
¿Qué es un Web Scraper y cómo funciona?
Publicado: 2024-01-16En el vasto y siempre cambiante panorama de Internet, los datos se han convertido en el elemento vital de la toma de decisiones y la planificación estratégica en diversos sectores. Aquí radica la importancia de los web scrapers: poderosas herramientas que navegan por el colosal mar de información en línea. Pero, ¿qué es exactamente el web scraping y por qué se ha vuelto tan crucial en la era digital?
El web scraping, en esencia, implica la extracción automatizada de datos de sitios web. Este proceso, a menudo llevado a cabo mediante software o scripts especializados, permite la recopilación de información específica de páginas web y su transformación en un formato estructurado, generalmente para análisis o uso en otras aplicaciones.
En un mundo donde los datos son los reyes, el web scraping sirve como un facilitador clave. Permite a empresas, investigadores e individuos acceder y aprovechar datos web públicos de manera eficiente y efectiva. Desde el análisis de la competencia y la investigación de mercado hasta el seguimiento de los sentimientos sociales y los proyectos académicos, las aplicaciones del web scraping son tan diversas como impactantes.
¿Qué es un Web Scraper? Conceptos básicos
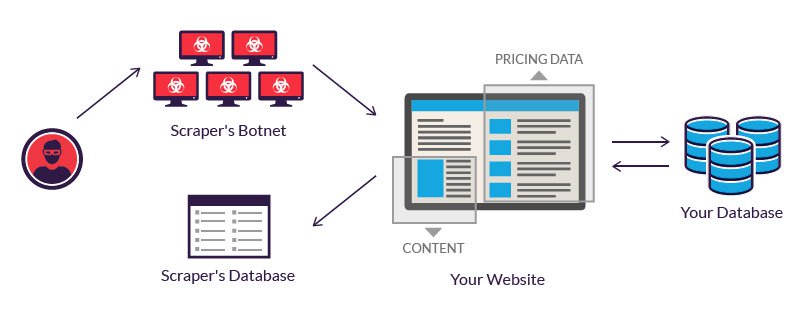
Fuente: https://www.imperva.com/learn/application-security/web-scraping-attack/
El web scraping es un proceso que implica la extracción automatizada de información de sitios web. Esta técnica emplea software o scripts especializados diseñados para acceder a páginas web, recuperar los datos necesarios y luego convertir esos datos a un formato estructurado para su uso posterior. La simplicidad de esta definición, sin embargo, contradice la sofisticación y versatilidad del web scraping como herramienta. Ahora, es posible que hayas entendido qué es un web scraper, así que aprendamos cómo funciona.
En su nivel más fundamental, el web scraping cumple dos funciones principales:
- Recopilación de datos : los programas de raspado web son expertos en navegar a través de páginas web, identificar y recopilar tipos específicos de datos. Esto podría incluir detalles de productos de sitios de comercio electrónico, precios de acciones de sitios web financieros, ofertas de trabajo de portales de empleo o cualquier otro contenido web de acceso público.
- Transformación de datos : una vez que se recopilan los datos, las herramientas de web scraping transforman estos datos web no estructurados (a menudo código HTML) en un formato estructurado como CSV, Excel o una base de datos. Esta transformación hace que los datos sean más fáciles de analizar, manipular y utilizar para diversos fines.
Estas funciones básicas del web scraping lo convierten en una herramienta poderosa para cualquiera que necesite acceder a grandes cantidades de información basada en la web de manera rápida y eficiente. Ya sea que se trate de una pequeña empresa que monitorea los precios de la competencia o de una gran corporación que analiza las tendencias del mercado, el web scraping proporciona un medio para recopilar datos relevantes sin la necesidad de una extracción manual. En las siguientes secciones, profundizaremos en cómo funcionan estas herramientas de scraping, sus diferentes tipos y su amplia gama de aplicaciones en el mundo digital.
