
孤立したページとは何ですか?それらを修正する方法
公開: 2022-06-14孤立したページは、ドメイン内のページであり、それらを指す内部リンクはありません。
サイトに孤立したページがあると、悪影響が生じます。
- サイト構造からリンクされていないランキングの可能性のあるページが発見されてインデックスに登録される可能性は低く、サイトに期待されるメリット(つまり、オーガニックトラフィック)を提供しません。
- 低品質の孤立したページは、バックリンク(他のWebサイトからのリンク)などの他のSEOシグナルが原因で、クロールされてインデックスに登録される場合があります。 これは、サイトのクロール予算の浪費であり、Webサイト上の他のより価値のあるページのインデックス作成に影響を与える可能性があります。
孤立したページはいたるところにあり、それらに対処するのは簡単ではありません。さまざまな理由で表示される可能性があります。 一部のページに内部リンクを追加するのを忘れるだけかもしれませんが、他の状況では、意図的に孤立したページを作成することができます。 孤立したページがサイトで果たす役割に応じて、異なる処理が必要になります。
この記事では、さまざまな種類の孤立したページがSEOにどのように影響するか、サイトで孤立したページを見つける方法、およびそれらに対処するために何をすべきかについて説明します。
孤立したページはSEOにどのように影響しますか?
孤立したページには、それらを指す内部リンクがないため、検索エンジンのクローラーやユーザーにとって問題があります。 それらはあなたのウェブサイトを閲覧しても見つかりません。 それらが他の方法で見つかった場合、それらがドメインの他の部分とどのように関連しているかを理解するのは難しいかもしれません。 これは特に検索エンジンに当てはまります。
孤立したページは検索エンジンにどのように影響しますか?
内部リンクの欠如は、検索エンジンのクローラーがWebサイトのコンテンツを検出する方法に悪影響を及ぼします。
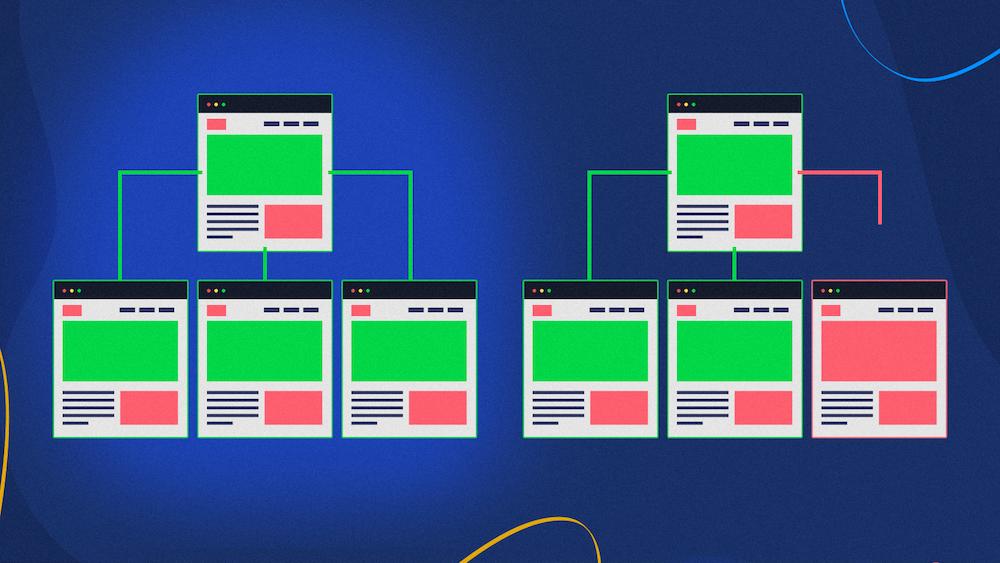
検索エンジンは、次のいずれかの方法で新しいページを検索します。
- WebサイトのURLへの内部または外部リンクをたどる、または
- XMLサイトマップファイルを調べます。
孤立したページがサイトマップに含まれているか、他のドメインからのリンクが含まれている可能性があります。 それらは引き続き孤立したページと見なされますが、クロールされてインデックスが作成される可能性が高くなります。これは必ずしも良いとは限りません。
Googleはインバウンドリンクなしでサイトマップで見つかったURLをインデックスに登録できますが、そのようなURLをサイトの階層に配置するのに苦労し、リンクがないために十分な価値があると見なされない場合があります。 サイトマップ内の孤立したページがインデックスに登録されるかどうかは、ウェブサイトのサイズなどの多くの要因に依存します(ウェブサイトが大きい場合、Googleは通常、多くのページをクロール解除してインデックスに登録せず、孤立したページにはほとんど優先順位を付けません)。
その結果、孤立したページは通常、インデックスに登録されず、Googleでランク付けされず、Webサイトへのオーガニックトラフィックを促進しません。
他の要因によって孤立したページがインデックスに登録された場合、問題はそれだけではありません。 内部リンクがないと、 PageRankは孤立したページに流れることができません。 これは、ドメイン内の他のページが高品質で関連性のある被リンクを持つことから得られるリンク権限が孤立したページに転送されないことを意味します。
また、内部リンクがないため、検索エンジンにはページを評価するための意味的または構造的なコンテキストがありません。 検索エンジンは、ページがサイト構造全体のどこに収まるかを知らなくても、ページがどのクエリに関連しているかを判断するのに苦労する可能性があります。
低品質の孤立したページがあり、robots.txtファイルでクロールが制限されていない場合、またはnoindexタグを介してインデックスがブロックされていない場合、検索エンジンはクロールの予算を浪費する可能性があります。 これは、クロール予算の問題に悩まされる可能性のある大規模なWebサイトがある場合に特に有害です。
まれに、低品質の孤立したページがインデックスの肥大化につながることもあります。これは、検索エンジンが制御されていない方法でドメイン上のページにインデックスを付け、薄いコンテンツや重複コンテンツなど、検出できるコンテンツにインデックスを付けるときに発生します。
