
L'importance de la normalisation des données
Publié: 2021-02-04Les entreprises ont toujours utilisé les données pour rester au top. Lorsque les entreprises travaillaient dans des magasins physiques, la plupart de ces analyses de données étaient hors ligne, car les ensembles de données étaient plus petits. Alors que de plus en plus d'entreprises ont déplacé leurs activités en ligne (ou du moins une partie de celles-ci), les ensembles de données ont augmenté en taille et atteignent désormais des tailles allant jusqu'à des téraoctets et des pétaoctets. Ces jeux de données sont constitués de :
un). Données internes pouvant contenir des détails sur les produits, des informations sur les employés, des contrats avec des partenaires, des mises à jour des stocks de l'entrepôt, etc.
b). Données provenant d'appareils IoT tels que les capteurs GPS, les robots intelligents, les capteurs de suivi et les jumeaux numériques
c). Données externes telles que les données des concurrents extraites du Web
Les données provenant de différentes sources peuvent ne pas toutes avoir la même forme et le même format. Vous pouvez avoir des données au format textuel, audio, vidéo et même tabulaire. Une fois que vous les avez tous convertis en un seul format structuré, vous remarquerez que tous n'ont pas les mêmes en-têtes. Même s'ils le font, les unités peuvent ne pas être les mêmes. Il peut également y avoir des lignes en double présentes dans les données.
Qu'est-ce que la normalisation des données ?
Le traitement de tous ces problèmes de données s'additionne et est collectivement appelé normalisation des données. Il aide principalement les données rassemblées à partir de différentes sources à réorganiser et à utiliser ensemble. Il améliore également la lisibilité des données pour l'équipe commerciale et offre ainsi une approche plus plug and play pour créer des visualisations de données .
La normalisation des données peut comprendre plusieurs étapes où chaque étape peut être subdivisée en différentes étapes pour différentes sources de données. Les techniques ou étapes de normalisation des données les plus courantes impliquent :
un). Suppression des entrées en double
b). Regroupement de données basé sur une méthodologie de regroupement logique
c). Création d'associations entre des points de données connexes
ré). Résolution des entrées de données conflictuelles
e). Conversion de différents ensembles de données en un seul format
F). Conversion de données semi-structurées ou non structurées en ensembles de valeurs-clés
g). Consolidation des données provenant de plusieurs sources
h). Conversion de toutes les lignes d'une colonne dans les mêmes unités
je). Division de colonnes avec de grandes valeurs numériques par puissances de 10
j). Affectation de valeurs numériques aux colonnes catégorielles
Ces efforts combinés conduisent à l'amélioration de la qualité des données en général et contribuent également à réduire le traitement requis dans les flux de travail d'entreprise où ces ensembles de données sont finalement utilisés. Ces processus peuvent être utilisés pour gérer différents types de champs tels que les noms, les adresses, les numéros de téléphone, les codes PIN, les valeurs monétaires, la distance entre deux points, etc. Chaque entreprise définit un ensemble de formats et de règles standard selon lesquels tous les ensembles de données qui entrent dans le flux de données sont normalisés.
Les données brutes peuvent être traitées de différentes manières en fonction de l'ensemble des règles de normalisation en place. Quelques exemples de normalisation des données sont présentés dans le tableau ci-dessous.
| Données brutes | Données normalisées |
| 25 parc sud | 25 Parc Sud |
| Sr VP Publicité | Vice-président principal de la publicité |
| 1 centimètre | 1cm |
| 1 pied | 30.48cm |
| Homme/Femme/Autres | H/F/O |
| 25 $ | ₹1850 |
Et si vous ne normalisez pas vos données ?
D'après les recherches menées par Gartner, près de 40 % de tous les efforts commerciaux sont perdus en raison de la mauvaise qualité des données. Des données erronées ou des données mal formatées ont un impact sur différentes étapes des processus métier et nuisent à l'efficacité opérationnelle ainsi qu'à la gestion des risques. Lorsque les décisions fondées sur des données reposent sur des données erronées, la capacité de l'entreprise à utiliser les données à son avantage est compromise. Les avantages de l'utilisation du Big Data pour les décisions commerciales sont perdus lorsque vous ne parvenez pas à normaliser et à intégrer différentes sources de données.
L'un des principaux ennemis des données utilisables est les données manquantes ou brisées - des lignes où tous les points de données peuvent ne pas être présents correctement. Ces problèmes peuvent survenir soit en raison d'un traitement incorrect des données brutes, soit en raison d'incohérences dans les données sources. L'autre problème majeur de données qui rend les données inutilisables est la quantité de données non structurées qui ne sont pas décomposées en bits utilisables.

Selon une étude de Priceonomics, jusqu'à 55 % des données collectées par les entreprises ne sont pas utilisées . Ces données inutilisées qui ont été collectées par les entreprises mais qui n'ont pas pu être utilisées en raison de certaines contraintes sont appelées dark-data. Lorsqu'on leur a demandé les raisons de ne pas pouvoir utiliser une si grande partie des données, 66 % des répondants ont choisi "données manquantes ou cassées" comme réponse, tandis que 25 % ont choisi de se plaindre des formats non structurés.
