
고객 세분화의 기술적 측면 2부 – 데이터 무결성
게시 됨: 2022-04-18마지막 기사는 데이터 동기화가 효과적인 분할을 가능하게 하는 방법을 이해하는 데 도움이 되었습니다. 그러나 실제 세분화 마법사가 되려면 데이터 무결성 으로 집합적으로 정의되는 데이터 품질을 평가하고 유지 관리하는 기능이 한 가지 더 필요합니다. 이에 대해 배우는 가장 좋은 방법은 연습을 통해 배우는 것이지만, 중요한 개념을 중심으로 머리를 감싸면 시작하는 데 도움이 됩니다.
데이터 무결성은 광범위한 주제입니다. 사실 IT 부서 전체의 가장 중요한 목표입니다. 그들은 모두 잘못된 데이터를 기반으로 인사이트를 도출하는 것을 피하기 위해 고용되었습니다.
고객 세분화로 좁힐 때 CRM 전문가는 데이터 고유성, 데이터 유형 및 데이터 제약 조건을 알고 있어야 합니다.
데이터 고유성
고객이 메시지를 두 번 받거나 더 심하게는 매번 다른 할인으로 메시지를 두 번 받는 경우를 상상해 보십시오. 단일 사례는 큰 피해를 입히지 않지만 이 숫자가 커지면 캠페인은 충성도 저하를 비롯한 장기적인 결과를 초래하는 즉각적인 실패가 될 수 있습니다.
이것이 고객 데이터베이스가 데이터 고유성을 처리해야 하는 이유입니다. 그렇게 하려면 두 고객을 구별할 수 있는 식별자 를 찾아야 합니다. 이메일이나 전화번호일 수 있습니다. 모든 Tom, Dick 또는 Harry에 대해 고유하지만 식별자에 대한 좋은 후보는 아닙니다. 우선 이메일 주소와 전화번호는 사람마다 바뀔 수 있습니다. 둘째, "."를 포함하여 이메일의 고유성을 보장하는 데 문제가 있을 수 있습니다. 및 "+" 또는 영어가 아닌 문자.
이것이 CRM이 고유한 내부 식별자를 사용하는 이유입니다. UUID(Universally Unique Identifier) 또는 GUID(Globally Unique Identifier) 로 만들어졌습니다.
이는 고객의 고유한 속성(예: 이메일 또는 전화번호)을 가져와 암호화하고 모든 고객에게 고유한 임의의 문자열을 생성하는 알고리즘입니다. John이 고객이 되면 CRM은 8f14a65f-3032-42c8-a196-1cf66d11b930과 같은 식별자를 생성합니다.
이러한 긴 식별자를 생성하면 중복 ID를 생성할 위험을 거의 0으로 줄일 수 있습니다.
데이터 유형
데이터를 저장하는 형식은 데이터 무결성에 또 다른 위협이 되거나 도움이 될 수 있습니다. 설문조사를 진행하고 청중에게 가장 좋아하는 스마트폰을 요청한다고 상상해 보세요. 프로모션 기간 동안 iPhone X를 선택한 모든 고객에게 제안을 보내려고 합니다.
회신 목록을 읽으면 다음 레코드가 표시됩니다.
- 아이폰X
- 아이폰 X
- 나는 전화10
- 아이폰X
- 아이폰 10
- 노키아 3310
- 등등...
"iPhone X" 고객을 위한 세그먼트를 생성할 때 시스템은 5명이 아닌 1명의 고객만 표시합니다. 이 문제에 대한 솔루션은 간단합니다. 답변 필드 유형을 열린 텍스트 대신 미리 정의된 목록으로 변경하기만 하면 됩니다. 그러나 출시 전에 잊어버리면 결국에는 수많은 수동 작업이 발생하게 됩니다.

이와 같은 단순하지만 골치 아픈 실수는 모든 고객 여정 단계에 대한 데이터 모델을 이해하고 다시 확인하면 피할 수 있습니다. 첫 번째 단계는 CRM에서 모든 엔터티에 대한 데이터를 저장하고 처리하기 위해 제공하는 옵션에 대한 설명서를 방문하는 것입니다. 이를 데이터 스키마라고 합니다.
