
Machine Learning vs Analisi Predittiva: Differenza e Utilizzo
Pubblicato: 2021-01-12Apprendimento automatico
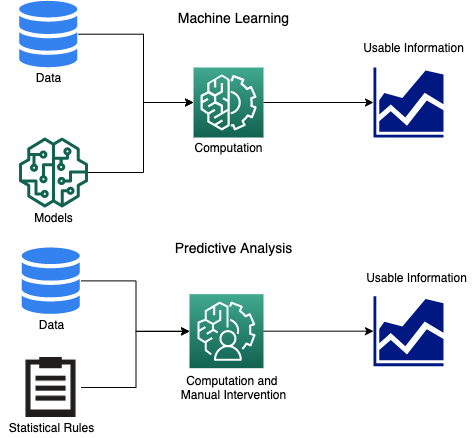
L'apprendimento automatico è una tecnica computazionale in cui è possibile utilizzare diversi algoritmi per generare modelli dai dati in tempo reale. Questi modelli vengono quindi utilizzati per produrre risultati di consumo da dati aggiornati. Man mano che più dati vengono inseriti nel sistema nel tempo, il modello si evolve automaticamente in base ai nuovi apprendimenti. L'apprendimento automatico richiede grandi quantità di dati per funzionare correttamente e fornire risultati più accurati. La crescita dei dati, generati da fonti come IoT e web scraping, ha contribuito a potenziare l'apprendimento automatico.
Sebbene in teoria sia possibile eseguire qualsiasi algoritmo su qualsiasi set di dati, per ottenere i migliori risultati è necessario valutare prima il tipo e il formato dei dati. L'apprendimento automatico consente l'elaborazione dei dati in tempo reale e la maggior parte dei modelli consuma un flusso continuo di dati e cresce autonomamente.
Il termine Machine Learning può essere utilizzato sia per l'apprendimento supervisionato che per quello non supervisionato. Nell'apprendimento supervisionato, il set di dati è contrassegnato e il modello viene prima eseguito sui dati contrassegnati per imparare da esso. Quindi viene eseguito su dati senza tag, per produrre previsioni. Nel caso dell'apprendimento non supervisionato, tutti i dati sono privi di tag e gli algoritmi di solito utilizzano punti dati diversi per trovare modelli, somiglianze e differenze nel set di dati. Puoi capire la differenza attraverso un caso d'uso di ciascuno:
un). In Supervised Learning, puoi addestrare la tua macchina su immagini etichettate di cani e gatti e, una volta addestrata, puoi inserire immagini senza etichetta di cani e gatti e testare le capacità predittive della macchina.
b). Nell'apprendimento non supervisionato, forniresti più immagini senza etichetta di cani e gatti e verificheresti se la macchina può separarli.
Analisi predittiva
L'uso dell'analisi predittiva esiste da molto prima dell'inizio dell'IA o persino della crescita delle moderne macchine computazionali. Implica la compressione di grandi quantità di dati che saranno più leggibili dall'uomo. Nella sua forma più semplice, può essere il calcolo di medie, conteggi o mediane. Di solito viene utilizzato per trovare una risposta a una domanda specifica come:
un). Quali sono le categorie più vendute sui siti di eCommerce in inverno?
b). Quali sono le parole chiave che possono essere incluse in un articolo per assicurarsi che raggiunga un vasto pubblico?
Sebbene implichi lo studio di dati storici e attuali, lo stress è principalmente su un ampio set di dati storici e non può essere utilizzato su un flusso continuo di dati. Qualsiasi analisi predittiva combina tre componenti principali:
un). Dati: la qualità, la quantità e l'ampiezza dei dati definiranno il successo di un'analisi predittiva. Nel caso in cui i dati non siano sufficienti su uno di questi 3 fronti, è probabile che vedremo un risultato distorto.
b). Presupposti: anche prima che venga condotto uno studio, ci sono alcune ipotesi fatte sui dati a portata di mano. Ad esempio, se si calcolano le vendite cumulative degli ultimi 10 anni per scoprire la possibile crescita nell'anno in corso, si presume che le metriche di crescita seguiranno lo stesso schema.
c). Tecniche statistiche: le tecniche di apprendimento statistico come la regressione e gli alberi decisionali costituiscono il calcolo di base necessario per consumare i dati a portata di mano, e quindi comprendere queste tecniche è un must prima di gestire i dati.
Che è migliore?
Sia l'apprendimento automatico che l'analisi predittiva sono tecniche computazionali ed entrambe vengono eseguite oggi su macchine. Sarebbe difficile stabilire quale sia il migliore poiché entrambi affrontano affermazioni di problemi diverse. Possiamo tuttavia discutere alcuni dei pro e dei contro di ciascuno.
L'apprendimento automatico è una scienza più avanzata e può essere utilizzata su quasi tutti i tipi di dati, che si tratti di immagini satellitari o di un set di dati di dettagli degli studenti. La quantità di dati che fornisci a un modello di Machine Learning e la sua pulizia insieme determinano le prestazioni del tuo modello nella vita reale.