さらに悪いことに、検索エンジンがページをインデックスに登録するのに十分な価値がないと判断したが、インデックスに登録できるようにすると、サイト上の他のページのインデックスを作成できなくなる可能性があります。 これは、これらの低品質のページがWebサイトの品質に関する一般的な考え方に悪影響を与える可能性があるためです。
ページに内部リンクが1つでもある場合、そのページは孤立したページとは見なされないことに注意してください。 ただし、ページにリンクが1つしかなく、それがWebサイトにとって不可欠である場合は、サイト階層内での位置を強化するために、より多くのリンクを構築することを検討してください。 このようにして、唯一のリンクが削除された場合にページが誤って孤立するのを防ぐこともできます。
孤立したページはユーザーにどのように影響しますか?
孤立したページもユーザーにとって問題があります。
孤立したページに高品質のコンテンツが含まれていて、ウェブサイトへの大量のトラフィックを促進し、コンバージョンにつながる場合、サイトの構造に含まれていないと、ユーザーはそれらを見つけるのが困難になります。 これはまた、そのようなページにコンテンツを作成するために費やされる時間とリソースの浪費につながります。
孤立したページが意図的にリンクされていないが、ユーザーが見つけられるようになっている場合は異なります。 これらのページにアクセスした訪問者は、古くなったコンテンツや無関係なコンテンツに出くわし、ユーザーエクスペリエンスを低下させる可能性があります。
孤立したページの種類
孤立したページの一般的な原因は次のとおりです。
- サイトの移行—古いページの一部が新しいメインナビゲーションに含まれておらず、新しいターゲットページにリダイレクトされていない場合など。
- 最適化されていないサイトアーキテクチャ。サイトアーキテクチャ戦略がないために一部のページがリンク解除されます。 ナビゲーションに新しいタイプのページが自動的に含まれないメカニズムがサイトに存在する可能性もあります。
- 知らない追加のURLを作成するCMS、
- ページが古くなったり、関連性がなくなったりします。ページへのリンクは削除されますが、ページは公開されたままになります。在庫切れの商品で発生する可能性があります。
- 意図的に特定のページへのリンクを追加しない-たとえば、プロモーションキャンペーンや有料キャンペーンのランディングページ。
これらの多くは、サイトの移行を実行したり、サイトをステージング環境から本番環境に移動したり、サイトに大幅な変更を加えたりするための一貫した普遍的なプロセスがないために発生します。
孤立したページが存在する理由はさまざまである可能性があるため、それらに対処することは、これらのページへのリンクを追加することだけではありません。

すべてのページにそれらを指すリンクがあるべきではありません。 リンクを追加するということは、検索エンジンとユーザーにこれらのページを積極的に表示してもらいたいということです。
それらをサイト構造から遠ざけることは、それらがあなたにとって価値がないことを検索エンジンに示すシグナルの1つです。 これをrobots.txtでのクロールを制限したり、noindexタグでインデックスに登録できないようにするなどの他の側面と組み合わせると、Googleのインデックスから除外されます。
孤立したページを見つける方法
何かを修正する前の最初のステップは、孤立したページを見つけることです。 通常、 Webサイト上のすべてのページを見つけるための優れた方法は、SEOクローラーを使用することですが、この場合、クローラーでは十分ではない可能性があります。 これが孤立したページの問題です。クローラーはサイト上のリンクをたどってもページを見つけることができません。
サイト上の孤立したページを見つけるために使用できるデータソースは次のとおりです。
- あなたのサイトマップまたはあなたが持っているかもしれないURLの他のリスト。
- 他のWebサイトのページへのリンクを見つけるリンクデータベース(Ahrefs.comなど)。
- GoogleAnalyticsなどのWeb分析サービス。
- Google検索コンソールのような検索分析。
- サーバーログファイル。
一部のツールは、これらのデータソースを組み合わせています。 たとえば、 Ahrefsのサイト監査では、バックリンクとサイトマップで見つかった孤立したページを含むセクションがページエクスプローラーに表示されます。 制限は、Ahrefsがサイトマップにない、またはバックリンクのない孤立したページを表示しないことです。
同様に、 SEMrushのサイト監査でいくつかのデータソースを使用して孤立したページを見つけることができます。 それはあなたに2つのオプションを与えます:
- 内部リンクなしでサイトマップにあるページを表示します。
- 内部リンクのないGoogleAnalyticsで最近ヒットしたページを表示します。
