
データ正規化の重要性
公開: 2021-02-04企業は常にデータを使用してトップを維持してきました。 企業が実店舗で働いていたとき、データセットが小さかったため、このデータ処理のほとんどはオフラインで行われていました。 より多くの企業がビジネスをオンライン (または少なくともその一部) に移行するにつれて、データセットのサイズが大きくなり、現在では最大でテラバイトおよびペタバイトのサイズに達しています。 これらのデータセットは、次のもので構成されています。
a)。 製品の詳細、従業員情報、パートナー契約、倉庫在庫の更新などを含む内部データ
b)。 GPS センサー、スマート ロボット、追跡センサー、デジタル ツインなどの IoT デバイスからのデータ
c)。 ウェブからスクレイピングした競合他社のデータなどの外部データ
異なるソースからのデータは、すべてが同じ形状と形式であるとは限りません。 テキスト、オーディオ、ビデオ、さらには表形式のデータを使用できます。 それらすべてを 1 つの構造化された形式に変換すると、すべてのヘッダーが同じではないことがわかります。 たとえそうであっても、単位は同じではないかもしれません。 データに重複する行が存在する場合もあります。
データの正規化とは?
このようなすべてのデータの問題をまとめて処理することをまとめて、データの正規化と呼びます。 主に、さまざまなソースから収集されたデータを再編成して一緒に使用するのに役立ちます。 また、ビジネス チームにとってデータの読みやすさが向上するため、データの視覚化を作成するためのよりプラグ アンド プレイのアプローチが提供されます。
データの正規化は複数の段階を含む場合があり、各段階はさらに異なるデータ ソースの異なるステップに分割される場合があります。 最も一般的なデータ正規化の手法または段階には、次のものが含まれます。
a)。 重複エントリの削除
b)。 論理グループ化方法に基づくデータのグループ化
c)。 関連するデータ ポイント間の関連付けの作成
d)。 競合するデータ エントリの解決
e)。 異なるデータセットを単一の形式に変換する
f)。 半構造化データまたは非構造化データのキー値セットへの変換
g)。 複数のソースからのデータの統合
h)。 列内のすべての行を同じ単位に変換する
私)。 大きな数値を含む列を 10 の累乗で除算する
j)。 カテゴリ列への数値の割り当て
このような取り組みは、一般的にデータの品質の向上につながり、これらのデータセットが最終的に使用されるビジネス ワークフローで必要な処理を減らすのにも役立ちます。 このようなプロセスを使用して、名前、住所、電話番号、暗証番号、通貨値、2 地点間の距離など、さまざまな種類のフィールドを処理できます。 すべての企業は、データ ストリームに入るすべてのデータ セットを正規化するための一連の標準フォーマットとルールを定義しています。
生データは、一連の標準化ルールに基づいてさまざまな方法で処理できます。 以下の表に、データの標準化の例をいくつか示します。
| 生データ | 正規化されたデータ |
| 25 サウスパーク | 25 サウスパーク |
| 上級副社長広告 | 広告担当上級副社長 |
| 1センチメートル | 1cm |
| 1フィート | 30.48cm |
| 男性/女性/その他 | M/F/O |
| $25 | ¥1,850 |
データを正規化しないとどうなりますか?
Gartner が実施した調査によると、すべてのビジネス努力のほぼ 40% がデータ品質の低さが原因で失われています。 不適切なデータや不適切な形式のデータは、ビジネス プロセスのさまざまな段階に影響を与え、運用効率とリスク管理を損ないます。 データに基づく意思決定が誤ったデータに基づいている場合、企業がデータを有利に利用する能力が損なわれます。 さまざまなデータ ソースを標準化して適合させることができない場合、ビジネス上の意思決定にビッグ データを使用する利点は失われます。
使用可能なデータの主な敵の 1 つは、データの欠落または破損 (すべてのデータ ポイントが正しく存在しない行) です。 このような問題は、生データの処理が正しくないか、ソース データの不一致が原因で発生する可能性があります。 データを使用不能にするもう 1 つの主要なデータの問題は、使用可能なビットに分割されていない非構造化データの量です。

Priceonomics のある調査によると、企業が収集したデータの 55% が未使用のままになっています。 企業が収集したものの、何らかの制約により利用できなかった未使用のデータは、ダークデータと呼ばれます。 データの大部分を使用できない理由を尋ねたところ、回答者の 66% が「データの欠落または破損」を回答として選択し、25% が構造化されていない形式について不満を述べました。
