
顧客セグメンテーションの技術的側面パート2–データの整合性
公開: 2022-04-18前回の記事は、データ同期によって効果的なセグメンテーションがどのように可能になるかを理解するのに役立ちました。 しかし、実際のセグメンテーションウィザードになるには、もう1つ必要なことがあります。それは、データの品質を評価および維持する機能であり、まとめてデータの整合性として定義されます。 これについて学ぶための最良の方法は練習を通してですが、重要な概念に頭を包むことはあなたに有利なスタートを与えるでしょう。
データの整合性は幅広いトピックです。 正直なところ、それはIT部門全体の最重要目標です。 それらはすべて、誤ったデータに基づいて洞察を引き出すことを避けるために採用されています。
顧客のセグメンテーションに絞り込む場合、CRMスペシャリストは、データの一意性、データタイプ、およびデータの制約に注意する必要があります。
データの一意性
顧客がメッセージを2回受信するか、さらに悪いことに、毎回異なる割引でメッセージを2回受信することを想像してみてください。 1つのケースで大きな害はありませんが、この数が増えると、キャンペーンは即座に失敗し、ロイヤルティの低下などの長期的な結果を招く可能性があります。
これが、顧客データベースがデータの一意性を処理する必要がある理由です。 そのためには、2人の顧客を区別できる識別子を見つける必要があります。 メールや電話番号の可能性があります。 それらはすべてのトム、ディック、またはハリーに固有ですが、識別子の候補としては適していません。 まず第一に、電子メールアドレスと電話番号は人のために変わるかもしれません。 次に、「。」などのメールの一意性を確保する際に問題が発生する可能性があります。 および「+」または英語以外の文字。
これが、CRMが一意の内部識別子を使用する理由です。 これは、ユニバーサル一意識別子(UUID)またはグローバル一意識別子(GUID)として造られています。
これらは、顧客の固有の属性(電子メールや電話番号など)を取得して暗号化し、すべての顧客に固有のランダムな文字列を生成するアルゴリズムです。 Johnが顧客になると、CRMは8f14a65f-3032-42c8-a196-1cf66d11b930のような彼の識別子を生成します。
このような長い識別子を作成することで、重複するIDがほぼゼロになるリスクを減らすことができます。
データ型
データを保存する形式は、別の脅威であるか、データの整合性に役立つ可能性があります。 調査を実行して、お気に入りのスマートフォンを視聴者に尋ねるとします。プロモーション中にiPhoneXを選択したすべての顧客にオファーを送信したいとします。
返信のリストを読むと、次のレコードが表示されます。
- iPhone X
- iphone X
- i Phone10
- iPhone X
- iphone 10
- ノキア3310
- 等々...
「iPhoneX」の顧客のセグメントを作成する場合、システムには5人ではなく1人の顧客のみが表示されます。 この問題の解決策は簡単です。回答フィールドの種類を、オープンテキストではなく事前定義されたリストに変更するだけです。 しかし、ロールアウトする前にそれを忘れると、あなたはあなたのプレートにたくさんの手動の仕事をすることになります。

このような単純でありながら厄介な間違いは、カスタマージャーニーのすべてのステップのデータモデルを理解して再確認することで回避できます。 最初のステップは、CRMがすべてのエンティティのデータを保存および処理するために提供するオプションに関するドキュメントにアクセスすることです。これはデータスキーマと呼ばれます。
データスキーマがどのように見えるか、およびその機能を使用してデータの整合性を確保する方法を調べてみましょう。 データ型が最初になります。
データ型
データ型はデータの属性であり、CRMにデータの使用方法やデータを使用して実行できる操作を指示します。 これは、ほとんどすべてのCRMツールで見つけることができるタイプのリストです。
プリミティブ–基本タイプ
- ブール値–値trueまたはfalseを表します。 たとえば、属性is_first_time_customerを想像してみてください。