데이터 스키마의 모양과 해당 기능을 사용하여 데이터 무결성을 보장하는 방법을 살펴보겠습니다. 데이터 유형이 먼저 표시됩니다.
데이터 유형
데이터 유형은 CRM에 데이터를 사용하는 방법이나 데이터로 수행할 수 있는 작업을 알려주는 데이터의 속성입니다. 다음은 거의 모든 CRM 도구에서 찾을 수 있는 유형 목록입니다.
Primitives – 기본 유형
- 부울 – true 또는 false 값을 나타냅니다. 예를 들어 is_first_time_customer 속성을 상상해 보십시오.
- 정수 – 소수점이 없는 양수 또는 음수를 나타냅니다. 예를 들어 Salesforce CRM에서 정수의 최소값은 -2,147,483,648이고 최대값은 2,147,483,647입니다.
- Decimal(float) – 소수점이 포함된 숫자(예: 3.14159).
- 문자 – 단일 문자 또는 숫자를 포함한 모든 문자(총괄적으로 영숫자라고 함).
- 문자열 – 단어, 구 또는 문장과 같은 영숫자 문자열을 저장합니다.
- 날짜 – 특정 날짜를 나타내는 값입니다.
- 날짜/시간 – 특정 날짜와 시간을 나타내는 값입니다.
- Blob – (이진 대형 개체에서) 단일 개체로 저장된 이진 데이터 모음입니다. 단순함을 위해 하나의 파일(이미지, 음성 녹음, 동영상, PDF 등)으로 생각할 수 있습니다.
고급 유형으로 이동하기 전에 올바른 유형을 선택하는 방법에 대한 직관을 얻기 위해 잠시 멈추겠습니다. 각 데이터 유형에는 두 가지 특성이 있다는 것을 이미 눈치채셨을 것입니다.
- 어떤 종류의 가치를 나타낼 수 있는지,
- 저장할 수 있는 최소값과 최대값은 얼마입니까?
둘 다에 대한 두 가지 경험 법칙이 있습니다.
1) 가치 표현과 관련하여 - 유연성이 높을수록 데이터 자동화가 덜 가능하거나 더 좋을수록 데이터를 처리하는 데 더 많은 소프트웨어 작업이 필요합니다. 간단한 예는 미국의 우편번호입니다. 숫자인 경우 범위를 사용하여 상태를 추론할 수 있습니다(예: Alabama는 35801에서 35816까지). 그것은 문자열에 대해 불가능합니다.
또 다른 좋은 예는 설문조사입니다. 열린 텍스트 버전으로 iPhone X 변형을 계산하려면 모든 값을 포함하도록 쿼리를 조정해야 합니다. 또한 쿼리를 유지 관리해야 합니다. 사용자가 입력한 새 변형을 찾을 때마다 쿼리를 업데이트해야 합니다.
2) 두 번째 규칙은 최소값과 최대값에 관한 것입니다. 속성에 대해 설정한 크기가 클수록 더 유연합니다. 이제 왜 항상 가장 큰 옵션을 사용하지 않는지 물어볼 수 있습니다. 크기가 클수록 데이터를 처리하는 데 더 많은 컴퓨터 메모리가 필요하고 비용이 더 많이 들기 때문입니다. 수백 개의 레코드가 있는 경우 무시할 수 있지만 수백만 개의 레코드로 증가하면 CRM 인스턴스의 응답 속도가 느려지거나 제한에 도달하여 더 높은 요금제로 업그레이드해야 합니다.
합성 – 둘 이상의 프리미티브를 결합한 결과
- 배열 – 모든 크기의 기본 요소 그룹입니다. 일반적으로 [1, 3, 5, 13, 5]와 같이 대괄호로 묶인 시리즈 또는 기본 형식으로 표시됩니다.
- 세트 – 모든 크기의 프리미티브 그룹이지만 고유한 값[1, 3, 5, 13]만 있습니다.
- 열거형 – 열거형(열거자에서)은 사용자가 지정하는 유한한 식별자 집합 중 정확히 하나를 취하는 값을 가진 데이터 유형입니다(이것은 혼란을 피하기 위해 설문조사에 사용해야 하는 것입니다!).
