
O que é um raspador de web e como funciona?
Publicados: 2024-01-16No vasto e em constante evolução da Internet, os dados tornaram-se a força vital da tomada de decisões e do planeamento estratégico em vários setores. É aqui que reside a importância dos web scrapers – ferramentas poderosas que navegam no mar colossal de informações online. Mas o que exatamente é web scraping e por que se tornou tão crucial na era digital?
Web scraping, em sua essência, envolve a extração automatizada de dados de sites. Este processo, muitas vezes realizado por software ou scripts especializados, permite a recolha de informação específica de páginas web e a sua transformação num formato estruturado, normalmente para análise ou utilização noutras aplicações.
Em um mundo onde os dados são reis, o web scraping serve como um facilitador essencial. Ele permite que empresas, pesquisadores e indivíduos acessem e aproveitem dados públicos da web de forma eficiente e eficaz. Da análise da concorrência e pesquisa de mercado ao rastreamento de sentimentos sociais e projetos acadêmicos, as aplicações de web scraping são tão diversas quanto impactantes.
O que é um web scraper: o básico
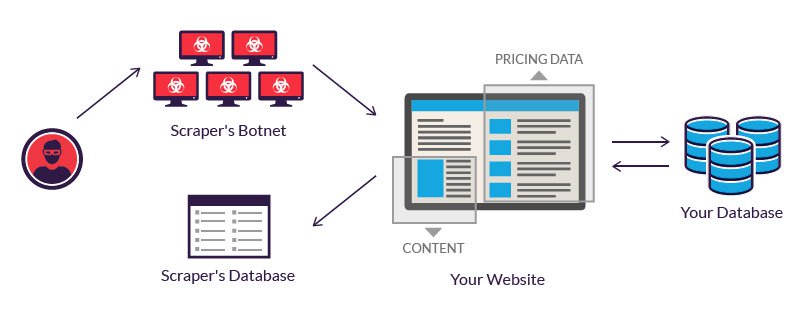
Fonte: https://www.imperva.com/learn/application-security/web-scraping-attack/
Web scraping é um processo que envolve a extração automatizada de informações de sites. Esta técnica emprega software ou scripts especializados projetados para acessar páginas da web, recuperar os dados necessários e, em seguida, converter esses dados em um formato estruturado para uso posterior. A simplicidade desta definição, no entanto, desmente a sofisticação e versatilidade da web scraping como ferramenta. Agora, você deve ter entendido o que é um web scraper, então vamos aprender como ele funciona.
Em seu nível mais fundamental, o web scraping tem duas funções principais:
- Coleta de dados : os programas de web scraping são adeptos da navegação pelas páginas da web, identificando e coletando tipos específicos de dados. Isso pode incluir detalhes de produtos de sites de comércio eletrônico, preços de ações de sites financeiros, anúncios de emprego de portais de emprego ou qualquer outro conteúdo da web acessível ao público.
- Transformação de dados : depois que os dados são coletados, as ferramentas de web scraping transformam esses dados não estruturados da web (geralmente código HTML) em um formato estruturado, como CSV, Excel ou banco de dados. Essa transformação torna os dados mais fáceis de analisar, manipular e utilizar para diversos fins.
Essas funções básicas de web scraping o tornam uma ferramenta poderosa para qualquer pessoa que precise acessar grandes quantidades de informações baseadas na web de forma rápida e eficiente. Quer se trate de uma pequena empresa monitorando os preços dos concorrentes ou de uma grande corporação analisando tendências de mercado, o web scraping fornece um meio de coletar dados relevantes sem a necessidade de extração manual. Nas próximas seções, nos aprofundaremos em como essas ferramentas de scraping funcionam, seus diferentes tipos e sua vasta gama de aplicações no mundo digital.
