
Technische Aspekte der Kundensegmentierung Teil 2 – Datenintegrität
Veröffentlicht: 2022-04-18Der letzte Artikel hat uns geholfen zu verstehen, wie die Datensynchronisierung eine effektive Segmentierung ermöglicht. Aber um ein echter Segmentierungsexperte zu werden, brauchen Sie noch etwas – die Fähigkeit, die Qualität von Daten zu bewerten und aufrechtzuerhalten, die zusammenfassend als Datenintegrität definiert wird. Der beste Weg, dies zu lernen, ist zwar die Übung, aber wenn Sie sich mit kritischen Konzepten befassen, erhalten Sie einen Vorsprung.
Datenintegrität ist ein weites Feld. Um ehrlich zu sein, ist dies das oberste Ziel der gesamten IT-Abteilung. Sie alle werden eingestellt, um zu vermeiden, dass Erkenntnisse auf der Grundlage falscher Daten gezogen werden.
Wenn wir es auf die Kundensegmentierung eingrenzen, sollte sich ein CRM-Spezialist der Einzigartigkeit von Daten, Datentypen und Dateneinschränkungen bewusst sein.
Eindeutigkeit der Daten
Stellen Sie sich vor, ein Kunde erhält zweimal eine Nachricht oder schlimmer noch, er erhält jedes Mal zweimal eine Nachricht mit einem anderen Rabatt. Ein einzelner Fall wird nicht viel Schaden anrichten, aber wenn diese Zahl steigt, könnte die Kampagne ein sofortiger Fehlschlag mit langfristigen Folgen sein, einschließlich des Loyalitätsverlusts.
Aus diesem Grund muss Ihre Kundendatenbank für die Eindeutigkeit der Daten sorgen. Dazu müssen Sie eine Kennung finden, mit der Sie zwischen zwei Kunden unterscheiden können. Das kann eine E-Mail oder eine Telefonnummer sein. Obwohl sie für jeden Tom, Dick oder Harry einzigartig sind, sind sie keine guten Kandidaten für eine Kennung. Zunächst einmal können sich E-Mail-Adressen und Telefonnummern für eine Person ändern. Zweitens haben Sie möglicherweise Probleme, die Eindeutigkeit von E-Mails sicherzustellen, einschließlich „.“ und „+“ oder nicht-englische Zeichen.
Aus diesem Grund verwenden CRMs eine eindeutige interne Kennung. Es wird als Universally Unique Identifier (UUID) oder Global Unique Identifier (GUID) geprägt.
Dies sind Algorithmen, die die eindeutigen Attribute des Kunden (wie E-Mail oder Telefonnummer) verwenden, sie verschlüsseln und eine Zeichenfolge aus zufälligen Zeichen generieren – einzigartig für jeden Kunden . Wenn John Ihr Kunde wird, generiert CRM eine Kennung für ihn, z. B. 8f14a65f-3032-42c8-a196-1cf66d11b930.
Indem Sie eine so lange ID erstellen, reduzieren Sie das Risiko, eine doppelte ID zu generieren, auf fast Null.
Datentypen
Das Format, in dem Sie Daten speichern, kann eine weitere Bedrohung darstellen oder zur Datenintegrität beitragen. Stellen Sie sich vor, Sie führen eine Umfrage durch und fragen Ihr Publikum nach einem Lieblings-Smartphone – Sie möchten jedem Kunden, der sich während der Aktion für das iPhone X entschieden hat, ein Angebot senden.
Wenn Sie die Liste der Antworten lesen, sehen Sie die folgenden Datensätze:
- iPhone X
- iPhone X
- ich Telefon10
- iPhone X
- iPhone 10
- Nokia 3310
- Und so weiter...
Beim Erstellen eines Segments für „iPhone X“-Kunden zeigt das System nur einen Kunden statt fünf an. Die Lösung für dieses Problem ist einfach – ändern Sie einfach den Antwortfeldtyp in eine vordefinierte Liste statt in einen offenen Text. Aber wenn Sie es vor einem Rollout vergessen, haben Sie am Ende viele manuelle Jobs auf Ihrem Teller.

Einfache, aber lästige Fehler wie dieser können vermieden werden, indem das Datenmodell für jeden Schritt der Kundenreise verstanden und überprüft wird. Der erste Schritt besteht darin, die Dokumentation zu den Optionen zu besuchen, die Ihr CRM bietet, um Daten für jede Entität zu speichern und zu verarbeiten – es wird als Datenschema bezeichnet.