Screaming Frogには、 SEOスパイダーを使用して孤立したページを見つけるための優れたガイドがあります。 彼らのプロセスは、クロール可能なページのXMLサイトマップを分析し、 GoogleAnalyticsおよびGoogleSearchConsoleとの統合を使用してクロール用のデータを提供することを中心に展開しています。
サイトマップ、Googleアナリティクス、Google検索コンソールの3つのデータソースそれぞれの孤立したURLを表示できます。 次に、孤立ページレポートを使用して、見つかったすべての孤立ページのリストをエクスポートできます。
同様に、GoogleAnalyticsやGoogleSearchConsoleなどの複数のデータソースを接続するオプションを提供するSitebulbもご覧ください。孤立したページを見つけるためのSitebulbのガイドをご覧ください。
サイトに関するより包括的なデータにアクセスするには、サイトの構造をより深く掘り下げる必要があります。 最も一般的な解決策は、自分でデータセットを相互参照することです。
クロール可能なページのリストを取得する
XMLサイトマップファイルにはクロール可能およびインデックス可能なURLのみが含まれている必要があるため、ページのリストを取得できます。 最善のアプローチは、クローラーを使用することです。
使用するクローラーは、インデックス可能なページのみをクロールするように設定する必要があります。 次のようなクロールページをスキップする必要があります。
- noindexタグを使用したインデックス作成をブロックしました。
- robots.txtディレクティブが原因で、クロールできません。
正しいプロトコル(HTTPまたはHTTPS)とサブドメイン(wwwまたは非www)を含む正規URLのみをクロールすることを忘れないでください。
アクセスされているページを確認する
クロール可能なページのリストを取得したら、ユーザーまたはクローラーがアクセスするページを見つける必要があります。
GoogleAnalyticsからデータを取得する
Google Analyticsは、外部リンク(ソーシャルメディアを含む)をたどるか、アドレスを直接入力することで、ユーザーまたはクローラーがアクセスするページを見つけるのに役立ちます。
Google Analyticsで、[行動]>[サイトコンテンツ]>[すべてのページ]に移動します。
次に、以前にアクセスしたことのあるすべてのURLを表示します。 可能な限り遡るように日付を調整します。 次に、受信したリストをエクスポートします。
Google検索コンソールからデータを取得する
また、 Google Search Consoleで有用なデータを見つけることができ、それをGoogleAnalyticsで見つけたデータと組み合わせるのは良いことです。 Google検索コンソールには、内部リンク以外の方法でGoogleのクローラーがアクセスしたURLに関するデータが含まれている場合があります。
GSCで、[パフォーマンス]>[ページ]を選択します。
表示されたデータにインプレッションが含まれていることを確認してください。 日付範囲を変更して、可能な限り過去にさかのぼります。これにより、選択した時間枠でインプレッションを受信したすべてのURLが表示されます。
サーバーログファイルを使用する
または、GoogleAnalyticsとGoogleSearch Consoleの代わりに、サーバーログファイルから最も包括的なデータを取得できます。 ログファイルには、検索エンジンのクローラーとユーザー、ユーザーがアクセスしたページなど、サイトにアクセスしたユーザーに関する情報が含まれています。 これを使用するには、サーバーにアクセスする必要があります。可能かどうかについては、開発者に相談してください。
データを相互参照する
GoogleAnalyticsおよびGoogleSearchConsoleデータセットで見つかったページ、またはエクスポートされた既知のページのリストから欠落しているログファイルを探す必要があります。これらは孤立したページになるためです。
Googleスプレッドシート、Excel、またはその他のツールでデータセットを比較できます。
すべての孤立したページを特定したら、最適化の次の部分のために、それらを別のファイルまたはスプレッドシートにエクスポートします。
孤立したページを分析する方法
Webサイトに孤立したページのリストができたら、検出されたページを確認し、それらをどうするかを決定するのに役立ついくつかの質問を自問する必要があります。
- このページはあなたのサイトにとって価値がありますか? トラフィックやコンバージョンの促進に関連する重要な目標がありますか?