- 整数–小数点のない正または負の数値を表します。 たとえば、Salesforce CRMでは、整数の最小値は-2,147,483,648、最大値は2,147,483,647です。
- Decimal(float)–小数点を含む数値(例:3.14159)。
- 文字– 1文字または数字を含む任意の文字(総称して英数字)。
- 文字列–単語、フレーズ、文などの英数字の文字列を格納します。
- 日付–特定の日を示す値。
- 日時–特定の日時を示す値。
- Blob –(バイナリラージオブジェクトから)単一のオブジェクトとして保存されたバイナリデータのコレクション。 簡単にするために、単一のファイル(画像、音声録音、映画、PDFなど)と考えることができます。
高度なタイプに移る前に、少し一時停止して、適切なタイプを選択する方法について直感的に理解しましょう。 各データ型には2つの特性があることにすでに気付いているでしょう。
- それがどのような価値を表すことができるか、
- 保存できる最小値と最大値は何ですか。
それらの両方に2つの親指のルールがあります:
1)値の表現に関しては、柔軟性が高いほど、データの自動化が少なくなるか、データを処理するために必要なソフトウェアの作業が増えます。 簡単な例は、米国の郵便番号です。 数値の場合は、範囲を使用して状態を推測できます(たとえば、アラバマは35801から35816です)。 それは弦にとっては不可能でしょう。
もう1つの良い例は、私たちの調査です。 オープンテキストバージョンでiPhoneXのバリエーションをカウントしたい場合は、クエリを微調整してすべての値を含める必要があります。 さらに、クエリを維持する必要があります。ユーザーが入力した新しいバリアントを見つけるたびに、クエリを更新する必要があります。
2)2番目のルールは、最小値と最大値に関するものです。 属性に設定するサイズが大きいほど、柔軟性が高くなります。 さて、あなたはなぜ常に最大のオプションを使用しないのかと疑問に思うかもしれません。 サイズが大きいほど、データを処理するために必要なコンピュータメモリが多くなり、コストが高くなるためです。 数百のレコードがある場合は無視できるかもしれませんが、数百万に達すると、CRMインスタンスの応答が遅くなるか、制限に達してより高い料金プランにアップグレードする必要があります。
コンポジット–2つ以上のプリミティブを組み合わせた結果
- 配列–任意のサイズのプリミティブのグループ。 これは通常、括弧内の一連のプリミティブまたはプリミティブとして表されます(例:[1、3、5、13、5])。
- セット–任意のサイズのプリミティブのグループですが、一意の値は[1、3、5、13]のみです。
- 列挙型–(列挙型からの)列挙型は、指定した有限の識別子のセットの1つをそれぞれが取る値を持つデータ型です(混乱を避けるために調査に使用する必要があります!)。
- オブジェクト–オブジェクトは、他の値を含む値であり、通常は固定の番号と順序で、通常は名前でインデックスが付けられます。 レコードの要素は通常、フィールドまたはメンバーと呼ばれます。 最初の部分のJSONの例を思い出してください。これらはオブジェクトです。
データの制約
データ型は、データの順序を維持し、面倒なデータクリーンアップタスクを防ぐのにすでに役立ちます。これは、マシンの助けを借りて実行できます。 しかし、制約を使用してそれ以上のことを行うことができます。

データ制約は、データが準拠しなければならない特定のプロパティを定義します。 信頼性の高いCRMシステムにより、制約が常に保持されます。つまり、新しいオブジェクトを作成したり、既存のオブジェクトを変更したりする場合です。
親愛なる{first.name}というタイトルのメールを受け取ったことはありますか? これは、名属性のNOTNULL制約を忘れた結果である可能性があります。
これと他の典型的な制約がどのように機能するかを次に示します。
- nullではない–各値は「NULL」であってはなりません。これは、平易な英語では空にできないことを意味します。
- 一意–値はデータベース内のオブジェクトごとに一意である必要があります。 たとえば、電子メールまたは電話番号で顧客を識別したい場合は、メッセージの重複やより深刻な問題を回避するために、このフィールドを一意にする必要があります。
- 主キー–値はオブジェクトごとに一意である必要があり、NULLであってはなりません。 ほとんどのCRMは、これらの制約をすぐに実装します。
