
Использование Regex (регулярных выражений) в цифровом маркетинге
Опубликовано: 2021-11-30Что такое регулярное выражение:
Регулярное выражение, или сокращенно Regex, представляет собой строку текста, которая позволяет нам управлять, сопоставлять, фильтровать и извлекать текст.
Regex особенно полезен в цифровом маркетинге, где часто необходимо извлекать определенные фрагменты полезных данных из больших наборов данных.
Извлечение этих полезных данных может быть трудоемкой задачей, если выполнять ее вручную, часто требуя значительного времени. С Regex мы можем использовать формулы для упрощения и ускорения этих задач.
Хотя поначалу Regex может показаться сложным или пугающим, этот блог должен продемонстрировать, насколько простым может быть Regex, и помочь другим маркетологам начать устранять и автоматизировать наиболее скучные и трудоемкие части анализа данных.
Общие жетоны:
Регулярное выражение состоит из токенов. Каждый из этих токенов соответствует одному символу или серии символов в вашем наборе данных или определяет позицию, в которой должен находиться символ. Мы можем увидеть некоторые примеры наиболее часто используемых токенов в таблице ниже.
| Токен | Функция |
| | | Альтернатива, или/или. «A|B» соответствует как «A», так и «B». |
| . | Соответствует любому одиночному символу, кроме новой строки. |
| * | Соответствует нулю или более чем. Таким образом, «.*» соответствует нулю или более любых символов, кроме новой строки. |
| + | Соответствует одному или нескольким. Таким образом, «.+» соответствует одному или нескольким любым символам, кроме новой строки. |
| ? | Совпадает ноль или один раз. Так ".?" соответствует, если есть ноль или один любой символ, кроме новой строки. |
| \ | Буквально соответствует следующему символу. Так "\." соответствует только «.» и никаких других персонажей. |
| (…) | Круглые скобки обозначают группу захвата. Захватывается все, что находится в круглых скобках. |
| (?:…) | Скругленные скобки, за которыми следует «?:», обозначают группу без захвата. Это похоже на группу захвата, но содержимое не сохраняется. |
| {…} | Фигурные скобки определяют, сколько экземпляров предыдущего токена вы хотите сопоставить. Например, «(a{1,3})» будет соответствовать от 1 до 3 экземпляров буквы «a». |
| […] | Квадратные скобки позволяют нам определять диапазоны или разные символы или токены для сопоставления. Например, «[Az]» соответствует любой букве верхнего или нижнего регистра. |
| ^ | Знак «^» соответствует началу строки или при использовании внутри квадратных скобок означает, что символы не входят в диапазон. Например, [^Az] не будет соответствовать строчным или прописным буквам. |
| $ | «$» соответствует концу строки. Например, «[Az]$» будет соответствовать букве верхнего или нижнего регистра, если она находится в конце строки. |
| \с | «\s» соответствует любому пробельному символу. |
| \С | «\S» соответствует любому непробельному символу. |
| \ д | «\d» соответствует любому цифровому символу. |
| \Д | «\D» соответствует любому нецифровому символу. |
| \ш | «\w» соответствует любой букве, цифре или символу подчеркивания. |
| \ Вт | «\W» соответствует чему угодно, кроме буквы, цифры или символа подчеркивания. |
Примеры полезных приложений для Regex в цифровом маркетинге:
Кричащая лягушка
В Screaming Frog мы можем выполнять пользовательские извлечения с помощью Regex. Пользовательские извлечения позволяют нам извлекать массу полезной информации с веб-сайта.
Некоторые примеры данных, которые мы можем извлечь, включают: Адреса электронной почты, идентификаторы отслеживания, разметка схемы, заголовки страниц, URL-адреса и многое другое. Если вы можете подумать об этом, вы, вероятно, можете использовать Regex, чтобы найти его!
На изображении ниже мы видим пример регулярного выражения, используемого для поиска адресов электронной почты. Это может быть полезно, поскольку наличие адресов электронной почты в виде простого текста на вашем веб-сайте может быть уязвимостью системы безопасности и привести к очистке адресов электронной почты.
