
Was ist ein Web Scraper und wie funktioniert er?
Veröffentlicht: 2024-01-16In der riesigen und sich ständig weiterentwickelnden Landschaft des Internets sind Daten zum Lebenselixier der Entscheidungsfindung und strategischen Planung in verschiedenen Sektoren geworden. Hierin liegt die Bedeutung von Web Scrapern – leistungsstarke Tools, die durch das riesige Meer an Online-Informationen navigieren. Aber was genau ist Web Scraping und warum ist es im digitalen Zeitalter so wichtig geworden?
Beim Web Scraping geht es im Kern um die automatisierte Extraktion von Daten von Websites. Dieser Prozess, der häufig von spezieller Software oder Skripten ausgeführt wird, ermöglicht die Erfassung spezifischer Informationen von Webseiten und deren Umwandlung in ein strukturiertes Format, typischerweise zur Analyse oder Verwendung in anderen Anwendungen.
In einer Welt, in der Daten König sind, ist Web Scraping ein entscheidender Faktor. Es ermöglicht Unternehmen, Forschern und Einzelpersonen, effizient und effektiv auf öffentliche Webdaten zuzugreifen und diese zu nutzen. Von Wettbewerbsanalysen und Marktforschung bis hin zur Verfolgung sozialer Gefühle und akademischer Projekte – die Anwendungen von Web Scraping sind ebenso vielfältig wie wirkungsvoll.
Was ist ein Web Scraper: Die Grundlagen
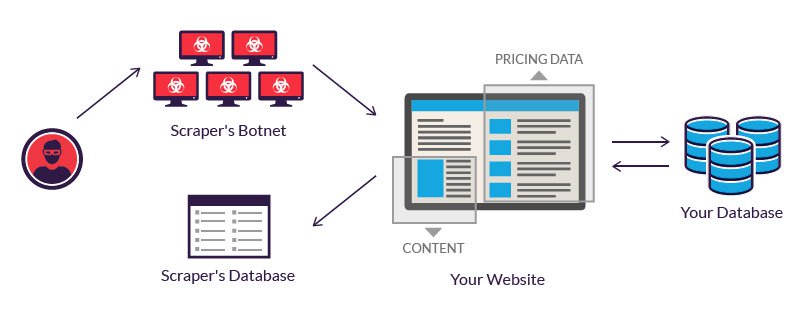
Quelle: https://www.imperva.com/learn/application-security/web-scraping-attack/
Web Scraping ist ein Prozess, bei dem automatisch Informationen von Websites extrahiert werden. Bei dieser Technik werden spezielle Software oder Skripte verwendet, die darauf ausgelegt sind, auf Webseiten zuzugreifen, die erforderlichen Daten abzurufen und diese Daten dann zur weiteren Verwendung in ein strukturiertes Format umzuwandeln. Die Einfachheit dieser Definition täuscht jedoch über die Raffinesse und Vielseitigkeit des Web Scraping als Werkzeug hinweg. Jetzt haben Sie vielleicht verstanden, was ein Web Scraper ist. Lassen Sie uns nun lernen, wie er funktioniert.
Auf seiner grundlegendsten Ebene erfüllt Web Scraping zwei Hauptfunktionen:
- Datenerfassung : Web-Scraping-Programme sind in der Lage, durch Webseiten zu navigieren und bestimmte Datentypen zu identifizieren und zu sammeln. Dazu können Produktdetails von E-Commerce-Websites, Aktienkurse von Finanzwebsites, Stellenausschreibungen von Stellenportalen oder andere öffentlich zugängliche Webinhalte gehören.
- Datentransformation : Sobald die Daten erfasst sind, wandeln Web-Scraping-Tools diese unstrukturierten Webdaten (häufig HTML-Code) in ein strukturiertes Format wie CSV, Excel oder eine Datenbank um. Diese Transformation erleichtert die Analyse, Bearbeitung und Nutzung der Daten für verschiedene Zwecke.
