
การใช้ Regex (นิพจน์ทั่วไป) ในการตลาดดิจิทัล
เผยแพร่แล้ว: 2021-11-30นิพจน์ทั่วไปคืออะไร:
Regular Expression หรือ Regex สั้นๆ คือสตริงข้อความที่ช่วยให้เราสามารถจัดการ จับคู่ กรอง และแยกข้อความได้
Regex มีประโยชน์อย่างยิ่งในการตลาดดิจิทัล ซึ่งมักจะจำเป็นต้องดึงข้อมูลที่เป็นประโยชน์เฉพาะออกจากชุดข้อมูลขนาดใหญ่
การดึงข้อมูลที่เป็นประโยชน์นี้อาจเป็นงานที่ยุ่งยากเมื่อดำเนินการเสร็จสิ้นด้วยตนเอง ซึ่งมักต้องใช้เวลามาก ด้วย Regex เราสามารถใช้สูตรเพื่อทำให้งานเหล่านี้ง่ายขึ้นและเร็วขึ้น
แม้ว่า Regex อาจดูน่ากลัวหรือน่ากลัวในตอนแรก บล็อกนี้ควรแสดงให้เห็นว่า Regex เรียบง่ายเพียงใด และช่วยสนับสนุนให้นักการตลาดรายอื่นเริ่มต้นในการกำจัดและทำให้ส่วนที่น่าเบื่อและใช้เวลานานที่สุดในการวิเคราะห์ข้อมูลเป็นแบบอัตโนมัติ
โทเค็นทั่วไป:
Regular Expression ประกอบด้วยโทเค็น โทเค็นแต่ละรายการจะจับคู่อักขระตัวเดียวหรือชุดอักขระภายในชุดข้อมูลของคุณ หรือกำหนดตำแหน่งที่อักขระต้องอยู่ เราสามารถดูตัวอย่างบางส่วนของโทเค็นที่ใช้บ่อยที่สุดในตารางด้านล่าง
| โทเค็น | การทำงาน |
| | | ทางเลือกอย่างใดอย่างหนึ่ง / หรือ “A|B” ตรงกับทั้ง “A” และ “B” |
| . | จับคู่กับอักขระตัวเดียวที่ไม่ใช่บรรทัดใหม่ |
| * | ตรงกับศูนย์หรือมากกว่า ดังนั้น “.*” จึงจับคู่กับศูนย์หรือมากกว่าของอักขระใดๆ ที่ไม่ใช่บรรทัดใหม่ |
| + | ตรงกับหนึ่งหรือมากกว่า ดังนั้น “.+” จะจับคู่กับอักขระหนึ่งตัวขึ้นไปที่ไม่ใช่บรรทัดใหม่ |
| ? | จับคู่ศูนย์หรือหนึ่งครั้ง ดังนั้น ".?" ตรงกันถ้ามีศูนย์หรืออักขระตัวใดตัวหนึ่งที่ไม่ใช่บรรทัดใหม่ |
| \ | จับคู่อักขระต่อไปนี้ตามตัวอักษร ดังนั้น "\." ตรงกับเฉพาะ “.” และไม่มีตัวละครอื่นๆ |
| (…) | วงเล็บเหลี่ยมหมายถึงกลุ่มการจับภาพ ทุกอย่างในวงเล็บเหลี่ยมจะถูกจับ |
| (?:…) | วงเล็บเหลี่ยมตามด้วย “?:” หมายถึงกลุ่มที่ไม่ถูกดักจับ ซึ่งคล้ายกับแคปเจอร์กรุ๊ปแต่เนื้อหาจะไม่ถูกเก็บไว้ |
