
Web Scraper คืออะไรและทำงานอย่างไร?
เผยแพร่แล้ว: 2024-01-16ในภูมิประเทศที่กว้างใหญ่และเปลี่ยนแปลงตลอดเวลาของอินเทอร์เน็ต ข้อมูลได้กลายเป็นส่วนสำคัญของการตัดสินใจและการวางแผนเชิงกลยุทธ์ในภาคส่วนต่างๆ ในที่นี้ความสำคัญของเครื่องขูดเว็บอยู่ที่เครื่องมืออันทรงพลังที่นำทางข้อมูลออนไลน์อันมหาศาล แต่จริงๆ แล้ว Web Scraping คืออะไร และเหตุใดจึงมีความสำคัญในยุคดิจิทัล
การขูดเว็บเป็นแกนหลักเกี่ยวข้องกับการดึงข้อมูลจากเว็บไซต์โดยอัตโนมัติ กระบวนการนี้ซึ่งมักดำเนินการโดยซอฟต์แวร์หรือสคริปต์พิเศษ ช่วยให้สามารถรวบรวมข้อมูลเฉพาะจากหน้าเว็บและการแปลงเป็นรูปแบบที่มีโครงสร้าง โดยทั่วไปสำหรับการวิเคราะห์หรือการใช้งานในแอปพลิเคชันอื่น
ในโลกที่ข้อมูลคือราชา การขูดเว็บทำหน้าที่เป็นตัวขับเคลื่อนหลัก ช่วยให้ธุรกิจ นักวิจัย และบุคคลสามารถเข้าถึงและใช้ประโยชน์จากข้อมูลเว็บสาธารณะได้อย่างมีประสิทธิภาพและประสิทธิผล ตั้งแต่การวิเคราะห์คู่แข่งและการวิจัยตลาดไปจนถึงการติดตามความรู้สึกทางสังคมและโครงการทางวิชาการ การใช้งาน Web Scraping มีความหลากหลายพอๆ กับที่สร้างผลกระทบ
Web Scraper คืออะไร: พื้นฐาน
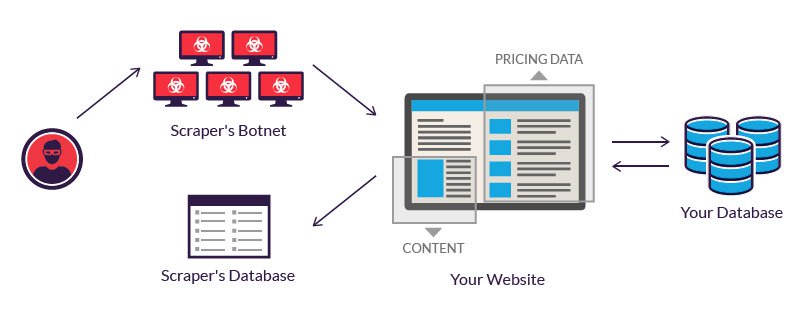
ที่มา: https://www.imperva.com/learn/application-security/web-scraping-attack/
การขูดเว็บเป็นกระบวนการที่เกี่ยวข้องกับการดึงข้อมูลจากเว็บไซต์โดยอัตโนมัติ เทคนิคนี้ใช้ซอฟต์แวร์หรือสคริปต์พิเศษที่ออกแบบมาเพื่อเข้าถึงหน้าเว็บ ดึงข้อมูลที่จำเป็น จากนั้นแปลงข้อมูลนั้นให้อยู่ในรูปแบบที่มีโครงสร้างเพื่อใช้ต่อไป ความเรียบง่ายของคำจำกัดความนี้ ปฏิเสธความซับซ้อนและความอเนกประสงค์ของการขูดเว็บในฐานะเครื่องมือ ตอนนี้คุณอาจเข้าใจแล้วว่า Web Scraper คืออะไร ดังนั้นเรามาเรียนรู้วิธีการทำงานกันดีกว่า
ในระดับพื้นฐานที่สุด การขูดเว็บทำหน้าที่หลักสองประการ:
- การรวบรวมข้อมูล : โปรแกรมขูดเว็บมีความเชี่ยวชาญในการนำทางผ่านหน้าเว็บ ระบุและรวบรวมข้อมูลประเภทเฉพาะ ซึ่งอาจรวมถึงรายละเอียดผลิตภัณฑ์จากไซต์อีคอมเมิร์ซ ราคาหุ้นจากเว็บไซต์ทางการเงิน ประกาศรับสมัครงานจากพอร์ทัลการจ้างงาน หรือเนื้อหาเว็บอื่น ๆ ที่เข้าถึงได้แบบสาธารณะ
