
Qu'est-ce qu'un Web Scraper et comment ça marche ?
Publié: 2024-01-16Dans le paysage vaste et en constante évolution d’Internet, les données sont devenues l’élément vital de la prise de décision et de la planification stratégique dans divers secteurs. C’est là que réside l’importance des web scrapers – des outils puissants qui naviguent dans la mer colossale d’informations en ligne. Mais qu’est-ce que le web scraping exactement et pourquoi est-il devenu si crucial à l’ère numérique ?
Le Web scraping, à la base, implique l’extraction automatisée de données à partir de sites Web. Ce processus, souvent effectué par des logiciels ou des scripts spécialisés, permet de collecter des informations spécifiques à partir de pages Web et de les transformer dans un format structuré, généralement pour analyse ou utilisation dans d'autres applications.
Dans un monde où les données sont reines, le web scraping constitue un outil clé. Il permet aux entreprises, aux chercheurs et aux particuliers d'accéder et d'exploiter les données publiques du Web de manière efficace et efficiente. De l'analyse des concurrents et des études de marché au suivi des sentiments sociaux et des projets universitaires, les applications du web scraping sont aussi diverses qu'elles ont un impact.
Qu'est-ce qu'un Web Scraper : les bases
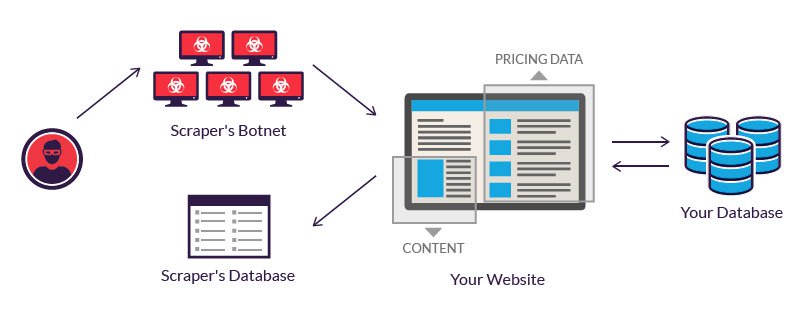
Source : https://www.imperva.com/learn/application-security/web-scraping-attack/
Le Web scraping est un processus qui implique l’extraction automatisée d’informations à partir de sites Web. Cette technique utilise des logiciels ou des scripts spécialisés conçus pour accéder aux pages Web, récupérer les données nécessaires, puis convertir ces données dans un format structuré pour une utilisation ultérieure. La simplicité de cette définition dément cependant la sophistication et la polyvalence du web scraping en tant qu'outil. Maintenant, vous avez peut-être compris ce qu'est un web scraper, alors apprenons comment il fonctionne.
À son niveau le plus fondamental, le web scraping remplit deux fonctions principales :
- Collecte de données : les programmes de web scraping sont capables de naviguer dans les pages Web, d'identifier et de collecter des types spécifiques de données. Cela peut inclure des détails sur les produits provenant de sites de commerce électronique, les cours des actions sur des sites Web financiers, des offres d'emploi sur des portails d'emploi ou tout autre contenu Web accessible au public.
- Transformation des données : Une fois les données collectées, les outils de web scraping transforment ces données web non structurées (souvent du code HTML) dans un format structuré tel que CSV, Excel ou une base de données. Cette transformation rend les données plus faciles à analyser, à manipuler et à utiliser à diverses fins.
Ces fonctions de base du web scraping en font un outil puissant pour toute personne ayant besoin d'accéder rapidement et efficacement à de grandes quantités d'informations sur le Web. Qu'il s'agisse d'une petite entreprise surveillant les prix de ses concurrents ou d'une grande entreprise analysant les tendances du marché, le web scraping offre un moyen de collecter des données pertinentes sans avoir besoin d'une extraction manuelle. Dans les sections suivantes, nous approfondirons le fonctionnement de ces outils de scraping, leurs différents types et leur vaste gamme d'applications dans le monde numérique.