| {…} | วงเล็บปีกกากำหนดจำนวนอินสแตนซ์ของโทเค็นก่อนหน้าที่คุณต้องการจับคู่ ตัวอย่างเช่น “(a{1,3})” จะจับคู่ระหว่าง 1 ถึง 3 ตัวของตัวอักษร “a” |
| […] | วงเล็บเหลี่ยมช่วยให้เราสามารถกำหนดช่วงหรืออักขระหรือโทเค็นต่างๆ ที่จะจับคู่ได้ ตัวอย่างเช่น “[Az]” จะจับคู่อักษรตัวพิมพ์ใหญ่หรือตัวพิมพ์เล็ก |
| ^ | “^” ตรงกับจุดเริ่มต้นของสตริง หรือเมื่อใช้ในวงเล็บเหลี่ยมหมายความว่าอักขระไม่อยู่ในช่วง ตัวอย่างเช่น [^Az] จะไม่จับคู่กับตัวพิมพ์เล็กหรือตัวพิมพ์ใหญ่ |
| $ | “$” ตรงกับจุดสิ้นสุดของสตริง ตัวอย่างเช่น “[Az]$” จะจับคู่กับอักษรตัวพิมพ์ใหญ่หรือตัวพิมพ์เล็กเมื่อพบที่ส่วนท้ายของสตริง |
| \s | “\s” จะจับคู่กับอักขระช่องว่างใดๆ |
| \S | “\S” จะจับคู่กับอักขระที่ไม่ใช่ช่องว่าง |
| \d | “\d” ตรงกับอักขระหลักใดๆ |
| \D | “\D” จะจับคู่กับอักขระที่ไม่ใช่ตัวเลขใดๆ |
| \w | “\w” จะจับคู่กับตัวอักษร ตัวเลข หรือขีดล่าง |
| \W | “\W” จะจับคู่กับสิ่งอื่นที่ไม่ใช่ตัวอักษร ตัวเลข หรือขีดล่าง |
ตัวอย่างแอปพลิเคชันที่เป็นประโยชน์สำหรับ Regex ในการตลาดดิจิทัล:
กรีดร้องกบ
ใน Screaming Frog เราสามารถทำการสกัดแบบกำหนดเองโดยใช้ Regex การดึงข้อมูลแบบกำหนดเองช่วยให้เราสามารถดึงข้อมูลที่เป็นประโยชน์มากมายจากเว็บไซต์
ตัวอย่างข้อมูลที่เราสามารถดึงออกมาได้ ได้แก่ ที่อยู่อีเมล รหัสติดตาม มาร์กอัปสคีมา ชื่อหน้า URL และอื่นๆ อีกมากมาย หากคุณคิดได้ คุณสามารถใช้ Regex เพื่อค้นหามันได้!
ในภาพด้านล่าง เราจะเห็นตัวอย่างของ Regex ที่ใช้ค้นหาที่อยู่อีเมล สิ่งนี้มีประโยชน์ เนื่องจากการมีที่อยู่อีเมลในรูปแบบข้อความธรรมดาบนเว็บไซต์ของคุณอาจเป็นช่องโหว่ด้านความปลอดภัยและส่งผลให้ที่อยู่อีเมลถูกคัดลอก
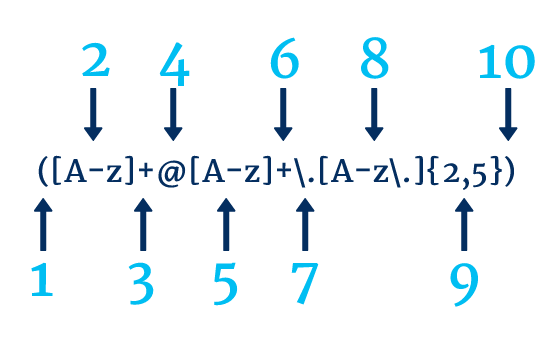
- ขั้นตอนที่ 1 แสดงจุดเริ่มต้นของแคปเจอร์กรุ๊ป
- ขั้นตอนที่ 2 จับคู่อักษรตัวพิมพ์ใหญ่ อักษรตัวพิมพ์เล็ก หรือขีดล่าง