Diese Grundfunktionen des Web Scraping machen es zu einem leistungsstarken Werkzeug für alle, die schnell und effizient auf große Mengen webbasierter Informationen zugreifen müssen. Ob es sich um ein kleines Unternehmen handelt, das die Preise der Konkurrenz überwacht, oder um ein großes Unternehmen, das Markttrends analysiert, Web Scraping bietet eine Möglichkeit, relevante Daten zu sammeln, ohne dass eine manuelle Extraktion erforderlich ist. In den nächsten Abschnitten werden wir tiefer in die Funktionsweise dieser Scraping-Tools, ihre unterschiedlichen Typen und ihre vielfältigen Einsatzmöglichkeiten in der digitalen Welt eintauchen.
Wie Web Scraper funktionieren: Ein technischer Tauchgang
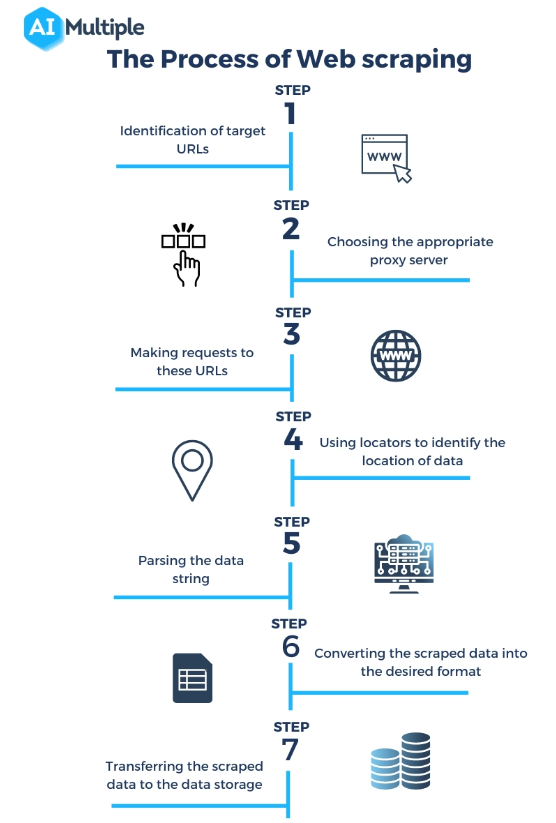
Quelle: https://research.aimultiple.com/web-scraping-vs-api/
Was ist ein Web-Scraper? Web Scraping hört sich vielleicht wie Zauberei an, ist aber tatsächlich ein gut orchestrierter technischer Prozess, der mehrere Schritte umfasst, um auf Daten von Websites zuzugreifen, sie zu extrahieren und zu verarbeiten. Hier ist ein genauerer Blick auf die Funktionsweise von Web Scrapern:
Senden einer Anfrage an den Webserver :
Der erste Schritt beim Web Scraping besteht darin, dass der Scraper eine Anfrage an den Webserver sendet, der die Zielwebseite hostet. Dies ähnelt dem, was passiert, wenn Sie eine URL in Ihren Browser eingeben. Der Unterschied besteht darin, dass der Scraper die Anfrage programmgesteuert sendet.
Aufrufen der Webseite :
Sobald die Anfrage gesendet wurde, antwortet der Server mit dem Inhalt der Webseite, normalerweise im HTML-Format. Der Scraper lädt diesen Inhalt dann zur Verarbeitung herunter. In einigen Fällen ist möglicherweise JavaScript-Rendering erforderlich, um den Inhalt der Seite vollständig zu laden, was einige fortgeschrittene Scraper bewältigen können.
Analysieren des HTML-Inhalts :
Die abgerufene Webseite liegt normalerweise im HTML-Format vor, einer Auszeichnungssprache mit einer bestimmten Struktur. Der Scraper analysiert diesen HTML-Inhalt, um seine Struktur zu verstehen, indem er Überschriften, Absätze, Links und andere Elemente anhand ihrer HTML-Tags identifiziert.
Relevante Daten extrahieren :
Nach dem Parsen identifiziert und extrahiert der Scraper die spezifischen Daten von Interesse. Dies kann alles sein, von Produktbeschreibungen und Preisen bis hin zu Artikeltexten oder statistischen Daten. Die Extraktion basiert auf den HTML-Elementen und ihren Attributen, wie Klassennamen oder IDs.
