
数据规范化的重要性
已发表: 2021-02-04公司一直使用数据来保持领先地位。 当企业在实体店中工作时,由于数据集较小,大部分数据处理都是离线的。 随着越来越多的公司将其业务转移到网上(或至少部分转移),数据集的规模不断扩大,现在达到 TB 和 PB 的规模。 这些数据集由以下部分组成:
一个)。 可能包含产品详细信息、员工信息、合作伙伴合同、仓库库存更新等的内部数据
乙)。 来自物联网设备的数据,如 GPS 传感器、智能机器人、跟踪传感器和数字双胞胎
C)。 从网络上抓取的竞争对手数据等外部数据
来自不同来源的数据可能并不都具有相同的形状和格式。 您可以拥有文本、音频、视频甚至表格格式的数据。 将它们全部转换为单一结构化格式后,您会发现并非所有它们都具有相同的标题。 即使他们这样做,单位也可能不一样。 数据中也可能存在重复的行。
什么是数据规范化?
所有此类数据问题的处理加在一起,统称为数据规范化。 它主要有助于将来自不同来源的数据进行重组和一起使用。 它还为业务团队提高了数据的可读性,从而提供了一种更加即插即用的方法来创建数据可视化。
数据规范化可以包括多个阶段,其中每个阶段可以进一步分为针对不同数据源的不同步骤。 最常见的数据规范化技术或阶段包括:
一个)。 删除重复条目
乙)。 基于逻辑分组方法对数据进行分组
C)。 在相关数据点之间创建关联
d)。 解决冲突的数据条目
e)。 将不同的数据集转换为单一格式
F)。 半结构化或非结构化数据到键值集的转换
G)。 整合来自多个来源的数据
H)。 将列中的所有行转换为相同的单位
一世)。 将具有大数值的列除以 10 的幂
j)。 为分类列分配数值
这些努力共同导致总体数据质量的提高,也有助于减少最终使用这些数据集的业务工作流程中所需的处理。 此类过程可用于处理不同类型的字段,例如姓名、地址、电话号码、pin 码、货币值、两点之间的距离等。 每家公司都定义了一组标准格式和规则,根据这些格式和规则对进入数据流的所有数据集进行规范化。
原始数据可以根据现有的标准化规则集以不同的方式进行处理。 下表显示了一些数据标准化的示例。
| 原始数据 | 标准化数据 |
| 25 南公园 | 25 南方公园 |
| 高级副总裁广告 | 广告高级副总裁 |
| 1 厘米 | 1厘米 |
| 1 英尺 | 30.48cm |
| 男/女/其他 | 中/下/下 |
| 25 美元 | ¥1850 |
如果你不规范化你的数据怎么办?
根据 Gartner 进行的研究,由于数据质量差,几乎40% 的业务努力都白费了。 不良数据或格式错误的数据会影响业务流程的不同阶段,并损害运营效率和风险管理。 当数据支持的决策基于错误数据时,企业利用数据发挥自身优势的能力就会受到影响。 当您无法标准化和适应不同的数据源时,将失去使用大数据进行业务决策的好处。

可用数据的主要敌人之一是丢失或损坏的数据——并非所有数据点都正确存在的行。 由于原始数据处理不正确或源数据不一致,可能会出现此类问题。 导致数据不可用的另一个主要数据问题是未分解为可用位的非结构化数据量。
根据 Priceonomics 的一项研究,公司收集的数据中有多达 55% 未被使用。 这种由公司收集但由于某些限制而无法使用的未使用数据被称为暗数据。 当被问及无法使用这么大一部分数据的原因时,66% 的受访者选择“丢失或损坏的数据”作为答案,而 25% 的受访者选择抱怨非结构化格式。
随着公司不断汇总来自内部和外部来源的数据,净数据规模不断增加。 如今,大多数公司都通过 AWS 或 GCP 等服务使用云存储服务,很容易忘记您的基础设施账单有多大。 虽然大多数服务根据您执行的查询而不是存储的数据大小向您收费,但您仍然需要考虑三件事:
一个)。 随着数据量的增长,查询将需要解析越来越多的数据并且执行时间会更长
乙)。 由于查询执行时间较长,多个查询同时运行可能会导致超时错误
C)。 随着每次查询解析的数据量增加,云服务产生的成本将稳步上升
数据规范化的好处
数据规范化的最大好处之一是实现数据分割的能力。 数据分段是基于不同参数对数据进行分组的能力,以便不同的内部团队可以更轻松地使用它们。 数据可以按客户性别、位置(城市或农村)、行业类型等不同因素进行细分。
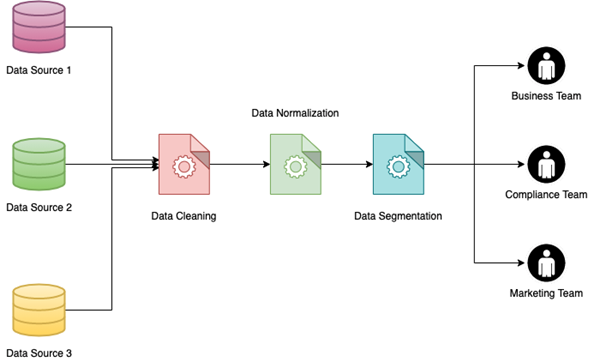
在大型数据集上实施数据分割,尤其是通过连接多个数据源编译的数据集,可能是一项艰巨的任务。 如果数据已经标准化,这将容易很多倍。 这样做的好处是多方面的:
一个)。 如果数据被规范化和分段,不同的团队可以提取不同的数据,而不用担心需要过滤不干净或损坏的数据。
乙)。 公司可以使用有针对性的广告和营销方法,使用分段数据,在其有限的营销预算中获得更好的转化率。
C)。 分段数据还可以帮助公司分析他们的结果和客户反馈,并了解什么是正确的,什么是走下坡路。 这些信息可以根据是否被消费或留在桌子上来决定公司的成败。
预测客户行为和检测异常是分析大量数据并尝试创建预测模型的大型企业的一些主要目标。 如果原始数据本身已经在标准化和标准化之后存储,则可以大大减少这些努力背后的努力。 无论您的数据科学团队正在开发新的机器学习模型,还是您的业务团队正在构建一个可以与 Netflix 相媲美的推荐系统,干净和规范化的数据都是绝对必要的起点。
事情会变得多糟糕?
当多个团队使用相同的数据源或通过数据在他们之间进行通信时,数据规范化会很有帮助。 数据源数量越多,涉及的团队和个人越多,非规范化数据的风险就越高。 非标准化数据发生的主要历史事件之一是价值 1.25 亿美元的火星探测器,由于工程师未能将值从英制转换为公制,该探测器丢失了。 保持一致性的单位转换仍然是核心数据规范化技术之一。
您的损失可能算不上这么高的价值,但您可能无法计算由于数据混乱而发生的损失。 它会慢慢渗透到数据不可用的主要原因之一。 间接地,贵公司未使用数据的百分比表示由于未努力规范数据而造成的损失。
虽然我们谈了很多关于数据的规范化和标准化,但正确地获取数据本身就是完成了一半的工作。 如果您从外部来源干净地抓取数据,则可以大大减少标准化工作。 我们在 PromptCloud 的团队以为客户提供 DaaS(数据即服务)解决方案而自豪,公司可以使用该解决方案向我们提供他们的网络抓取要求,我们以即插即用的格式提供数据。 我们可以从多个网站抓取数据,并在不同的容器中或通过不同的 API 提供来自每个网站的数据。 完成此操作后,您可以编写数据规范化模块来聚合数据并丰富它们——从而使您的团队能够做出数据支持的决策。