- ขั้นตอนที่ 3 บอกเราว่าเรากำลังค้นหา 1 อินสแตนซ์ขึ้นไปของขั้นตอนที่ 2
- ขั้นตอนที่ 4 ตรงกับ @
- ขั้นตอนที่ 5 จับคู่อักษรตัวพิมพ์ใหญ่ อักษรตัวพิมพ์เล็ก หรือขีดล่าง
- ขั้นตอนที่ 6 บอกเราว่าเรากำลังค้นหาอินสแตนซ์ของขั้นตอนที่ 5 . ตั้งแต่ 1 อินสแตนซ์ขึ้นไป
- ขั้นตอนที่ 7 จับคู่กับจุด เราต้องใช้ a \ ดังนั้นเราจับคู่กับช่วงเวลาตามตัวอักษร ไม่ใช่ "" การทำงาน
- ขั้นตอนที่ 8 จับคู่กับอักษรตัวพิมพ์ใหญ่ ตัวพิมพ์เล็ก ขีดล่าง หรือจุด
- ขั้นตอนที่ 9 บอกเราว่าเรากำลังมองหาระหว่าง 2 ถึง 5 ครั้งของขั้นตอนที่ 8
- ขั้นตอนที่ 10 แสดงการปิดของแคปเจอร์กรุ๊ป
หากเราทำการแยกเสียงกรีดร้องแบบกำหนดเองโดยใช้เว็บไซต์ Codefixer และเรียกใช้การรวบรวมข้อมูล เราจะเห็นที่อยู่อีเมลใดๆ ที่ปรากฏบนเว็บไซต์

Google Analytics
Google Analytics ช่วยให้เราใช้ Regex สำหรับแอปพลิเคชันต่างๆ เช่น; การกรองมุมมอง การสร้างเป้าหมาย การสร้างผู้ชม การจัดกลุ่มเนื้อหา และการจัดกลุ่มช่อง

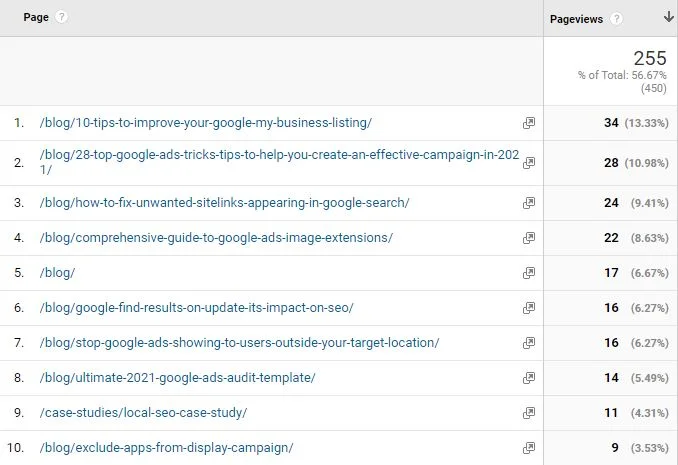
ในตัวอย่างด้านล่าง เราสามารถดูตัวอย่างของ Regex ที่ใช้ใน Google Analytics เพื่อกรองเพื่อแสดงเฉพาะการดูหน้าเว็บสำหรับหน้าบล็อกหรือกรณีศึกษา เป็นที่ยอมรับว่าใช้เกินความสามารถเล็กน้อย คุณสามารถใช้ (บล็อก|กรณี) ได้ แต่วิธีนี้จะให้การสาธิตที่ดีกว่าเกี่ยวกับวิธีการทำงาน

- ขั้นตอนที่ 1 แสดงจุดเริ่มต้นของแคปเจอร์กรุ๊ป
- ขั้นตอนที่ 2 หมายความว่านี่จะต้องเป็นจุดเริ่มต้นของสตริง
- ขั้นตอนที่ 3 จับคู่กับ “/” เราใช้ "\" ก่อนเครื่องหมายทับเพื่อจับคู่กับอักขระนั้นตามตัวอักษร
- ขั้นตอนที่ 4 ตรงกับคำว่า “บล็อก”
- ขั้นตอนที่ 5 จับคู่กับอักขระใดก็ได้ยกเว้นบรรทัดใหม่อย่างน้อยหนึ่งครั้ง
- ขั้นตอนที่ 6 หมายถึงเราต้องจับคู่กับบางอย่างก่อนหรือหลังแถบแนวตั้ง
- ขั้นตอนที่ 7 หมายความว่านี่จะต้องเป็นจุดเริ่มต้นของสตริง