Datentransformation und -speicherung :
Die extrahierten Daten, noch in Rohform, werden dann in ein strukturiertes Format wie CSV, JSON oder direkt in eine Datenbank umgewandelt. Dieser Schritt ist entscheidend, um die Daten für die Analyse oder Integration mit anderen Anwendungen nutzbar zu machen.
Herausforderungen bewältigen :
Beim Web-Scraping können Herausforderungen wie dynamisch geladene Inhalte, Anti-Scraping-Maßnahmen von Websites und die Aufrechterhaltung des Sitzungsstatus auftreten. Fortgeschrittene Scraper bewältigen diese Probleme, indem sie das Surfverhalten von Menschen nachahmen, IP-Adressen wechseln und Cookies und Sitzungen verwalten.
Respektierung rechtlicher und ethischer Grenzen :
Ethische Web-Scraper sind so programmiert, dass sie die rechtlichen Grenzen des Web-Scrapings respektieren. Dazu gehört die Einhaltung der robots.txt-Dateirichtlinien der Website, die Vermeidung übermäßiger Serverlast und die Einhaltung der Datenschutzgesetze.
Arten von Web Scrapern: Erkundung der Sorten
Web-Scraping-Tools gibt es in verschiedenen Formen, die jeweils auf spezifische Bedürfnisse und Herausforderungen zugeschnitten sind. Das Verständnis dieser verschiedenen Typen hilft bei der Auswahl des richtigen Werkzeugs für die jeweilige Aufgabe. Sehen wir uns einige der häufigsten Arten von Web-Scrapern an:
HTML-Scraper :
- Funktionalität : HTML-Scraper sind die einfachste Form von Web-Scrapern. Sie laden den HTML-Inhalt von Webseiten herunter und extrahieren Daten durch Parsen des HTML-Codes.
- Anwendungsfälle : Ideal für statische Websites, bei denen die Daten direkt in den HTML-Code eingebettet sind.
API-Schaber :
- Funktionalität : Diese Scraper extrahieren Daten aus APIs (Application Programming Interfaces), die von Websites bereitgestellt werden. Anstatt HTML zu analysieren, stellen sie Anfragen an einen API-Endpunkt und empfangen Daten in einem strukturierten Format wie JSON oder XML.
- Anwendungsfälle : Geeignet für Websites mit öffentlichen APIs und bietet eine effizientere und zuverlässigere Möglichkeit der Datenextraktion.
Browserbasierte Scraper :
- Funktionalität : Diese Tools ahmen einen Webbrowser nach, um mit Webseiten zu interagieren. Sie können JavaScript- und AJAX-Anfragen ausführen und sind so in der Lage, dynamische Inhalte zu extrahieren.
- Anwendungsfälle : Unverzichtbar für Websites, die zum Rendern von Inhalten stark auf JavaScript angewiesen sind, z. B. moderne Webanwendungen.
Headless Browser Scraper :
- Funktionalität : Diese funktionieren ähnlich wie browserbasierte Scraper und verwenden Headless-Browser (Browser ohne grafische Benutzeroberfläche) zum Rendern von Webseiten. Sie können mit komplexen Webseiten umgehen, die Sitzungsverwaltung, Cookies und die Ausführung von JavaScript erfordern.
- Anwendungsfälle : Nützlich zum Scrapen von Daten aus komplexen, dynamischen Websites und Single-Page-Anwendungen (SPAs).
Visuelle Web-Scraper :
- Funktionalität : Dies sind benutzerfreundliche Scraper mit einer grafischen Oberfläche, die es Benutzern ermöglichen, Datenpunkte auf einer Webseite visuell auszuwählen. Sie sind weniger technisch und erfordern keine Programmierkenntnisse.
- Anwendungsfälle : Ideal für Benutzer, die keine Programmierer sind, aber ohne komplexe Einrichtung Daten von Websites extrahieren müssen.