- การแปลงข้อมูล : เมื่อรวบรวมข้อมูลแล้ว เครื่องมือขูดเว็บจะเปลี่ยนข้อมูลเว็บที่ไม่มีโครงสร้าง (มักเป็นโค้ด HTML) ให้เป็นรูปแบบที่มีโครงสร้าง เช่น CSV, Excel หรือฐานข้อมูล การเปลี่ยนแปลงนี้ช่วยให้วิเคราะห์ จัดการ และใช้งานข้อมูลเพื่อวัตถุประสงค์ต่างๆ ได้ง่ายขึ้น
ฟังก์ชั่นพื้นฐานของการขูดเว็บทำให้เป็นเครื่องมือที่ทรงพลังสำหรับทุกคนที่ต้องการเข้าถึงข้อมูลบนเว็บจำนวนมากอย่างรวดเร็วและมีประสิทธิภาพ ไม่ว่าจะเป็นธุรกิจขนาดเล็กที่ติดตามราคาของคู่แข่งหรือบริษัทขนาดใหญ่ที่วิเคราะห์แนวโน้มของตลาด Web Scraping มอบวิธีการรวบรวมข้อมูลที่เกี่ยวข้องโดยไม่จำเป็นต้องแยกข้อมูลด้วยตนเอง ในส่วนถัดไป เราจะเจาะลึกเกี่ยวกับวิธีการทำงานของเครื่องมือขูดเหล่านี้ ประเภทต่างๆ และการใช้งานที่หลากหลายในโลกดิจิทัล
Web Scrapers ทำงานอย่างไร: เจาะลึกทางเทคนิค
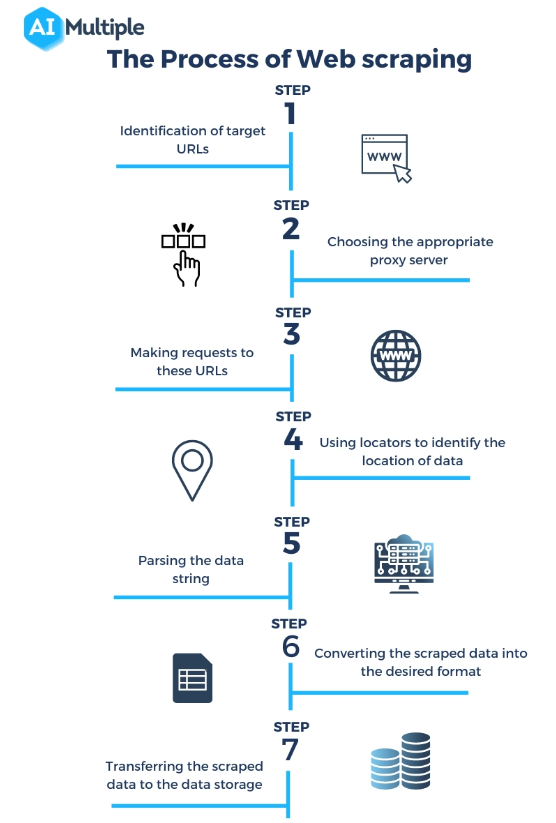
ที่มา: https://research.aimultiple.com/web-scraping-vs-api/
เครื่องขูดเว็บคืออะไร? การขูดเว็บอาจฟังดูเหมือนมหัศจรรย์ แต่จริงๆ แล้วมันเป็นกระบวนการทางเทคนิคที่ได้รับการจัดการอย่างดี ซึ่งเกี่ยวข้องกับหลายขั้นตอนในการเข้าถึง แยก และประมวลผลข้อมูลจากเว็บไซต์ มาดูกันว่าเครื่องขูดเว็บทำงานอย่างไร:
การส่งคำขอไปยังเว็บเซิร์ฟเวอร์ :
ขั้นตอนแรกในการขูดเว็บคือให้เครื่องขูดส่งคำขอไปยังเว็บเซิร์ฟเวอร์ที่โฮสต์หน้าเว็บเป้าหมาย สิ่งนี้คล้ายกับสิ่งที่เกิดขึ้นเมื่อคุณพิมพ์ URL ลงในเบราว์เซอร์ของคุณ ความแตกต่างก็คือที่ขูดส่งคำขอโดยทางโปรแกรม
การดึงข้อมูลเว็บเพจ :
เมื่อส่งคำขอแล้ว เซิร์ฟเวอร์จะตอบกลับด้วยเนื้อหาของหน้าเว็บ ซึ่งโดยทั่วไปจะอยู่ในรูปแบบ HTML เครื่องขูดจะดาวน์โหลดเนื้อหานี้เพื่อการประมวลผล ในบางกรณี อาจจำเป็นต้องมีการแสดงผล JavaScript เพื่อโหลดเนื้อหาของหน้าโดยสมบูรณ์ ซึ่งสแครปเปอร์ขั้นสูงบางตัวสามารถจัดการได้
แยกวิเคราะห์เนื้อหา HTML :
หน้าเว็บที่ดึงมามักจะอยู่ในรูปแบบ HTML ซึ่งเป็นภาษามาร์กอัปที่มีโครงสร้างเฉพาะ เครื่องมือขูดจะแยกวิเคราะห์เนื้อหา HTML นี้เพื่อให้เข้าใจโครงสร้างของเนื้อหา โดยระบุส่วนหัว ย่อหน้า ลิงก์ และองค์ประกอบอื่นๆ ตามแท็ก HTML
การแยกข้อมูลที่เกี่ยวข้อง :