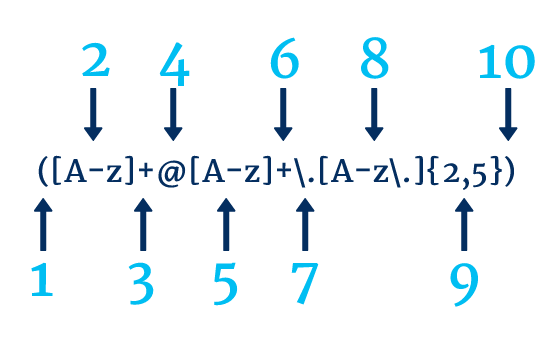
- Шаг 1 показывает начало группы захвата
- Шаг 2 соответствует любым заглавным буквам, строчным буквам или знакам подчеркивания.
- Шаг 3 говорит нам, что мы ищем 1 или более экземпляров шага 2.
- Шаг 4 соответствует @
- Шаг 5 соответствует любым заглавным буквам, строчным буквам или знакам подчеркивания.
- Шаг 6 говорит нам, что мы ищем 1 или более экземпляров шага 5.
- Шаг 7 соответствует точке, мы должны использовать \, поэтому мы сопоставляем точку буквально, а не «.» функция
- Шаг 8 соответствует любым заглавным буквам, строчным буквам, знакам подчеркивания или точкам.
- Шаг 9 говорит нам, что мы ищем от 2 до 5 вхождений шага 8.
- Шаг 10 показывает закрытие группы захвата
Если мы выполним пользовательское извлечение кричащей лягушки с помощью веб-сайта Codefixer и запустим сканирование, мы сможем увидеть любой из адресов электронной почты, которые появляются на веб-сайте.


Гугл Аналитика
Google Analytics позволяет нам использовать Regex для ряда приложений, таких как; фильтрация представлений, создание целей, создание аудиторий, группировка контента и группировка каналов.
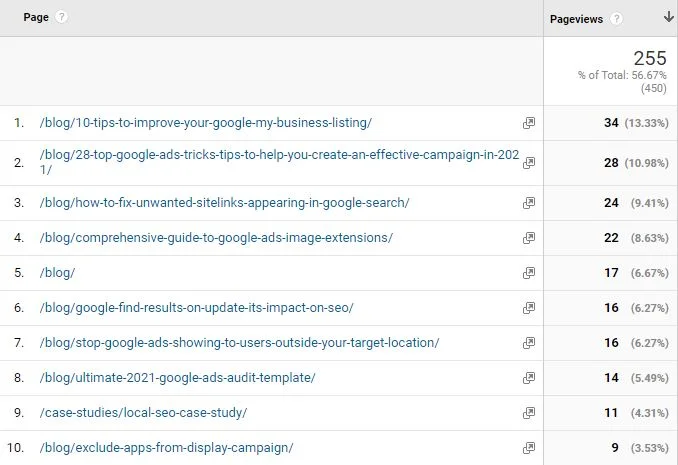
В приведенном ниже примере мы видим пример регулярного выражения, используемого в Google Analytics для фильтрации, чтобы показывать только просмотры страниц либо для блога, либо для страниц тематических исследований. По общему признанию, это немного излишне, вы могли бы просто использовать (blog|case), но это дает лучшую демонстрацию того, как это работает.

- Шаг 1 показывает начало группы захвата
- Шаг 2 означает, что это должно быть начало строки
- Шаг 3 соответствует символу «/». Мы используем «\» перед косой чертой, чтобы буквально соответствовать именно этому символу.
- Шаг 4 соответствует слову «блог».
- Шаг 5 соответствует любому символу, кроме новой строки, один или несколько раз
- Шаг 6 означает, что нам нужно сопоставить что-то до или после вертикальной черты.
