
Aspek Teknis Segmentasi Pelanggan Bagian 2 – Integritas Data
Diterbitkan: 2022-04-18Artikel terakhir membantu kami memahami bagaimana sinkronisasi data memungkinkan segmentasi yang efektif. Namun untuk menjadi ahli segmentasi yang sesungguhnya, Anda memerlukan satu hal lagi — kemampuan untuk mengevaluasi dan memelihara kualitas data, yang secara kolektif didefinisikan sebagai integritas data . Meskipun cara terbaik untuk mempelajarinya adalah melalui latihan, membungkus kepala Anda dengan konsep-konsep penting akan memberi Anda awal yang baik.
Integritas data adalah topik yang luas. Sejujurnya, itu adalah tujuan terpenting dari seluruh departemen TI. Mereka semua dipekerjakan untuk menghindari menggambar wawasan berdasarkan data yang salah.
Ketika kami mempersempitnya menjadi segmentasi pelanggan, spesialis CRM harus menyadari keunikan data, tipe data, dan batasan data.
Keunikan data
Bayangkan seorang pelanggan mendapatkan pesan dua kali atau, lebih buruk lagi, mendapatkan pesan dua kali setiap kali dengan diskon yang berbeda. Satu kasus tidak akan menyebabkan banyak kerugian, tetapi jika jumlah ini meningkat, kampanye mungkin gagal seketika dengan konsekuensi jangka panjang, termasuk penurunan loyalitas.
Inilah sebabnya mengapa basis data pelanggan Anda harus menjaga keunikan data. Untuk melakukannya, Anda perlu menemukan pengenal yang memungkinkan Anda membedakan antara dua pelanggan. Mungkin email atau nomor telepon. Meskipun mereka unik untuk setiap Tom, Dick, atau Harry, mereka bukan kandidat yang baik untuk pengenal. Pertama-tama, alamat email dan nomor telepon mungkin berubah untuk seseorang. Kedua, Anda mungkin mengalami masalah dalam memastikan keunikan email, termasuk "." dan karakter “+” atau non-Inggris.
Itu sebabnya CRM menggunakan pengidentifikasi internal yang unik. Ini diciptakan sebagai pengidentifikasi unik universal (UUID) atau pengidentifikasi unik global (GUID) .
Ini adalah algoritme yang mengambil atribut unik pelanggan (seperti email atau nomor telepon), mengenkripsinya, dan menghasilkan serangkaian karakter acak — unik untuk setiap pelanggan . Saat John menjadi pelanggan Anda, CRM akan membuatkan pengenal untuknya, seperti 8f14a65f-3032-42c8-a196-1cf66d11b930.
Dengan membuat pengidentifikasi yang begitu panjang, Anda mengurangi risiko menghasilkan id duplikat hingga hampir nol.
Tipe data
Format tempat Anda menyimpan data mungkin merupakan ancaman atau bantuan lain untuk integritas data. Bayangkan menjalankan survei dan meminta audiens Anda untuk smartphone favorit — Anda ingin mengirimkan penawaran kepada setiap pelanggan yang memilih iPhone X selama promosi.
Saat Anda membaca daftar balasan, Anda melihat catatan berikut:
- iPhone X
- iphone X
- saya Telepon10
- iPhone X
- iphone 10
- Nokia 3310
- Dan seterusnya...
Saat membuat segmen untuk pelanggan "iPhone X", sistem hanya akan menampilkan satu pelanggan, bukan lima. Solusi untuk masalah ini sangat mudah — cukup ubah jenis bidang jawaban ke daftar yang telah ditentukan, bukan teks terbuka. Tetapi jika Anda melupakannya sebelum peluncuran, Anda akan berakhir dengan banyak pekerjaan manual di piring Anda.

Kesalahan sederhana namun merepotkan seperti ini dapat dihindari dengan memahami dan memeriksa ulang model data untuk setiap langkah perjalanan pelanggan. Langkah pertama adalah mengunjungi dokumentasi tentang opsi yang ditawarkan CRM Anda untuk menyimpan dan memproses data untuk setiap entitas — ini disebut skema data.