SaaS-Web-Scraper :
- Funktionalität : Diese werden als Service von Unternehmen angeboten, die auf Web Scraping spezialisiert sind. Sie bewältigen die Komplexität des Scrapings und stellen Daten in einem gebrauchsfertigen Format bereit.
- Anwendungsfälle : Geeignet für Unternehmen, die Web-Scraping-Funktionen benötigen, sich aber nicht mit den technischen Aspekten befassen möchten.
Kundenspezifische Schaber :
- Funktionalität : Diese Scraper wurden für spezifische Anforderungen entwickelt und sind auf einzigartige Datenextraktionsanforderungen zugeschnitten, die häufig komplexe Logik und Funktionen beinhalten.
- Anwendungsfälle : Notwendig bei umfangreichen oder hochkomplexen Schabevorgängen, die mit handelsüblichen Werkzeugen nicht bewältigt werden können.
Jeder Webscraper-Typ hat seine Stärken und eignet sich für unterschiedliche Szenarien. Vom einfachen HTML-Scraping bis zum Umgang mit dynamischen Inhalten und APIs hängt die Wahl von der Website-Struktur, der Komplexität der Aufgabe und dem technischen Fachwissen des Benutzers ab. In den nächsten Abschnitten befassen wir uns mit den praktischen Anwendungen dieser Tools und wie sie Daten in wertvolle Erkenntnisse umwandeln.

Die Rechtslandschaft: Compliance und Ethik beim Web Scraping verstehen
Web Scraping ist zwar ein leistungsstarkes Tool zur Datenextraktion, operiert jedoch in einem komplexen rechtlichen und ethischen Umfeld. Für Unternehmen und Einzelpersonen, die Web Scraping betreiben, ist es von entscheidender Bedeutung, die rechtlichen Grundlagen und ethischen Überlegungen zu verstehen, um die Einhaltung sicherzustellen und gute Praktiken aufrechtzuerhalten. In diesem Abschnitt werden folgende Aspekte beleuchtet:
Rechtliche Überlegungen beim Web Scraping :
- Urheberrechtsgesetze : Im Internet veröffentlichte Daten sind häufig durch Urheberrechtsgesetze geschützt. Das Scrapen von urheberrechtlich geschützten Daten ohne Genehmigung kann zu rechtlichen Problemen führen.
- Nutzungsbedingungen : Viele Websites enthalten Klauseln in ihren Nutzungsbedingungen (ToS), die Web Scraping ausdrücklich verbieten. Ein Verstoß gegen diese Bedingungen kann zu rechtlichen Schritten seitens des Website-Eigentümers führen.
- Datenschutzgesetze : Vorschriften wie die DSGVO (Datenschutz-Grundverordnung) und der CCPA (California Consumer Privacy Act) legen strenge Regeln für die Erhebung und Nutzung personenbezogener Daten fest. Web-Scraper müssen die Einhaltung dieser Datenschutzgesetze sicherstellen.
Ethische Überlegungen beim Web Scraping :
- Respekt vor robots.txt : Diese Datei auf Websites gibt an, wie und was Webcrawler scrapen dürfen. Ethisches Web-Scraping beinhaltet die Einhaltung dieser Richtlinien.
- Minimierung der Serverlast : Aggressives Scraping kann den Server einer Website überlasten und möglicherweise zum Absturz führen. Ethische Scraper sind so konzipiert, dass sie die Surfgeschwindigkeit und -muster von Menschen nachahmen, um solche Probleme zu vermeiden.
- Transparenz und Zweck : Beim ethischen Scraping geht es darum, transparent darüber zu sein, wer die Daten zu welchem Zweck sammelt. Es bedeutet auch, die Extraktion sensibler Informationen zu vermeiden.
Best Practices für rechtliches und ethisches Web Scraping :
- Erlaubnis einholen : Wenn möglich, ist es am besten, die Erlaubnis des Website-Inhabers einzuholen, bevor man seine Daten löscht, insbesondere wenn die Daten sensibel oder urheberrechtlich geschützt sind.
- Halten Sie sich an gesetzliche Standards : Stellen Sie sicher, dass Ihre Scraping-Aktivitäten den relevanten lokalen und internationalen Gesetzen entsprechen.