- 外部キー–値は、別のオブジェクトの既存のレコードを参照する必要があります(主キーまたはその他の一意の制約を介して)。 システムでギフトカードを見つけたが、所有者情報がない場合を想像してみてください。 おそらくあなたの顧客の1人がそれを手に入れ、チェックアウトで失敗すると失望するので、あなたはそれを非アクティブ化することを躊躇します。 ギフトカードと顧客オブジェクトの間に外部キーを追加すると、所有者が割り当てられたり、誤って既存のカードから所有者を削除したりしないとシステムがカードを作成しないため、この問題は解決します。
- チェック–制約が満たされるために真でなければならない式。 これは、特定のデータ型の属性に適用できる条件の包括的な制約です。 次の例は、概念を理解するのに役立ちます。
- 電子メール(文字列)は特定のパターンに準拠している必要があります(wikiの記事を読んで、中央の必須の@よりも複雑であることを確認してください)。
- 年齢(整数)は13より大きくする必要があります。
- 生年月日(日付)は3月である必要があります。
- 顧客の作成(日付)は、2020年10月1日より前である必要があります。
- 最後の注文(DateTime)は、昨日の正午より前であってはなりません。
- 電話番号(文字列)は国のプレフィックスで始まる必要があります。
- 住所(オブジェクト)は、番地、番号、都市、国、郵便番号で構成する必要があります。これには、独自の「チェック」制約を設定できます。
データの正規化
データの整合性についての理解を深めるために知っておくべきもう1つの概念があります。これは、データ重複の部分をより具体的にするためです。 これはデータの正規化と呼ばれます。
例として、ロイヤルティプログラムを見てみましょう。 後で分析を実行するには、顧客を階層にグループ化する必要があります。 顧客が特定の層にいつ参加したかに関する情報を保持するテーブルを想像してください。
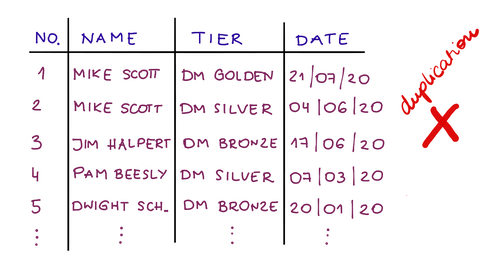
すべての人のDunderMifflinゴールデンティアと同じ長さのティアの名前を保存する代わりに、プログラムティアのテーブルを参照する番号を保持するだけです。
したがって、20000 Dunder Mifflin Golden Tierを保持する代わりに、#3のような20000参照があります。 何らかの理由で階層名を変更したい場合は、一箇所で更新するだけでデータの整合性が保たれます。
それでは、より高度な正規化の概念について詳しく見ていきましょう。 顧客がさまざまな層をどのように移動したかを監視したいとします。 次の表に保存できます。
顧客| ティア| ティア入力日
マイク・スコット| DMゴールデンティア| 2020年7月21日
マイク・スコット| DMシルバーティア| 2020年4月6日
ジム・ハルパート| DMブロンズティア| 2020年6月17日
ただし、これを格納するために3つの個別のオブジェクトを作成することをお勧めします。1つは層のリストを含むテーブル、1つは顧客のリストを含むテーブル、もう1つは両方を接続するためのテーブルです。 これにより、顧客の情報や階層情報を個別に変更するときに得られる最大の自由度が得られます。もちろん、重複データは少なくなります。
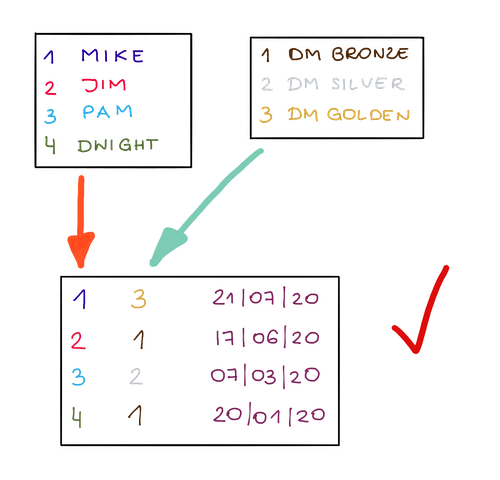
デフォルトのCRMオブジェクトは通常、データ正規化の概念に従います。 それでも、すぐに使用できるスキーマを拡張してカスタムオブジェクトを作成する場合は、常にデータの正規化を念頭に置いておく必要があります。
要点
新しいCRMを使用していることに気付いたら、そのドキュメントにアクセスしてデータスキーマを調べてください。 デフォルトのオブジェクトを調べて、箱から出して何ができるかを確認します。 データ型と、Hubspot計算、Salesforce計算フィールドと数式などの組み込みメカニズムを使用してデータ型を操作する方法、またはデータ型をLiquidなどのテンプレート言語で表示する方法を学びます。
演習として、eコマースデータスキーマの構築に関するFabricの記事にアクセスして、この投稿のデータ整合性理論が実際のユースケースにどのように適用されるかを調べることもできます。