
Ce este un Web Scraper și cum funcționează?
Publicat: 2024-01-16În peisajul vast și în continuă evoluție al internetului, datele au devenit componenta vitală a procesului de luare a deciziilor și a planificării strategice în diferite sectoare. Aici constă semnificația web scrapers – instrumente puternice care navighează în marea colosală de informații online. Dar ce este exact web scraping și de ce a devenit atât de crucial în era digitală?
Web scraping, în esență, implică extragerea automată a datelor de pe site-uri web. Acest proces, deseori realizat de software sau scripturi specializate, permite colectarea de informații specifice din pagini web și transformarea acesteia într-un format structurat, de obicei pentru analiză sau utilizare în alte aplicații.
Într-o lume în care datele sunt rege, web scraping servește ca un factor cheie. Permite companiilor, cercetătorilor și persoanelor fizice să acceseze și să utilizeze datele web publice în mod eficient și eficient. De la analiza concurenților și cercetarea de piață până la urmărirea sentimentelor sociale și a proiectelor academice, aplicațiile de web scraping sunt pe cât de diverse, pe atât de impactante.
Ce este un Web Scraper: Elementele de bază
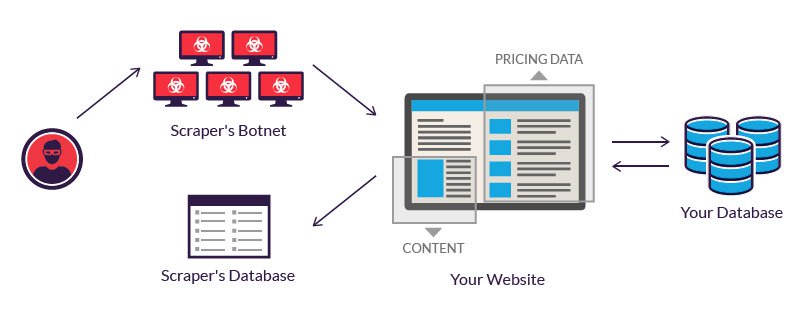
Sursa: https://www.imperva.com/learn/application-security/web-scraping-attack/
Web scraping este un proces care implică extragerea automată a informațiilor de pe site-uri web. Această tehnică folosește software specializat sau scripturi concepute pentru a accesa paginile web, a prelua datele necesare și apoi a converti acele date într-un format structurat pentru utilizare ulterioară. Simplitatea acestei definiții, totuși, contrazice sofisticarea și versatilitatea web scraping ca instrument. Acum, s-ar putea să fi înțeles ce este un web scraper, așa că haideți să aflăm cum funcționează.
La nivelul său cel mai fundamental, web scraping servește două funcții principale:
- Colectarea datelor : programele de scraping web sunt adepți la navigarea prin pagini web, identificarea și colectarea anumitor tipuri de date. Acestea pot include detalii despre produse de pe site-uri de comerț electronic, prețuri ale acțiunilor de pe site-uri financiare, afișări de locuri de muncă de pe portaluri de angajare sau orice alt conținut web accesibil publicului.
- Transformarea datelor : odată ce datele sunt colectate, instrumentele web scraping transformă aceste date web nestructurate (adesea cod HTML) într-un format structurat, cum ar fi CSV, Excel sau o bază de date. Această transformare face datele mai ușor de analizat, manipulat și utilizat în diverse scopuri.
Aceste funcții de bază ale web scraping îl fac un instrument puternic pentru oricine are nevoie de acces rapid și eficient la cantități mari de informații bazate pe web. Fie că este vorba de o afacere mică care monitorizează prețurile concurenței sau de o mare corporație care analizează tendințele pieței, web scraping oferă un mijloc de a culege date relevante fără a fi nevoie de extragerea manuală. În secțiunile următoare, ne vom aprofunda în modul în care funcționează aceste instrumente de răzuit, tipurile lor diferite și gama lor largă de aplicații în lumea digitală.
