
Techniczne aspekty segmentacji klientów, część 2 – Integralność danych
Opublikowany: 2022-04-18Ostatni artykuł pomógł nam zrozumieć, w jaki sposób synchronizacja danych umożliwia skuteczną segmentację. Aby jednak zostać prawdziwym czarodziejem segmentacji, potrzebujesz jeszcze jednej rzeczy — zdolności do oceny i utrzymania jakości danych, zbiorczo określanej jako integralność danych . Chociaż najlepszym sposobem na poznanie tego jest praktyka, owinięcie głowy wokół krytycznych koncepcji da ci przewagę.
Integralność danych to szeroki temat. Prawdę mówiąc, jest to nadrzędny cel całego działu IT. Wszyscy są zatrudniani, aby uniknąć wyciągania wniosków na podstawie nieprawidłowych danych.
Kiedy zawęzimy go do segmentacji klientów, specjalista CRM powinien być świadomy unikalności danych, typów danych i ograniczeń danych.
Unikalność danych
Wyobraź sobie, że klient otrzymuje wiadomość dwa razy lub, co gorsza, otrzymuje wiadomość dwa razy za każdym razem z inną zniżką. Pojedyncza sprawa nie wyrządzi wiele szkód, ale jeśli liczba ta wzrośnie, kampania może zakończyć się natychmiastową porażką z długofalowymi konsekwencjami, w tym spadkiem lojalności.
Dlatego Twoja baza klientów musi dbać o unikalność danych. Aby to zrobić, musisz znaleźć identyfikator , który pozwoli rozróżnić dwóch klientów. Może to być e-mail lub numer telefonu. Chociaż są unikalne dla każdego Toma, Dicka lub Harry'ego, nie są dobrymi kandydatami na identyfikator. Przede wszystkim adresy e-mail i numery telefonów mogą ulec zmianie dla danej osoby. Po drugie, możesz mieć problemy z zapewnieniem niepowtarzalności e-maili, w tym „.” oraz „+” lub znaki inne niż angielskie.
Dlatego CRM używają unikalnego identyfikatora wewnętrznego. Jest ukuty jako uniwersalny unikalny identyfikator (UUID) lub globalnie unikalny identyfikator (GUID) .
Są to algorytmy, które pobierają unikalne atrybuty klienta (takie jak adres e-mail lub numer telefonu), szyfrują je i generują ciąg losowych znaków — unikalny dla każdego klienta . Gdy Jan zostanie Twoim klientem, CRM wygeneruje dla niego identyfikator, taki jak 8f14a65f-3032-42c8-a196-1cf66d11b930.
Tworząc tak długi identyfikator, zmniejszasz ryzyko wygenerowania duplikatu identyfikatora prawie do zera.
Typy danych
Format, w którym przechowujesz dane, może stanowić kolejne zagrożenie lub pomóc w zachowaniu integralności danych. Wyobraź sobie, że przeprowadzasz ankietę i prosisz odbiorców o ulubiony smartfon — chcesz wysłać ofertę do każdego klienta, który wybrał iPhone'a X podczas promocji.
Kiedy czytasz listę odpowiedzi, widzisz następujące wpisy:
- iPhone X
- iPhone X
- Telefon10
- iPhone X
- iPhone 10
- Nokia 3310
- I tak dalej...
Tworząc segment dla klientów „iPhone X”, system pokaże tylko jednego klienta zamiast pięciu. Rozwiązanie tego problemu jest proste — wystarczy zmienić typ pola odpowiedzi na predefiniowaną listę zamiast na otwarty tekst. Ale jeśli zapomnisz o tym przed wdrożeniem, skończysz z wieloma ręcznymi zadaniami na talerzu.

Prostych, ale kłopotliwych błędów, takich jak ten, można uniknąć, rozumiejąc i dwukrotnie sprawdzając model danych na każdym etapie podróży klienta. Pierwszym krokiem jest zapoznanie się z dokumentacją dotyczącą opcji oferowanych przez CRM do przechowywania i przetwarzania danych dla każdego podmiotu — nazywa się to schematem danych.