Como funcionam os web scrapers: um mergulho técnico
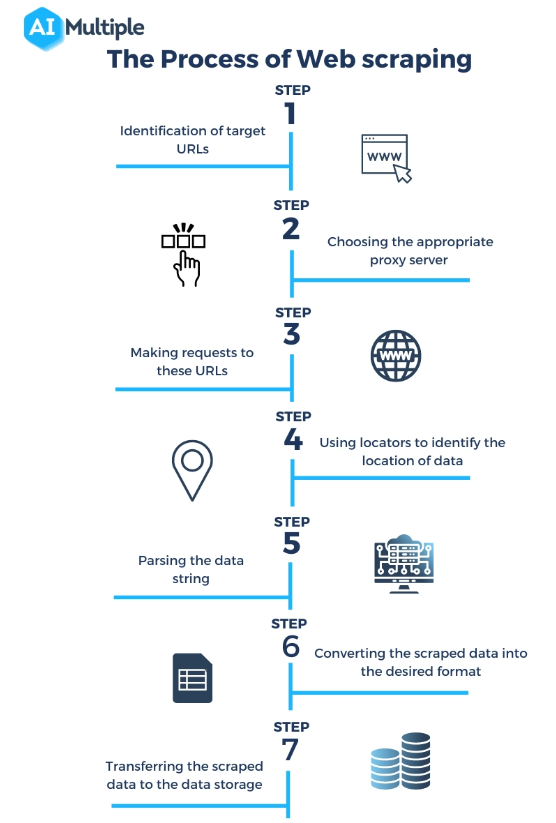
Fonte: https://research.aimultiple.com/web-scraping-vs-api/
O que é um raspador de web? Web scraping pode parecer mágica, mas na verdade é um processo técnico bem orquestrado que envolve várias etapas para acessar, extrair e processar dados de sites. Aqui está uma visão mais detalhada de como funcionam os web scrapers:
Enviando uma solicitação ao servidor Web :
A primeira etapa do web scraping é o raspador enviar uma solicitação ao servidor web que hospeda a página de destino. Isso é semelhante ao que acontece quando você digita uma URL no navegador; a diferença é que o raspador envia a solicitação programaticamente.
Recuperando a página da Web :
Assim que a solicitação é enviada, o servidor responde com o conteúdo da página web, normalmente em formato HTML. O raspador então baixa esse conteúdo para processamento. Em alguns casos, a renderização de JavaScript pode ser necessária para carregar totalmente o conteúdo da página, o que alguns scrapers avançados podem lidar.
Analisando o conteúdo HTML :
A página recuperada geralmente está no formato HTML, que é uma linguagem de marcação com uma estrutura específica. O raspador analisa esse conteúdo HTML para entender sua estrutura – identificando cabeçalhos, parágrafos, links e outros elementos com base em suas tags HTML.
Extraindo dados relevantes :
Após a análise, o raspador identifica e extrai os dados específicos de interesse. Pode ser qualquer coisa, desde descrições e preços de produtos até textos de artigos ou dados estatísticos. A extração é baseada nos elementos HTML e seus atributos, como nomes de classes ou IDs.
Transformação e armazenamento de dados :
Os dados extraídos, ainda em formato bruto, são então transformados em um formato estruturado como CSV, JSON ou diretamente em um banco de dados. Esta etapa é crucial para tornar os dados utilizáveis para análise ou integração com outras aplicações.
Lidando com Desafios :
A raspagem da Web pode encontrar desafios como conteúdo carregado dinamicamente, medidas anti-raspagem por sites e manutenção do estado da sessão. Scrapers avançados navegam neles imitando o comportamento de navegação humano, alternando endereços IP e gerenciando cookies e sessões.
Respeitando os limites legais e éticos :
Os web scrapers éticos são programados para respeitar os limites legais do web scraping. Isso envolve seguir as diretrizes do arquivo robots.txt do site, evitar carga excessiva do servidor e garantir a conformidade com as leis de privacidade de dados.
Tipos de raspadores de web: explorando as variedades
As ferramentas de web scraping vêm em vários formatos, cada um projetado para atender a necessidades e desafios específicos. Compreender esses diferentes tipos ajuda a selecionar a ferramenta certa para o trabalho. Vamos explorar alguns dos tipos comuns de web scrapers:
Raspadores de HTML :
- Funcionalidade : os raspadores de HTML são a forma mais básica de raspadores da web. Eles baixam o conteúdo HTML das páginas da web e extraem dados analisando o código HTML.
- Casos de uso : Ideal para sites estáticos onde os dados são incorporados diretamente no HTML.
Raspadores de API :
- Funcionalidade : Esses scrapers extraem dados de APIs (Interfaces de Programação de Aplicativos) fornecidas por sites. Em vez de analisar HTML, eles fazem solicitações a um endpoint de API e recebem dados em um formato estruturado como JSON ou XML.
- Casos de uso : Adequado para sites com APIs públicas, oferecendo uma forma mais eficiente e confiável de extração de dados.
Raspadores baseados em navegador :
- Funcionalidade : Essas ferramentas imitam um navegador da web para interagir com as páginas da web. Eles podem executar solicitações JavaScript e AJAX, tornando-os capazes de extrair conteúdo dinâmico.
- Casos de uso : essenciais para sites que dependem muito de JavaScript para renderização de conteúdo, como aplicativos da web modernos.
Raspadores de navegador sem cabeça :
- Funcionalidade : Operando de forma semelhante aos scrapers baseados em navegador, eles usam navegadores headless (navegadores sem interface gráfica de usuário) para renderizar páginas da web. Eles podem lidar com páginas da web complexas que requerem gerenciamento de sessão, cookies e execução de JavaScript.
- Casos de uso : úteis para extrair dados de sites complexos e dinâmicos e aplicativos de página única (SPAs).