Comment fonctionnent les Web Scrapers : une plongée technique
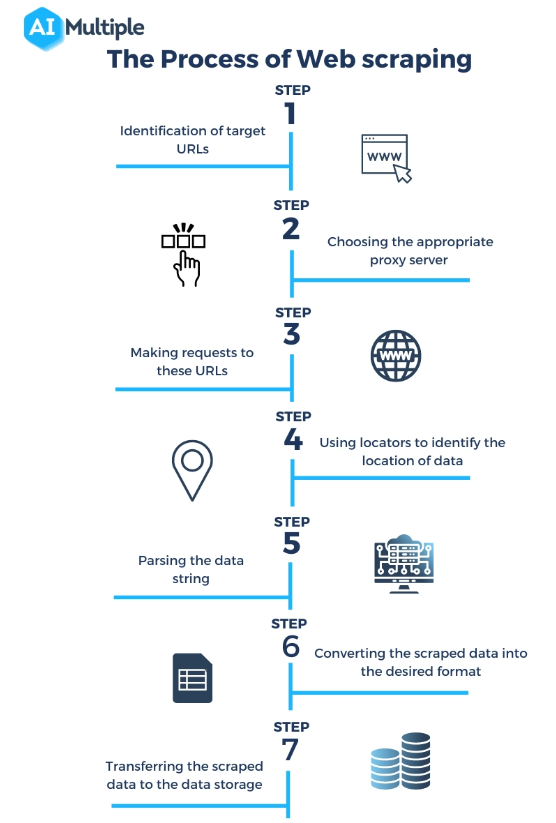
Source : https://research.aimultiple.com/web-scraping-vs-api/
Qu'est-ce qu'un grattoir Web ? Le web scraping peut sembler magique, mais il s'agit en fait d'un processus technique bien orchestré impliquant plusieurs étapes pour accéder, extraire et traiter les données des sites Web. Voici un aperçu plus approfondi du fonctionnement des web scrapers :
Envoi d'une requête au serveur Web :
La première étape du web scraping consiste pour le scraper à envoyer une requête au serveur web hébergeant la page web cible. Ceci est similaire à ce qui se produit lorsque vous saisissez une URL dans votre navigateur ; la différence est que le scraper envoie la requête par programme.
Récupération de la page Web :
Une fois la demande envoyée, le serveur répond avec le contenu de la page Web, généralement au format HTML. Le scraper télécharge ensuite ce contenu pour traitement. Dans certains cas, le rendu JavaScript peut être nécessaire pour charger complètement le contenu de la page, ce que certains scrapers avancés peuvent gérer.
Analyser le contenu HTML :
La page Web récupérée est généralement au format HTML, qui est un langage de balisage avec une structure spécifique. Le scraper analyse ce contenu HTML pour donner un sens à sa structure – identifiant les en-têtes, les paragraphes, les liens et autres éléments en fonction de leurs balises HTML.
Extraction des données pertinentes :
Après l'analyse, le scraper identifie et extrait les données spécifiques d'intérêt. Il peut s'agir de descriptions de produits et de prix, de textes d'articles ou de données statistiques. L'extraction est basée sur les éléments HTML et leurs attributs, comme les noms de classe ou les identifiants.
Transformation et stockage des données :
Les données extraites, encore sous forme brute, sont ensuite transformées dans un format structuré comme CSV, JSON, ou directement dans une base de données. Cette étape est cruciale pour rendre les données utilisables pour l’analyse ou l’intégration avec d’autres applications.
Relever les défis :
Le web scraping peut rencontrer des défis tels que le contenu chargé dynamiquement, les mesures anti-scraping prises par les sites Web et le maintien de l'état de la session. Les scrapers avancés les parcourent en imitant le comportement de navigation humain, en faisant pivoter les adresses IP et en gérant les cookies et les sessions.
Respecter les limites juridiques et éthiques :
Les web scrapers éthiques sont programmés pour respecter les limites légales du web scraping. Cela implique de respecter les directives relatives au fichier robots.txt du site Web, d'éviter une charge excessive du serveur et de garantir le respect des lois sur la confidentialité des données.