- Шаг 7 означает, что это должно быть начало строки
- Шаг 8 соответствует символу «/». Мы используем «\» перед косой чертой, чтобы буквально соответствовать именно этому символу.
- Шаг 9 соответствует слову «кейс»
- Шаг 10 соответствует любому символу, кроме новой строки, один или несколько раз
- Шаг 11 показывает закрытие группы захвата
Когда мы фильтруем наше представление Google Analytics, теперь мы можем видеть, что мы видим только просмотры страниц для наших страниц, которые находятся в подпапках блога или тематических исследований.
Диспетчер тегов Google
В Диспетчере тегов Google мы можем использовать регулярное выражение для запуска событий Google Analytics, когда пользователь выполняет действие.
Одна вещь, которую мы можем отслеживать с помощью Диспетчера тегов Google, — это пользователи, нажимающие номер телефона на веб-сайте.
Иногда на веб-сайте отслеживание простых событий, таких как клики по номеру телефона, может быть затруднено из-за форматирования или вариантов номера телефона, отображаемого на веб-сайте.
Это усложняет процесс создания тега в Диспетчере тегов Google для запуска события при нажатии на номер телефона из-за того, что он не имеет согласованного формата, а это означает, что мы не можем просто настроить этот триггер на срабатывание, когда URL-адрес клика содержит «тел: 02890 923383».
Допустим, у нас есть ссылки на номера телефонов Codefixer на веб-сайте в трех разных формах;
- тел:02890923383
- тел:028 90 923383
- тел:(+44) 2890 923383
Мы можем использовать следующее регулярное выражение для сопоставления со всеми тремя телефонными номерами выше.

- Шаг 1 показывает начало группы без захвата «(?:»
- Шаг 2 будет соответствовать «тел:»
- Шаг 3 открывает первую группу захвата
- Шаг 4 соответствует «028» в начале телефонных номеров, где это применимо.
- Шаг 5 означает «или», поэтому мы можем сопоставить первый или следующий набор символов.
- Шаг 6 соответствует «(+44)». Символ «\» предназначен для экранирования специальных символов +, ( и )
- Шаг 7 закрывает группу захвата
- Шаг 8 соответствует, если есть ноль или один пробельный символ
- Шаг 9 соответствует любому символу от 0 до 9
- Шаг 10 соответствует, если есть ноль или один пробельный символ
- Шаг 11 совпадает с одним или несколькими предыдущими шагами и, наконец, закрывает группу без захвата.
Как выучить регулярное выражение:
Хотя приведенное выше руководство содержит введение, несколько примеров и практические приложения для Regex, я буду первым, кто признает, что я ни в коем случае не эксперт, и чтение сообщения в блоге, вероятно, не сделает вас экспертом во всех областях. неожиданность.
Основной способ улучшить Regex — это засучить рукава и регулярно практиковать свои навыки.
В рамках своей роли руководителя PPC в Codefixer я начал регулярно использовать Regex для упрощения и автоматизации простых задач, и со временем я начал использовать его в более сложных или сложных ситуациях, которые помогли улучшить мое понимание и использует для Regex.
В Интернете есть масса фантастических бесплатных ресурсов для изучения Regex. Три основных веб-сайта, которые я считаю наиболее полезными:
- https://regex101.com/ — фантастический веб-сайт для создания, тестирования и отладки вашего регулярного выражения. Обычно у меня всегда открыта вкладка в браузере с открытым Regex101. Это просто спасение, когда вы просто не можете понять, как что-то сделать!
- https://regexone.com — Regexone — это веб-сайт с простыми в использовании информативными и увлекательными упражнениями, которые помогут вам изучить и использовать Regex. Задания начинаются довольно легко, но быстро прогрессируют, становясь все более сложными. Идеально подходит для начинающих.
- https://www.sitepoint.com/learn-regex/ — этот блог Sitepoint объясняет Regex очень простыми и понятными терминами. Хотя вам, вероятно, это не понадобится каждый день, оно всегда будет на моей панели закладок в качестве отличного ресурса для начинающих.