
什么是孤立页面以及如何修复它们
已发表: 2022-06-14孤立页面是域中没有任何指向它们的内部链接的页面。
在您的网站上拥有孤儿页面会带来负面后果:
- 未与您的网站结构链接的具有排名潜力的页面不太可能被发现和编入索引,并且不会为您的网站提供预期的收益(即自然流量),
- 由于其他 SEO 信号,如反向链接(来自其他网站的链接),可能会抓取和索引低质量的孤立页面。 这会浪费您网站的抓取预算,从而影响您网站上其他更有价值页面的索引。
孤立页面无处不在,解决它们并不简单——它们可能出于多种原因出现。 您可能只是忘记向某些页面添加内部链接,而在其他情况下,您可以故意创建孤立页面。 根据孤立页面在您的网站上所扮演的角色,它需要不同的处理方式。
在本文中,我将解释各种类型的孤立页面如何影响您的 SEO,如何在您的网站上发现孤立页面,以及如何解决这些问题。
孤立页面如何影响 SEO?
孤立页面没有指向它们的内部链接,这对搜索引擎爬虫和用户来说是个问题。 浏览您的网站不会找到它们; 如果以其他方式找到它们,则可能很难理解它们与您域的其他部分的关系。 对于搜索引擎来说尤其如此。
孤立页面如何影响搜索引擎?
缺乏内部链接会对搜索引擎爬虫如何发现您网站上的内容产生负面影响。
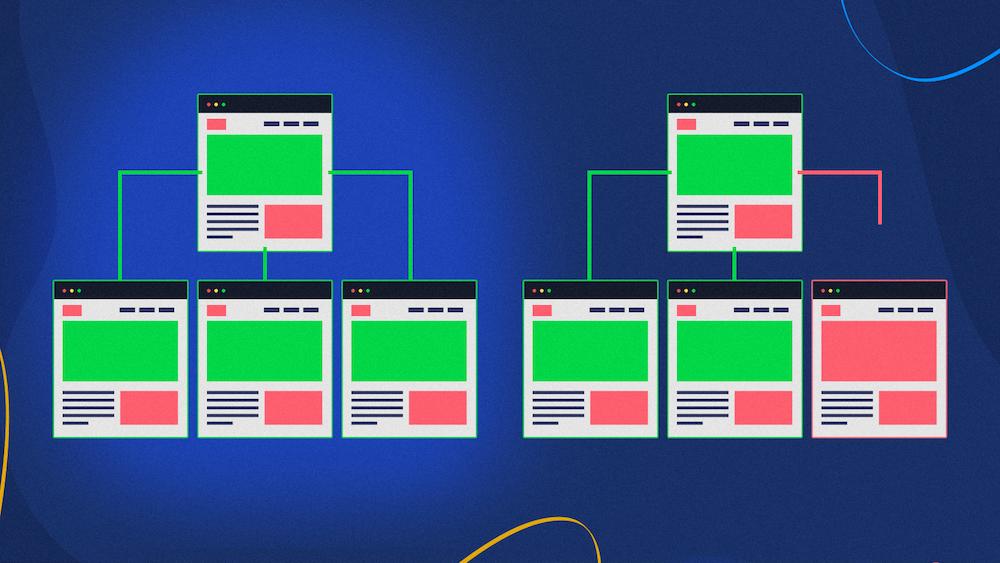
搜索引擎通过以下方式查找新页面:
- 跟踪指向您网站上 URL 的内部或外部链接,或
- 检查您的XML 站点地图文件。
孤立页面可能包含在站点地图中或具有来自其他域的链接。 它们仍将被视为孤立页面,但它们被抓取和编入索引的机会增加了——这不一定是好事。
虽然 Google 可以在没有任何入站链接的情况下将站点地图中的 URL 编入索引,但它将难以将这样的 URL 放置在站点的层次结构中,并且由于缺少链接而可能无法将其视为足够有价值。 站点地图中的孤立页面是否被编入索引取决于许多因素,例如网站大小(对于较大的网站,Google 通常会留下许多未抓取和未编入索引的页面,并且孤立页面的优先级可能很小)。
因此,孤立页面通常不会被编入索引,也不会在 Google 上排名,从而不会为您的网站带来自然流量。
如果孤立页面由于其他因素而被编入索引,那么并发症不会就此结束。 如果没有内部链接, PageRank 将无法流入孤立页面。 这意味着域内其他页面从具有高质量、相关反向链接中获得的任何链接权限都不会转移到孤立页面。
此外,由于没有内部链接,搜索引擎没有用于评估页面的语义或结构上下文。 搜索引擎可能很难确定该页面与哪些查询相关,而不知道它在您的整体网站结构中的位置。
如果您有低质量的孤立页面,并且它们的抓取不受 robots.txt 文件的限制,或者它们的索引没有被 noindex 标签阻止,搜索引擎可能会浪费抓取预算来抓取它们。 如果您有一个可能遭受爬网预算问题的大型网站,这尤其有害。
在极少数情况下,低质量的孤立页面也可能导致索引膨胀,当搜索引擎以不受控制的方式索引域上的页面时,会发生索引它可以找到的任何内容,包括稀薄或重复的内容。
而且,更糟糕的是,如果搜索引擎确定该页面的价值不足以被编入索引,但您将其设置为可编入索引,则可能会阻止它们将您网站上的其他页面编入索引。 这是因为这些低质量的页面可能会对您网站质量的总体概念产生负面影响。
请记住,如果一个页面甚至有一个内部链接,它就不再被视为孤立页面。 但是,如果一个页面只有一个链接并且它对您的网站至关重要,请考虑建立更多链接以加强其在网站层次结构中的地位。 这样,如果唯一的链接被删除,您还可以防止页面意外地被孤立。
孤立页面如何影响用户?
