
Cos'è un Web Scraper e come funziona?
Pubblicato: 2024-01-16Nel panorama vasto e in continua evoluzione di Internet, i dati sono diventati la linfa vitale del processo decisionale e della pianificazione strategica in vari settori. Qui sta l’importanza dei web scraper: potenti strumenti che navigano nel colossale mare delle informazioni online. Ma cos’è esattamente il web scraping e perché è diventato così cruciale nell’era digitale?
Il web scraping, essenzialmente, comporta l’estrazione automatizzata di dati dai siti web. Questo processo, spesso eseguito da software o script specializzati, consente la raccolta di informazioni specifiche dalle pagine Web e la loro trasformazione in un formato strutturato, tipicamente per l'analisi o l'utilizzo in altre applicazioni.
In un mondo in cui i dati la fanno da padrone, il web scraping funge da fattore chiave. Consente ad aziende, ricercatori e privati di accedere e sfruttare i dati web pubblici in modo efficiente ed efficace. Dall'analisi della concorrenza e dalle ricerche di mercato al monitoraggio dei sentimenti sociali e dei progetti accademici, le applicazioni del web scraping sono tanto diverse quanto di grande impatto.
Cos'è un Web Scraper: nozioni di base
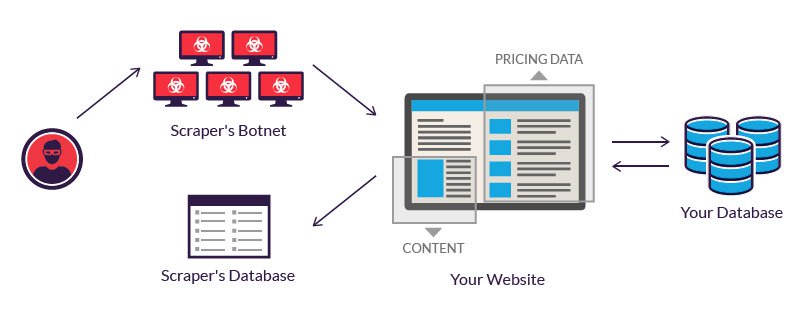
Fonte: https://www.imperva.com/learn/application-security/web-scraping-attack/
Il web scraping è un processo che prevede l'estrazione automatizzata di informazioni dai siti web. Questa tecnica utilizza software o script specializzati progettati per accedere alle pagine Web, recuperare i dati necessari e quindi convertirli in un formato strutturato per un ulteriore utilizzo. La semplicità di questa definizione, tuttavia, smentisce la sofisticatezza e la versatilità del web scraping come strumento. Ora potresti aver capito cos'è un web scraper, quindi impariamo come funziona.
Al suo livello più fondamentale, il web scraping svolge due funzioni principali:
- Raccolta dati : i programmi di web scraping sono adatti a navigare attraverso le pagine web, identificando e raccogliendo tipi specifici di dati. Ciò potrebbe includere dettagli sui prodotti da siti di e-commerce, prezzi delle azioni da siti Web finanziari, offerte di lavoro da portali di lavoro o qualsiasi altro contenuto Web accessibile al pubblico.
- Trasformazione dei dati : una volta raccolti i dati, gli strumenti di web scraping trasformano questi dati web non strutturati (spesso codice HTML) in un formato strutturato come CSV, Excel o un database. Questa trasformazione rende i dati più facili da analizzare, manipolare e utilizzare per vari scopi.
Queste funzioni di base del web scraping lo rendono uno strumento potente per chiunque abbia bisogno di accedere a grandi quantità di informazioni basate sul web in modo rapido ed efficiente. Che si tratti di una piccola impresa che monitora i prezzi della concorrenza o di una grande azienda che analizza le tendenze del mercato, il web scraping fornisce un mezzo per raccogliere dati rilevanti senza la necessità di estrazione manuale. Nelle prossime sezioni approfondiremo il funzionamento di questi strumenti di scraping, i loro diversi tipi e la loro vasta gamma di applicazioni nel mondo digitale.