- 孤立したページであるにもかかわらず、このページはキーワードでランク付けされていますか?
- あなたのウェブサイトの分類法のどこにページが存在するべきですか?
- このページは重複していますか、それともほぼ重複していますか? 孤立していない別の関連ページにコンテンツを移動できますか?
- このページは最適化されていますか? 何らかの方法でそれを改善する必要がありますか?
- ページには多くの質の高い被リンクがありますか?
それとは別に、そもそもなぜページが孤立したのかを考えるのは良いことです。 これは、将来そのような問題を認識し、場合によってはそれらを回避するのに役立ちます。
孤立したページを最適化する
孤立したページがどのような目的を果たし、それがWebサイトとマーケティングの目標を推進するのにどのように役立つかを理解したら、ページで実行するステップがある場合はそれを決定できます。
他の内部ページからページへのリンク
サイト訪問者にとって不可欠であるために孤立したページを見つけて訪問したい場合は、Webサイトの他のページからそのページへの内部リンクを追加する必要があります。 このようにして、検索クローラーとユーザーがページを見つける機会を作成します。
リンク元として最適な場所を検討する必要があります。次のことを検討することをお勧めします。
- 他のテーマに関連する記事からのリンクを追加する必要がありますか?
- このページ用のスペースを確保するために、サイトアーキテクチャを再構築する必要がありますか?
- リンクをより適切にするために、コンテンツを書き直す必要がありますか?
- メインナビゲーションまたはフッターにリンクが必要ですか?
- 検索エンジンとそれにアクセスするユーザーにコンテキストを与えるために、どのアンカーテキストを選択する必要がありますか?
これらへのアプローチ方法がわからない場合は、内部リンクに関する記事をご覧ください。
ページをリダイレクトする
もう1つの方法は、新しい場所へのURLリダイレクトを設定することです。理想的には、訪問者に役立ち、中断することなくユーザージャーニーを補完する、関連する同等のページです。
ページを永続的にリダイレクトする場合は、301リダイレクトを使用して、可能な限り多くのPageRankを保持し、検索エンジンへの移動を正しく示します。
ページを削除する
サイトにとって価値がなく必要な孤立したページを見つけ、それをリダイレクトできない場合は、削除できます。
最も一般的なアプローチは、ステータスコードを404に変更することです。
ページをそのままにします
ページへの内部リンクを必要としないビジネスニーズに対応している場合は、ページのリンクを解除したままにします。
これは、たとえば、特定の時間にのみユーザーに表示したいキャンペーンのランディングページがある場合に当てはまります。
定期的に新しい孤立したページを探します
サイトのサイズに応じて、SEOに影響を与える前に、将来の孤立したページをキャッチするための監視プロセスを設定する必要があります。
たとえば、定期的なクロールを設定して、将来孤立したページを見つけることができます。
孤立したページが将来表示されないようにする最善の方法は、孤立したページの原因を特定し、コアで問題に対処することです。 たとえば、リンクのない不要なURLを生成するメカニズムをサイトで特定した場合は、このメカニズムを修正して、時間が経つにつれて孤立したページが表示されないようにします。
新しいページを公開するときは、意識的にページをリンクさせたくない場合を除いて、リンクがそのページを指していることを確認してください。 可能であれば、カテゴリページや関連アイテムなどの内部リンクを自動的に生成するソリューションを実装します。
まとめ
Webサイトの孤立したページを最適化すると、次のことが役立ちます。
- それらとサイト構造の他のページにコンテキストを追加し、
- ページをクロール可能およびインデックス可能にし、適切なキーワードでランク付けされる可能性を高めます。
- Webサイト内のより多くのページ間でPageRankを転送します。
少量の孤立したページはどのサイトでも標準であり、大きな問題のように扱われるべきではないことに注意してください。
孤立したページが増えると、問題はさらに深刻になり、潜在的なランキング、トラフィック、コンバージョンを逃して、収益とビジネスの成功を妨げる可能性があります。
不要な孤立したページをキャッチし、すぐに対処するための定期的なプロセスを優先します。