Lassen Sie uns untersuchen, wie ein Datenschema aussieht und wie Sie seine Funktionen verwenden können, um die Datenintegrität sicherzustellen. Datentypen gehen zuerst.
Datentypen
Datentypen sind Datenattribute, die CRM mitteilen, wie wir die Daten verwenden oder welche Operationen wir mit ihnen durchführen können. Hier ist die Liste der Typen, die Sie in so ziemlich jedem CRM-Tool finden können.
Primitive – Grundtypen
- Boolean – stellt Werte wahr oder falsch dar. Stellen Sie sich zum Beispiel ein Attribut vor: is_first_time_customer.
- Ganzzahl – stellt eine positive oder negative Zahl dar, die kein Dezimalkomma hat. Beispielsweise haben Ganzzahlen in Salesforce CRM einen Mindestwert von -2.147.483.648 und einen Höchstwert von 2.147.483.647.
- Dezimal (Float) – eine Zahl, die einen Dezimalpunkt enthält, z. B. 3,14159.
- Zeichen – ein einzelner Buchstabe oder ein beliebiges Zeichen, einschließlich Zahlen (zusammen als alphanumerisch bezeichnet).
- Zeichenfolge – speichert eine Zeichenfolge aus beliebigen alphanumerischen Zeichen, z. B. ein Wort, eine Phrase oder einen Satz.
- Datum – ein Wert, der einen bestimmten Tag angibt.
- Datetime – ein Wert, der einen bestimmten Tag und eine bestimmte Uhrzeit angibt.
- Blob – (vom Binary Large Object) eine Sammlung von Binärdaten, die als einzelnes Objekt gespeichert werden. Sie können es sich der Einfachheit halber als eine einzelne Datei vorstellen (Bild, Sprachaufnahme, Film, PDF usw.).
Bevor wir zu fortgeschrittenen Typen übergehen, lassen Sie uns einen Moment innehalten, um etwas Intuition zu gewinnen, wie man den richtigen Typ auswählt. Sie haben wahrscheinlich schon bemerkt, dass jeder Datentyp zwei Eigenschaften hat:
- welche Art von Werten es darstellen kann,
- Was sind die minimalen und maximalen Werte, die es speichern kann?
Für beide gibt es zwei Faustregeln:
1) Wenn es um die Wertedarstellung geht – je mehr Flexibilität Sie haben, desto weniger Datenautomatisierung ist möglich, oder besser, desto mehr Arbeit in Software ist notwendig, um Daten zu verarbeiten. Ein einfaches Beispiel wäre die Postleitzahl in den USA. Wenn es sich um eine Zahl handelt, können wir Bereiche verwenden, um auf den Staat zu schließen (z. B. Alabama ist 35801 bis 35816). Das wäre für die Saite unmöglich.
Ein weiteres gutes Beispiel wäre unsere Umfrage. Wenn wir iPhone X-Varianten mit der offenen Textversion zählen wollten, müssten wir unsere Abfrage so anpassen, dass sie alle Werte enthält. Außerdem müssten wir die Abfrage pflegen – jedes Mal, wenn wir eine neue Variante finden, die von einem Benutzer eingegeben wurde, muss die Abfrage aktualisiert werden.
2) Die zweite Regel betrifft die Mindest- und Höchstwerte. Je größer Sie ein Attribut einrichten, desto flexibler ist es. Jetzt fragen Sie sich vielleicht, warum Sie nicht immer die größte Option verwenden? Weil die größere Größe mehr Computerspeicher benötigt, um Daten zu verarbeiten, und dies mehr kostet. Es kann vernachlässigbar sein, wenn Sie Hunderte von Datensätzen haben, aber wenn Sie auf Millionen anwachsen, reagiert Ihre CRM-Instanz möglicherweise langsamer oder Sie stoßen an das Limit und sind gezwungen, auf einen höheren Preisplan umzusteigen.
Composite – Ergebnis der Kombination von zwei oder mehr Primitiven
- Array – eine Gruppe von Primitiven beliebiger Größe. Es wird normalerweise als eine Reihe oder Primitive in Klammern dargestellt, zB [1, 3, 5, 13, 5].
- Set – eine Gruppe von Primitives beliebiger Größe, aber nur mit eindeutigen Werten [1, 3, 5, 13].