Mari kita jelajahi bagaimana skema data terlihat dan bagaimana Anda dapat menggunakan fitur-fiturnya untuk memastikan integritas data. Tipe data pergi dulu.
Tipe data
Tipe data adalah atribut data yang memberi tahu CRM bagaimana kami dapat menggunakan data atau operasi apa yang dapat kami lakukan dengannya. Berikut daftar jenis yang dapat Anda temukan di hampir setiap alat CRM.
Primitif – tipe dasar
- Boolean – mewakili nilai benar atau salah. Misalnya, bayangkan sebuah atribut: is_first_time_customer.
- Integer – mewakili angka, positif atau negatif, yang tidak memiliki titik desimal. Misalnya, di Salesforce CRM, bilangan bulat memiliki nilai minimum -2.147.483.648 dan nilai maksimum 2.147.483.647.
- Desimal (mengambang) – angka yang menyertakan titik desimal, misalnya, 3.14159.
- Karakter – satu huruf atau karakter apa pun, termasuk angka (secara kolektif disebut alfanumerik).
- String – menyimpan string karakter alfanumerik apa pun, seperti kata, frasa, atau kalimat.
- Tanggal – nilai yang menunjukkan hari tertentu.
- Datetime – nilai yang menunjukkan hari dan waktu tertentu.
- Blob – (dari objek besar biner) kumpulan data biner yang disimpan sebagai objek tunggal. Anda dapat menganggapnya sebagai satu file (gambar, rekaman suara, film, PDF, dll.) untuk kesederhanaan.
Sebelum kita beralih ke tipe lanjutan, mari kita berhenti sejenak untuk mendapatkan beberapa intuisi tentang bagaimana memilih tipe yang tepat. Anda mungkin telah memperhatikan bahwa setiap tipe data memiliki dua karakteristik:
- nilai-nilai apa yang dapat diwakilinya,
- berapa nilai minimum dan maksimum yang dapat disimpannya.
Ada dua aturan praktis untuk keduanya:
1) Dalam hal representasi nilai – semakin banyak fleksibilitas yang Anda miliki, semakin sedikit otomatisasi data yang mungkin, atau lebih baik, semakin banyak pekerjaan dalam perangkat lunak yang diperlukan untuk memproses data. Contoh sederhana adalah kode pos di AS. Jika itu angka, kita dapat menggunakan rentang untuk menyimpulkan keadaan (misalnya, Alabama adalah 35801 hingga 35816). Itu tidak mungkin untuk string.
Contoh bagus lainnya adalah survei kami. Jika kami ingin menghitung varian iPhone X dengan versi teks terbuka, kami perlu mengubah kueri kami untuk memasukkan semua nilai. Selain itu, kami perlu mempertahankan kueri – setiap kali kami menemukan varian baru yang diketik oleh pengguna, kueri harus diperbarui.
2) Aturan kedua adalah tentang nilai minimum dan maksimum. Semakin besar ukuran yang Anda atur untuk suatu atribut, semakin fleksibel atribut tersebut. Sekarang, Anda mungkin bertanya mengapa tidak selalu menggunakan opsi terbesar? Karena ukuran yang lebih besar membutuhkan lebih banyak memori komputer yang diperlukan untuk memproses data, dan ini membutuhkan biaya lebih. Ini mungkin diabaikan ketika Anda memiliki ratusan catatan, tetapi ketika Anda tumbuh menjadi jutaan, instans CRM Anda mungkin lebih lambat untuk merespons, atau Anda akan mencapai batas dan akan dipaksa untuk meningkatkan ke paket harga yang lebih tinggi.

Komposit – hasil dari menggabungkan dua atau lebih primitif
- Array – sekelompok primitif dari berbagai ukuran. Biasanya direpresentasikan sebagai deret atau primitif dalam tanda kurung, misalnya [1, 3, 5, 13, 5].