หลังจากแยกวิเคราะห์แล้ว สแครปเปอร์จะระบุและแยกข้อมูลเฉพาะที่สนใจ อาจเป็นอะไรก็ได้ตั้งแต่คำอธิบายและราคาของผลิตภัณฑ์ ไปจนถึงข้อความในบทความหรือข้อมูลทางสถิติ การแตกข้อมูลจะขึ้นอยู่กับองค์ประกอบ HTML และคุณลักษณะ เช่น ชื่อคลาสหรือ ID
การแปลงและจัดเก็บข้อมูล :
ข้อมูลที่แยกออกมาซึ่งยังอยู่ในรูปแบบดิบจะถูกแปลงเป็นรูปแบบที่มีโครงสร้าง เช่น CSV, JSON หรือลงในฐานข้อมูลโดยตรง ขั้นตอนนี้มีความสำคัญอย่างยิ่งในการทำให้ข้อมูลสามารถนำมาใช้ในการวิเคราะห์หรือบูรณาการกับแอปพลิเคชันอื่นๆ
การจัดการกับความท้าทาย :
การขูดเว็บอาจเผชิญกับความท้าทาย เช่น เนื้อหาที่โหลดแบบไดนามิก มาตรการป้องกันการขูดโดยเว็บไซต์ และการรักษาสถานะเซสชัน สแครปเปอร์ขั้นสูงนำทางสิ่งเหล่านี้โดยเลียนแบบพฤติกรรมการท่องเว็บของมนุษย์ การหมุนเวียนที่อยู่ IP และการจัดการคุกกี้และเซสชัน
การเคารพขอบเขตทางกฎหมายและจริยธรรม :
โปรแกรมขูดเว็บตามหลักจริยธรรมได้รับการตั้งโปรแกรมให้เคารพขอบเขตทางกฎหมายของการขูดเว็บ สิ่งนี้เกี่ยวข้องกับการปฏิบัติตามหลักเกณฑ์เกี่ยวกับไฟล์ robots.txt ของเว็บไซต์ การหลีกเลี่ยงการโหลดเซิร์ฟเวอร์มากเกินไป และการปฏิบัติตามกฎหมายความเป็นส่วนตัวของข้อมูล
ประเภทของเครื่องขูดเว็บ: สำรวจความหลากหลาย
เครื่องมือขูดเว็บมีหลายรูปแบบ แต่ละแบบได้รับการออกแบบมาเพื่อตอบสนองความต้องการและความท้าทายเฉพาะ การทำความเข้าใจประเภทต่างๆ เหล่านี้ช่วยในการเลือกเครื่องมือที่เหมาะกับงาน มาสำรวจเว็บสแครปเปอร์ประเภททั่วไปบางประเภทกัน:
เครื่องขูด HTML :
- ฟังก์ชันการทำงาน : สแครปเปอร์ HTML เป็นรูปแบบพื้นฐานของเว็บสแครปเปอร์ พวกเขาดาวน์โหลดเนื้อหา HTML ของหน้าเว็บและดึงข้อมูลโดยแยกวิเคราะห์โค้ด HTML
- กรณีการใช้งาน : เหมาะสำหรับเว็บไซต์แบบสแตติกที่มีการฝังข้อมูลโดยตรงภายใน HTML
เครื่องขูด API :
- ฟังก์ชั่นการทำงาน : เครื่องขูดเหล่านี้จะดึงข้อมูลจาก API (Application Programming Interfaces) ที่จัดทำโดยเว็บไซต์ แทนที่จะแยกวิเคราะห์ HTML พวกเขาส่งคำขอไปยังตำแหน่งข้อมูล API และรับข้อมูลในรูปแบบที่มีโครงสร้าง เช่น JSON หรือ XML
- กรณีการใช้งาน : เหมาะสำหรับเว็บไซต์ที่มี API สาธารณะ ซึ่งนำเสนอวิธีการดึงข้อมูลที่มีประสิทธิภาพและเชื่อถือได้มากขึ้น
เครื่องขูดบนเบราว์เซอร์ :