Cómo funcionan los Web Scrapers: una inmersión técnica
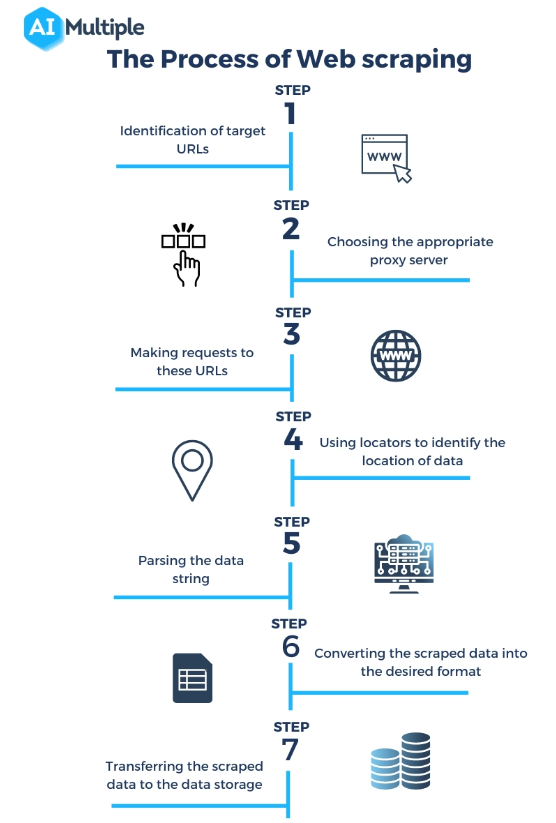
Fuente: https://research.aimultiple.com/web-scraping-vs-api/
¿Qué es un raspador web? El web scraping puede parecer mágico, pero en realidad es un proceso técnico bien orquestado que implica varios pasos para acceder, extraer y procesar datos de sitios web. He aquí un vistazo más de cerca a cómo funcionan los web scrapers:
Envío de una solicitud al servidor web :
El primer paso en el web scraping es que el scraper envíe una solicitud al servidor web que aloja la página web de destino. Esto es similar a lo que sucede cuando escribe una URL en su navegador; la diferencia es que el raspador envía la solicitud mediante programación.
Recuperando la página web :
Una vez enviada la solicitud, el servidor responde con el contenido de la página web, normalmente en formato HTML. Luego, el raspador descarga este contenido para procesarlo. En algunos casos, es posible que se requiera renderizado de JavaScript para cargar completamente el contenido de la página, algo que algunos scrapers avanzados pueden manejar.
Analizando el contenido HTML :
La página web recuperada suele estar en formato HTML, que es un lenguaje de marcado con una estructura específica. El raspador analiza este contenido HTML para darle sentido a su estructura: identifica encabezados, párrafos, enlaces y otros elementos en función de sus etiquetas HTML.
Extracción de datos relevantes :
Después del análisis, el raspador identifica y extrae los datos específicos de interés. Esto podría ser cualquier cosa, desde descripciones y precios de productos hasta textos de artículos o datos estadísticos. La extracción se basa en los elementos HTML y sus atributos, como nombres de clases o ID.
Transformación y almacenamiento de datos :
Los datos extraídos, aún en forma sin procesar, se transforman a un formato estructurado como CSV, JSON o directamente a una base de datos. Este paso es crucial para que los datos sean utilizables para el análisis o la integración con otras aplicaciones.
Manejo de desafíos :
El web scraping puede encontrar desafíos como contenido cargado dinámicamente, medidas anti-scraping por parte de los sitios web y mantenimiento del estado de la sesión. Los raspadores avanzados navegan por ellos imitando el comportamiento de navegación humana, rotando direcciones IP y administrando cookies y sesiones.
Respetar los límites legales y éticos :
Los web scrapers éticos están programados para respetar los límites legales del web scraping. Esto implica cumplir con las pautas del archivo robots.txt del sitio web, evitar una carga excesiva del servidor y garantizar el cumplimiento de las leyes de privacidad de datos.