Raspadores visuais da Web :
- Funcionalidade : São scrapers fáceis de usar com uma interface gráfica que permite aos usuários selecionar visualmente pontos de dados em uma página da web. São menos técnicos e não requerem conhecimentos de programação.
- Casos de uso : Ideal para usuários que não são programadores, mas precisam extrair dados de sites sem configurações complexas.
Raspadores da Web SaaS :
- Funcionalidade : São oferecidos como serviço por empresas especializadas em web scraping. Eles lidam com as complexidades da raspagem e fornecem dados em um formato pronto para uso.
- Casos de uso : Adequado para empresas que exigem recursos de web scraping, mas não desejam lidar com os aspectos técnicos.
Raspadores personalizados :
- Funcionalidade : Construídos para requisitos específicos, esses scrapers são adaptados para atender a necessidades exclusivas de extração de dados, muitas vezes envolvendo lógica e recursos complexos.
- Casos de uso : necessários ao lidar com operações de raspagem em grande escala ou altamente complexas que as ferramentas disponíveis no mercado não conseguem realizar.
Cada tipo de web scraper tem seus pontos fortes e é adequado para diferentes cenários. Desde a simples raspagem de HTML até lidar com conteúdo dinâmico e APIs, a escolha depende da estrutura do site, da complexidade da tarefa e do conhecimento técnico do usuário. Nas próximas seções, nos aprofundaremos nas aplicações práticas dessas ferramentas e como elas transformam dados em insights valiosos.

O cenário jurídico: Compreendendo a conformidade e a ética na web scraping
Web scraping, embora seja uma ferramenta poderosa para extração de dados, opera em um cenário jurídico e ético complexo. É crucial que empresas e indivíduos envolvidos em web scraping entendam a legalidade e as considerações éticas para garantir a conformidade e manter boas práticas. Esta seção esclarece estes aspectos:
Considerações legais sobre web scraping :
- Leis de direitos autorais : Os dados publicados na Internet são frequentemente protegidos por leis de direitos autorais. A extração de dados protegidos por direitos autorais sem permissão pode levar a problemas legais.
- Contratos de termos de serviço : muitos sites incluem cláusulas em seus Termos de serviço (ToS) que proíbem explicitamente o web scraping. A violação destes termos pode resultar em ações legais por parte do proprietário do site.
- Leis de privacidade de dados : Regulamentações como GDPR (Regulamento Geral de Proteção de Dados) e CCPA (Lei de Privacidade do Consumidor da Califórnia) impõem regras rígidas sobre como os dados pessoais podem ser coletados e usados. Os web scrapers devem garantir a conformidade com essas leis de privacidade.
Considerações éticas em web scraping :
- Respeitando o robots.txt : este arquivo em sites especifica como e o que os rastreadores da web podem raspar. A raspagem ética da web envolve a adesão a essas diretrizes.
- Minimizando a carga do servidor : a raspagem agressiva pode sobrecarregar o servidor de um site, potencialmente causando seu travamento. Os scrapers éticos são projetados para imitar a velocidade e os padrões de navegação humana para evitar tais problemas.
- Transparência e Propósito : A raspagem ética envolve ser transparente sobre quem está coletando os dados e com que finalidade. Significa também evitar a extração de informações confidenciais.
Melhores práticas para web scraping legal e ético :
- Solicitar permissão : sempre que possível, é melhor solicitar permissão do proprietário do site antes de extrair seus dados, especialmente se os dados forem confidenciais ou protegidos por direitos autorais.
- Aderir aos padrões legais : Certifique-se de que suas atividades de raspagem cumpram as leis locais e internacionais relevantes.
- Utilizar os dados com responsabilidade : Os dados coletados devem ser utilizados de forma ética e responsável, respeitando a privacidade do usuário e evitando danos aos titulares dos dados.
Navegando em áreas cinzentas :
- A legalidade do web scraping geralmente cai em áreas cinzentas, dependendo de como os dados são usados, da natureza dos dados e da jurisdição. É aconselhável consultar especialistas jurídicos em caso de dúvida.
Compreender e aderir às considerações legais e éticas do web scraping não envolve apenas conformidade, mas também manter a integridade e a reputação do seu negócio. À medida que avançamos, as práticas de web scraping provavelmente continuarão a evoluir junto com o cenário jurídico, tornando imperativo que os usuários se mantenham informados e conscientes.
Escolhendo um Web Scraper: dicas e práticas recomendadas
Selecionar o web scraper certo é uma decisão crucial que pode impactar significativamente a eficácia de seus esforços de coleta de dados. Aqui estão algumas dicas e práticas recomendadas para orientá-lo na escolha da ferramenta de web scraping ideal e no uso eficaz dela:
Avalie suas necessidades :
- Entenda seus requisitos : antes de mergulhar na infinidade de ferramentas de web scraping disponíveis, esclareça o que você precisa fazer, com que frequência precisa fazer isso e a complexidade dos dados e sites envolvidos.