Cum funcționează Web Scrapers: O scufundare tehnică
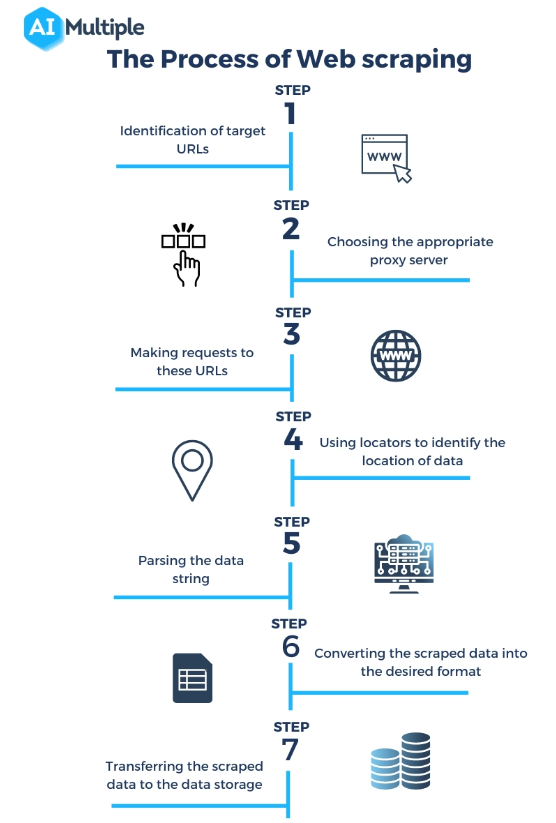
Sursa: https://research.aimultiple.com/web-scraping-vs-api/
Ce este un web scraper? Web scraping ar putea suna ca magic, dar este de fapt un proces tehnic bine orchestrat care implică mai mulți pași pentru a accesa, extrage și procesa date de pe site-uri web. Iată o privire mai atentă asupra modului în care funcționează web scrapers:
Trimiterea unei cereri către serverul web :
Primul pas în web scraping este ca scraperul să trimită o solicitare către serverul web care găzduiește pagina web țintă. Acest lucru este similar cu ceea ce se întâmplă atunci când introduceți o adresă URL în browser; diferența este că scraperul trimite cererea în mod programatic.
Preluarea paginii web :
Odată ce cererea este trimisă, serverul răspunde cu conținutul paginii web, de obicei în format HTML. Scraperul descarcă apoi acest conținut pentru procesare. În unele cazuri, poate fi necesară redarea JavaScript pentru a încărca complet conținutul paginii, lucru pe care unii scrapers avansati îl pot gestiona.
Analizarea conținutului HTML :
Pagina web preluată este de obicei în format HTML, care este un limbaj de marcare cu o structură specifică. Scraperul analizează acest conținut HTML pentru a da sens structurii sale – identificând anteturi, paragrafe, linkuri și alte elemente pe baza etichetelor lor HTML.
Extragerea datelor relevante :
După parsare, screperul identifică și extrage datele specifice de interes. Acesta poate fi orice, de la descrieri de produse și prețuri până la textul articolului sau date statistice. Extragerea se bazează pe elementele HTML și pe atributele acestora, cum ar fi numele claselor sau ID-urile.
Transformarea și stocarea datelor :
Datele extrase, încă în formă brută, sunt apoi transformate într-un format structurat precum CSV, JSON sau direct într-o bază de date. Acest pas este crucial pentru a face datele utilizabile pentru analiză sau integrare cu alte aplicații.
Gestionarea provocărilor :
Web scraping poate întâmpina provocări precum conținutul încărcat dinamic, măsurile anti-scraping ale site-urilor web și menținerea stării sesiunii. Scraperele avansate navighează în acestea imitând comportamentul uman de navigare, rotind adresele IP și gestionând cookie-uri și sesiuni.
Respectarea limitelor legale și etice :
Scraperele etice ale web sunt programate pentru a respecta limitele legale ale web scraping. Aceasta implică aderarea la instrucțiunile pentru fișierele robots.txt ale site-ului web, evitarea încărcării excesive a serverului și asigurarea conformității cu legile privind confidențialitatea datelor.