- ฟังก์ชั่นการทำงาน : เครื่องมือเหล่านี้เลียนแบบเว็บเบราว์เซอร์เพื่อโต้ตอบกับหน้าเว็บ พวกเขาสามารถดำเนินการคำขอ JavaScript และ AJAX ทำให้สามารถคัดลอกเนื้อหาแบบไดนามิกได้
- กรณีการใช้งาน : จำเป็นสำหรับเว็บไซต์ที่ต้องอาศัย JavaScript อย่างมากในการแสดงเนื้อหา เช่น เว็บแอปพลิเคชันสมัยใหม่
เครื่องขูดเบราว์เซอร์ Headless :
- ฟังก์ชันการทำงาน : ทำงานคล้ายกับสแครปเปอร์ที่ใช้เบราว์เซอร์ โดยจะใช้เบราว์เซอร์แบบไม่มีส่วนหัว (เบราว์เซอร์ที่ไม่มีอินเทอร์เฟซผู้ใช้แบบกราฟิก) ในการแสดงผลหน้าเว็บ พวกเขาสามารถจัดการหน้าเว็บที่ซับซ้อนซึ่งต้องมีการจัดการเซสชัน คุกกี้ และการดำเนินการ JavaScript
- กรณีการใช้งาน : มีประโยชน์สำหรับการดึงข้อมูลจากเว็บไซต์ไดนามิกที่ซับซ้อนและแอปพลิเคชันหน้าเดียว (SPA)
Visual Web Scrapers :
- ฟังก์ชันการทำงาน : แครปเปอร์เหล่านี้เป็นมิตรกับผู้ใช้พร้อมอินเทอร์เฟซแบบกราฟิกที่อนุญาตให้ผู้ใช้เลือกจุดข้อมูลบนหน้าเว็บด้วยสายตา มีเทคนิคน้อยและไม่จำเป็นต้องมีความรู้ด้านการเขียนโปรแกรม
- กรณีการใช้งาน : เหมาะสำหรับผู้ใช้ที่ไม่ใช่โปรแกรมเมอร์ แต่ต้องการดึงข้อมูลจากเว็บไซต์โดยไม่ต้องตั้งค่าที่ซับซ้อน
เครื่องขูดเว็บ SaaS :
- ฟังก์ชั่นการทำงาน : บริการเหล่านี้นำเสนอโดยบริษัทที่เชี่ยวชาญด้านการขูดเว็บ พวกเขาจัดการกับความซับซ้อนของการขูดและให้ข้อมูลในรูปแบบที่พร้อมใช้งาน
- กรณีการใช้งาน : เหมาะสำหรับธุรกิจที่ต้องการความสามารถในการขูดเว็บ แต่ไม่ต้องการจัดการกับด้านเทคนิค
เครื่องขูดแบบกำหนดเอง :
- ฟังก์ชันการทำงาน : สร้างขึ้นสำหรับความต้องการเฉพาะ เครื่องขูดเหล่านี้ได้รับการออกแบบมาเพื่อตอบสนองความต้องการในการดึงข้อมูลเฉพาะ ซึ่งมักจะเกี่ยวข้องกับตรรกะและคุณสมบัติที่ซับซ้อน
- กรณีการใช้งาน : จำเป็นเมื่อต้องจัดการกับงานขูดขนาดใหญ่หรือซับซ้อนสูง ซึ่งเครื่องมือที่มีจำหน่ายทั่วไปไม่สามารถทำได้
เครื่องขูดเว็บแต่ละประเภทมีจุดแข็งและเหมาะสมกับสถานการณ์ที่แตกต่างกัน ตั้งแต่การคัดลอก HTML อย่างง่ายไปจนถึงการจัดการเนื้อหาแบบไดนามิกและ API ตัวเลือกจะขึ้นอยู่กับโครงสร้างเว็บไซต์ ความซับซ้อนของงาน และความเชี่ยวชาญทางเทคนิคของผู้ใช้ ในส่วนถัดไป เราจะเจาะลึกการใช้งานจริงของเครื่องมือเหล่านี้ และวิธีที่เครื่องมือเหล่านี้แปลงข้อมูลให้เป็นข้อมูลเชิงลึกอันมีค่า