Przyjrzyjmy się, jak wygląda schemat danych i jak można korzystać z jego funkcji, aby zapewnić integralność danych. Typy danych idą na pierwszym miejscu.
Typy danych
Typy danych to atrybuty danych, które informują CRM, w jaki sposób możemy wykorzystać dane lub jakie operacje możemy z nimi wykonać. Oto lista typów, które można znaleźć w prawie każdym narzędziu CRM.
Prymitywy – podstawowe typy
- Boolean – reprezentuje wartości prawdziwe lub fałszywe. Na przykład wyobraź sobie atrybut: is_first_time_customer.
- Integer – reprezentuje liczbę, dodatnią lub ujemną, która nie ma kropki dziesiętnej. Na przykład w Salesforce CRM liczby całkowite mają minimalną wartość -2 147 483 648 i maksymalną 2 147 483 647.
- Decimal (float) – liczba zawierająca kropkę dziesiętną, np. 3.14159.
- Znak – pojedyncza litera lub dowolny znak, w tym cyfry (łącznie nazywane alfanumerycznymi).
- String – przechowuje ciąg dowolnych znaków alfanumerycznych, takich jak słowo, fraza lub zdanie.
- Data – wartość wskazująca konkretny dzień.
- Datetime – wartość wskazująca konkretny dzień i godzinę.
- Blob – (z dużego obiektu binarnego) zbiór danych binarnych przechowywanych jako pojedynczy obiekt. Możesz myśleć o tym jako o pojedynczym pliku (obraz, nagranie głosowe, film, plik PDF itp.) Dla uproszczenia.
Zanim przejdziemy do typów zaawansowanych, zatrzymajmy się na chwilę, aby nabrać intuicji, jak wybrać odpowiedni typ. Prawdopodobnie zauważyłeś już, że każdy typ danych ma dwie cechy:
- jakie wartości może reprezentować,
- jakie są minimalne i maksymalne wartości, które może przechowywać.
Obydwa mają dwie praktyczne zasady:
1) Jeśli chodzi o reprezentację wartości – im większa elastyczność, tym mniejsza automatyzacja danych lub lepiej, tym więcej pracy w oprogramowaniu jest konieczne do przetwarzania danych. Prostym przykładem może być kod pocztowy w USA. Jeśli jest to liczba, możemy użyć zakresów, aby wywnioskować stan (np. Alabama to od 35801 do 35816). To byłoby niemożliwe dla sznurka.
Innym dobrym przykładem może być nasza ankieta. Jeśli chcielibyśmy policzyć warianty iPhone'a X w otwartej wersji tekstowej, musielibyśmy dostosować nasze zapytanie, aby zawierało wszystkie wartości. Dodatkowo musielibyśmy utrzymywać zapytanie – za każdym razem, gdy znajdziemy nowy wariant wpisany przez użytkownika, zapytanie musi zostać zaktualizowane.
2) Druga zasada dotyczy wartości minimalnych i maksymalnych. Im większy rozmiar ustawisz dla atrybutu, tym bardziej jest on elastyczny. Teraz możesz zapytać, dlaczego nie zawsze korzystać z największej opcji? Ponieważ większy rozmiar potrzebuje więcej pamięci komputera niezbędnej do przetwarzania danych, a to kosztuje więcej. Może to być nieistotne, gdy masz setki rekordów, ale gdy osiągniesz miliony, Twoja instancja CRM może wolniej reagować lub osiągniesz limit i będziesz zmuszony przejść na wyższy plan cenowy.
Composite – wynik połączenia dwóch lub więcej prymitywów
- Array – grupa prymitywów dowolnej wielkości. Jest zwykle reprezentowany jako seria lub prymitywy w nawiasach, np. [1, 3, 5, 13, 5].
- Zbiór – grupa prymitywów o dowolnej wielkości, ale tylko o unikalnych wartościach [1, 3, 5, 13].