Tipos de web scrapers: explorando las variedades
Las herramientas de web scraping vienen en varias formas, cada una diseñada para satisfacer necesidades y desafíos específicos. Comprender estos diferentes tipos ayuda a seleccionar la herramienta adecuada para el trabajo. Exploremos algunos de los tipos comunes de web scrapers:
Raspadores HTML :
- Funcionalidad : los scrapers HTML son la forma más básica de scrapers web. Descargan el contenido HTML de las páginas web y extraen datos analizando el código HTML.
- Casos de uso : ideal para sitios web estáticos donde los datos están incrustados directamente en HTML.
Rascadores API :
- Funcionalidad : estos raspadores extraen datos de las API (interfaces de programación de aplicaciones) proporcionadas por los sitios web. En lugar de analizar HTML, realizan solicitudes a un punto final API y reciben datos en un formato estructurado como JSON o XML.
- Casos de uso : adecuado para sitios web con API públicas, ya que ofrece una forma más eficiente y confiable de extracción de datos.
Scrapers basados en navegador :
- Funcionalidad : estas herramientas imitan un navegador web para interactuar con páginas web. Pueden ejecutar solicitudes de JavaScript y AJAX, lo que los hace capaces de extraer contenido dinámico.
- Casos de uso : esencial para sitios web que dependen en gran medida de JavaScript para la representación de contenido, como las aplicaciones web modernas.
Scrapers de navegador sin cabeza :
- Funcionalidad : funcionan de manera similar a los raspadores basados en navegador y utilizan navegadores sin cabeza (navegadores sin una interfaz gráfica de usuario) para representar páginas web. Pueden manejar páginas web complejas que requieren administración de sesiones, cookies y ejecución de JavaScript.
- Casos de uso : útil para extraer datos de sitios web complejos y dinámicos y aplicaciones de una sola página (SPA).
Raspadores web visuales :
- Funcionalidad : son raspadores fáciles de usar con una interfaz gráfica que permite a los usuarios seleccionar visualmente puntos de datos en una página web. Son menos técnicos y no requieren conocimientos de programación.
- Casos de uso : ideal para usuarios que no son programadores pero que necesitan extraer datos de sitios web sin una configuración compleja.
Raspadores web SaaS :
- Funcionalidad : Son ofrecidos como servicio por empresas especializadas en web scraping. Manejan las complejidades del scraping y proporcionan datos en un formato listo para usar.
- Casos de uso : Adecuado para empresas que requieren capacidades de web scraping pero no quieren ocuparse de los aspectos técnicos.
Rascadores personalizados :
- Funcionalidad : creados para requisitos específicos, estos raspadores están diseñados para satisfacer necesidades únicas de extracción de datos, que a menudo implican lógica y características complejas.
- Casos de uso : Necesario cuando se trata de operaciones de raspado a gran escala o altamente complejas que las herramientas disponibles en el mercado no pueden manejar.
Cada tipo de web scraper tiene sus puntos fuertes y se adapta a diferentes escenarios. Desde el simple raspado de HTML hasta el manejo de contenido dinámico y API, la elección depende de la estructura del sitio web, la complejidad de la tarea y la experiencia técnica del usuario. En las siguientes secciones, profundizaremos en las aplicaciones prácticas de estas herramientas y cómo transforman los datos en información valiosa.

El panorama legal: comprensión del cumplimiento y la ética en el web scraping
El web scraping, si bien es una poderosa herramienta para la extracción de datos, opera en un panorama legal y ético complejo. Es fundamental que las empresas y las personas que participan en el web scraping comprendan los aspectos legales y las consideraciones éticas para garantizar el cumplimiento y mantener buenas prácticas. Esta sección arroja luz sobre estos aspectos:
Consideraciones legales en el web scraping :
- Leyes de derechos de autor : los datos publicados en Internet suelen estar protegidos por leyes de derechos de autor. La extracción de datos con derechos de autor sin permiso puede generar problemas legales.
