en formato de texto, audio, video e incluso tabular. Una vez que los haya convertido todos a un solo formato estructurado, notará que no todos tienen los mismos encabezados. Incluso si lo hacen, las unidades pueden no ser las mismas. También puede haber filas duplicadas presentes en los datos.
¿Qué es la normalización de datos?
El procesamiento de todos estos problemas de datos juntos se suma y se denomina colectivamente Normalización de datos. Principalmente ayuda en los datos recopilados de diferentes fuentes para ser reorganizados y utilizados juntos. También mejora la legibilidad de los datos para el equipo comercial y, por lo tanto, proporciona un enfoque más práctico para crear visualizaciones de datos .
La normalización de datos puede comprender múltiples etapas en las que cada etapa se puede dividir en diferentes pasos para diferentes fuentes de datos. Las técnicas o etapas de normalización de datos más comunes involucran:
a). Eliminación de entradas duplicadas
b). Agrupación de datos basada en la metodología de agrupación lógica
C). Crear asociaciones entre puntos de datos relacionados
d). Resolución de entradas de datos en conflicto
mi). Conversión de diferentes conjuntos de datos a un solo formato
F). Conversión de datos semiestructurados o no estructurados en conjuntos de clave-valor
gramo). Consolidación de datos de múltiples fuentes
h). Conversión de todas las filas de una columna a las mismas unidades
i). Dividir columnas con valores numéricos grandes por potencias de 10
j). Asignación de valores numéricos a columnas categóricas
Dichos esfuerzos en conjunto conducen a mejorar la calidad de los datos en general y también ayudan a reducir el procesamiento requerido en los flujos de trabajo comerciales donde estos conjuntos de datos finalmente se utilizan. Dichos procesos se pueden usar para manejar diferentes tipos de campos, como nombres, direcciones, números de teléfono, códigos PIN, valores de moneda, la distancia entre dos puntos y más. Cada empresa define un conjunto de formatos y reglas estándar según los cuales se normalizan todos los conjuntos de datos que ingresan al flujo de datos.
Los datos sin procesar se pueden procesar de diferentes maneras según el conjunto de reglas de estandarización vigentes. En la siguiente tabla se muestran algunos ejemplos de estandarización de datos.
| Datos sin procesar | Datos normalizados |
| 25 parque sur | 25 parque sur |
| Anuncio de vicepresidente sénior | Vicepresidente sénior de Publicidad |
| 1 centímetro | 1cm |
| 1 pie | 30,48 cm |
| Hombre/Mujer/Otros | H/F/O |
| $25 | $ 1850 |
¿Qué sucede si no normaliza sus datos?
Según una investigación realizada por Gartner, casi el 40 % de todos los esfuerzos comerciales se pierden debido a la mala calidad de los datos. Los datos erróneos o los datos mal formateados afectan las diferentes etapas de los procesos comerciales y perjudican la eficiencia operativa, así como la gestión de riesgos. Cuando las decisiones respaldadas por datos se basan en datos erróneos, la capacidad de la empresa para utilizar los datos en beneficio propio se ve comprometida. Los beneficios de usar Big Data para tomar decisiones comerciales se pierden cuando no puede estandarizar y adaptarse a diferentes fuentes de datos.
Uno de los principales enemigos de los datos utilizables son los datos perdidos o rotos: filas en las que no todos los puntos de datos pueden estar presentes correctamente. Dichos problemas pueden surgir debido a un procesamiento incorrecto de los datos sin procesar o debido a inconsistencias en los datos de origen. El otro problema importante de datos que hace que los datos sean inutilizables es la cantidad de datos no estructurados que no se dividen en bits utilizables.

Según un estudio de Priceonomics, hasta el 55 % de los datos recopilados por las empresas no se utilizan . Estos datos no utilizados que fueron recopilados por las empresas pero que no pudieron usarse debido a ciertas limitaciones se denominan datos oscuros. Cuando se les preguntó por las razones detrás de no poder usar una fracción tan grande de los datos, el 66% de los encuestados eligió como respuesta "datos faltantes o rotos", mientras que el 25% eligió quejarse de los formatos no estructurados.
A medida que las empresas siguen agregando datos de fuentes internas y externas, el tamaño de los datos netos sigue aumentando. Hoy en día, la mayoría de las empresas utilizan servicios de almacenamiento en la nube de servicios como AWS o GCP y es fácil olvidar lo grandes que son sus facturas de infraestructura. Si bien la mayoría de los servicios le cobran en función de las consultas que realiza y no del tamaño de los datos almacenados, aún deberá tener en cuenta tres cosas:
a). A medida que crece el volumen de datos, las consultas deberán analizar cada vez más datos y tardarán más en ejecutarse.
b). Como efecto de que las consultas tardan más en ejecutarse, varias consultas que se ejecutan al mismo tiempo pueden provocar un error de tiempo de espera.