Come funzionano i Web Scraper: un'immersione tecnica
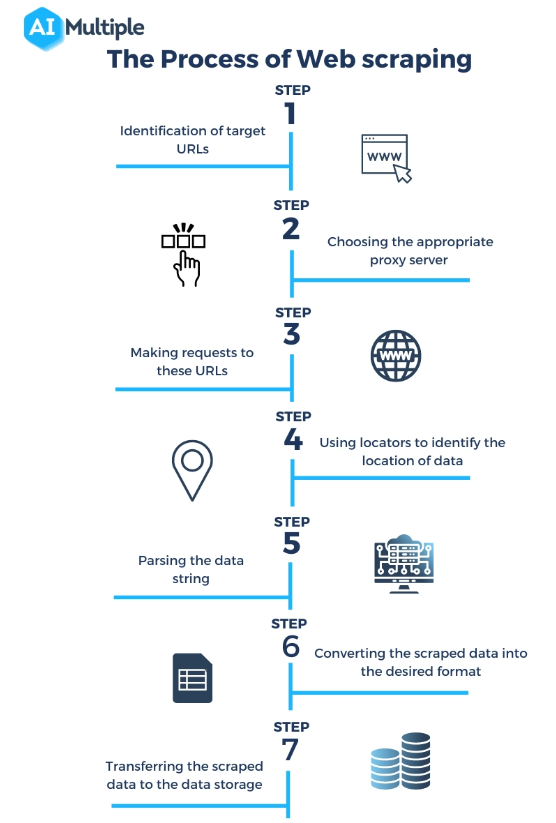
Fonte: https://research.aimultiple.com/web-scraping-vs-api/
Cos'è un web scraper? Il web scraping potrebbe sembrare magico, ma in realtà è un processo tecnico ben orchestrato che prevede diversi passaggi per accedere, estrarre ed elaborare i dati dai siti web. Ecco uno sguardo più da vicino su come funzionano i web scraper:
Invio di una richiesta al server Web :
Il primo passo nel web scraping è che lo scraper invii una richiesta al server web che ospita la pagina web di destinazione. Questo è simile a ciò che accade quando digiti un URL nel tuo browser; la differenza è che lo scraper invia la richiesta a livello di codice.
Recupero della pagina Web :
Una volta inviata la richiesta, il server risponde con il contenuto della pagina web, tipicamente in formato HTML. Il raschietto scarica quindi questo contenuto per l'elaborazione. In alcuni casi, potrebbe essere necessario il rendering JavaScript per caricare completamente il contenuto della pagina, cosa che alcuni scraper avanzati possono gestire.
Analisi del contenuto HTML :
La pagina web recuperata è solitamente in formato HTML, che è un linguaggio di markup con una struttura specifica. Lo scraper analizza questo contenuto HTML per dare un senso alla sua struttura, identificando intestazioni, paragrafi, collegamenti e altri elementi in base ai relativi tag HTML.
Estrazione dei dati rilevanti :
Dopo l'analisi, il raschietto identifica ed estrae i dati specifici di interesse. Potrebbe trattarsi di qualsiasi cosa, dalle descrizioni dei prodotti e i prezzi al testo degli articoli o ai dati statistici. L'estrazione si basa sugli elementi HTML e sui loro attributi, come nomi di classi o ID.
Trasformazione e archiviazione dei dati :
I dati estratti, ancora in forma grezza, vengono poi trasformati in un formato strutturato come CSV, JSON, o direttamente in un database. Questo passaggio è fondamentale per rendere i dati utilizzabili per l'analisi o l'integrazione con altre applicazioni.
Gestire le sfide :
Il Web scraping può incontrare sfide come contenuti caricati dinamicamente, misure anti-scraping da parte dei siti Web e mantenimento dello stato della sessione. Gli scraper avanzati navigano tra questi imitando il comportamento di navigazione umana, ruotando gli indirizzi IP e gestendo cookie e sessioni.