Tipuri de web scrapers: explorarea varietăților
Instrumentele web scraping vin în diferite forme, fiecare concepută pentru a răspunde nevoilor și provocărilor specifice. Înțelegerea acestor tipuri diferite ajută la selectarea instrumentului potrivit pentru lucrare. Să explorăm câteva dintre tipurile obișnuite de web scrapers:
Scrapers HTML :
- Funcționalitate : scraper-urile HTML sunt cea mai de bază formă de scraper-uri web. Ei descarcă conținutul HTML al paginilor web și extrag date prin analizarea codului HTML.
- Cazuri de utilizare : Ideal pentru site-uri web statice în care datele sunt încorporate direct în HTML.
Scrapers API :
- Funcționalitate : Aceste scrapers extrag date din API-uri (Application Programming Interfaces) furnizate de site-uri web. În loc să analizeze HTML, ei fac solicitări către un punct final API și primesc date într-un format structurat, cum ar fi JSON sau XML.
- Cazuri de utilizare : potrivite pentru site-uri web cu API-uri publice, oferind o modalitate mai eficientă și mai fiabilă de extragere a datelor.
Raclete bazate pe browser :
- Funcționalitate : Aceste instrumente imită un browser web pentru a interacționa cu paginile web. Aceștia pot executa solicitări JavaScript și AJAX, făcându-le capabile să trimită conținut dinamic.
- Cazuri de utilizare : esențial pentru site-urile web care se bazează în mare măsură pe JavaScript pentru redarea conținutului, cum ar fi aplicațiile web moderne.
Raclete pentru browser fără cap :
- Funcționalitate : funcționând similar cu scraper-urile bazate pe browser, acestea folosesc browsere fără cap (browsere fără interfață grafică de utilizator) pentru a reda paginile web. Ei pot gestiona pagini web complexe care necesită management de sesiune, cookie-uri și executarea JavaScript.
- Cazuri de utilizare : util pentru extragerea datelor de pe site-uri web complexe, dinamice și aplicații cu o singură pagină (SPA).
Visual Web Scrapers :
- Funcționalitate : Acestea sunt răzuitoare ușor de utilizat, cu o interfață grafică care permite utilizatorilor să selecteze vizual punctele de date pe o pagină web. Sunt mai puțin tehnice și nu necesită cunoștințe de programare.
- Cazuri de utilizare : Ideal pentru utilizatorii care nu sunt programatori, dar care trebuie să răzuiască date de pe site-uri web fără configurare complexă.
Scrapers web SaaS :
- Funcționalitate : Acestea sunt oferite ca serviciu de companii specializate în web scraping. Aceștia se ocupă de complexitatea scrapingului și oferă date într-un format gata de utilizare.
- Cazuri de utilizare : potrivit pentru companiile care necesită capacități de scraping web, dar nu doresc să se ocupe de aspectele tehnice.
Raclete personalizate :
- Funcționalitate : Construite pentru cerințe specifice, aceste răzuitoare sunt adaptate pentru a răspunde nevoilor unice de extragere a datelor, implicând adesea o logică și caracteristici complexe.
- Cazuri de utilizare : Este necesar atunci când aveți de-a face cu operațiuni de răzuire la scară largă sau extrem de complexe pe care uneltele disponibile nu le pot gestiona.
Fiecare tip de raclere web are punctele sale forte și se potrivește diferitelor scenarii. De la simpla scraping HTML la tratarea conținutului dinamic și a API-urilor, alegerea depinde de structura site-ului web, de complexitatea sarcinii și de expertiza tehnică a utilizatorului. În secțiunile următoare, vom analiza aplicațiile practice ale acestor instrumente și modul în care acestea transformă datele în informații valoroase.

Peisajul juridic: înțelegerea conformității și eticii în web scraping
Web scraping, în timp ce un instrument puternic pentru extragerea datelor, operează într-un peisaj juridic și etic complex. Este esențial pentru companiile și persoanele care se angajează în web scraping să înțeleagă legalitățile și considerentele etice pentru a asigura conformitatea și pentru a menține bunele practici. Această secțiune pune în lumină aceste aspecte:
Considerații juridice în web scraping :
- Legile drepturilor de autor : Datele publicate pe internet sunt adesea protejate de legile drepturilor de autor. Eliminarea datelor care sunt protejate prin drepturi de autor fără permisiune poate duce la probleme legale.