- 개체 – 개체는 일반적으로 고정된 숫자와 시퀀스로 되어 있고 일반적으로 이름으로 인덱싱된 다른 값을 포함하는 값입니다. 레코드의 요소는 일반적으로 필드 또는 멤버라고 합니다. 첫 번째 부분의 JSON 예제를 기억하십시오. 그것들은 객체입니다.
데이터 제약
데이터 유형은 이미 데이터의 순서를 유지하고 지루한 데이터 정리 작업을 방지하는 데 도움이 됩니다. 이러한 작업은 기계의 도움으로 처리할 수 있습니다. 그러나 우리는 제약 조건으로 그 이상을 할 수 있습니다.

데이터 제약 조건은 데이터가 준수해야 하는 특정 속성을 정의합니다. 신뢰할 수 있는 CRM 시스템은 제약 조건이 항상 유지되도록 합니다. 즉, 새 개체를 만들 거나 기존 개체를 수정할 때입니다.
Dear {first.name}이라는 제목의 이메일을 받은 적이 있습니까? 이것은 이름 속성에 대한 NOT NULL 제약 조건을 잊어버린 결과일 수 있습니다.
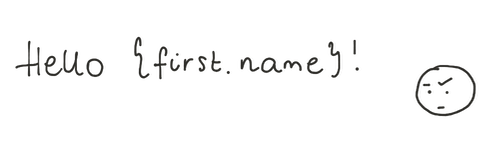
이 제약 조건과 기타 일반적인 제약 조건이 작동하는 방식은 다음과 같습니다.
- Not null – 각 값은 "NULL"이 아니어야 합니다. 이는 일반 영어로 비어 있을 수 없음을 의미합니다.
- 고유 – 값은 데이터베이스의 각 개체에 대해 고유해야 합니다. 예를 들어 이메일이나 전화 번호로 고객을 식별하려면 이 필드를 고유하게 지정하여 중복 메시지와 더 심각한 문제를 방지해야 합니다.
- 기본 키 – 값은 각 개체에 대해 고유해야 하며 NULL이 아니어야 합니다. 대부분의 CRM은 이러한 제약 조건을 즉시 구현합니다.
- 외래 키 – 값은 기본 키 또는 기타 고유 제약 조건을 통해 다른 개체의 기존 레코드를 참조해야 합니다. 시스템에서 기프트 카드를 찾았지만 소유자 정보가 없다고 상상해 보십시오. 아마도 당신의 고객 중 한 명이 그것을 받았고 체크아웃에서 실패하면 실망할 것이기 때문에 비활성화하는 것을 주저합니다. 기프트 카드와 고객 개체 사이에 외래 키를 추가하면 이 문제를 해결할 수 있습니다. 시스템은 소유자가 지정되지 않은 카드를 생성하지 않거나 실수로 기존 카드에서 소유자를 제거하지 않기 때문입니다.
- 확인 – 제약 조건이 충족되려면 true여야 하는 표현식입니다. 이것은 특정 데이터 유형의 속성에 적용할 수 있는 조건에 대한 포괄적인 제약 조건입니다. 다음 예는 개념을 이해하는 데 도움이 될 것입니다.
- 이메일(문자열)은 특정 패턴을 따라야 합니다(중간에 필수 @보다 더 복잡함을 보려면 Wiki 기사를 읽으십시오).
- 나이(정수)는 13보다 커야 합니다.
- 생년월일(날짜)은 3월이어야 합니다.
- 고객 생성(날짜)은 2020년 10월 1일 이전이어야 합니다.
- 마지막 주문(DateTime)은 어제 정오 이전이 아니어야 합니다.
- 전화번호(문자열)는 국가 접두사로 시작해야 합니다.
- 주소(객체)는 거리, 번호, 도시, 국가, 우편 번호로 구성되어야 합니다.
데이터 정규화
데이터 무결성에 대한 이해를 향상시키기 위해 알아야 할 또 다른 개념이 있습니다. 데이터 복제 부분은 좀 더 구체적입니다. 데이터 정규화 라고 합니다.