Types de Web Scrapers : Explorer les variétés
Les outils de web scraping se présentent sous différentes formes, chacune étant conçue pour répondre à des besoins et à des défis spécifiques. Comprendre ces différents types aide à sélectionner le bon outil pour le travail. Explorons quelques-uns des types courants de scrapers Web :
Grattoirs HTML :
- Fonctionnalité : les scrapers HTML sont la forme la plus basique de scrapers Web. Ils téléchargent le contenu HTML des pages Web et extraient les données en analysant le code HTML.
- Cas d'utilisation : Idéal pour les sites Web statiques où les données sont intégrées directement dans le HTML.
Grattoirs API :
- Fonctionnalité : Ces scrapers extraient les données des API (Application Programming Interfaces) fournies par les sites Web. Au lieu d'analyser le HTML, ils envoient des requêtes à un point de terminaison d'API et reçoivent des données dans un format structuré comme JSON ou XML.
- Cas d'utilisation : adapté aux sites Web dotés d'API publiques, offrant un moyen d'extraction de données plus efficace et plus fiable.
Scrapers basés sur un navigateur :
- Fonctionnalité : Ces outils imitent un navigateur Web pour interagir avec les pages Web. Ils peuvent exécuter des requêtes JavaScript et AJAX, ce qui les rend capables de récupérer du contenu dynamique.
- Cas d'utilisation : essentiel pour les sites Web qui s'appuient fortement sur JavaScript pour le rendu du contenu, tels que les applications Web modernes.
Grattoirs de navigateur sans tête :
- Fonctionnalité : fonctionnant de la même manière que les scrapers basés sur un navigateur, ceux-ci utilisent des navigateurs sans tête (navigateurs sans interface utilisateur graphique) pour afficher les pages Web. Ils peuvent gérer des pages Web complexes nécessitant une gestion de session, des cookies et l'exécution de JavaScript.
- Cas d'utilisation : utile pour récupérer les données de sites Web complexes et dynamiques et d'applications à page unique (SPA).
Scrapers Web visuels :
- Fonctionnalité : Il s'agit de scrapers conviviaux dotés d'une interface graphique qui permettent aux utilisateurs de sélectionner visuellement des points de données sur une page Web. Ils sont moins techniques et ne nécessitent pas de connaissances en programmation.
- Cas d'utilisation : Idéal pour les utilisateurs qui ne sont pas des programmeurs mais qui ont besoin de récupérer des données sur des sites Web sans configuration complexe.
Grattoirs Web SaaS :
- Fonctionnalité : Ceux-ci sont proposés sous forme de service par des sociétés spécialisées dans le web scraping. Ils gèrent les complexités du scraping et fournissent des données dans un format prêt à l’emploi.
- Cas d'utilisation : convient aux entreprises qui ont besoin de fonctionnalités de web scraping mais ne souhaitent pas s'occuper des aspects techniques.
Grattoirs personnalisés :
- Fonctionnalité : Conçus pour des exigences spécifiques, ces scrapers sont conçus pour répondre à des besoins uniques d'extraction de données, impliquant souvent une logique et des fonctionnalités complexes.
- Cas d'utilisation : nécessaire lorsqu'il s'agit d'opérations de grattage à grande échelle ou très complexes que les outils disponibles dans le commerce ne peuvent pas gérer.
Chaque type de web scraper a ses atouts et est adapté à différents scénarios. Du simple scraping HTML au traitement du contenu dynamique et des API, le choix dépend de la structure du site Web, de la complexité de la tâche et de l'expertise technique de l'utilisateur. Dans les sections suivantes, nous approfondirons les applications pratiques de ces outils et la manière dont ils transforment les données en informations précieuses.

Le paysage juridique : comprendre la conformité et l'éthique dans le Web Scraping
Le web scraping, bien qu’il s’agisse d’un outil puissant d’extraction de données, opère dans un paysage juridique et éthique complexe. Il est crucial pour les entreprises et les particuliers qui s'engagent dans le web scraping de comprendre les considérations juridiques et éthiques afin de garantir la conformité et de maintenir de bonnes pratiques. Cette section met en lumière ces aspects :
Considérations juridiques dans le Web Scraping :
- Lois sur le droit d'auteur : Les données publiées sur Internet sont souvent protégées par les lois sur le droit d'auteur. La suppression de données protégées par des droits d'auteur sans autorisation peut entraîner des problèmes juridiques.