Rispetto dei confini legali ed etici :
I web scraper etici sono programmati per rispettare i limiti legali del web scraping. Ciò implica aderire alle linee guida del file robots.txt del sito Web, evitare un carico eccessivo del server e garantire il rispetto delle leggi sulla privacy dei dati.
Tipi di web scraper: esplorare le varietà
Gli strumenti di web scraping sono disponibili in varie forme, ciascuna progettata per soddisfare esigenze e sfide specifiche. Comprendere questi diversi tipi aiuta a selezionare lo strumento giusto per il lavoro. Esploriamo alcuni dei tipi più comuni di web scraper:
Raschiatori HTML :
- Funzionalità : gli scraper HTML sono la forma più elementare di scraper web. Scaricano il contenuto HTML delle pagine Web ed estraggono i dati analizzando il codice HTML.
- Casi d'uso : ideale per siti Web statici in cui i dati sono incorporati direttamente nell'HTML.
Raschiatori API :
- Funzionalità : questi raschiatori estraggono dati dalle API (Interfacce di programmazione dell'applicazione) fornite dai siti Web. Invece di analizzare l'HTML, effettuano richieste a un endpoint API e ricevono dati in un formato strutturato come JSON o XML.
- Casi d'uso : adatto per siti Web con API pubbliche, offre un modo più efficiente e affidabile di estrazione dei dati.
Scraper basati su browser :
- Funzionalità : questi strumenti imitano un browser web per interagire con le pagine web. Possono eseguire richieste JavaScript e AJAX, rendendoli in grado di estrarre contenuti dinamici.
- Casi d'uso : essenziali per i siti Web che fanno molto affidamento su JavaScript per il rendering dei contenuti, come le moderne applicazioni Web.
Raschiatori per browser senza testa :
- Funzionalità : funzionano in modo simile agli scraper basati su browser, utilizzano browser headless (browser senza interfaccia utente grafica) per visualizzare le pagine web. Possono gestire pagine Web complesse che richiedono la gestione delle sessioni, i cookie e l'esecuzione di JavaScript.
- Casi d'uso : utile per estrarre dati da siti Web complessi e dinamici e applicazioni a pagina singola (SPA).
Raschiatori Web visivi :
- Funzionalità : si tratta di raschiatori intuitivi con un'interfaccia grafica che consente agli utenti di selezionare visivamente i punti dati su una pagina web. Sono meno tecnici e non richiedono conoscenze di programmazione.
- Casi d'uso : ideale per gli utenti che non sono programmatori ma hanno bisogno di estrarre dati da siti Web senza configurazioni complesse.
Raschiatori Web SaaS :
- Funzionalità : Sono offerti come servizio da aziende specializzate in web scraping. Gestiscono le complessità dello scraping e forniscono dati in un formato pronto all'uso.
- Casi d'uso : adatto per le aziende che richiedono funzionalità di web scraping ma non vogliono occuparsi degli aspetti tecnici.
Raschiatori personalizzati :
- Funzionalità : costruiti per requisiti specifici, questi raschiatori sono personalizzati per soddisfare esigenze uniche di estrazione dei dati, che spesso coinvolgono logiche e funzionalità complesse.
- Casi d'uso : necessari quando si hanno a che fare con operazioni di raschiatura su larga scala o altamente complesse che gli strumenti standard non sono in grado di gestire.
Ogni tipo di raschietto web ha i suoi punti di forza ed è adatto a diversi scenari. Dal semplice scraping HTML alla gestione di contenuti dinamici e API, la scelta dipende dalla struttura del sito web, dalla complessità dell'attività e dalle competenze tecniche dell'utente. Nelle prossime sezioni approfondiremo le applicazioni pratiche di questi strumenti e il modo in cui trasformano i dati in informazioni preziose.

Il panorama legale: comprendere la conformità e l'etica nel web scraping
Il web scraping, pur essendo un potente strumento per l’estrazione dei dati, opera in un panorama giuridico ed etico complesso. È fondamentale che le aziende e gli individui impegnati nel web scraping comprendano gli aspetti legali e le considerazioni etiche per garantire la conformità e mantenere buone pratiche. Questa sezione mette in luce questi aspetti:
Considerazioni legali sul Web Scraping :
- Leggi sul copyright : i dati pubblicati su Internet sono spesso protetti dalle leggi sul copyright. Lo scraping di dati protetti da copyright senza autorizzazione può portare a problemi legali.
