
Важность нормализации данных
Опубликовано: 2021-02-04Компании всегда использовали данные, чтобы оставаться на вершине. Когда предприятия работали в обычных магазинах, большая часть обработки данных выполнялась в автономном режиме, поскольку наборы данных были меньше. По мере того, как все больше компаний переводили свой бизнес в онлайн (или, по крайней мере, его часть), наборы данных росли в размерах и теперь достигают размеров до терабайтов и петабайтов. Эти наборы данных состоят из:
а). Внутренние данные, которые могут содержать информацию о продукте, информацию о сотрудниках, контракты с партнерами, обновления складских запасов и многое другое.
б). Данные с устройств Интернета вещей, таких как датчики GPS, интеллектуальные роботы, датчики слежения и цифровые двойники.
в). Внешние данные, такие как данные о конкурентах, взятые из Интернета.
Данные из разных источников могут не иметь одинаковой формы и формата. Вы можете иметь данные в текстовом, аудио, видео и даже табличном формате. После преобразования всех их в единый структурированный формат вы обнаружите, что не все из них имеют одинаковые заголовки. Даже если они есть, единицы измерения могут быть разными. В данных также могут присутствовать повторяющиеся строки.
Что такое нормализация данных?
Обработка всех таких проблем с данными вместе складывается и в совокупности называется нормализацией данных. В основном это помогает реорганизовать данные, собранные из разных источников, и использовать их вместе. Это также повышает удобочитаемость данных для бизнес-группы и, таким образом, обеспечивает более простой подход к созданию визуализаций данных .
Нормализация данных может включать несколько этапов, каждый из которых может быть дополнительно разделен на разные этапы для разных источников данных. Наиболее распространенные методы или этапы нормализации данных включают:
а). Удаление повторяющихся записей
б). Группировка данных на основе методологии логической группировки
в). Создание ассоциаций между связанными точками данных
г). Разрешение противоречивых записей данных
д). Преобразование разных наборов данных в единый формат
е). Преобразование полуструктурированных или неструктурированных данных в наборы "ключ-значение"
грамм). Консолидация данных из нескольких источников
час). Преобразование всех строк в столбце в одни и те же единицы
я). Разделение столбцов с большими числовыми значениями на степени 10
ж). Присвоение числовых значений категориальным столбцам
Такие усилия вместе приводят к улучшению качества данных в целом, а также помогают сократить объем обработки, необходимой в бизнес-процессах, где эти наборы данных в конечном итоге используются. Такие процессы можно использовать для обработки различных типов полей, таких как имена, адреса, номера телефонов, пин-коды, значения валюты, расстояние между двумя точками и многое другое. Каждая компания определяет набор стандартных форматов и правил, согласно которым все наборы данных, поступающие в поток данных, нормализуются.
Необработанные данные можно обрабатывать по-разному в зависимости от набора действующих правил стандартизации. Некоторые примеры стандартизации данных показаны в таблице ниже.
| Необработанные данные | Нормализованные данные |
| 25 южный парк | 25 Южный парк |
| Старший вице-президент по рекламе | Старший вице-президент по рекламе |
| 1 сантиметр | 1см |
| 1 фут | 30,48 см |
| Мужчина/женщина/другие | М/Ж/О |
| 25 долларов | ₹ 1850 |
Что делать, если вы не нормализуете свои данные?
Согласно исследованию, проведенному Gartner, почти 40% всех бизнес-усилий теряются из-за низкого качества данных. Неверные данные или плохо отформатированные данные влияют на различные этапы бизнес-процессов и снижают операционную эффективность, а также управление рисками. Когда решения, основанные на данных, основаны на ошибочных данных, способность бизнеса использовать данные в своих интересах ставится под угрозу. Преимущества использования больших данных для принятия бизнес-решений теряются, если вы не можете стандартизировать и использовать различные источники данных.
Одним из главных врагов пригодных для использования данных являются отсутствующие или поврежденные данные — строки, в которых не все точки данных могут быть представлены правильно. Такие проблемы могут возникать либо из-за неправильной обработки исходных данных, либо из-за несоответствия в исходных данных. Другая серьезная проблема данных, которая делает данные непригодными для использования, — это количество неструктурированных данных, которые не разбиты на пригодные для использования биты.

Согласно одному исследованию Priceonomics, до 55% данных, собранных компаниями, остаются неиспользованными . Эти неиспользованные данные, которые были собраны компаниями, но не могли быть использованы из-за определенных ограничений, называются скрытыми данными. На вопрос о причинах невозможности использовать такую большую часть данных 66% респондентов выбрали в качестве ответа «отсутствующие или поврежденные данные», тогда как 25% предпочли пожаловаться на неструктурированные форматы.
