
デジタル マーケティングでの Regex (正規表現) の使用
公開: 2021-11-30正規表現とは:
正規表現、または略して Regex は、テキストの管理、照合、フィルタリング、および抽出を可能にするテキストの文字列です。
正規表現は、大規模なデータ セットから有用なデータの特定の部分を抽出する必要があることが多いデジタル マーケティングで特に役立ちます。
この有用なデータの抽出は、手動で完了すると面倒な作業になる可能性があり、多くの場合、かなりの時間がかかります。 正規表現を使用すると、数式を使用してこれらのタスクを簡素化し、高速化できます。
正規表現は最初は困難または威圧的に見えるかもしれませんが、このブログは、正規表現がいかに単純であるかを示し、他のマーケターがデータ分析の最も退屈で時間のかかる部分を排除して自動化することを開始するのに役立つはずです.
共通トークン:
正規表現はトークンで構成されます。 これらの各トークンは、データ セット内の 1 文字または一連の文字と一致するか、文字が存在する必要がある位置を決定します。 以下の表に、最も一般的に使用されるトークンの例をいくつか示します。
| トークン | 関数 |
| | | | 代替、どちらか/または。 「A|B」は、「A」と「B」の両方に一致します。 |
| . | 改行以外の任意の 1 文字と一致します。 |
| * | 0 個以上に一致します。 したがって、「.*」は、改行以外の 0 個以上の任意の文字と一致します。 |
| + | 1 つ以上に一致します。 したがって、「.+」は、改行以外の 1 つ以上の任意の文字と一致します。 |
| ? | 0 回または 1 回一致します。 そう "。?" 改行以外の文字が 0 個または 1 個ある場合に一致します。 |
| \ | 次の文字と文字通り一致します。 そう "\。" 「.」のみに一致します。 そして他のキャラクターはありません。 |
| (…) | 丸括弧はキャプチャ グループを示します。 丸括弧内のすべてがキャプチャされます。 |
| (?:…) | 「?:」が後に続く丸括弧は、非キャプチャ グループを示します。 これはキャプチャ グループに似ていますが、コンテンツは保持されません。 |
| {…} | 中括弧は、照合する前のトークンのインスタンス数を決定します。 たとえば、「(a{1,3})」は、文字「a」の 1 ~ 3 回のインスタンスに一致します。 |
| […] | 角括弧を使用すると、一致する範囲または異なる文字またはトークンを定義できます。 たとえば、「[Az]」は大文字または小文字に一致します。 |
| ^ | 「^」は文字列の先頭に一致します。角括弧内で使用すると、範囲外の文字を意味します。 たとえば、[^Az] は小文字または大文字と一致しません。 |
| $ | 「$」は文字列の末尾に一致します。 たとえば、「[Az]$」は、文字列の末尾にある場合、大文字または小文字と一致します。 |
| \s | 「\s」は、任意の空白文字と一致します。 |
| \S | 「\S」は、空白以外の任意の文字と一致します。 |
| \d | 「\d」は、任意の数字と一致します。 |
| \D | 「\D」は、数字以外の任意の文字と一致します。 |
| \w | 「\w」は、任意の文字、数字、またはアンダースコアと一致します。 |
| \W | 「\W」は、文字、数字、またはアンダースコア以外のものと一致します。 |
デジタル マーケティングにおける正規表現の有用なアプリケーションの例:
叫ぶカエル
Screaming Frog では、正規表現を使用してカスタム抽出を実行できます。 カスタム抽出により、Web サイトから大量の有用な情報を抽出できます。
抽出できるデータの例には次のものがあります。 メール アドレス、トラッキング ID、スキーマ マークアップ、ページ タイトル、URL など。 思いついたら、おそらく Regex を使って見つけることができます!