- Accordi sui termini di servizio : molti siti Web includono clausole nei propri Termini di servizio (ToS) che vietano esplicitamente il web scraping. La violazione di questi termini può comportare azioni legali da parte del proprietario del sito web.
- Leggi sulla privacy dei dati : regolamenti come il GDPR (Regolamento generale sulla protezione dei dati) e il CCPA (California Consumer Privacy Act) impongono regole rigide su come i dati personali possono essere raccolti e utilizzati. I web scraper devono garantire il rispetto di queste leggi sulla privacy.
Considerazioni etiche sul web scraping :
- Rispettando robots.txt : questo file sui siti web specifica come e cosa i web crawler possono raschiare. Il web scraping etico implica il rispetto di queste linee guida.
- Riduzione al minimo del carico del server : lo scraping aggressivo può sovraccaricare il server di un sito Web, causandone potenzialmente l'arresto anomalo. I raschiatori etici sono progettati per imitare la velocità e i modelli di navigazione umana per evitare tali problemi.
- Trasparenza e scopo : lo scraping etico implica essere trasparenti su chi raccoglie i dati e per quale scopo. Significa anche evitare l’estrazione di informazioni sensibili.
Migliori pratiche per il web scraping legale ed etico :
- Richiedere l'autorizzazione : ove possibile, è meglio chiedere l'autorizzazione al proprietario del sito Web prima di eliminare i propri dati, soprattutto se i dati sono sensibili o protetti da copyright.
- Aderisci agli standard legali : assicurati che le tue attività di raschiatura siano conformi alle leggi locali e internazionali pertinenti.
- Utilizzare i dati in modo responsabile : i dati raccolti devono essere utilizzati in modo etico e responsabile, rispettando la privacy degli utenti ed evitando danni agli interessati.
Navigazione nelle aree grigie :
- La legalità del web scraping spesso rientra in aree grigie, a seconda di come vengono utilizzati i dati, della natura dei dati e della giurisdizione. Si consiglia di consultare esperti legali in caso di dubbi.
Comprendere e aderire alle considerazioni legali ed etiche nel web scraping non significa solo conformità, ma anche mantenimento dell'integrità e della reputazione della propria attività. Man mano che andiamo avanti, le pratiche di web scraping continueranno probabilmente ad evolversi insieme al panorama legale, rendendo imperativo per gli utenti rimanere informati e coscienziosi.
Scelta di un web scraper: suggerimenti e migliori pratiche
Selezionare il web scraper giusto è una decisione cruciale che può avere un impatto significativo sull'efficacia dei tuoi sforzi di raccolta dati. Ecco alcuni suggerimenti e migliori pratiche per guidarti nella scelta dello strumento di web scraping ideale e nel suo utilizzo efficace:
Valuta le tue esigenze :
- Comprendi le tue esigenze : prima di immergerti nella miriade di strumenti di web scraping disponibili, chiarisci cosa devi eseguire lo scraping, quanto spesso devi farlo e la complessità dei dati e dei siti Web coinvolti.
- Scalabilità : valuta se hai bisogno di uno strumento in grado di gestire lo scraping su larga scala o se sarà sufficiente una soluzione più semplice e diretta.
Valuta le caratteristiche :
- Facilità d'uso : se non sei tecnicamente portato, cerca un raschietto con un'interfaccia intuitiva o funzionalità visive punta e clicca.
- Funzionalità di estrazione dei dati : assicurati che lo strumento possa estrarre il tipo di dati di cui hai bisogno (testo, immagini, ecc.) e gestire contenuti dinamici caricati con JavaScript o AJAX.
- Opzioni di esportazione dei dati : controlla i formati in cui lo scraper può esportare i dati (CSV, JSON, database, ecc.) e assicurati che soddisfino le tue esigenze.