Поскольку компании продолжают собирать данные как из внутренних, так и из внешних источников, чистый размер данных продолжает увеличиваться. Сегодня большинство компаний используют облачные хранилища таких сервисов, как AWS или GCP, и легко забыть, насколько велики становятся ваши счета за инфраструктуру. Хотя большинство сервисов взимают плату за выполняемые вами запросы, а не за размер хранимых данных, вам все равно необходимо учитывать три вещи:
а). По мере роста объема данных запросам потребуется анализировать все больше и больше данных, и их выполнение будет занимать больше времени.
б). Из-за того, что запросы выполняются дольше, одновременное выполнение нескольких запросов может привести к ошибке тайм-аута.
в). По мере увеличения объема данных, анализируемых для каждого запроса, затраты на облачные сервисы будут неуклонно расти.
Преимущества нормализации данных
Одним из самых больших преимуществ нормализации данных является возможность реализации сегментации данных. Сегментация данных — это возможность группировать данные на основе различных параметров, чтобы их было легче использовать различным внутренним командам. Данные можно сегментировать по различным факторам, таким как пол клиентов, местоположение (город или сельская местность), тип отрасли и многое другое.
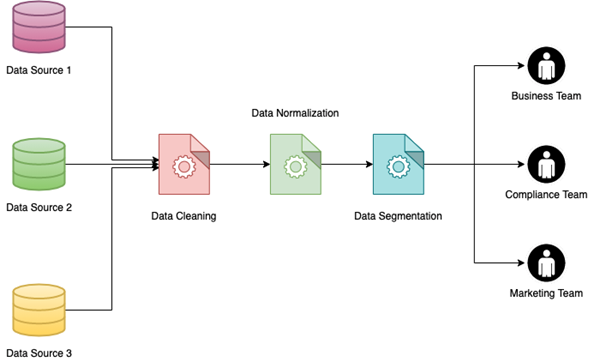
Реализация сегментации данных в большом наборе данных, особенно в том, который был скомпилирован путем объединения нескольких источников данных, может оказаться непростой задачей. Однако это будет во много раз проще, если данные уже нормализованы. Преимущества этого многогранны:
а). Если данные нормализованы и сегментированы, разные группы могут извлекать разные данные, не беспокоясь о необходимости фильтрации нечистых или поврежденных данных.
б). Компании могут использовать таргетированный подход к рекламе и маркетингу, используя сегментированные данные, чтобы повысить коэффициент конверсии при ограниченном маркетинговом бюджете.
в). Сегментированные данные также могут помочь компаниям проанализировать свои результаты и отзывы клиентов и понять, что было сделано правильно, а что нет. Эта информация может создать или разрушить компанию в зависимости от того, потребляется ли она или остается на столе.
Прогнозирование поведения клиентов и обнаружение аномалий являются одними из основных задач крупных предприятий, которые анализируют большие объемы данных и пытаются создавать прогнозные модели. Усилия, стоящие за такими усилиями, могут быть значительно сведены к минимуму, если сами необработанные данные были сохранены после нормализации и стандартизации. Независимо от того, работает ли ваша команда Data Science над новой моделью машинного обучения или ваша бизнес-команда работает над созданием рекомендательной системы, которая будет сравниваться с системой Netflix, чистые и нормализованные данные абсолютно необходимы в качестве отправной точки.
Насколько все может быть плохо?
Нормализация данных может быть полезна, когда несколько команд используют один и тот же источник данных или обмениваются данными между собой. Чем больше количество источников данных и чем больше количество задействованных команд и отдельных лиц, тем выше риски ненормализованных данных. Одним из основных исторических событий, произошедших с ненормализованными данными, стал марсианский зонд стоимостью 125 миллионов долларов , который был утерян, поскольку инженерам не удалось преобразовать значения из английской в метрическую систему. Преобразование единиц измерения для обеспечения единообразия остается одним из основных методов нормализации данных.
Ваши потери могут не учитывать такое высокое значение, но вы не сможете рассчитать потери, возникающие из-за захламленности данных. Постепенно это станет одной из основных причин непригодности данных. Косвенно процент неиспользуемых данных в вашей компании будет означать потери из-за того, что вы не приложили усилий для нормализации данных.
Хотя мы много говорили о нормализации и стандартизации данных, правильная выборка данных сама по себе — это половина сделанной работы. Если вы аккуратно извлекаете данные из внешних источников , ваши усилия по нормализации могут быть значительно сокращены. Наша команда в PromptCloud гордится тем, что предоставляет клиентам решение DaaS (данные как услуга), с помощью которого компании могут просто предоставить нам свои требования к очистке веб-страниц, а мы предлагаем данные в формате plug and play. Мы можем собирать данные с нескольких веб-сайтов и предоставлять данные с каждого в разных контейнерах или через разные API. Как только это будет сделано, вы сможете написать свои модули нормализации данных для агрегирования данных и их обогащения, что позволит вашей команде принимать решения на основе данных.