- Accords de conditions de service : de nombreux sites Web incluent des clauses dans leurs conditions de service (ToS) qui interdisent explicitement le web scraping. La violation de ces conditions peut entraîner des poursuites judiciaires de la part du propriétaire du site Web.
- Lois sur la confidentialité des données : des réglementations telles que le RGPD (Règlement général sur la protection des données) et le CCPA (California Consumer Privacy Act) imposent des règles strictes sur la manière dont les données personnelles peuvent être collectées et utilisées. Les scrapers Web doivent garantir le respect de ces lois sur la confidentialité.
Considérations éthiques dans le Web Scraping :
- Respect du fichier robots.txt : ce fichier sur les sites Web précise comment et ce que les robots d'exploration sont autorisés à gratter. Le scraping éthique du Web implique le respect de ces directives.
- Minimiser la charge du serveur : un scraping agressif peut surcharger le serveur d'un site Web, provoquant potentiellement son crash. Les scrapers éthiques sont conçus pour imiter la vitesse et les modèles de navigation humaine afin d'éviter de tels problèmes.
- Transparence et finalité : Le scraping éthique implique d'être transparent sur qui collecte les données et dans quel but. Cela signifie également éviter l’extraction d’informations sensibles.
Meilleures pratiques pour le Web Scraping juridique et éthique :
- Demander l'autorisation : dans la mesure du possible, il est préférable de demander l'autorisation du propriétaire du site Web avant de récupérer ses données, surtout si les données sont sensibles ou protégées par le droit d'auteur.
- Adhérez aux normes juridiques : assurez-vous que vos activités de scraping sont conformes aux lois locales et internationales en vigueur.
- Utiliser les données de manière responsable : les données collectées doivent être utilisées de manière éthique et responsable, en respectant la vie privée des utilisateurs et en évitant de nuire aux personnes concernées.
Naviguer dans les zones grises :
- La légalité du web scraping se situe souvent dans des zones grises, en fonction de la manière dont les données sont utilisées, de la nature des données et de la juridiction. Il est conseillé de consulter des experts juridiques en cas de doute.
Comprendre et respecter les considérations juridiques et éthiques liées au web scraping n'est pas seulement une question de conformité, mais également de maintien de l'intégrité et de la réputation de votre entreprise. À mesure que nous avançons, les pratiques de web scraping continueront probablement d'évoluer avec le paysage juridique, rendant impératif pour les utilisateurs de rester informés et consciencieux.
Choisir un Web Scraper : conseils et bonnes pratiques
Choisir le bon web scraper est une décision cruciale qui peut avoir un impact significatif sur l’efficacité de vos efforts de collecte de données. Voici quelques conseils et bonnes pratiques pour vous guider dans le choix de l’outil de web scraping idéal et dans son utilisation efficace :
Évaluez vos besoins :
- Comprenez vos besoins : avant de plonger dans la myriade d'outils de scraping Web disponibles, clarifiez ce que vous devez gratter, la fréquence à laquelle vous devez le faire et la complexité des données et des sites Web impliqués.
- Évolutivité : déterminez si vous avez besoin d'un outil capable de gérer le scraping à grande échelle ou si une solution plus simple et plus directe suffira.
Évaluez les fonctionnalités :
- Facilité d'utilisation : Si vous n'êtes pas techniquement enclin, recherchez un grattoir doté d'une interface conviviale ou de fonctionnalités visuelles de type pointer-cliquer.
- Capacités d'extraction de données : assurez-vous que l'outil peut extraire le type de données dont vous avez besoin (texte, images, etc.) et gérer le contenu dynamique chargé avec JavaScript ou AJAX.
- Options d'exportation de données : Vérifiez les formats dans lesquels le scraper peut exporter des données (CSV, JSON, bases de données, etc.) et assurez-vous qu'ils répondent à vos exigences.