- ขั้นตอนที่ 8 จับคู่กับ “/” เราใช้ "\" ก่อนเครื่องหมายทับเพื่อจับคู่กับอักขระนั้นตามตัวอักษร
- ขั้นตอนที่ 9 ตรงกับคำว่า “กรณี”
- ขั้นตอนที่ 10 จับคู่กับอักขระใดก็ได้ยกเว้นบรรทัดใหม่อย่างน้อยหนึ่งครั้ง
- ขั้นตอนที่ 11 แสดงการปิดของแคปเจอร์กรุ๊ป
เมื่อเรากรองข้อมูลพร็อพเพอร์ตี้ Google Analytics ของเรา ตอนนี้เราจะเห็นว่าเราเห็นเฉพาะการดูหน้าเว็บในบล็อกหรือโฟลเดอร์ย่อยกรณีศึกษาเท่านั้น
Google Tag Manager
ใน Google Tag Manager เราสามารถใช้ Regex เพื่อทริกเกอร์เหตุการณ์ Google Analytics เมื่อผู้ใช้ดำเนินการเสร็จสิ้น
สิ่งหนึ่งที่เราสามารถติดตามได้โดยใช้ Google Tag Manager คือผู้ใช้คลิกหมายเลขโทรศัพท์บนเว็บไซต์
ในบางครั้ง บนเว็บไซต์ การติดตามเหตุการณ์ง่ายๆ เช่น การคลิกหมายเลขโทรศัพท์ อาจมีความซับซ้อนโดยการจัดรูปแบบหรือรูปแบบหมายเลขโทรศัพท์ที่ปรากฏบนเว็บไซต์
ซึ่งทำให้กระบวนการสร้างแท็กใน Google Tag Manager ซับซ้อนขึ้นเพื่อทริกเกอร์เหตุการณ์เมื่อมีการคลิกหมายเลขโทรศัพท์เนื่องจากหมายเลขโทรศัพท์ไม่อยู่ในรูปแบบที่สอดคล้องกัน หมายความว่าเราไม่สามารถตั้งค่าให้ทริกเกอร์นี้เริ่มทำงานได้ง่ายๆ เมื่อ Click URL ประกอบด้วย “โทร:02890 923383”
สมมติว่าเรามีลิงก์หมายเลขโทรศัพท์ Codefixer บนเว็บไซต์ในสามรูปแบบที่แตกต่างกัน
- tel:02890923383
- โทร:028 90 923383
- เบอร์โทร:(+44) 2890 923383
เราสามารถใช้ Regex ต่อไปนี้เพื่อจับคู่กับหมายเลขโทรศัพท์ทั้งสามด้านบน

- ขั้นตอนที่ 1 แสดงจุดเริ่มต้นของกลุ่มที่ไม่จับภาพ “(?:”
- ขั้นตอนที่ 2 จะจับคู่กับ “tel:”
- ขั้นตอนที่ 3 เปิดแคปเจอร์กรุ๊ปแรก
- ขั้นตอนที่ 4 จับคู่กับ “028” ที่จุดเริ่มต้นของหมายเลขโทรศัพท์ที่เกี่ยวข้อง
- ขั้นตอนที่ 5 หมายถึง "หรือ" เพื่อให้เราสามารถจับคู่กับอักขระชุดแรกหรือชุดถัดไปได้
- ขั้นตอนที่ 6 ตรงกับ “(+44)” \"\" คือหนีอักขระพิเศษ +, (, และ )
- ขั้นตอนที่ 7 ปิดแคปเจอร์กรุ๊ป