- Aufzählung – eine Aufzählung (von Enumerator) ist ein Datentyp mit Werten, die jeweils genau einen aus einer endlichen Menge von Identifikatoren annehmen, die Sie angeben (diesen sollten wir für unsere Umfrage verwenden, um das Durcheinander zu vermeiden!).
- Objekt – Ein Objekt ist ein Wert, der andere Werte enthält, normalerweise in festen Zahlen und Sequenzen und normalerweise durch Namen indiziert. Die Elemente von Datensätzen werden normalerweise als Felder oder Mitglieder bezeichnet. Erinnern Sie sich an die JSON-Beispiele aus dem ersten Teil, sie sind Objekte.
Datenbeschränkungen
Datentypen helfen uns bereits, die Ordnung in den Daten aufrechtzuerhalten und langwierige Datenbereinigungsaufgaben zu vermeiden, worauf wir mit Hilfe von Maschinen reagieren können. Aber wir können mehr als das mit Einschränkungen tun.

Datenbeschränkungen definieren bestimmte Eigenschaften, denen Daten entsprechen müssen. Ein zuverlässiges CRM-System stellt sicher, dass die Einschränkungen jederzeit gelten – z. B. wenn Sie ein neues Objekt erstellen oder ein vorhandenes ändern .
Haben Sie jemals eine E-Mail mit dem Titel "Sehr geehrter {first.name}" erhalten? Dies kann darauf zurückzuführen sein, dass Sie eine NOT NULL-Einschränkung für das Vornamensattribut vergessen haben.
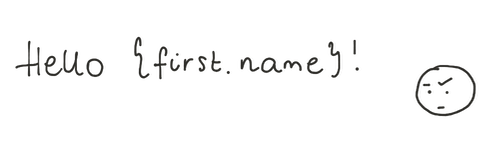
So funktionieren diese und andere typische Einschränkungen:
- Nicht null – jeder Wert darf nicht „NULL“ sein, was im Klartext bedeutet, dass er nicht leer sein darf.
- Eindeutig – Wert(e) müssen für jedes Objekt in einer Datenbank eindeutig sein. Wenn Sie beispielsweise Kunden per E-Mail oder Telefonnummer identifizieren möchten, sollten Sie dieses Feld eindeutig machen, um doppelte Nachrichten und schwerwiegendere Probleme zu vermeiden.
- Primärschlüssel – Wert(e) müssen für jedes Objekt eindeutig sein und dürfen nicht NULL sein. Die meisten CRMs implementieren diese Einschränkungen standardmäßig.
- Fremdschlüssel – Wert(e) müssen auf einen vorhandenen Datensatz in einem anderen Objekt verweisen (über seinen Primärschlüssel oder eine andere eindeutige Einschränkung). Stellen Sie sich vor, Sie finden in Ihrem System einen Geschenkgutschein, der jedoch keine Besitzerinformationen enthält. Sie zögern, es zu deaktivieren, weil vielleicht einer Ihrer Kunden es bekommen hat und enttäuscht sein wird, wenn es an der Kasse scheitert. Das Hinzufügen eines Fremdschlüssels zwischen einer Geschenkkarte und Kundenobjekten würde dieses Problem lösen, da das System keine Karte ohne zugewiesenen Besitzer erstellt oder versehentlich einen Besitzer von einer vorhandenen Karte entfernt.
- Check – ein Ausdruck, der wahr sein muss, damit die Bedingung erfüllt wird. Dies ist eine übergreifende Einschränkung für Bedingungen, die Sie auf Attribute bestimmter Datentypen anwenden können. Die folgenden Beispiele sollen Ihnen helfen, das Konzept zu verstehen:
- E-Mail (String) sollte einem bestimmten Muster entsprechen (lesen Sie den Wiki-Artikel, um zu sehen, dass es komplizierter ist als das obligatorische @ in der Mitte).
- Das Alter (Ganzzahl) sollte größer als 13 sein.
- Das Geburtsdatum (Datum) sollte im März liegen.
- Die Kundenerstellung (Datum) sollte vor dem 1. Oktober 2020 liegen.
- Die letzte Bestellung (DateTime) sollte nicht vor gestern Mittag erfolgen.
- Die Telefonnummer (String) sollte mit einer Landesvorwahl beginnen.
- Adresse (Objekt) sollte aus Straße, Hausnummer, Stadt, Land, Postleitzahl bestehen – die ihre eigenen „Check“-Einschränkungen haben können.