- Set – sekelompok primitif dengan ukuran berapa pun tetapi hanya dengan nilai unik [1, 3, 5, 13].
- Enum – sebuah enum (dari enumerator) adalah tipe data dengan nilai yang masing-masing mengambil tepat satu dari satu set pengidentifikasi terbatas yang Anda tentukan (ini salah satu yang harus kami gunakan untuk survei kami untuk menghindari kekacauan!).
- Objek – Objek adalah nilai yang berisi nilai lain, biasanya dalam angka dan urutan tetap dan biasanya diindeks oleh nama. Elemen record biasanya disebut field atau member. Ingat contoh JSON dari bagian pertama, mereka adalah objek.
Kendala data
Tipe data sudah membantu kami menjaga ketertiban dalam data dan mencegah tugas pembersihan data yang membosankan, sesuatu yang dapat kami tindak dengan bantuan mesin. Tapi kita bisa melakukan lebih dari itu dengan kendala.
Batasan data menentukan properti spesifik yang harus dipatuhi oleh data. Sistem CRM yang andal memastikan bahwa kendala terus ada setiap saat — yaitu, saat Anda membuat objek baru atau memodifikasi objek yang sudah ada.
Pernahkah Anda menerima email dengan judul Dear {first.name}? Ini mungkin akibat dari melupakan batasan NOT NULL pada atribut nama depan.
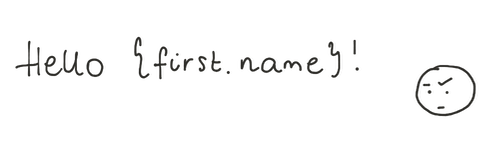
Inilah cara kerja ini dan batasan khas lainnya:
- Not null – setiap nilai tidak boleh “NULL”, yang dalam bahasa Inggris berarti tidak boleh kosong.
- Unik – nilai harus unik untuk setiap objek dalam database. Misalnya, jika Anda ingin mengidentifikasi pelanggan melalui email atau nomor telepon, Anda harus membuat bidang ini unik untuk menghindari pesan duplikat dan masalah yang lebih parah.
- Kunci utama – nilai harus unik untuk setiap objek dan tidak boleh NULL. Sebagian besar CRM menerapkan batasan ini di luar kotak.
- Kunci asing – nilai harus mereferensikan catatan yang ada di objek lain (melalui kunci utama atau batasan unik lainnya). Bayangkan Anda menemukan kartu hadiah di sistem Anda, tetapi tidak memiliki informasi pemilik. Anda ragu untuk menonaktifkannya karena mungkin salah satu pelanggan Anda mendapatkannya dan akan kecewa jika gagal di kasir. Menambahkan kunci asing antara kartu hadiah dan objek pelanggan akan memecahkan masalah ini karena sistem tidak akan membuat kartu tanpa pemilik yang ditunjuk atau menghapus pemilik dari kartu yang ada karena kesalahan.
- Periksa – ekspresi yang harus benar agar kendala terpenuhi. Ini adalah batasan umum untuk kondisi yang dapat Anda terapkan pada atribut tipe data tertentu. Contoh-contoh berikut akan membantu Anda memahami konsep:
- Email (string) harus sesuai dengan pola tertentu (baca artikel wiki untuk melihat bahwa itu lebih rumit daripada wajib @ di tengah).
- Usia (bilangan bulat) harus lebih besar dari 13.
- Tanggal lahir (tanggal) harus pada bulan Maret.
- Pembuatan pelanggan (tanggal) harus sebelum 1 Oktober 2020.
- Pesanan terakhir (DateTime) tidak boleh lebih awal dari siang kemarin.
- Nomor telepon (string) harus dimulai dengan awalan negara.
- Alamat (objek) harus terdiri dari jalan, nomor, kota, negara, kode pos — yang dapat memiliki batasan "periksa" sendiri.
Normalisasi data
Ada konsep lain yang harus Anda ketahui untuk meningkatkan pemahaman Anda tentang integritas data, bagian duplikasi data untuk lebih spesifik. Ini disebut normalisasi data .