ภาพรวมทางกฎหมาย: ทำความเข้าใจการปฏิบัติตามกฎระเบียบและจริยธรรมในการขูดเว็บ
Web scraping เป็นเครื่องมือที่มีประสิทธิภาพในการดึงข้อมูล แต่ทำงานในสภาพแวดล้อมทางกฎหมายและจริยธรรมที่ซับซ้อน เป็นสิ่งสำคัญสำหรับธุรกิจและบุคคลที่มีส่วนร่วมในการขูดเว็บเพื่อทำความเข้าใจกฎหมายและข้อพิจารณาทางจริยธรรมเพื่อให้แน่ใจว่ามีการปฏิบัติตามและรักษาแนวปฏิบัติที่ดี ในส่วนนี้ให้ความกระจ่างเกี่ยวกับประเด็นเหล่านี้:
ข้อพิจารณาทางกฎหมายในการขูดเว็บ :
- กฎหมายลิขสิทธิ์ : ข้อมูลที่เผยแพร่บนอินเทอร์เน็ตมักได้รับการคุ้มครองโดยกฎหมายลิขสิทธิ์ การคัดลอกข้อมูลที่มีลิขสิทธิ์โดยไม่ได้รับอนุญาตอาจทำให้เกิดปัญหาทางกฎหมายได้
- ข้อตกลงข้อกำหนดในการให้บริการ : เว็บไซต์หลายแห่งมีข้อกำหนดในข้อกำหนดในการให้บริการ (ToS) ซึ่งห้ามการขูดเว็บอย่างชัดเจน การละเมิดข้อกำหนดเหล่านี้อาจส่งผลให้เจ้าของเว็บไซต์ดำเนินการทางกฎหมาย
- กฎหมายความเป็นส่วนตัวของข้อมูล : ข้อบังคับต่างๆ เช่น GDPR (ระเบียบการคุ้มครองข้อมูลทั่วไป) และ CCPA (กฎหมายความเป็นส่วนตัวของผู้บริโภคแห่งแคลิฟอร์เนีย) กำหนดกฎเกณฑ์ที่เข้มงวดเกี่ยวกับวิธีการรวบรวมและใช้ข้อมูลส่วนบุคคล เครื่องขูดเว็บจะต้องปฏิบัติตามกฎหมายความเป็นส่วนตัวเหล่านี้
ข้อพิจารณาทางจริยธรรมในการขูดเว็บ :
- การปฏิบัติตาม robots.txt : ไฟล์นี้บนเว็บไซต์จะระบุวิธีการและสิ่งที่โปรแกรมรวบรวมข้อมูลเว็บได้รับอนุญาตให้ทำการขูด การขูดเว็บอย่างมีจริยธรรมเกี่ยวข้องกับการปฏิบัติตามหลักเกณฑ์เหล่านี้
- การลดภาระเซิร์ฟเวอร์ให้เหลือน้อยที่สุด : การขูดแบบก้าวร้าวอาจทำให้เซิร์ฟเวอร์ของเว็บไซต์ทำงานหนักเกินไป ซึ่งอาจเป็นสาเหตุให้เซิร์ฟเวอร์ล่มได้ เครื่องขูดที่มีจริยธรรมได้รับการออกแบบเพื่อเลียนแบบความเร็วและรูปแบบการท่องเว็บของมนุษย์เพื่อหลีกเลี่ยงปัญหาดังกล่าว
- ความโปร่งใสและวัตถุประสงค์ : การคัดลอกอย่างมีจริยธรรมเกี่ยวข้องกับการมีความโปร่งใสว่าใครเป็นผู้รวบรวมข้อมูลและเพื่อวัตถุประสงค์ใด นอกจากนี้ยังหมายถึงการหลีกเลี่ยงการดึงข้อมูลที่ละเอียดอ่อนอีกด้วย
แนวทางปฏิบัติที่ดีที่สุดสำหรับการขูดเว็บทางกฎหมายและจริยธรรม :