L'analisi predittiva è più adatta per le affermazioni di problemi in cui hai già una domanda e una breve comprensione di dove i dati possono portarti. Di solito è guidato da dati storici. Tuttavia, nei casi in cui tali dati non siano disponibili, o se è probabile che le tendenze storiche non corrispondano ai dati attuali, a causa di alcune deviazioni, possono rivelarsi inutilizzabili.
| Apprendimento automatico | Analisi predittiva |
| Utilizza modelli di algoritmi, creati utilizzando i dati di addestramento | Utilizza un insieme di regole predefinite che possono essere aggiornate |
| Può adattarsi automaticamente e imparare da nuovi dati | Di solito deve essere ottimizzato per gestire casi limite e modifiche |
| Puoi utilizzare uno degli algoritmi preesistenti che meglio si adatta ai dati a portata di mano | Devi scrivere il codice per il tuo caso d'uso specifico |
| Può essere eseguito senza dati storici, poiché può essere eseguito anche su un flusso di dati live | I dati storici sono necessari prima di creare una serie di regole |
| Soluzione basata sui dati | Soluzione basata su casi d'uso |
| I modelli di Machine Learning possono richiedere più tempo per essere pronti | I modelli di analisi predittiva possono essere pronti per il test molto più velocemente |
Tabella: Analisi predittiva vs Machine Learning

Poiché l'analisi predittiva implica lo studio di dati storici, è possibile generare rapidamente inferenze o modelli e applicarli ai dati correnti. D'altra parte, i modelli di Machine Learning di solito devono essere addestrati su un flusso di dati per un periodo prolungato per essere in grado di gestire i casi limite e migliorarne l'accuratezza.
Lo svantaggio è l'incapacità del modello di analisi predittiva di adattarsi alle variazioni nei flussi di dati. Le deviazioni nei dati possono rendere inutilizzabile un modello di analisi predittiva e il team dei dati dovrebbe tornare alla tabella per apportare alcune modifiche manuali. I modelli di Machine Learning, durante l'addestramento su un flusso di dati diversificato e continuo, possono adattarsi facilmente ai cambiamenti o alle deviazioni presenti nei dati.
La sovrapposizione
Il miglioramento delle previsioni e dell'adattamento in tempo reale è integrato nella progettazione dei modelli di Machine Learning. D'altra parte, Predictive Analytics funziona su un set di dati statico e qualsiasi modifica nel set di dati richiede la ricalibrazione di diversi parametri. La principale differenza sta nel fatto che nel caso dell'analisi predittiva si fa affidamento sull'intervento umano per interpretare i risultati e le associazioni.
Tuttavia, in alcuni casi, l'analisi predittiva può sfruttare Machine Learning per generare risultati più accurati e in uno scenario del genere può diventare un sottoinsieme di Machine Learning. Se hai già una specifica dichiarazione di problema ma non sei sicuro della direzione, Machine Learning può produrre informazioni utili. In un processo diverso, Machine Learning può essere utilizzato anche per elaborare i dati grezzi e produrre un set di dati più fruibile che può quindi essere utilizzato per l'analisi predittiva.
Tuttavia, in alcuni casi, l'analisi predittiva può sfruttare Machine Learning per generare risultati più accurati e in uno scenario del genere può diventare un sottoinsieme di Machine Learning. Se hai già una specifica dichiarazione di problema ma non sei sicuro della direzione, Machine Learning può produrre informazioni utili. In un processo diverso, Machine Learning può essere utilizzato anche per elaborare i dati grezzi e produrre un set di dati più fruibile che può quindi essere utilizzato per l'analisi predittiva.
Quali sono i casi d'uso?
UN). Campagne di marketing
Le campagne di marketing sono diventate digitali nel tentativo di aumentare i tassi di conversione e ridurre le spese. Le campagne di marketing mirate di solito utilizzano l'analisi predittiva per consumare dati del passato e dati di campagne condotte da altre società. Le aziende utilizzano anche i dati demografici degli utenti come posizione, età, sesso, stato civile, data di nascita, per mostrare i prodotti al cliente giusto al momento giusto.
La cronologia delle ricerche precedenti e i modelli di acquisto vengono utilizzati anche per decidere quali prodotti mostrare ai clienti. In questo modo, sulla home page non vengono mostrati a due clienti gli stessi prodotti.
B). Gestione del magazzino
Le grandi aziende di e-commerce utilizzano le informazioni relative alla cronologia delle ricerche e ai modelli di acquisto precedenti per decidere quali articoli conservare in quale magazzino, soprattutto quando hanno più magazzini sparsi in città o paesi. Queste ottimizzazioni non solo riducono i costi per l'azienda, ma assicurano anche che i tempi di consegna dei prodotti siano più brevi per i clienti.
L'apprendimento automatico ha visto una rapida crescita e algoritmi come le reti neurali hanno visto usi importanti come il rilevamento delle cellule tumorali e la previsione delle vendite. Alcuni dei principali casi d'uso di Machine Learning oggigiorno includono:
un). Riconoscimento delle immagini
b). Riconoscimento vocale
c). Previsione del traffico
d). Bot autonomi
e). Filtraggio spam e malware
f). Assistenti virtuali
g). Intercettazione di una frode
h). Diagnosi medica
Dove puoi ottenere i dati?
Di solito, lo stesso team di Data Science di un'azienda tecnologica lavora sia sull'apprendimento automatico che sull'analisi predittiva e li applica in base alla dichiarazione del problema in questione. Indipendentemente dal processo applicato, non è possibile ottenere nulla senza i dati corretti.
Il Web Scraping è uno dei modi più popolari per raccogliere dati oggi e i provider DaaS come PromptCloud aiutano i propri clienti a ottenere i dati giusti per diversi tipi di obiettivi. Il nostro team rende la raccolta dei dati un processo in due fasi: tu ci fornisci i requisiti e noi ti forniamo i dati. Indipendentemente dall'algoritmo utilizzato e dalla tecnologia utilizzata, il nostro feed di dati pulito può consentire alla tua azienda di stare al passo con i tempi.