孤立页面对用户来说也是个问题。
如果您的孤立页面包含高质量的内容,这些内容应该会为您的网站带来大量流量并导致转化,那么如果它们未包含在您的网站结构中,用户将很难找到它们。 这也导致浪费专门用于在此类页面上创建内容的时间和资源。
如果您的孤立页面故意不链接到但仍然可供用户查找,则情况会有所不同。 登陆这些页面的访问者可能会遇到过时或不相关的内容,从而导致糟糕的用户体验。
孤立页面的类型
孤立页面的常见原因包括:
- 站点迁移——例如当一些旧页面没有包含在新的主导航中并且没有被重定向到新的目标页面时,
- 未优化的站点架构,由于没有站点架构策略,某些页面未链接。 网站上的某些机制也可能不会自动在导航中包含新类型的页面,
- CMS 创建了您不知道的其他 URL,
- 页面变得过时或不相关,指向它们的链接被删除但页面仍然发布 - 它可能发生在缺货的产品中,
- 不故意添加指向某些页面的链接——例如,促销或付费活动的登录页面。
其中许多是由于缺乏连贯的、通用的流程来进行站点迁移、将站点从暂存环境移动到生产环境、对站点进行重大更改等。

因为孤立页面的存在可能有很多不同的原因,解决它们不仅仅是添加指向这些页面的链接。
不是所有的页面都应该有指向它们的链接。 添加链接意味着您积极希望搜索引擎和用户查看这些页面。
将它们排除在您的网站结构之外是向搜索引擎表明它们对您没有价值的信号之一。 这与其他方面相结合,例如限制它们在 robots.txt 中的抓取或使用 noindex 标签使其不可索引,将使它们远离 Google 的索引。
如何查找孤立页面
修复任何东西之前的第一步是找到你的孤立页面。 通常,在您的网站上查找所有页面的好方法是使用 SEO 爬虫,但在这种情况下,爬虫可能还不够。 这就是孤立页面的问题——爬虫不会通过跟踪您网站上的链接来找到它们。
可用于在您的网站上查找孤立页面的数据源是:
- 您可能拥有的站点地图或其他 URL 列表。
- 链接数据库(如 Ahrefs.com)可在其他网站上找到指向您的页面的链接。
- 网络分析服务,例如 Google Analytics。
- 搜索分析,例如 Google Search Console。
- 您的服务器日志文件。
一些工具结合了这些数据源。 例如, Ahrefs 的站点审核向您显示页面资源管理器中的一个部分,其中包含通过反向链接和站点地图找到的孤立页面。 限制是 Ahrefs 不会显示不在站点地图中或没有反向链接的孤立页面。
同样,您可以使用SEMrush 的 Site Audit找到使用多个数据源的孤立页面。 它为您提供了两种选择:
- 查看在您的站点地图中找到的页面,无需任何内部链接。
- 在 Google Analytics 中查看没有内部链接的最近点击的页面。
Screaming Frog 有一个关于使用其 SEO Spider 发现孤儿页面的简洁指南。 他们的过程围绕着分析您的 XML 站点地图以获取可抓取页面,并使用与Google Analytics 和 Google Search Console 的集成来为抓取提供数据。
您将能够查看三个数据源(站点地图、Google Analytics 和 Google Search Console)中每一个的孤立 URL。 然后,您可以使用孤立页面报告导出所有找到的孤立页面的列表。
您还可以查看 Sitebulb,它同样提供连接多个数据源的选项,包括 Google Analytics 和 Google Search Console——查看 Sitebulb 的查找孤立页面指南。
要访问有关您网站的更全面的数据,您需要更深入地挖掘其结构。 最常见的解决方案是自行交叉引用数据集。
获取可抓取页面列表
您可以从 XML 站点地图文件中检索页面列表,因为它应该只包含您的可抓取和可索引的 URL。 最好的方法是使用爬虫。
无论您使用哪种爬虫,都应设置为仅爬取可索引页面。 它应该跳过以下爬网页面:
- 使用noindex 标签阻止索引,
- 由于robots.txt 指令,不可抓取。
请记住只抓取规范的 URL,包括正确的协议(HTTP 或 HTTPS)和子域(www 或非 www)。
发现哪些页面正在被访问
获得可抓取页面列表后,您需要找到用户或抓取工具访问的页面。
从谷歌分析获取数据
谷歌分析可以帮助您通过跟踪外部链接(包括社交媒体)或直接输入地址来查找用户或爬虫访问的页面。
在 Google Analytics 中,导航到行为 > 网站内容 > 所有页面。
然后,您将查看之前访问过的所有 URL。 调整日期以尽可能早地进行。 然后,导出收到的列表。