- Enum – wyliczenie (z enumeratora) to typ danych z wartościami, z których każda przyjmuje dokładnie jeden ze skończonego zestawu identyfikatorów, które określisz (jest to jeden, którego powinniśmy użyć w naszej ankiecie, aby uniknąć bałaganu!).
- Obiekt — obiekt to wartość zawierająca inne wartości, zwykle w stałych liczbach i sekwencjach, zazwyczaj indeksowana według nazw. Elementy rekordów są zwykle nazywane polami lub członkami. Zapamiętaj przykłady JSON z pierwszej części, są to obiekty.
Ograniczenia danych
Typy danych już pomagają nam utrzymać porządek w danych i zapobiegać żmudnym zadaniu czyszczenia danych, na czym możemy działać z pomocą maszyn. Ale z ograniczeniami możemy zrobić więcej.

Ograniczenia danych definiują określone właściwości, z którymi dane muszą być zgodne. Niezawodny system CRM zapewnia, że ograniczenia obowiązują przez cały czas — np. gdy tworzysz nowy obiekt lub modyfikujesz istniejący.
Czy kiedykolwiek otrzymałeś tytuł e-maila Dear {first.name}? Może to być wynikiem zapomnienia o ograniczeniu NOT NULL w atrybucie imienia.
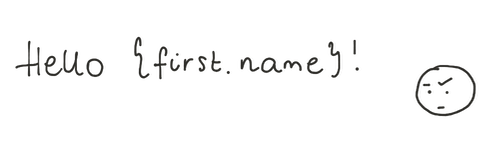
Oto jak działa to i inne typowe ograniczenia:
- Not null – każda wartość nie może być „NULL”, co w prostym języku angielskim oznacza, że nie może być pusta.
- Unique – wartości muszą być unikalne dla każdego obiektu w bazie danych. Na przykład, jeśli chcesz identyfikować klientów za pomocą adresu e-mail lub numeru telefonu, powinieneś uczynić to pole unikalnym, aby uniknąć duplikatów wiadomości i poważniejszych problemów.
- Klucz podstawowy — wartości muszą być unikalne dla każdego obiektu i nie mogą mieć wartości NULL. Większość CRM wdraża te ograniczenia od razu.
- Klucz obcy — wartości muszą odwoływać się do istniejącego rekordu w innym obiekcie (poprzez jego klucz podstawowy lub inne ograniczenie unikatowe). Wyobraź sobie, że w swoim systemie znajdujesz kartę podarunkową, ale nie zawiera ona informacji o właścicielu. Wahasz się, czy go dezaktywować, ponieważ być może jeden z Twoich klientów go otrzymał i będzie rozczarowany, jeśli nie powiedzie się przy kasie. Dodanie klucza obcego między kartą podarunkową a obiektami klienta rozwiązałoby ten problem, ponieważ system nie utworzy karty bez przypisania przez właściciela lub omyłkowego usunięcia właściciela z istniejącej karty.
- Check – wyrażenie, które musi być prawdziwe, aby ograniczenie zostało spełnione. Jest to ograniczenie zbiorcze dla warunków, które można zastosować do atrybutów określonych typów danych. Poniższe przykłady powinny pomóc w zrozumieniu tej koncepcji:
- E-mail (ciąg) powinien być zgodny z określonym wzorcem (przeczytaj artykuł wiki, aby zobaczyć, że jest bardziej skomplikowany niż obowiązkowy @ w środku).
- Wiek (liczba całkowita) powinien być większy niż 13.
- Data urodzenia (data) powinna być w marcu.
- Utworzenie klienta (data) powinno nastąpić przed 1 października 2020 r.
- Ostatnie zamówienie (DateTime) nie powinno być wcześniejsze niż wczoraj w południe.
- Numer telefonu (ciąg) powinien zaczynać się od prefiksu kraju.
- Adres (obiekt) powinien składać się z ulicy, numeru, miasta, kraju, kodu pocztowego – co może mieć swoje własne ograniczenia „sprawdzające”.
Normalizacja danych
Jest jeszcze jedna koncepcja, o której powinieneś wiedzieć, aby lepiej zrozumieć integralność danych, a dokładniej mówiąc o duplikacji danych. Nazywa się to normalizacją danych .