C). A medida que aumenta la cantidad de datos que se analizan para cada consulta, los costos incurridos por los servicios en la nube aumentarían constantemente
Los beneficios de la normalización de datos
Uno de los mayores beneficios de la normalización de datos es la capacidad de implementar la segmentación de datos. La segmentación de datos es la capacidad de agrupar datos en función de diferentes parámetros para que puedan ser utilizados más fácilmente por diferentes equipos internos. Los datos se pueden segmentar por diferentes factores como el género de los clientes, la ubicación (urbana o rural), el tipo de industria y más.
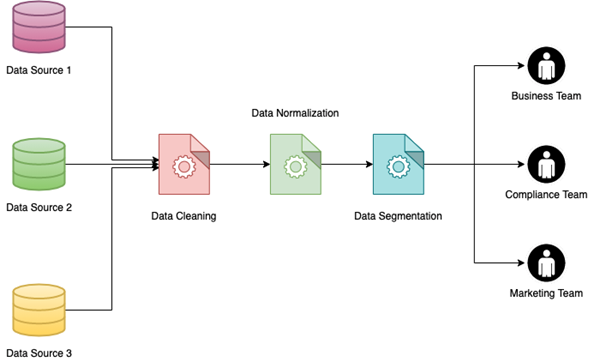
Implementar la segmentación de datos en un gran conjunto de datos, especialmente uno que se haya compilado al unir varias fuentes de datos, puede ser una tarea abrumadora. Sin embargo, será mucho más fácil si los datos ya se han normalizado. Los beneficios de esto son múltiples:
a). Si los datos se normalizan y segmentan, diferentes equipos pueden extraer datos diferentes sin preocuparse por la necesidad de filtrar datos sucios o rotos.
b). Las empresas pueden utilizar un enfoque de publicidad y marketing dirigido utilizando datos segmentados para obtener mejores tasas de conversión en sus presupuestos de marketing limitados.
C). Los datos segmentados también pueden ayudar a las empresas a analizar sus resultados y los comentarios de los clientes y comprender qué salió bien y qué salió mal. Esta información puede hacer o deshacer una empresa en función de si se consume o se deja sobre la mesa.
Pronosticar el comportamiento de los clientes y detectar anomalías son algunos de los principales objetivos de las grandes empresas que analizan grandes volúmenes de datos e intentan crear modelos predictivos. Los esfuerzos detrás de tales esfuerzos se pueden minimizar en gran medida si los propios datos sin procesar se han almacenado después de la normalización y estandarización. Ya sea que su equipo de ciencia de datos esté trabajando en un nuevo modelo de aprendizaje automático o que su equipo comercial esté trabajando para crear un sistema de recomendación que se compare con el de Netflix, los datos limpios y normalizados son una necesidad absoluta como punto de partida.
¿Qué tan mal pueden ponerse las cosas?
La normalización de datos puede ser útil cuando varios equipos usan la misma fuente de datos o se comunican entre ellos a través de datos. Cuanto mayor sea el número de fuentes de datos y mayor el número de equipos e individuos involucrados, mayores serán los riesgos de los datos no normalizados. Uno de los principales eventos históricos que ocurrieron con los datos no normalizados fue el de la sonda de Marte de $ 125 millones que se perdió porque los ingenieros no pudieron convertir los valores del sistema inglés al sistema métrico. Las conversiones de unidades para mantener la uniformidad siguen siendo una de las principales técnicas de normalización de datos.
Es posible que sus pérdidas no representen un valor tan alto, pero es posible que no pueda calcular las pérdidas que se producen debido a la confusión de datos. Lentamente se filtraría en una de las principales razones de la inutilización de los datos. Indirectamente, el porcentaje de datos no utilizados en su empresa significaría la pérdida por no esforzarse en normalizar los datos.
Si bien hablamos mucho sobre la normalización y la estandarización de los datos, obtener los datos correctamente en sí mismo es la mitad del trabajo realizado. Si extrae datos limpiamente de fuentes externas , sus esfuerzos para la normalización pueden reducirse considerablemente. Nuestro equipo en PromptCloud se enorgullece de brindarles a los clientes una solución DaaS (datos como servicio) mediante la cual las empresas pueden proporcionarnos sus requisitos de web scraping y nosotros ofrecemos los datos en un formato plug and play. Podemos extraer datos de varios sitios web y proporcionar datos de cada uno en diferentes contenedores o mediante diferentes API. Una vez hecho esto, puede escribir sus módulos de normalización de datos para agregar los datos y enriquecerlos, lo que permite a su equipo tomar decisiones respaldadas por datos.