Sebagai contoh, mari kita ambil program loyalitas. Kami perlu mengelompokkan pelanggan dalam tingkatan untuk melakukan beberapa analitik nanti. Bayangkan tabel yang menyimpan informasi tentang kapan pelanggan bergabung dengan tingkat tertentu.
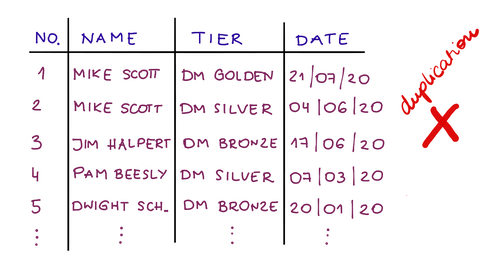
Alih-alih menyimpan nama tier, yang dapat berupa Dunder Mifflin Golden Tier untuk setiap orang, kami hanya menyimpan nomor yang merujuk ke tabel tier program.
Jadi, alih-alih memegang 20000 Dunder Mifflin Golden Tier, kami memiliki 20000 referensi seperti #3. Saat Anda ingin mengubah nama tier karena alasan tertentu, Anda hanya perlu memperbaruinya di satu tempat, dan integritas data akan tetap terjaga.
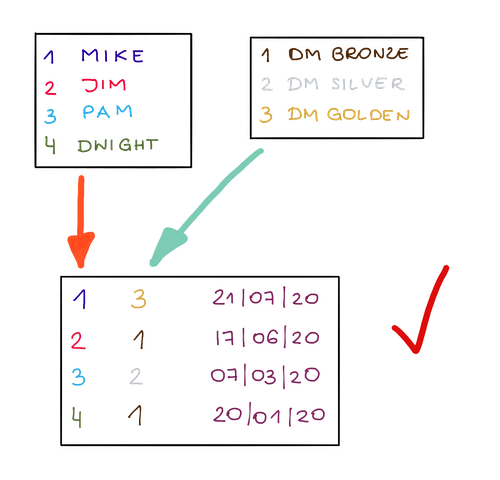
Sekarang, mari kita masuk lebih dalam ke konsep normalisasi yang lebih maju. Mari kita asumsikan Anda ingin memantau bagaimana pelanggan berpindah di berbagai tingkatan. Kita bisa menyimpannya dalam tabel berikut:
Pelanggan | Tingkat | Tanggal Masuk Tingkat
Mike Scott | Tingkat Emas DM | 21/07/2020
Mike Scott | Tingkat Perak DM | 04/06/2020
Jim Halpert | Tingkat Perunggu DM | 17/06/2020
Tetapi lebih baik membuat tiga objek terpisah untuk menyimpannya, satu tabel dengan daftar tingkatan, satu tabel dengan daftar pelanggan, dan satu lagi untuk menghubungkan keduanya. Itu memberi kami kebebasan paling banyak yang bisa kami dapatkan saat mengubah informasi pelanggan atau informasi tingkat secara terpisah, dan kami memiliki lebih sedikit data duplikat, tentu saja.
Objek CRM default biasanya mengikuti konsep normalisasi data. Namun, jika Anda ingin membuat beberapa objek kustom dengan memperluas skema siap pakai, Anda harus selalu mengingat normalisasi data.
Bawa pulang
Saat Anda menemukan diri Anda bekerja dengan CRM baru, kunjungi dokumentasi mereka untuk menjelajahi skema data. Telusuri objek default untuk melihat apa yang dapat Anda lakukan di luar kotak. Pelajari tipe data dan bagaimana Anda dapat menindaklanjutinya dengan mekanisme bawaan seperti penghitungan Hubspot, Bidang Terhitung Salesforce dengan Rumus, atau cara menyajikannya dengan bahasa template seperti Liquid.
Sebagai latihan, Anda juga dapat mengunjungi artikel Fabric tentang membangun skema data e-niaga untuk mengeksplorasi bagaimana teori integritas data dari pos ini berlaku untuk kasus penggunaan kehidupan nyata.