- Acuerdos de términos de servicio : muchos sitios web incluyen cláusulas en sus Términos de servicio (ToS) que prohíben explícitamente el web scraping. La violación de estos términos puede dar lugar a acciones legales por parte del propietario del sitio web.
- Leyes de privacidad de datos : regulaciones como GDPR (Reglamento general de protección de datos) y CCPA (Ley de privacidad del consumidor de California) imponen reglas estrictas sobre cómo se pueden recopilar y utilizar los datos personales. Los web scrapers deben garantizar el cumplimiento de estas leyes de privacidad.
Consideraciones éticas en el web scraping :
- Respetando el archivo robots.txt : este archivo en los sitios web especifica cómo y qué rastreadores web pueden realizar scraping. El web scraping ético implica cumplir con estas pautas.
- Minimizar la carga del servidor : el scraping agresivo puede sobrecargar el servidor de un sitio web y provocar su falla. Los raspadores éticos están diseñados para imitar la velocidad y los patrones de navegación humana para evitar tales problemas.
- Transparencia y propósito : el scraping ético implica ser transparente sobre quién recopila los datos y con qué propósito. También significa evitar la extracción de información sensible.
Mejores prácticas para el web scraping legal y ético :
- Solicite permiso : siempre que sea posible, es mejor solicitar permiso al propietario del sitio web antes de extraer sus datos, especialmente si los datos son confidenciales o están protegidos por derechos de autor.
- Cumpla con los estándares legales : asegúrese de que sus actividades de scraping cumplan con las leyes locales e internacionales pertinentes.
- Utilice los datos de forma responsable : Los datos recopilados deben utilizarse de forma ética y responsable, respetando la privacidad del usuario y evitando daños a los interesados.
Navegando por áreas grises :
- La legalidad del web scraping a menudo cae en áreas grises, dependiendo de cómo se utilizan los datos, la naturaleza de los datos y la jurisdicción. Es recomendable consultar a expertos legales en caso de duda.
Comprender y cumplir las consideraciones legales y éticas en el web scraping no se trata solo de cumplimiento, sino también de mantener la integridad y la reputación de su negocio. A medida que avancemos, es probable que las prácticas de web scraping sigan evolucionando junto con el panorama legal, lo que hace que sea imperativo que los usuarios se mantengan informados y conscientes.
Elegir un Web Scraper: consejos y mejores prácticas
Seleccionar el web scraper adecuado es una decisión crucial que puede afectar significativamente la efectividad de sus esfuerzos de recopilación de datos. A continuación se ofrecen algunos consejos y mejores prácticas que le guiarán a la hora de elegir la herramienta de web scraping ideal y utilizarla de forma eficaz:
Evalúe sus necesidades :
- Comprenda sus requisitos : antes de sumergirse en la gran cantidad de herramientas de raspado web disponibles, aclare qué necesita raspar, con qué frecuencia debe hacerlo y la complejidad de los datos y los sitios web involucrados.
- Escalabilidad : considere si necesita una herramienta que pueda manejar el scraping a gran escala o si una solución más simple y directa será suficiente.
Evalúe las características :
- Facilidad de uso : si no tiene conocimientos técnicos, busque un raspador con una interfaz fácil de usar o funciones visuales de apuntar y hacer clic.
- Capacidades de extracción de datos : asegúrese de que la herramienta pueda extraer el tipo de datos que necesita (texto, imágenes, etc.) y manejar contenido dinámico cargado con JavaScript o AJAX.
- Opciones de exportación de datos : verifique los formatos en los que el raspador puede exportar datos (CSV, JSON, bases de datos, etc.) y asegúrese de que cumplan con sus requisitos.