- Escalabilidade : considere se você precisa de uma ferramenta que possa lidar com scraping em grande escala ou se uma solução mais simples e direta será suficiente.
Avalie os recursos :
- Facilidade de uso : se você não tiver conhecimento técnico, procure um raspador com uma interface amigável ou recursos visuais de apontar e clicar.
- Capacidades de extração de dados : certifique-se de que a ferramenta possa extrair o tipo de dados que você precisa (texto, imagens, etc.) e lidar com conteúdo dinâmico carregado com JavaScript ou AJAX.
- Opções de exportação de dados : verifique os formatos nos quais o scraper pode exportar dados (CSV, JSON, bancos de dados, etc.) e certifique-se de que atendam aos seus requisitos.
Considere a conformidade legal :
- Escolha um raspador que respeite os termos de serviço e os padrões legais do site, especialmente ao lidar com dados confidenciais ou pessoais.
Verifique se há desvio do recurso anti-raspagem :
- Muitos sites empregam medidas anti-raspagem. Certifique-se de que a ferramenta selecionada possa navegar com eficácia por eles, possivelmente por meio de recursos como rotação de IP, troca de agente de usuário e resolução de CAPTCHA.
Suporte Técnico e Comunidade :
- Uma ferramenta com bom suporte técnico e uma comunidade de usuários ativa pode ser inestimável, especialmente quando você encontra desafios ou precisa se adaptar às mudanças na tecnologia de web scraping.
Melhores práticas no uso do Web Scraper :
- Respeite o robots.txt : siga as diretrizes do arquivo robots.txt do site para manter práticas éticas de scraping.
- Limitação de taxa : para evitar sobrecarregar os servidores do site, configure seu scraper para fazer solicitações a uma taxa razoável.
- Tratamento de erros : implemente um tratamento robusto de erros para gerenciar problemas como tempos limite ou erros de servidor normalmente.
- Garantia de qualidade de dados : verifique regularmente a qualidade dos dados extraídos para garantir precisão e integridade.
- Mantenha-se informado : mantenha-se atualizado sobre os últimos desenvolvimentos em tecnologias de web scraping e regulamentações legais.
Considerando cuidadosamente esses fatores e seguindo as práticas recomendadas, você pode escolher um web scraper que não apenas atenda às suas necessidades de coleta de dados, mas também o faça de maneira eficiente, ética e legalmente compatível.
PromptCloud: as melhores soluções de web scraping para suas necessidades de dados
No domínio dinâmico da coleta e análise de dados, a PromptCloud emerge como líder no fornecimento de soluções de web scraping de última geração. Feito sob medida para empresas e indivíduos que buscam aproveitar o poder dos dados, o PromptCloud oferece uma variedade de serviços de scraping que se destacam por sua eficiência, confiabilidade e conformidade. Veja por que o PromptCloud é sua escolha para web scraping:
Serviços personalizados de web scraping :
- Soluções sob medida : PromptCloud entende que cada requisito de dados é único. Seus serviços personalizados de web scraping são projetados para atender a necessidades específicas, seja na extração de grandes volumes de dados ou na extração de informações de sites complexos.
Escalabilidade e Confiabilidade :
- Lidar com necessidades de dados em grande escala : a infraestrutura do PromptCloud foi construída para gerenciar a extração de dados em grande escala sem esforço, garantindo confiabilidade e consistência na entrega de dados.
- Garantia de alto tempo de atividade : Fornecem uma plataforma robusta com garantia de alto tempo de atividade, garantindo que seu processo de coleta de dados seja ininterrupto e eficiente.
Tecnologia e recursos avançados :
- Ferramentas de ponta : Utilizando o que há de mais moderno em tecnologia de web scraping, o PromptCloud pode navegar por medidas anti-raspagem sofisticadas e conteúdo carregado dinamicamente.
- Dados em formatos prontos para uso : eles fornecem dados em vários formatos estruturados, tornando-os imediatamente acionáveis para suas necessidades de negócios.
PromptCloud é um farol para empresas e indivíduos que buscam aproveitar o poder do web scraping sem as complexidades envolvidas na configuração e manutenção de tais sistemas. Com o PromptCloud, você obtém acesso a dados precisos, oportunos e compatíveis, capacitando sua empresa a tomar decisões informadas e permanecer à frente no cenário competitivo do mercado.
Pronto para desbloquear o potencial de web scraping?
Explore as ofertas do PromptCloud e dê o primeiro passo para transformar sua estratégia de dados. Entre em contato conosco em [email protected] para saber mais sobre seus serviços e como eles podem ser a chave para desbloquear o potencial de seus dados.