Alors que les entreprises continuent d'agréger des données provenant de sources internes et externes, la taille nette des données ne cesse d'augmenter. Aujourd'hui, la plupart des entreprises utilisent des services de stockage en nuage par des services comme AWS ou GCP et il est facile d'oublier l'importance de vos factures d'infra. Bien que la plupart des services vous facturent en fonction des requêtes que vous effectuez et non de la taille des données stockées, vous devrez tout de même tenir compte de trois éléments :
un). À mesure que le volume de données augmente, les requêtes devront analyser de plus en plus de données et prendront plus de temps à s'exécuter
b). En raison des requêtes prenant plus de temps à s'exécuter, plusieurs requêtes exécutées en même temps peuvent entraîner une erreur de délai d'attente
c). À mesure que la quantité de données analysées pour chaque requête augmente, les coûts encourus pour les services cloud augmenteraient régulièrement
Les avantages de la normalisation des données
L'un des principaux avantages de la normalisation des données est la possibilité de mettre en œuvre la segmentation des données. La segmentation des données est la capacité de regrouper des données en fonction de différents paramètres afin qu'elles puissent être utilisées plus facilement par différentes équipes internes. Les données peuvent être segmentées selon différents facteurs tels que le sexe des clients, l'emplacement (urbain ou rural), le type d'industrie, etc.
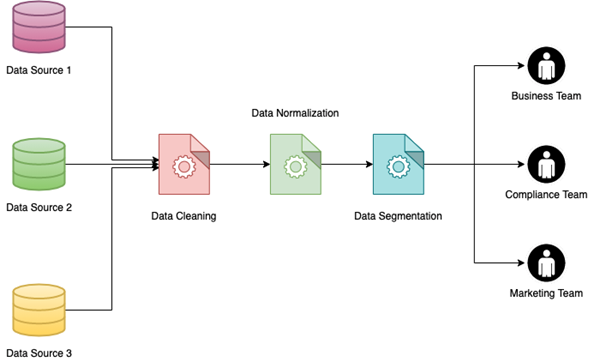
La mise en œuvre de la segmentation des données sur un grand ensemble de données, en particulier celui qui a été compilé en joignant plusieurs sources de données, peut être une tâche ardue. Ce sera beaucoup plus facile si les données ont déjà été normalisées. Les avantages de ceci sont multiples :
un). Si les données sont normalisées et segmentées, différentes équipes peuvent extraire différentes données sans se soucier de la nécessité de filtrer les données impures ou cassées.
b). Les entreprises peuvent utiliser une approche publicitaire et marketing ciblée en utilisant des données segmentées pour obtenir de meilleurs taux de conversion dans leurs budgets marketing limités.
c). Les données segmentées peuvent également aider les entreprises à analyser leurs résultats et les commentaires des clients et à comprendre ce qui s'est bien passé et ce qui s'est mal passé. Ces informations peuvent faire ou défaire une entreprise selon qu'elles sont consommées ou laissées sur la table.
Prévoir le comportement des clients et détecter les anomalies sont quelques-unes des principales cibles des grandes entreprises qui analysent de gros volumes de données et tentent de créer des modèles prédictifs. Les efforts derrière de tels efforts peuvent être grandement minimisés si les données brutes elles-mêmes ont été stockées après normalisation et standardisation. Que votre équipe de science des données travaille sur un nouveau modèle d'apprentissage automatique ou que votre équipe commerciale travaille à la création d'un système de recommandation comparable à celui de Netflix, des données propres et normalisées sont une nécessité absolue comme point de départ.
À quel point les choses peuvent-elles aller mal ?
La normalisation des données peut être utile lorsque plusieurs équipes utilisent la même source de données ou communiquent entre elles via des données. Plus le nombre de sources de données est élevé et plus le nombre d'équipes et d'individus impliqués est élevé, plus les risques de données non normalisées sont élevés. L'un des événements historiques majeurs survenus avec des données non normalisées a été celui de la sonde Mars de 125 millions de dollars qui a été perdue car les ingénieurs n'ont pas réussi à convertir les valeurs de l'anglais au système métrique. Les conversions d'unités pour maintenir l'uniformité restent l'une des principales techniques de normalisation des données.
Vos pertes peuvent ne pas représenter une valeur aussi élevée, mais vous ne pourrez peut-être pas calculer les pertes qui se produisent en raison de données encombrées. Cela s'infiltrerait lentement dans l'une des principales raisons de l'inutilisabilité des données. Indirectement, le pourcentage de données inutilisées dans votre entreprise signifierait la perte due au fait de ne pas déployer d'efforts pour normaliser les données.
Bien que nous ayons beaucoup parlé de normalisation et de standardisation des données, la récupération correcte des données elle-même représente la moitié du travail effectué. Si vous extrayez proprement les données de sources externes , vos efforts de normalisation peuvent être considérablement réduits. Notre équipe de PromptCloud est fière de fournir aux clients une solution DaaS (Data as a Service) à l'aide de laquelle les entreprises peuvent simplement nous fournir leurs besoins en matière de grattage Web et nous offrons les données dans un format plug and play. Nous pouvons extraire des données de plusieurs sites Web et fournir des données de chacun dans différents conteneurs ou via différentes API. Une fois cela fait, vous pouvez ensuite écrire vos modules de normalisation des données pour agréger les données et les enrichir - permettant ainsi à votre équipe de prendre des décisions fondées sur des données.