企業が内部ソースと外部ソースの両方からデータを収集し続けるにつれて、正味のデータ サイズは増加し続けています。 今日、ほとんどの企業は AWS や GCP などのサービスによるクラウド ストレージ サービスを使用しており、インフラの請求額がどれほど大きいかを忘れがちです。 ほとんどのサービスは、保存されたデータのサイズではなく、実行したクエリに基づいて課金されますが、それでも次の 3 つのことを考慮する必要があります。
a)。 データ量が増えると、クエリはより多くのデータを解析する必要があり、実行に時間がかかります
b)。 クエリの実行に時間がかかるため、複数のクエリを同時に実行するとタイムアウト エラーが発生する可能性があります。
c)。 クエリごとに解析されるデータの量が増加するにつれて、クラウド サービスにかかるコストは着実に上昇します。
データ正規化の利点
データ正規化の最大の利点の 1 つは、データ セグメンテーションを実装できることです。 データ セグメンテーションは、さまざまな内部チームがより簡単に使用できるように、さまざまなパラメーターに基づいてデータをグループ化する機能です。 データは、顧客の性別、場所 (都市または地方)、業種など、さまざまな要因によってセグメント化できます。
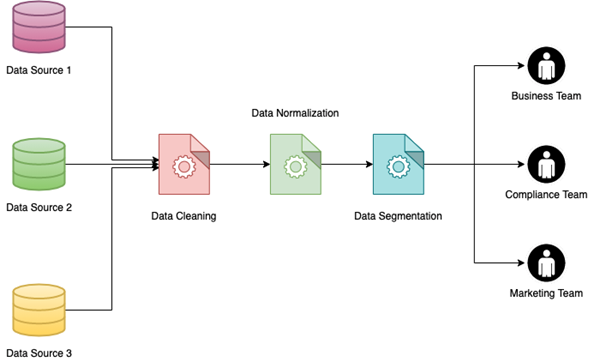
大規模なデータ セット、特に複数のデータ ソースを結合してコンパイルされたデータ セットにデータ セグメンテーションを実装するのは、困難な作業になる可能性があります。 ただし、データがすでに正規化されている場合は、何倍も簡単になります。 これには多面的な利点があります。
a)。 データが正規化されてセグメント化されている場合、さまざまなチームがさまざまなデータを引き出すことができ、汚れたデータや壊れたデータをフィルタリングする必要性を心配する必要はありません。
b)。 企業は、セグメント化されたデータを使用してターゲットを絞った広告とマーケティングのアプローチを使用して、限られたマーケティング予算でより良いコンバージョン率を得ることができます.
c)。 セグメント化されたデータは、企業が結果と顧客からのフィードバックを分析し、何がうまくいき、何がうまくいかなかったかを理解するのにも役立ちます。 この情報は、消費されるかテーブルに残されるかによって、会社の成否を左右する可能性があります。
顧客の行動を予測し、異常を検出することは、大量のデータを分析して予測モデルを作成しようとする大企業の主な目標の一部です。 生データ自体が正規化および標準化された後に保存されている場合、そのような努力の背後にある努力を大幅に最小限に抑えることができます。 データ サイエンス チームが新しい機械学習モデルに取り組んでいるか、ビジネス チームが Netflix と比較できるレコメンデーション システムの構築に取り組んでいるかにかかわらず、クリーンで正規化されたデータは出発点として絶対に必要です。
事態はどの程度悪化する可能性がありますか?
データの正規化は、複数のチームが同じデータ ソースを使用している場合や、データを介してチーム間で通信している場合に役立ちます。 データ ソースの数が多く、関与するチームや個人の数が多いほど、正規化されていないデータのリスクが高くなります。 正規化されていないデータに発生した主要な歴史的出来事の 1 つは、エンジニアが英語からメートル法への値の変換に失敗したために失われた1 億 2500 万ドルの火星探査機の出来事でした。 統一性を維持するための単位変換は、コア データ正規化手法の 1 つです。
損失はそれほど大きな値ではないかもしれませんが、データが雑然としているために発生する損失を計算できない場合があります。 それは、データが使用できなくなる主な理由の 1 つに徐々に浸透していきます。 間接的に、会社で使用されていないデータの割合は、データを正規化するための努力を怠ったことによる損失を意味します。
データの正規化と標準化について多くのことを話しましたが、データを適切に取得すること自体で作業の半分が完了しました。 外部ソースからデータをきれいにスクレイピングすれば、正規化の労力を大幅に削減できます。 PromptCloud の私たちのチームは、企業が Web スクレイピング要件を私たちに提供するだけで、プラグ アンド プレイ形式でデータを提供できる DaaS (サービスとしてのデータ) ソリューションを顧客に提供することに誇りを持っています。 複数の Web サイトからデータをスクレイピングし、それぞれのデータを異なるコンテナーまたは異なる API 経由で提供できます。 これが完了したら、データの正規化モジュールを作成してデータを集約し、それらを充実させることができます。これにより、チームはデータに基づく決定を下すことができます。