예를 들어 로열티 프로그램을 살펴보겠습니다. 나중에 일부 분석을 수행하려면 고객을 계층으로 그룹화해야 합니다. 고객이 특정 계층에 합류한 시점에 대한 정보를 보관하는 테이블을 상상해 보십시오.
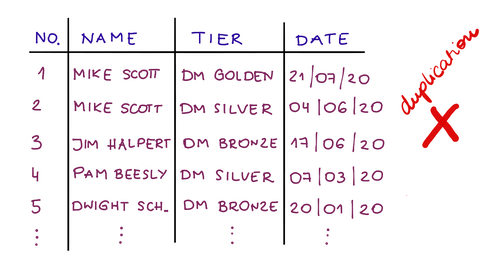
모든 사람에 대해 Dunder Mifflin Golden Tier만큼 길 수 있는 계층 이름을 저장하는 대신 프로그램 계층 테이블을 참조하는 숫자를 보유하기만 하면 됩니다.
따라서 20000 Dunder Mifflin Golden Tier를 보유하는 대신 #3과 같은 20000 참조가 있습니다. 어떤 이유로 계층 이름을 변경하려는 경우 한 곳에서만 업데이트하면 데이터 무결성이 유지됩니다.
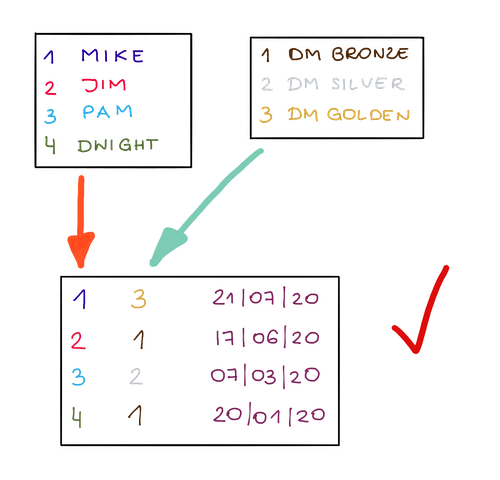
이제 좀 더 고급 정규화 개념에 대해 자세히 살펴보겠습니다. 고객이 여러 계층에서 어떻게 이동했는지 모니터링하려고 한다고 가정해 보겠습니다. 다음 테이블에 저장할 수 있습니다.
고객 | 계층 | 계층 입력 날짜
마이크 스콧 | DM 골든 티어 | 2020년 7월 21일
마이크 스콧 | DM 실버 등급 | 2020년 4월 6일
짐 할퍼트 | DM 브론즈 티어 | 2020년 6월 17일
그러나 이것을 저장하기 위해 세 개의 개별 개체를 만드는 것이 좋습니다. 하나는 계층 목록이 있는 테이블, 하나는 고객 목록이 포함된 테이블, 그리고 다른 하나는 이 둘을 모두 연결하는 것입니다. 이를 통해 고객 정보 또는 계층 정보를 개별적으로 변경할 때 얻을 수 있는 최대한의 자유를 얻을 수 있으며 물론 중복 데이터도 적습니다 .
기본 CRM 개체는 일반적으로 데이터 정규화 개념을 따릅니다. 그러나 기본 스키마를 확장하여 일부 사용자 정의 개체를 생성하려면 항상 데이터 정규화를 염두에 두어야 합니다.
테이크아웃
새로운 CRM으로 작업하고 있는 자신을 발견하면 해당 설명서를 방문하여 데이터 스키마를 살펴보십시오. 기본 개체를 살펴보고 즉시 수행할 수 있는 작업을 확인합니다. 데이터 유형과 Hubspot 계산, Salesforce 계산 필드(공식 포함) 또는 Liquid와 같은 템플릿 언어로 데이터를 표시하는 방법과 같은 기본 제공 메커니즘을 사용하여 데이터 유형에 대해 조치를 취하는 방법에 대해 알아보십시오.
연습으로 전자 상거래 데이터 스키마 구축에 대한 Fabric의 기사를 방문하여 이 게시물의 데이터 무결성 이론이 실제 사용 사례에 어떻게 적용되는지 살펴볼 수도 있습니다.