- Verantwortungsvoller Umgang mit Daten : Die gesammelten Daten sollten ethisch und verantwortungsvoll verwendet werden, wobei die Privatsphäre der Benutzer respektiert und Schaden für die betroffenen Personen vermieden werden sollte.
Navigieren in Grauzonen :
- Die Rechtmäßigkeit von Web Scraping bewegt sich häufig in Grauzonen, abhängig von der Art der Datenverwendung, der Art der Daten und der Gerichtsbarkeit. Im Zweifelsfall ist es ratsam, einen Rechtsexperten zu Rate zu ziehen.
Beim Verstehen und Einhalten der rechtlichen und ethischen Aspekte beim Web Scraping geht es nicht nur um Compliance, sondern auch um die Wahrung der Integrität und des Rufs Ihres Unternehmens. Im weiteren Verlauf werden sich die Web-Scraping-Praktiken wahrscheinlich zusammen mit der Rechtslandschaft weiterentwickeln, sodass es für Benutzer unerlässlich ist, informiert und gewissenhaft zu bleiben.
Auswahl eines Web Scrapers: Tipps und Best Practices
Die Auswahl des richtigen Web Scrapers ist eine entscheidende Entscheidung, die sich erheblich auf die Effektivität Ihrer Datenerfassungsbemühungen auswirken kann. Hier sind einige Tipps und Best Practices, die Sie bei der Auswahl des idealen Web-Scraping-Tools und seiner effektiven Nutzung unterstützen:
Bewerten Sie Ihre Bedürfnisse :
- Verstehen Sie Ihre Anforderungen : Bevor Sie sich mit den unzähligen verfügbaren Web-Scraping-Tools befassen, klären Sie, was Sie zum Scrapen benötigen, wie oft Sie es durchführen müssen und wie komplex die beteiligten Daten und Websites sind.
- Skalierbarkeit : Überlegen Sie, ob Sie ein Werkzeug benötigen, das großflächiges Schaben bewältigen kann, oder ob eine einfachere, unkompliziertere Lösung ausreicht.
Bewerten Sie die Funktionen :
- Benutzerfreundlichkeit : Wenn Sie technisch nicht versiert sind, suchen Sie nach einem Scraper mit einer benutzerfreundlichen Oberfläche oder visuellen Point-and-Click-Funktionen.
- Datenextraktionsfunktionen : Stellen Sie sicher, dass das Tool die Art von Daten extrahieren kann, die Sie benötigen (Text, Bilder usw.) und dynamische Inhalte verarbeiten kann, die mit JavaScript oder AJAX geladen wurden.
- Datenexportoptionen : Überprüfen Sie die Formate, in denen der Scraper Daten exportieren kann (CSV, JSON, Datenbanken usw.) und stellen Sie sicher, dass sie Ihren Anforderungen entsprechen.
Berücksichtigen Sie die Einhaltung gesetzlicher Vorschriften :
- Wählen Sie einen Scraper, der die Nutzungsbedingungen und rechtlichen Standards der Website respektiert, insbesondere beim Umgang mit sensiblen oder persönlichen Daten.
Überprüfen Sie, ob die Anti-Scraping-Funktion umgangen wird :
- Viele Websites verwenden Anti-Scraping-Maßnahmen. Stellen Sie sicher, dass das von Ihnen ausgewählte Tool diese effektiv bewältigen kann, möglicherweise durch Funktionen wie IP-Rotation, User-Agent-Wechsel und CAPTCHA-Lösung.
Technischer Support und Community :
- Ein Tool mit guter technischer Unterstützung und einer aktiven Benutzergemeinschaft kann von unschätzbarem Wert sein, insbesondere wenn Sie auf Herausforderungen stoßen oder sich an Änderungen in der Web-Scraping-Technologie anpassen müssen.
Best Practices für die Verwendung von Web Scraper :
- Respektieren Sie robots.txt : Halten Sie sich an die Anweisungen in der robots.txt-Datei der Website, um ethische Scraping-Praktiken einzuhalten.