下の画像では、電子メール アドレスを検索するために使用される正規表現の例を確認できます。 Web サイトにプレーン テキストのメール アドレスを使用すると、セキュリティ上の脆弱性が発生し、メール アドレスがスクレイピングされる可能性があるため、これは便利です。
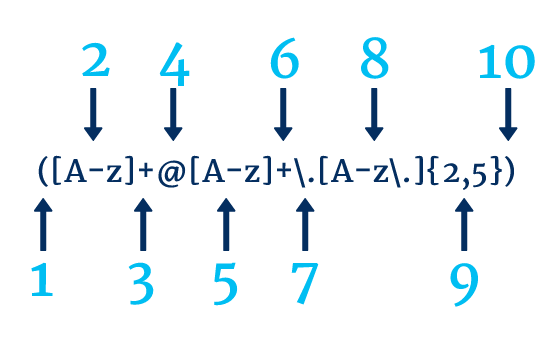
- ステップ 1 は、キャプチャ グループの開始を示しています
- ステップ 2 は、大文字、小文字、またはアンダースコアに一致します。
- ステップ 3 は、ステップ 2 のインスタンスを 1 つ以上探していることを示しています。
- ステップ 4 は @ と一致します
- ステップ 5 は、大文字、小文字、またはアンダースコアに一致します。
- ステップ 6 は、ステップ 5 のインスタンスを 1 つ以上探していることを示しています。
- ステップ 7 はピリオドと一致します。\ を使用する必要があるため、「.」ではなく文字どおりピリオドと一致します。 関数
- ステップ 8 は、大文字、小文字、アンダースコア、またはピリオドと一致します。
- ステップ 9 は、ステップ 8 の 2 ~ 5 回の発生を探していることを示しています。
- ステップ 10 は、キャプチャ グループの終了を示しています。
Codefixer Web サイトを使用してスクリーミング フロッグのカスタム抽出を行い、クロールを実行すると、Web サイトに表示されるすべての電子メール アドレスを確認できます。

グーグルアナリティクス
Google アナリティクスでは、次のような多くのアプリケーションで正規表現を使用できます。 ビューのフィルタリング、目標の作成、オーディエンスの作成、コンテンツのグループ化、およびチャネルのグループ化。

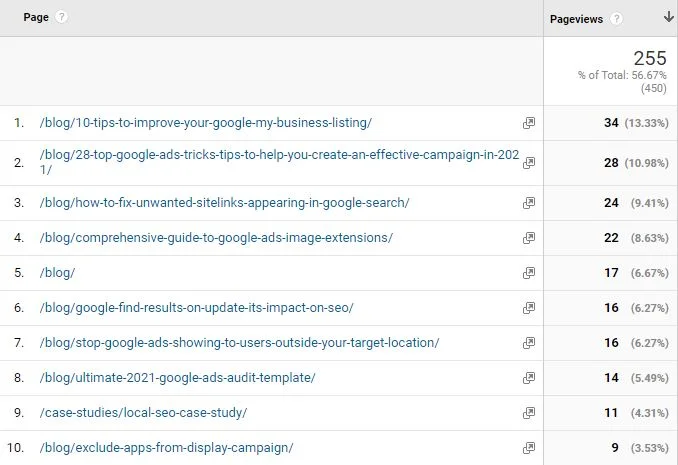
以下の例では、ブログまたはケース スタディ ページのいずれかのページビューのみを表示するようにフィルタリングするために Google アナリティクスで使用される正規表現の例を見ることができます。 確かに、これは少しやり過ぎです。(blog|case) を使用することもできますが、これにより、それがどのように機能するかについてのより良いデモンストレーションが得られます。

- ステップ 1 は、キャプチャ グループの開始を示しています
- ステップ 2 は、これが文字列の先頭でなければならないことを意味します
- ステップ 3 は「/」に一致します。 スラッシュの前に「\」を使用して、文字通りその文字と正確に一致させます
- ステップ 4 は「blog」という単語に一致します
- ステップ 5 は、改行を除く任意の文字と 1 回以上一致します
- ステップ 6 は、垂直バーの前後に何かを一致させる必要があることを意味します
- ステップ 7 は、これが文字列の先頭でなければならないことを意味します
- ステップ 8 は「/」に一致します。 スラッシュの前に「\」を使用して、文字通りその文字と正確に一致させます
- ステップ 9 は単語「case」と一致します
- ステップ 10 は、改行を除く任意の文字と 1 回以上一致します
- ステップ 11 は、キャプチャ グループの終了を示しています。
Google アナリティクス ビューをフィルタリングすると、ブログまたはケース スタディのサブフォルダにあるページのページ ビューのみが表示されていることがわかります。
Google タグ マネージャー
Google タグ マネージャーでは、正規表現を使用して、ユーザーがアクションを完了したときに Google アナリティクス イベントをトリガーできます。