Considera la conformità legale :
- Scegli uno scraper che rispetti i termini di servizio del sito Web e gli standard legali, soprattutto quando si tratta di dati sensibili o personali.
Controllare il bypass della funzione anti-scraping :
- Molti siti Web utilizzano misure anti-scraping. Assicurati che lo strumento selezionato possa esplorarli in modo efficace, possibilmente attraverso funzionalità come la rotazione IP, il cambio di agente utente e la risoluzione di CAPTCHA.
Supporto tecnico e comunità :
- Uno strumento con un buon supporto tecnico e una comunità di utenti attiva può essere prezioso, soprattutto quando si incontrano sfide o è necessario adattarsi ai cambiamenti nella tecnologia di web scraping.
Migliori pratiche nell'utilizzo di Web Scraper :
- Rispetta robots.txt : aderisci alle direttive nel file robots.txt del sito web per mantenere pratiche di scraping etiche.
- Limitazione della velocità : per evitare di sovraccaricare i server del sito Web, imposta il tuo scraper per effettuare richieste a una velocità ragionevole.
- Gestione degli errori : implementa una solida gestione degli errori per gestire con garbo problemi come timeout o errori del server.
- Garanzia della qualità dei dati : controllare regolarmente la qualità dei dati raschiati per garantire accuratezza e completezza.
- Rimani informato : tieniti aggiornato sugli ultimi sviluppi nelle tecnologie di web scraping e nelle normative legali.
Considerando attentamente questi fattori e seguendo le migliori pratiche, puoi scegliere un web scraper che non solo soddisfi le tue esigenze di raccolta dati, ma lo faccia anche in modo efficiente, etico e conforme alla legge.
PromptCloud: le migliori soluzioni di web scraping per le tue esigenze di dati
Nel regno dinamico della raccolta e dell'analisi dei dati, PromptCloud emerge come leader nella fornitura di soluzioni di web scraping all'avanguardia. Pensato per aziende e privati che cercano di sfruttare la potenza dei dati, PromptCloud offre una gamma di servizi di scraping che si distinguono per efficienza, affidabilità e conformità. Ecco perché PromptCloud è la scelta giusta per il web scraping:
Servizi di web scraping personalizzati :
- Soluzioni su misura : PromptCloud comprende che ogni requisito di dati è unico. I loro servizi di web scraping personalizzati sono progettati per soddisfare esigenze specifiche, sia che si tratti di recuperare grandi volumi di dati o di estrarre informazioni da siti Web complessi.
Scalabilità e affidabilità :
- Gestire esigenze di dati su larga scala : l'infrastruttura di PromptCloud è progettata per gestire facilmente l'estrazione di dati su larga scala, garantendo affidabilità e coerenza nella fornitura dei dati.
- Garanzia di tempo di attività elevato : forniscono una piattaforma solida con una garanzia di tempo di attività elevato, garantendo che il processo di raccolta dei dati sia ininterrotto ed efficiente.
Tecnologia e caratteristiche avanzate :
- Strumenti all'avanguardia : utilizzando la più recente tecnologia di web scraping, PromptCloud può navigare attraverso sofisticate misure anti-scraping e contenuti caricati dinamicamente.
- Dati in formati pronti all'uso : forniscono dati in vari formati strutturati, rendendoli immediatamente utilizzabili per le esigenze aziendali.
PromptCloud rappresenta un faro per aziende e privati che cercano di sfruttare la potenza del web scraping senza le complessità legate alla configurazione e al mantenimento di tali sistemi. Con PromptCloud, ottieni l'accesso a dati accurati, tempestivi e conformi, consentendo alla tua azienda di prendere decisioni informate e rimanere all'avanguardia nel panorama del mercato competitivo.
Pronto a sbloccare il potenziale del Web Scraping?
Esplora le offerte di PromptCloud e fai il primo passo verso la trasformazione della tua strategia sui dati. Contattaci all'indirizzo [email protected] per saperne di più sui loro servizi e su come possono essere la chiave per sbloccare il potenziale dei tuoi dati.