- Ratenbegrenzung : Um eine Überlastung der Website-Server zu vermeiden, stellen Sie Ihren Scraper so ein, dass Anfragen mit einer angemessenen Rate erfolgen.
- Fehlerbehandlung : Implementieren Sie eine robuste Fehlerbehandlung, um Probleme wie Zeitüberschreitungen oder Serverfehler ordnungsgemäß zu verwalten.
- Datenqualitätssicherung : Überprüfen Sie regelmäßig die Qualität der Scraping-Daten, um Genauigkeit und Vollständigkeit sicherzustellen.
- Bleiben Sie auf dem Laufenden : Bleiben Sie über die neuesten Entwicklungen bei Web-Scraping-Technologien und gesetzlichen Vorschriften auf dem Laufenden.
Indem Sie diese Faktoren sorgfältig abwägen und Best Practices befolgen, können Sie einen Web-Scraper auswählen, der nicht nur Ihre Datenerfassungsanforderungen erfüllt, sondern dies auch auf effiziente, ethische und gesetzeskonforme Weise tut.
PromptCloud: Beste Web-Scraping-Lösungen für Ihre Datenanforderungen
Im dynamischen Bereich der Datenerfassung und -analyse erweist sich PromptCloud als führender Anbieter modernster Web-Scraping-Lösungen. PromptCloud ist auf Unternehmen und Privatpersonen zugeschnitten, die die Leistungsfähigkeit von Daten nutzen möchten, und bietet eine Reihe von Scraping-Diensten an, die sich durch Effizienz, Zuverlässigkeit und Compliance auszeichnen. Hier erfahren Sie, warum PromptCloud Ihre erste Wahl für Web Scraping ist:
Maßgeschneiderte Web-Scraping-Dienste :
- Maßgeschneiderte Lösungen : PromptCloud ist sich bewusst, dass jede Datenanforderung einzigartig ist. Ihre maßgeschneiderten Web-Scraping-Dienste sind auf spezifische Anforderungen zugeschnitten, sei es das Scraping großer Datenmengen oder das Extrahieren von Informationen aus komplexen Websites.
Skalierbarkeit und Zuverlässigkeit :
- Bewältigung großer Datenanforderungen : Die Infrastruktur von PromptCloud ist darauf ausgelegt, die Extraktion großer Datenmengen mühelos zu verwalten und so Zuverlässigkeit und Konsistenz bei der Datenbereitstellung zu gewährleisten.
- Hohe Verfügbarkeitsgarantie : Sie bieten eine robuste Plattform mit einer hohen Verfügbarkeitsgarantie und stellen sicher, dass Ihr Datenerfassungsprozess unterbrechungsfrei und effizient ist.
Fortschrittliche Technologie und Funktionen :
- Modernste Tools : Mithilfe der neuesten Web-Scraping-Technologie kann PromptCloud durch ausgefeilte Anti-Scraping-Maßnahmen und dynamisch geladene Inhalte navigieren.
- Daten in gebrauchsfertigen Formaten : Sie liefern Daten in verschiedenen strukturierten Formaten, sodass sie für Ihre Geschäftsanforderungen sofort umsetzbar sind.
PromptCloud ist ein Leuchtturm für Unternehmen und Einzelpersonen, die die Leistungsfähigkeit von Web Scraping nutzen möchten, ohne die Komplexität, die mit der Einrichtung und Wartung solcher Systeme verbunden ist. Mit PromptCloud erhalten Sie Zugriff auf genaue, aktuelle und konforme Daten und ermöglichen Ihrem Unternehmen, fundierte Entscheidungen zu treffen und im wettbewerbsintensiven Marktumfeld die Nase vorn zu haben.
Sind Sie bereit, das Potenzial des Web Scraping auszuschöpfen?
Entdecken Sie die Angebote von PromptCloud und machen Sie den ersten Schritt zur Transformation Ihrer Datenstrategie. Kontaktieren Sie uns unter [email protected], um mehr über ihre Dienstleistungen zu erfahren und darüber, wie sie der Schlüssel zur Erschließung Ihres Datenpotenzials sein können.