- ขั้นตอนที่ 8 จับคู่ว่ามีอักขระช่องว่างเป็นศูนย์หรือหนึ่งตัว
- ขั้นตอนที่ 9 จับคู่กับอักขระใดก็ได้ระหว่าง 0-9
- ขั้นตอนที่ 10 จับคู่ว่ามีอักขระช่องว่างเป็นศูนย์หรือหนึ่งตัว
- ขั้นตอนที่ 11 จับคู่กับขั้นตอนก่อนหน้า 1 ขั้นตอนขึ้นไปและปิดกลุ่มที่ไม่จับภาพในที่สุด
วิธีการเรียนรู้ Regex:
แม้ว่าคำแนะนำข้างต้นจะให้ข้อมูลเบื้องต้น ตัวอย่างบางส่วน และการใช้งานจริงสำหรับ Regex อันดับแรก ฉันต้องยอมรับว่าฉันไม่ได้เป็นผู้เชี่ยวชาญ และการอ่านบล็อกโพสต์อาจไม่ทำให้คุณเป็นผู้เชี่ยวชาญได้ทั้งหมด ทันที.
วิธีหลักในการทำให้ Regex ดีขึ้นคือการพับแขนเสื้อขึ้นและฝึกฝนทักษะของคุณเป็นประจำ
ในฐานะที่เป็นส่วนหนึ่งของบทบาทของฉันในฐานะหัวหน้า PPC ใน Codefixer ฉันได้เริ่มใช้ Regex เป็นประจำเพื่อลดความซับซ้อนและทำให้งานง่าย ๆ เป็นไปโดยอัตโนมัติ และเมื่อเวลาผ่านไป ฉันได้เริ่มใช้มันในสถานการณ์ที่ซับซ้อนหรือซับซ้อนมากขึ้น ซึ่งช่วยปรับปรุงความเข้าใจของฉัน และใช้สำหรับ Regex
มีแหล่งข้อมูลออนไลน์ฟรีมากมายสำหรับการเรียนรู้ Regex สามเว็บไซต์หลักที่ฉันพบว่ามีประโยชน์มากที่สุดคือ:
- https://regex101.com/ – เว็บไซต์ที่ยอดเยี่ยมสำหรับการสร้าง ทดสอบ และแก้จุดบกพร่อง Regex ของคุณ ฉันมักจะมีแท็บเปิดอยู่บนเบราว์เซอร์ของฉันโดยเปิด Regex101 ไว้ นี่เป็นเครื่องช่วยชีวิตที่สมบูรณ์แบบเมื่อคุณนึกไม่ออกว่าจะทำอะไรบางอย่าง!
- https://regexone.com – Regexone เป็นเว็บไซต์ที่มีแบบฝึกหัดที่ให้ความรู้และง่ายต่อการติดตามเพื่อช่วยให้คุณเรียนรู้และใช้งาน Regex งานเริ่มต้นค่อนข้างง่าย แต่คืบหน้าอย่างรวดเร็วเพื่อให้กลายเป็นความท้าทายมากขึ้น เหมาะสำหรับผู้เริ่มต้น
- https://www.sitepoint.com/learn-regex/ – บล็อก Sitepoint นี้อธิบาย Regex ด้วยคำศัพท์ที่เข้าใจง่ายและเข้าใจง่าย แม้ว่าคุณอาจจะไม่ต้องการสิ่งนี้ทุกวัน แต่ก็มีที่บนแถบบุ๊กมาร์กของฉันเสมอเพื่อเป็นแหล่งข้อมูลที่ดีสำหรับผู้เริ่มต้น