Jako przykład weźmy program lojalnościowy. Musimy pogrupować klientów w warstwy, aby później przeprowadzić niektóre analizy. Wyobraź sobie tabelę przechowującą informacje o tym, kiedy klient dołączył do określonej warstwy.
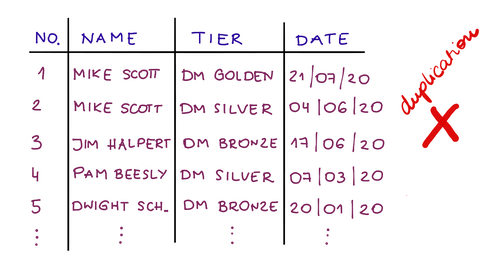
Zamiast przechowywać nazwę poziomu, która może być tak długa, jak złoty poziom Dunder Mifflin dla każdej osoby, po prostu przechowujemy numer, który odnosi się do tabeli poziomów programu.
Więc zamiast mieć 20000 Dunder Mifflin Golden Tier, mamy 20000 referencji, takich jak #3. Jeśli z jakiegoś powodu chcesz zmienić nazwę warstwy, musisz ją zaktualizować tylko w jednym miejscu, a integralność danych zostanie zachowana.
Przejdźmy teraz do bardziej zaawansowanej koncepcji normalizacji. Załóżmy, że chcesz monitorować, jak klient przechodził przez różne poziomy. Moglibyśmy to zapisać w poniższej tabeli:
Klient | Poziom | Data wprowadzenia poziomu
Mike Scott | DM Złoty Poziom | 21.07.2020
Mike Scott | Poziom srebrny DM | 06.04.2020
Jim Halpert | Brązowy poziom DM | 17.06.2012
Ale lepiej jest utworzyć trzy oddzielne obiekty do przechowywania tego, jedną tabelę z listą poziomów, jedną tabelę z listą klientów i drugą, aby połączyć je obie. Daje nam to największą swobodę, jaką możemy uzyskać, zmieniając oddzielnie informacje o kliencie lub informacje o poziomie, i oczywiście mamy mniej zduplikowanych danych .
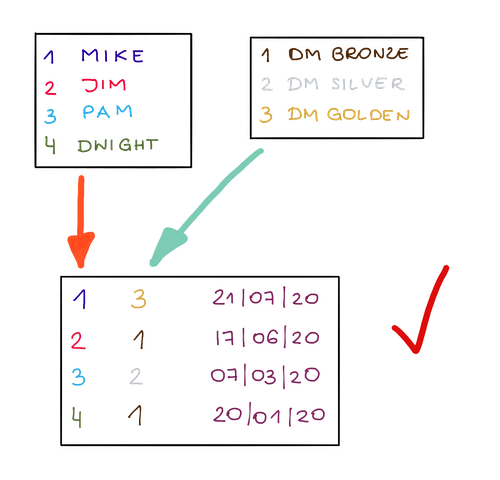
Domyślne obiekty CRM zwykle są zgodne z koncepcjami normalizacji danych. Jeśli jednak chcesz tworzyć niestandardowe obiekty, rozszerzając gotowy schemat, zawsze powinieneś mieć na uwadze normalizację danych.
Na wynos
Gdy zaczniesz pracować z nowym CRM, zapoznaj się z ich dokumentacją, aby zapoznać się ze schematem danych. Przejrzyj domyślne obiekty, aby zobaczyć, co możesz zrobić po wyjęciu z pudełka. Dowiedz się o typach danych i o tym, jak możesz na nich działać dzięki wbudowanym mechanizmom, takim jak obliczenia Hubspot, pola obliczeniowe Salesforce z formułami lub jak prezentować je za pomocą języków szablonów, takich jak Liquid.
W ramach ćwiczenia możesz również zapoznać się z artykułem Fabric na temat budowania schematu danych e-commerce, aby dowiedzieć się, jak teoria integralności danych z tego postu ma zastosowanie do rzeczywistego przypadku użycia.