- ขออนุญาต : หากเป็นไปได้ วิธีที่ดีที่สุดคือขออนุญาตจากเจ้าของเว็บไซต์ก่อนที่จะคัดลอกข้อมูล โดยเฉพาะอย่างยิ่งหากข้อมูลมีความละเอียดอ่อนหรือมีลิขสิทธิ์คุ้มครอง
- ปฏิบัติตามมาตรฐานทางกฎหมาย : ตรวจสอบให้แน่ใจว่ากิจกรรมการขูดของคุณเป็นไปตามกฎหมายท้องถิ่นและกฎหมายระหว่างประเทศที่เกี่ยวข้อง
- ใช้ข้อมูลอย่างมีความรับผิดชอบ : ข้อมูลที่รวบรวมควรใช้อย่างมีจริยธรรมและความรับผิดชอบ โดยเคารพความเป็นส่วนตัวของผู้ใช้ และหลีกเลี่ยงอันตรายต่อเจ้าของข้อมูล
การนำทางพื้นที่สีเทา :
- ความถูกต้องตามกฎหมายของการขูดเว็บมักจะตกอยู่ในพื้นที่สีเทา ขึ้นอยู่กับวิธีการใช้ข้อมูล ลักษณะของข้อมูล และเขตอำนาจศาล ขอแนะนำให้ปรึกษาผู้เชี่ยวชาญด้านกฎหมายเมื่อมีข้อสงสัย
การทำความเข้าใจและปฏิบัติตามข้อพิจารณาทางกฎหมายและจริยธรรมในการขูดเว็บไม่ได้เป็นเพียงเกี่ยวกับการปฏิบัติตามกฎระเบียบ แต่ยังรวมถึงการรักษาความสมบูรณ์และชื่อเสียงของธุรกิจของคุณด้วย เมื่อเราก้าวไปข้างหน้า แนวปฏิบัติในการขูดเว็บมีแนวโน้มที่จะพัฒนาต่อไปพร้อมกับภูมิทัศน์ทางกฎหมาย ทำให้ผู้ใช้จำเป็นต้องรับทราบข้อมูลและมีสติ
การเลือก Web Scraper: เคล็ดลับและแนวทางปฏิบัติที่ดีที่สุด
การเลือกเครื่องขูดเว็บที่เหมาะสมถือเป็นการตัดสินใจที่สำคัญซึ่งอาจส่งผลกระทบอย่างมากต่อความมีประสิทธิผลของความพยายามในการรวบรวมข้อมูลของคุณ ต่อไปนี้เป็นเคล็ดลับและแนวทางปฏิบัติที่ดีที่สุดเพื่อเป็นแนวทางในการเลือกเครื่องมือขูดเว็บที่เหมาะสมที่สุดและใช้งานอย่างมีประสิทธิภาพ:
ประเมินความต้องการของคุณ :
- ทำความเข้าใจความต้องการของคุณ : ก่อนที่จะเจาะลึกเครื่องมือขูดเว็บที่มีอยู่มากมาย ให้ชี้แจงสิ่งที่คุณต้องขูด ความถี่ที่คุณต้องทำ และความซับซ้อนของข้อมูลและเว็บไซต์ที่เกี่ยวข้อง
- ความสามารถในการปรับขนาด : พิจารณาว่าคุณต้องการเครื่องมือที่สามารถจัดการกับการขูดขนาดใหญ่ได้หรือไม่ หรือวิธีแก้ปัญหาที่ง่ายกว่าและตรงไปตรงมามากกว่าก็เพียงพอแล้ว
ประเมินคุณสมบัติ :
- ใช้งานง่าย : หากคุณไม่มีความรู้ทางเทคนิค ให้มองหาเครื่องขูดที่มีอินเทอร์เฟซที่เป็นมิตรต่อผู้ใช้หรือคุณลักษณะแบบชี้และคลิกด้วยภาพ
- ความสามารถในการแยกข้อมูล : ตรวจสอบให้แน่ใจว่าเครื่องมือสามารถแยกประเภทข้อมูลที่คุณต้องการ (ข้อความ รูปภาพ ฯลฯ) และจัดการเนื้อหาแบบไดนามิกที่โหลดด้วย JavaScript หรือ AJAX