Considere el cumplimiento legal :
- Elija un raspador que respete los términos de servicio del sitio web y los estándares legales, especialmente cuando se trata de datos personales o confidenciales.
Verifique la omisión de la función anti-raspado :
- Muchos sitios web emplean medidas anti-scraping. Asegúrese de que la herramienta que seleccione pueda navegar por ellos de manera efectiva, posiblemente a través de funciones como la rotación de IP, el cambio de agente de usuario y la resolución de CAPTCHA.
Soporte técnico y comunidad :
- Una herramienta con buen soporte técnico y una comunidad de usuarios activa puede ser invaluable, especialmente cuando enfrenta desafíos o necesita adaptarse a los cambios en la tecnología de web scraping.
Mejores prácticas en el uso de Web Scraper :
- Respete el archivo robots.txt : respete las directivas del archivo robots.txt del sitio web para mantener prácticas de scraping éticas.
- Limitación de velocidad : para evitar sobrecargar los servidores del sitio web, configure su raspador para realizar solicitudes a una velocidad razonable.
- Manejo de errores : implemente un manejo sólido de errores para gestionar problemas como tiempos de espera o errores del servidor con elegancia.
- Garantía de calidad de los datos : verifique periódicamente la calidad de los datos extraídos para garantizar su precisión e integridad.
- Manténgase informado : manténgase al tanto de los últimos avances en tecnologías de web scraping y regulaciones legales.
Al considerar cuidadosamente estos factores y seguir las mejores prácticas, puede elegir un raspador web que no solo satisfaga sus necesidades de recopilación de datos, sino que también lo haga de manera eficiente, ética y conforme a la ley.
PromptCloud: las mejores soluciones de web scraping para sus necesidades de datos
En el ámbito dinámico de la recopilación y el análisis de datos, PromptCloud emerge como líder en el suministro de soluciones de web scraping de última generación. PromptCloud, diseñado para empresas e individuos que buscan aprovechar el poder de los datos, ofrece una gama de servicios de scraping que se destacan por su eficiencia, confiabilidad y cumplimiento. He aquí por qué PromptCloud es su opción preferida para el web scraping:
Servicios de raspado web personalizados :
- Soluciones a medida : PromptCloud entiende que cada requisito de datos es único. Sus servicios de web scraping personalizados están diseñados para satisfacer necesidades específicas, ya sea recolectando grandes volúmenes de datos o extrayendo información de sitios web complejos.
Escalabilidad y confiabilidad :
- Maneje las necesidades de datos a gran escala : la infraestructura de PromptCloud está diseñada para administrar la extracción de datos a gran escala sin esfuerzo, garantizando confiabilidad y coherencia en la entrega de datos.
- Garantía de alto tiempo de actividad : Proporcionan una plataforma sólida con una garantía de alto tiempo de actividad, lo que garantiza que su proceso de recopilación de datos sea ininterrumpido y eficiente.
Tecnología y características avanzadas :
- Herramientas de vanguardia : utilizando lo último en tecnología de web scraping, PromptCloud puede navegar a través de sofisticadas medidas anti-scraping y contenido cargado dinámicamente.
- Datos en formatos listos para usar : entregan datos en varios formatos estructurados, lo que los hace inmediatamente procesables para sus necesidades comerciales.
PromptCloud se erige como un faro para empresas e individuos que buscan aprovechar el poder del web scraping sin las complejidades que implica la configuración y el mantenimiento de dichos sistemas. Con PromptCloud, obtiene acceso a datos precisos, oportunos y compatibles, lo que permite a su empresa tomar decisiones informadas y mantenerse a la vanguardia en el competitivo panorama del mercado.
¿Listo para desbloquear el potencial del Web Scraping?
Explore las ofertas de PromptCloud y dé el primer paso hacia la transformación de su estrategia de datos. Póngase en contacto con nosotros en [email protected] para obtener más información sobre sus servicios y cómo pueden ser la clave para desbloquear el potencial de sus datos.