Datennormalisierung
Es gibt noch ein weiteres Konzept, das Sie kennen sollten, um Ihr Verständnis der Datenintegrität zu verbessern, nämlich den Teil der Datenduplizierung, um genauer zu sein. Es heißt Datennormalisierung .
Nehmen wir als Beispiel ein Treueprogramm. Wir müssen Kunden in Ebenen gruppieren, um später einige Analysen durchzuführen. Stellen Sie sich eine Tabelle vor, die Informationen darüber enthält, wann ein Kunde einer bestimmten Ebene beigetreten ist.
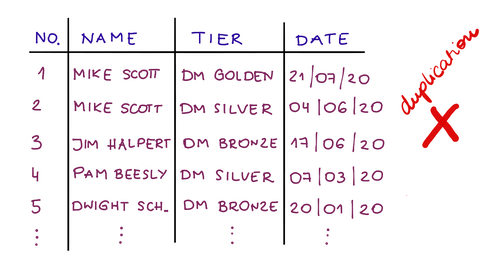
Anstatt den Namen der Stufe zu speichern, der für jede Person so lang sein kann wie Dunder Mifflin Golden Tier, speichern wir einfach eine Nummer, die auf eine Tabelle der Programmstufen verweist.
Anstatt also 20.000 Dunder Mifflin Golden Tier zu halten, haben wir 20.000 Referenzen wie Nr. 3. Wenn Sie den Ebenennamen aus irgendeinem Grund ändern möchten, müssen Sie ihn nur an einer Stelle aktualisieren, und die Datenintegrität bleibt erhalten.
Lassen Sie uns nun tiefer in ein fortgeschritteneres Normalisierungskonzept einsteigen. Angenommen, Sie möchten überwachen, wie sich ein Kunde über verschiedene Stufen bewegt. Wir könnten es in der folgenden Tabelle speichern:
Kunde | Stufe | Stufe-Eingabedatum
Mike Scott | DM Goldene Stufe | 21.07.2020
Mike Scott | DM-Silberstufe | 04.06.2020
Jim Halpert | DM-Bronzestufe | 17.06.2020
Es ist jedoch besser, drei separate Objekte zu erstellen, um dies zu speichern, eine Tabelle mit der Liste der Stufen, eine Tabelle mit der Liste der Kunden und eine weitere, um beide zu verbinden. Das gibt uns die größtmögliche Freiheit, wenn wir Kunden- oder Stufeninformationen separat ändern , und wir haben natürlich weniger doppelte Daten .
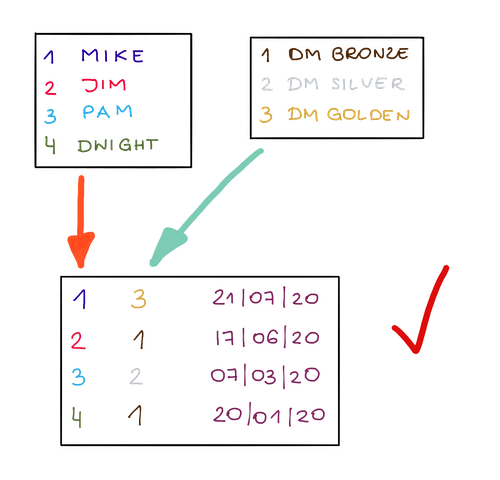
Die Standard-CRM-Objekte folgen normalerweise Datennormalisierungskonzepten. Wenn Sie jedoch benutzerdefinierte Objekte erstellen möchten, indem Sie das Standardschema erweitern, sollten Sie die Datennormalisierung immer im Hinterkopf behalten.
Imbiss
Wenn Sie mit einem neuen CRM arbeiten, besuchen Sie dessen Dokumentation, um das Datenschema zu erkunden. Gehen Sie die Standardobjekte durch, um zu sehen, was Sie sofort tun können. Lernen Sie Datentypen kennen und erfahren Sie, wie Sie mit integrierten Mechanismen wie Hubspot-Berechnungen, von Salesforce berechneten Feldern mit Formeln auf sie reagieren oder wie Sie sie mit Vorlagensprachen wie Liquid präsentieren können.
Als Übung können Sie auch den Artikel von Fabric über das Erstellen eines E-Commerce-Datenschemas lesen, um zu untersuchen, wie eine Datenintegritätstheorie aus diesem Beitrag auf einen realen Anwendungsfall angewendet werden kann.