- ตัวเลือกการส่งออกข้อมูล : ตรวจสอบรูปแบบที่สแครปเปอร์สามารถส่งออกข้อมูล (CSV, JSON, ฐานข้อมูล ฯลฯ) และตรวจสอบให้แน่ใจว่าตรงตามความต้องการของคุณ
พิจารณาการปฏิบัติตามกฎหมาย :
- เลือกเครื่องมือขูดที่เคารพข้อกำหนดในการให้บริการของเว็บไซต์และมาตรฐานทางกฎหมาย โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับข้อมูลที่ละเอียดอ่อนหรือข้อมูลส่วนบุคคล
ตรวจสอบการบายพาสคุณสมบัติป้องกันการขูด :
- เว็บไซต์หลายแห่งใช้มาตรการป้องกันการขูด ตรวจสอบให้แน่ใจว่าเครื่องมือที่คุณเลือกสามารถนำทางสิ่งเหล่านี้ได้อย่างมีประสิทธิภาพ ซึ่งอาจผ่านฟีเจอร์ต่างๆ เช่น การหมุนเวียน IP การสลับตัวแทนผู้ใช้ และการแก้ไข CAPTCHA
การสนับสนุนทางเทคนิคและชุมชน :
- เครื่องมือที่มีการสนับสนุนทางเทคนิคที่ดีและชุมชนผู้ใช้ที่กระตือรือร้นนั้นเป็นสิ่งที่มีค่าอย่างยิ่ง โดยเฉพาะอย่างยิ่งเมื่อคุณเผชิญกับความท้าทายหรือจำเป็นต้องปรับตัวให้เข้ากับการเปลี่ยนแปลงในเทคโนโลยีการขูดเว็บ
แนวทางปฏิบัติที่ดีที่สุดในการใช้ Web Scraper :
- เคารพ robots.txt : ปฏิบัติตามคำสั่งในไฟล์ robots.txt ของเว็บไซต์ เพื่อรักษาหลักปฏิบัติในการคัดลอกข้อมูลอย่างมีจริยธรรม
- การจำกัดอัตรา : เพื่อหลีกเลี่ยงไม่ให้เซิร์ฟเวอร์เว็บไซต์ทำงานหนักเกินไป ให้ตั้งค่าเครื่องขูดของคุณให้ส่งคำขอในอัตราที่สมเหตุสมผล
- การจัดการข้อผิดพลาด : ใช้การจัดการข้อผิดพลาดที่มีประสิทธิภาพเพื่อจัดการปัญหาต่างๆ เช่น การหมดเวลาหรือข้อผิดพลาดของเซิร์ฟเวอร์อย่างสวยงาม
- การประกันคุณภาพข้อมูล : ตรวจสอบคุณภาพของข้อมูลที่คัดลอกเป็นประจำเพื่อให้มั่นใจถึงความถูกต้องและครบถ้วน
- รับทราบข้อมูลอยู่เสมอ : ติดตามการพัฒนาล่าสุดในเทคโนโลยีการขูดเว็บและกฎระเบียบทางกฎหมาย
ด้วยการพิจารณาปัจจัยเหล่านี้อย่างรอบคอบและปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุด คุณสามารถเลือกเว็บสแครปเปอร์ที่ไม่เพียงแต่ตรงกับความต้องการในการรวบรวมข้อมูลของคุณเท่านั้น แต่ยังทำในลักษณะที่มีประสิทธิภาพ มีจริยธรรม และปฏิบัติตามกฎหมายอีกด้วย
PromptCloud: โซลูชั่นขูดเว็บที่ดีที่สุดสำหรับความต้องการข้อมูลของคุณ