- Acorduri privind termenii și condițiile : multe site-uri web includ clauze în Termenii și condițiile lor (ToS) care interzic în mod explicit scrapingul web. Încălcarea acestor termeni poate duce la acțiuni legale din partea proprietarului site-ului.
- Legile privind confidențialitatea datelor : reglementări precum GDPR (General Data Protection Regulation) și CCPA (California Consumer Privacy Act) impun reguli stricte cu privire la modul în care datele personale pot fi colectate și utilizate. Web scrapers trebuie să asigure conformitatea cu aceste legi de confidențialitate.
Considerații etice în Web Scraping :
- Respectarea robots.txt : Acest fișier de pe site-uri web specifică cum și ce crawler-uri web au permisiunea de a răzui. Scrapingul etic al web implică aderarea la aceste linii directoare.
- Minimizarea încărcării serverului : scraping agresiv poate supraîncărca serverul unui site web, ceea ce poate duce la blocarea acestuia. Scraperele etice sunt concepute pentru a imita viteza și modelele de navigare umane pentru a evita astfel de probleme.
- Transparență și scop : Scrapingul etic implică a fi transparent cu privire la cine colectează datele și în ce scop. Înseamnă și evitarea extragerii informațiilor sensibile.
Cele mai bune practici pentru web scraping legal și etic :
- Căutați permisiunea : acolo unde este posibil, cel mai bine este să solicitați permisiunea proprietarului site-ului web înainte de a le elimina datele, mai ales dacă datele sunt sensibile sau sunt protejate de drepturi de autor.
- Respectați standardele legale : asigurați-vă că activitățile dvs. de răzuire respectă legile locale și internaționale relevante.
- Utilizați datele în mod responsabil : datele colectate trebuie utilizate în mod etic și responsabil, respectând confidențialitatea utilizatorilor și evitând vătămarea persoanelor vizate.
Navigarea zonelor gri :
- Legalitatea web scraping se încadrează adesea în zone gri, în funcție de modul în care sunt utilizate datele, de natura datelor și de jurisdicție. Este recomandabil să consultați experți juridici atunci când aveți îndoieli.
Înțelegerea și aderarea la considerentele legale și etice în web scraping nu se referă doar la conformitate, ci și la menținerea integrității și a reputației afacerii dvs. Pe măsură ce avansăm, practicile de web scraping vor continua probabil să evolueze odată cu peisajul legal, făcând imperativ ca utilizatorii să rămână informați și conștiincioși.
Alegerea unui Web Scraper: sfaturi și bune practici
Selectarea web scraper-ului potrivit este o decizie crucială care poate avea un impact semnificativ asupra eficienței eforturilor dvs. de colectare a datelor. Iată câteva sfaturi și cele mai bune practici pentru a vă ghida în alegerea instrumentului ideal de scraping web și în utilizarea lui eficientă:
Evaluează-ți nevoile :
- Înțelegeți-vă cerințele : înainte de a vă scufunda în multitudinea de instrumente de scraping web disponibile, clarificați ce trebuie să răzuiți, cât de des trebuie să faceți acest lucru și complexitatea datelor și a site-urilor web implicate.
- Scalabilitate : Luați în considerare dacă aveți nevoie de o unealtă care poate gestiona răzuirea pe scară largă sau dacă o soluție mai simplă și mai simplă va fi suficientă.
Evaluați caracteristicile :
- Ușurință în utilizare : dacă nu sunteți înclinat din punct de vedere tehnic, căutați un răzuitor cu o interfață ușor de utilizat sau caracteristici vizuale de tip point-and-click.
- Capacitate de extragere a datelor : Asigurați-vă că instrumentul poate extrage tipul de date de care aveți nevoie (text, imagini etc.) și poate gestiona conținut dinamic încărcat cu JavaScript sau AJAX.
- Opțiuni de export de date : verificați formatele în care scraperul poate exporta date (CSV, JSON, baze de date etc.) și asigurați-vă că îndeplinesc cerințele dvs.