Google タグ マネージャーを使用して追跡できることの 1 つは、ユーザーがウェブサイトで電話番号をクリックすることです。
Web サイトでは、電話番号のクリックなどの単純なイベントの追跡が、Web サイトに表示される電話番号の形式やバリエーションによって複雑になる場合があります。
これにより、Google タグ マネージャーでタグを作成して電話番号がクリックされたときにイベントをトリガーするプロセスが複雑になります。これは、電話番号の形式が一貫していないためです。つまり、クリック URL に「tel:02890 923383」。
Web サイトに Codefixer の電話番号リンクが 3 つの異なる形式であるとします。
- 電話:02890923383
- tel:028 90 923383
- 電話:(+44) 2890 923383
次の正規表現を使用して、上記の 3 つの電話番号すべてに一致させることができます。

- ステップ 1 は、非キャプチャ グループ「(?:」の先頭を示しています。
- ステップ 2 は「tel:」と一致します。
- 手順 3 では、最初のキャプチャ グループを開きます
- ステップ 4 は、電話番号の先頭にある「028」に一致します。
- ステップ 5 は「または」を意味するため、最初または次の文字セットと一致させることができます。
- ステップ 6 は「(+44)」に一致します。 「\」は、特殊文字 +、(、および ) をエスケープするためのものです。
- ステップ 7 は、キャプチャ グループを閉じます
- ステップ 8 は、空白文字が 0 個または 1 個の場合に一致します。
- ステップ 9 は、0 ~ 9 の任意の文字と一致します
- ステップ 10 は、空白文字が 0 個または 1 個の場合に一致します
- ステップ 11 は、前のステップの 1 つ以上と一致し、最後に非キャプチャ グループを閉じます。
正規表現を学ぶ方法:
上記のガイドでは、Regex の紹介、いくつかの例、および実用的なアプリケーションを提供していますが、私が決して専門家ではないことを最初に認めます。突然の。
正規表現を上達させる主な方法は、袖をまくり上げて定期的にスキルを練習することです。
Codefixer の PPC リードとしての役割の一環として、単純なタスクを簡素化および自動化するために正規表現を定期的に使用し始めました。時間が経つにつれて、より複雑または複雑な状況で正規表現を使用するようになり、理解が深まりました。正規表現に使用します。
正規表現を学習するための素晴らしい無料リソースがオンラインでたくさんあります。 私が最も役立つと思った主な 3 つの Web サイトは次のとおりです。
- https://regex101.com/ – 正規表現を構築、テスト、デバッグするための素晴らしい Web サイト。 私は通常、Regex101を開いたブラウザで常にタブを開いています。 何かを行う方法がまったくわからない場合、これは絶対的な命の恩人です!
- https://regexone.com – Regexone は、Regex の学習と使用に役立つ、わかりやすく有益で楽しいエクササイズを提供する Web サイトです。 タスクは非常に簡単に始まりますが、すぐに進行してより困難になります。 初心者に最適です。
- https://www.sitepoint.com/learn-regex/ – この Sitepoint ブログでは、Regex を非常にシンプルで理解しやすい用語で説明しています。 これはおそらく毎日必要というわけではありませんが、初心者向けの優れたリソースとして常にブックマーク バーに表示されます。