从 Google Search Console 获取数据
您还可以在Google Search Console中找到有用的数据,最好将其与 Google Analytics 中的数据结合起来。 Google Search Console 可能包含有关 Google 的抓取工具通过您的内部链接以外的方式访问的 URL 的数据。
在 GSC 中,选择性能 > 页面。
确保展示的数据中包含展示次数。 将日期范围更改为尽可能早,这将向您显示在所选时间范围内获得展示的所有 URL。
使用服务器日志文件
或者,您可以从服务器日志文件中获取最全面的数据,而不是 Google Analytics 和 Google Search Console 。 日志文件包含有关谁访问过您的网站的信息——包括搜索引擎爬虫和用户以及他们访问了哪些页面。 要使用它,您将需要访问服务器 - 请咨询您的开发人员以了解是否可行。
交叉引用数据
您需要查找在 Google Analytics 和 Google Search Console 数据集中找到的页面或已知页面导出列表中缺少的日志文件,因为这些将是您的孤立页面。
您可以在 Google 表格、Excel 或任何其他工具中比较数据集。
查明所有孤立页面后,将它们导出到单独的文件或电子表格中以进行下一部分优化。
如何分析孤立页面
在您的网站上有一个孤立页面列表后,您需要查看发现的页面并问自己一些问题,这些问题将帮助您确定如何处理它们:
- 此页面对您的网站有价值吗? 它是否有与推动流量或转化相关的重要目标?
- 尽管是孤立页面,但此页面是否对任何关键字进行排名?
- 该页面应该存在于您网站的分类中的什么位置?
- 此页面是重复的还是接近重复的? 您可以将内容移动到另一个尚未孤立的相关页面吗?
- 这个页面优化了吗? 你应该以任何方式改进它吗?
- 该页面是否有许多高质量的反向链接?
除此之外,最好先考虑一下为什么这些页面会变成孤儿。 这将帮助您在将来意识到此类问题并可能避免它们。
优化孤儿页面
一旦您了解了孤立页面的用途以及它如何帮助推动您的网站和营销目标,您就可以确定对该页面采取的步骤(如果有)。
从其他内部页面链接到该页面
当您因为网站访问者必须找到和访问孤立页面时,您必须从网站上的其他页面添加内部链接。 这样,您就可以为搜索爬虫和用户找到该页面创造机会。
您需要考虑最合适的链接位置——您可能需要考虑以下几点:
- 您是否应该从其他与主题相关的文章中添加指向它的链接?
- 您是否需要重组您的网站架构来为该页面腾出空间?
- 您是否应该重写您的任何内容以使链接更适合?
- 在主导航或页脚中是否应该有指向它的链接?
- 您应该选择什么锚文本来为搜索引擎和访问它的用户提供上下文?
如果您不确定如何处理这些问题,我们会为您提供有关内部链接的文章。
重定向页面
另一种方法是设置一个 URL 重定向到一个新位置——理想情况下,一个相关的等效页面仍然对访问者有帮助,并在不中断的情况下补充他们的用户旅程。
如果您永久重定向页面,请使用 301 重定向以保留尽可能多的 PageRank 并正确指示移动到搜索引擎。
删除页面
如果您发现一个对您的站点没有价值且不需要的孤立页面,并且无法重定向它,您可以将其删除。
最典型的做法是将其状态码更改为 404。
保持页面不变
如果页面服务于不需要内部链接到页面的业务需求,请保持页面未链接到。
例如,如果您有一个广告系列的登录页面,您只想在特定时间向用户展示,则可能会出现这种情况。
定期寻找新的孤立页面
根据您网站的大小,您应该设置一个监控流程以在它们有机会影响您的 SEO 之前捕获任何未来的孤立页面。
例如,您可以设置定期爬网以在将来查找孤立页面。
防止孤立页面在未来出现的最佳方法是找出导致它们的原因并从核心解决问题。 例如,如果您在您的网站上确定了一种机制,该机制会生成没有链接的不必要 URL,请立即修复它以防止随着时间的推移出现更多孤立页面。
每当您发布新页面时,请确保链接指向它,除非您有意识地不希望该页面被链接到。 如果可能,实施自动生成内部链接的解决方案,例如类别页面和相关项目。
包起来
优化网站上的孤立页面可以帮助您:
- 为它们和站点结构中的其他页面添加上下文,
- 使页面可抓取和可索引,从而为适当的关键字提供更高的排名机会,
- 在您网站的更多页面之间转移 PageRank。
请记住,少量孤立页面对于任何网站都是标准的,不应被视为大问题。
当您获得更多孤立页面时,问题变得更加严重,这可能会使您错过潜在的排名、流量和转化,从而阻碍您的收入和业务成功。
优先采用常规流程来捕获任何不需要的孤立页面并立即解决它们。