ในขอบเขตแบบไดนามิกของการรวบรวมและวิเคราะห์ข้อมูล PromptCloud กลายเป็นผู้นำในการให้บริการโซลูชั่นการขูดเว็บที่ล้ำสมัย ปรับแต่งมาสำหรับธุรกิจและบุคคลที่ต้องการควบคุมพลังของข้อมูล PromptCloud เสนอบริการขูดข้อมูลที่หลากหลายซึ่งโดดเด่นในด้านประสิทธิภาพ ความน่าเชื่อถือ และการปฏิบัติตามข้อกำหนด นี่คือเหตุผลที่ PromptCloud เป็นตัวเลือกที่ดีสำหรับการขูดเว็บ:
บริการขูดเว็บแบบกำหนดเอง :
- Bespoke Solutions : PromptCloud เข้าใจดีว่าความต้องการข้อมูลแต่ละอย่างมีเอกลักษณ์เฉพาะตัว บริการขูดเว็บแบบกำหนดเองได้รับการออกแบบมาเพื่อตอบสนองความต้องการเฉพาะ ไม่ว่าจะเป็นการขูดข้อมูลจำนวนมากหรือดึงข้อมูลจากเว็บไซต์ที่ซับซ้อน
ความสามารถในการปรับขนาดและความน่าเชื่อถือ :
- จัดการกับความต้องการข้อมูลขนาดใหญ่ : โครงสร้างพื้นฐานของ PromptCloud ถูกสร้างขึ้นเพื่อจัดการการแยกข้อมูลขนาดใหญ่ได้อย่างง่ายดาย ทำให้มั่นใจได้ถึงความน่าเชื่อถือและความสม่ำเสมอในการส่งข้อมูล
- การรับประกันความพร้อมใช้งานสูง : เป็นแพลตฟอร์มที่แข็งแกร่งพร้อมการรับประกันความพร้อมใช้งานสูง ทำให้มั่นใจได้ว่ากระบวนการรวบรวมข้อมูลของคุณจะไม่หยุดชะงักและมีประสิทธิภาพ
เทคโนโลยีและคุณสมบัติขั้นสูง :
- เครื่องมือล้ำสมัย : ด้วยการใช้เทคโนโลยีการขูดเว็บล่าสุด PromptCloud สามารถนำทางผ่านมาตรการป้องกันการขูดที่ซับซ้อนและเนื้อหาที่โหลดแบบไดนามิก
- ข้อมูลในรูปแบบที่พร้อมใช้งาน : ส่งข้อมูลในรูปแบบที่มีโครงสร้างหลากหลาย ทำให้สามารถดำเนินการตามความต้องการทางธุรกิจของคุณได้ทันที
PromptCloud ทำหน้าที่เป็นสัญญาณสำหรับธุรกิจและบุคคลที่ต้องการใช้ประโยชน์จากพลังของการขูดเว็บโดยไม่ต้องยุ่งยากในการตั้งค่าและบำรุงรักษาระบบดังกล่าว ด้วย PromptCloud คุณจะสามารถเข้าถึงข้อมูลที่ถูกต้อง ทันเวลา และเป็นไปตามข้อกำหนด ช่วยให้ธุรกิจของคุณมีข้อมูลในการตัดสินใจและก้าวนำในตลาดที่มีการแข่งขันสูง
พร้อมที่จะปลดล็อกศักยภาพของ Web Scraping แล้วหรือยัง?
สำรวจข้อเสนอของ PromptCloud และก้าวแรกสู่การเปลี่ยนแปลงกลยุทธ์ข้อมูลของคุณ ติดต่อเราที่ [email protected] เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับบริการของพวกเขา และวิธีที่พวกเขาสามารถเป็นกุญแจสำคัญในการปลดล็อกศักยภาพข้อมูลของคุณ