Pensez à la conformité légale :
- Choisissez un scraper qui respecte les conditions d’utilisation du site Web et les normes légales, notamment lorsqu’il s’agit de données sensibles ou personnelles.
Vérifiez le contournement de la fonction anti-grattage :
- De nombreux sites Web utilisent des mesures anti-grattage. Assurez-vous que l'outil que vous sélectionnez peut naviguer efficacement dans ces éléments, éventuellement grâce à des fonctionnalités telles que la rotation IP, la commutation utilisateur-agent et la résolution CAPTCHA.
Support technique et communauté :
- Un outil doté d'un bon support technique et d'une communauté d'utilisateurs active peut s'avérer inestimable, en particulier lorsque vous rencontrez des défis ou devez vous adapter aux changements dans la technologie de web scraping.
Meilleures pratiques d'utilisation de Web Scraper :
- Respectez robots.txt : respectez les directives du fichier robots.txt du site Web pour maintenir des pratiques de scraping éthiques.
- Limitation du débit : pour éviter de surcharger les serveurs du site Web, configurez votre scraper pour qu'il effectue des requêtes à un tarif raisonnable.
- Gestion des erreurs : implémentez une gestion robuste des erreurs pour gérer les problèmes tels que les délais d'attente ou les erreurs de serveur avec élégance.
- Assurance qualité des données : vérifiez régulièrement la qualité des données récupérées pour garantir leur exactitude et leur exhaustivité.
- Restez informé : restez au courant des derniers développements en matière de technologies de web scraping et de réglementations légales.
En examinant attentivement ces facteurs et en suivant les meilleures pratiques, vous pouvez choisir un grattoir Web qui non seulement répond à vos besoins en matière de collecte de données, mais le fait également de manière efficace, éthique et conforme à la loi.
PromptCloud : meilleures solutions de grattage Web pour vos besoins en données
Dans le domaine dynamique de la collecte et de l'analyse de données, PromptCloud apparaît comme un leader dans la fourniture de solutions de web scraping de pointe. Adapté aux entreprises et aux particuliers qui cherchent à exploiter la puissance des données, PromptCloud propose une gamme de services de scraping qui se distinguent par leur efficacité, leur fiabilité et leur conformité. Voici pourquoi PromptCloud est votre choix idéal pour le web scraping :
Services de Web Scraping personnalisés :
- Solutions sur mesure : PromptCloud comprend que chaque exigence en matière de données est unique. Leurs services personnalisés de scraping Web sont conçus pour répondre à des besoins spécifiques, qu'il s'agisse de récupérer de gros volumes de données ou d'extraire des informations de sites Web complexes.
Évolutivité et fiabilité :
- Gérer les besoins en données à grande échelle : l'infrastructure de PromptCloud est conçue pour gérer sans effort l'extraction de données à grande échelle, garantissant ainsi la fiabilité et la cohérence de la livraison des données.
- Garantie de disponibilité élevée : ils fournissent une plate-forme robuste avec une garantie de disponibilité élevée, garantissant que votre processus de collecte de données est ininterrompu et efficace.
Technologie et fonctionnalités avancées :
- Outils de pointe : Utilisant la dernière technologie de web scraping, PromptCloud peut naviguer à travers des mesures anti-scraping sophistiquées et du contenu chargé dynamiquement.
- Données dans des formats prêts à l'emploi : ils fournissent des données dans différents formats structurés, les rendant immédiatement exploitables pour les besoins de votre entreprise.
PromptCloud constitue une référence pour les entreprises et les particuliers cherchant à tirer parti de la puissance du web scraping sans les complexités liées à la mise en place et à la maintenance de tels systèmes. Avec PromptCloud, vous avez accès à des données précises, opportunes et conformes, permettant à votre entreprise de prendre des décisions éclairées et de garder une longueur d'avance dans le paysage concurrentiel du marché.
Prêt à libérer le potentiel du Web Scraping ?
Explorez les offres de PromptCloud et faites le premier pas vers la transformation de votre stratégie de données. Contactez-nous à [email protected] pour en savoir plus sur leurs services et comment ils peuvent être la clé pour libérer le potentiel de vos données.