Luați în considerare conformitatea legală :
- Alegeți un scraper care respectă termenii și standardele legale ale site-ului web, mai ales atunci când aveți de-a face cu date sensibile sau personale.
Verificați ocolirea funcției anti-răzuire :
- Multe site-uri web folosesc măsuri anti-răzuire. Asigurați-vă că instrumentul pe care îl selectați poate naviga eficient în acestea, eventual prin funcții precum rotația IP, comutarea agent utilizator și rezolvarea CAPTCHA.
Suport tehnic și comunitate :
- Un instrument cu suport tehnic bun și o comunitate activă de utilizatori poate fi de neprețuit, mai ales atunci când întâmpinați provocări sau trebuie să vă adaptați la schimbările din tehnologia web scraping.
Cele mai bune practici în utilizarea Web Scraper :
- Respectați robots.txt : respectați directivele din fișierul robots.txt al site-ului web pentru a menține practicile etice de scraping.
- Limitarea ratei : pentru a evita supraîncărcarea serverelor site-urilor web, setați scraperul pentru a face cereri la o rată rezonabilă.
- Gestionarea erorilor : implementați o gestionare robustă a erorilor pentru a gestiona cu grație probleme precum expirările de timp sau erorile de server.
- Asigurarea calității datelor : verificați în mod regulat calitatea datelor răzuite pentru a asigura acuratețea și caracterul complet.
- Rămâneți informat : fiți la curent cu cele mai recente evoluții în tehnologiile web scraping și reglementările legale.
Luând în considerare cu atenție acești factori și urmând cele mai bune practici, puteți alege un web scraper care nu numai că satisface nevoile dvs. de colectare a datelor, dar o face și într-o manieră eficientă, etică și conformă legal.
PromptCloud: Cele mai bune soluții Web Scraping pentru nevoile dvs. de date
În domeniul dinamic al colectării și analizei datelor, PromptCloud apare ca lider în furnizarea de soluții de scraping web de ultimă generație. Creat pentru companii și persoane care doresc să valorifice puterea datelor, PromptCloud oferă o gamă de servicii de scraping care se remarcă prin eficiență, fiabilitate și conformitate. Iată de ce PromptCloud este alegerea dvs. de preferat pentru web scraping:
Servicii personalizate de răzuire web :
- Soluții personalizate : PromptCloud înțelege că fiecare cerință de date este unică. Serviciile lor personalizate de web scraping sunt concepute pentru a satisface nevoi specifice, fie că este vorba de colectarea unor volume mari de date sau de extragerea de informații de pe site-uri web complexe.
Scalabilitate și fiabilitate :
- Gestionați nevoile de date la scară largă : infrastructura PromptCloud este construită pentru a gestiona extragerea datelor la scară largă fără efort, asigurând fiabilitatea și coerența în livrarea datelor.
- Garanție ridicată de funcționare : oferă o platformă robustă cu o garanție de funcționare ridicată, asigurând că procesul dvs. de colectare a datelor este neîntrerupt și eficient.
Tehnologie și caracteristici avansate :
- Instrumente de ultimă oră : Utilizând cea mai recentă tehnologie de scraping web, PromptCloud poate naviga prin măsuri sofisticate anti-scraping și conținut încărcat dinamic.
- Date în formate gata de utilizare : oferă date în diverse formate structurate, făcându-le imediat acționabile pentru nevoile dvs. de afaceri.
PromptCloud este un far pentru companii și persoane care doresc să valorifice puterea web scraping fără complexitățile implicate în configurarea și întreținerea unor astfel de sisteme. Cu PromptCloud, obțineți acces la date precise, în timp util și conforme, împuternicindu-vă afacerea să ia decizii în cunoștință de cauză și să rămână în fruntea peisajului competitiv al pieței.
Sunteți gata să deblocați potențialul Web Scraping?
Explorați ofertele PromptCloud și faceți primul pas către transformarea strategiei dvs. de date. Luați legătura cu noi la [email protected] pentru a afla mai multe despre serviciile lor și despre cum acestea pot fi cheia pentru a vă debloca potențialul de date.